3316 Repositories
Python data-quality-analysis Libraries

Code and data for paper "Deep Photo Style Transfer"
deep-photo-styletransfer Code and data for paper "Deep Photo Style Transfer" Disclaimer This software is published for academic and non-commercial use
 9.9k Dec 29, 2022
9.9k Dec 29, 2022
A data preprocessing and feature engineering script for a machine learning pipeline is prepared.
FEATURE ENGINEERING Business Problem: A data preprocessing and feature engineering script for a machine learning pipeline needs to be prepared. It is
 7 Dec 18, 2021
7 Dec 18, 2021
Required for a machine learning pipeline data preprocessing and variable engineering script needs to be prepared
Feature-Engineering Required for a machine learning pipeline data preprocessing and variable engineering script needs to be prepared. When the dataset
 5 Apr 21, 2022
5 Apr 21, 2022
Sentiment Analysis Project using Count Vectorizer and TF-IDF Vectorizer
Sentiment Analysis Project This project contains two sentiment analysis programs for Hotel Reviews using a Hotel Reviews dataset from Datafiniti. The
 0 Mar 28, 2022
0 Mar 28, 2022
The repository forked from NVlabs uses our data. (Differentiable rasterization applied to 3D model simplification tasks)
nvdiffmodeling [origin_code] Differentiable rasterization applied to 3D model simplification tasks, as described in the paper: Appearance-Driven Autom
 2 Oct 31, 2022
2 Oct 31, 2022

Extract rooms type, door, neibour rooms, rooms corners nad bounding boxes, and generate graph from rplan dataset
Housegan-data-reader House-GAN++ (data-reader) Code and instructions for converting rplan dataset (raster images) to housegan++ data format. House-GAN
 13 Nov 24, 2022
13 Nov 24, 2022
A Semi-Intelligent ChatBot filled with statistical and economical data for the Premier League.
MONEYBALL - ChatBot Module: 4006CEM, Class: B, Group: 5 Contributors: Jonas Djondo Roshan Kc Cole Samson Daniel Rodrigues Ihteshaam Naseer Kind remind
 1 Nov 18, 2021
1 Nov 18, 2021
Data Utilities e.g. for importing files to onetask
Use this repository to easily convert your source files (csv, txt, excel, json, html) into record-oriented JSON files that can be uploaded into onetask.
 1 Jul 18, 2022
1 Jul 18, 2022
Finding Label and Model Errors in Perception Data With Learned Observation Assertions
Finding Label and Model Errors in Perception Data With Learned Observation Assertions This is the project page for Finding Label and Model Errors in P
 17 Oct 14, 2022
17 Oct 14, 2022
🐦 Quickly annotate data from the comfort of your Jupyter notebook
🐦 pigeon - Quickly annotate data on Jupyter Pigeon is a simple widget that lets you quickly annotate a dataset of unlabeled examples from the comfort
 647 Jan 5, 2023
647 Jan 5, 2023

This is the code used in the paper "Entity Embeddings of Categorical Variables".
This is the code used in the paper "Entity Embeddings of Categorical Variables". If you want to get the original version of the code used for the Kagg
 845 Nov 29, 2022
845 Nov 29, 2022
A scikit-learn-compatible module for estimating prediction intervals.
MAPIE - Model Agnostic Prediction Interval Estimator MAPIE allows you to easily estimate prediction intervals (or prediction sets) using your favourit
 588 Jan 4, 2023
588 Jan 4, 2023
A high performance implementation of HDBSCAN clustering.
HDBSCAN HDBSCAN - Hierarchical Density-Based Spatial Clustering of Applications with Noise. Performs DBSCAN over varying epsilon values and integrates
2.3k Jan 2, 2023

PyClustering is a Python, C++ data mining library.
pyclustering is a Python, C++ data mining library (clustering algorithm, oscillatory networks, neural networks). The library provides Python and C++ implementations (C++ pyclustering library) of each algorithm or model. C++ pyclustering library is a part of pyclustering and supported for Linux, Windows and MacOS operating systems.
 1k Jan 5, 2023
1k Jan 5, 2023

The Fundamental Clustering Problems Suite (FCPS) summaries 54 state-of-the-art clustering algorithms, common cluster challenges and estimations of the number of clusters as well as the testing for cluster tendency.
FCPS Fundamental Clustering Problems Suite The package provides over sixty state-of-the-art clustering algorithms for unsupervised machine learning pu
 9 Nov 27, 2022
9 Nov 27, 2022
t-SNE and hierarchical clustering are popular methods of exploratory data analysis, particularly in biology.
tree-SNE t-SNE and hierarchical clustering are popular methods of exploratory data analysis, particularly in biology. Building on recent advances in s
 61 Nov 21, 2022
61 Nov 21, 2022
Subpopulation detection in high-dimensional single-cell data
PhenoGraph for Python3 PhenoGraph is a clustering method designed for high-dimensional single-cell data. It works by creating a graph ("network") repr
 42 Sep 5, 2022
42 Sep 5, 2022
Kats, a kit to analyze time series data, a lightweight, easy-to-use, generalizable, and extendable framework to perform time series analysis, from understanding the key statistics and characteristics, detecting change points and anomalies, to forecasting future trends.
Description Kats is a toolkit to analyze time series data, a lightweight, easy-to-use, and generalizable framework to perform time series analysis. Ti
 4.1k Jan 9, 2023
4.1k Jan 9, 2023
A statistical library designed to fill the void in Python's time series analysis capabilities, including the equivalent of R's auto.arima function.
pmdarima Pmdarima (originally pyramid-arima, for the anagram of 'py' + 'arima') is a statistical library designed to fill the void in Python's time se
 1.3k Dec 22, 2022
1.3k Dec 22, 2022
A statistical library designed to fill the void in Python's time series analysis capabilities, including the equivalent of R's auto.arima function.
pmdarima Pmdarima (originally pyramid-arima, for the anagram of 'py' + 'arima') is a statistical library designed to fill the void in Python's time se
1.3k Jan 6, 2023

Contains an implementation (sklearn API) of the algorithm proposed in "GENDIS: GEnetic DIscovery of Shapelets" and code to reproduce all experiments.
GENDIS GENetic DIscovery of Shapelets In the time series classification domain, shapelets are small subseries that are discriminative for a certain cl
 90 Oct 28, 2022
90 Oct 28, 2022
Calling Julia from Python - an experiment on data loading
Calling Julia from Python - an experiment on data loading See the slides. TLDR After reading Patrick's blog post, we decided to try to replace C++ wit
 8 Jun 7, 2022
8 Jun 7, 2022
Official implementation for "Image Quality Assessment using Contrastive Learning"
Image Quality Assessment using Contrastive Learning Pavan C. Madhusudana, Neil Birkbeck, Yilin Wang, Balu Adsumilli and Alan C. Bovik This is the offi
 67 Dec 30, 2022
67 Dec 30, 2022
An experimental Python-to-C transpiler and domain specific language for embedded high-performance computing
An experimental Python-to-C transpiler and domain specific language for embedded high-performance computing
 562 Dec 28, 2022
562 Dec 28, 2022

The audio-video synchronization of MKV Container Format is exploited to achieve data hiding
The audio-video synchronization of MKV Container Format is exploited to achieve data hiding, where the hidden data can be utilized for various management purposes, including hyper-linking, annotation, and authentication
 1 Nov 17, 2021
1 Nov 17, 2021
Urban Big Data Centre Housing Sensor Project
Housing Sensor Project The Urban Big Data Centre is conducting a study of indoor environmental data in Scottish houses. We are using Raspberry Pi devi
 2 Dec 13, 2021
2 Dec 13, 2021
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository will provide the official PyTorch implementa
 238 Nov 25, 2022
238 Nov 25, 2022
A deep-learning pipeline for segmentation of ambiguous microscopic images.
Welcome to Official repository of deepflash2 - a deep-learning pipeline for segmentation of ambiguous microscopic images. Quick Start in 30 seconds se
 39 Dec 19, 2022
39 Dec 19, 2022
Full-featured Decision Trees and Random Forests learner.
CID3 This is a full-featured Decision Trees and Random Forests learner. It can save trees or forests to disk for later use. It is possible to query tr
 3 Aug 15, 2022
3 Aug 15, 2022

Repository containing detailed experiments related to the paper "Memotion Analysis through the Lens of Joint Embedding".
Memotion Analysis Through The Lens Of Joint Embedding This repository contains the experiments conducted as described in the paper 'Memotion Analysis
 1 Mar 16, 2022
1 Mar 16, 2022
This repository is maintained for the scientific paper tittled " Study of keyword extraction techniques for Electric Double Layer Capacitor domain using text similarity indexes: An experimental analysis "
kwd-extraction-study This repository is maintained for the scientific paper tittled " Study of keyword extraction techniques for Electric Double Layer
 1 Dec 5, 2022
1 Dec 5, 2022

Stochastic gradient descent with model building
Stochastic Model Building (SMB) This repository includes a new fast and robust stochastic optimization algorithm for training deep learning models. Th
 22 Jan 19, 2022
22 Jan 19, 2022

Scrutinizing XAI with linear ground-truth data
This repository contains all the experiments presented in the corresponding paper: "Scrutinizing XAI using linear ground-truth data with suppressor va
 2 Oct 4, 2022
2 Oct 4, 2022
Code and real data for the paper "Counterfactual Temporal Point Processes", available at arXiv.
counterfactual-tpp This is a repository containing code and real data for the paper Counterfactual Temporal Point Processes. Pre-requisites This code
 11 Dec 9, 2022
11 Dec 9, 2022
Code and data accompanying our SVRHM'21 paper.
Code and data accompanying our SVRHM'21 paper. Requires tensorflow 1.13, python 3.7, scikit-learn, and pytorch 1.6.0 to be installed. Python scripts i
 5 Nov 17, 2021
5 Nov 17, 2021
Automated detection of anomalous exoplanet transits in light curve data.
Automatically detecting anomalous exoplanet transits This repository contains the source code for the paper "Automatically detecting anomalous exoplan
 1 Feb 1, 2022
1 Feb 1, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE: A Benchmark Suite for Data-centric NLP You can get the english version of README. 以数据为中心的AI测评(DataCLUE) 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE
 135 Dec 22, 2022
135 Dec 22, 2022
Stochastic Extragradient: General Analysis and Improved Rates
Stochastic Extragradient: General Analysis and Improved Rates This repository is the official implementation of the paper "Stochastic Extragradient: G
 4 Nov 11, 2022
4 Nov 11, 2022
Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings
Text2Music Emotion Embedding Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings Reference Emotion Embedding Spaces for Matching
 50 Dec 5, 2022
50 Dec 5, 2022

A collection of online resources to help you on your Tech journey.
Everything Tech Resources & Projects About The Project Coming from an engineering background and looking to up skill yourself on a new field can be di
 396 Dec 31, 2022
396 Dec 31, 2022

SASE : Self-Adaptive noise distribution network for Speech Enhancement with heterogeneous data of Cross-Silo Federated learning
SASE : Self-Adaptive noise distribution network for Speech Enhancement with heterogeneous data of Cross-Silo Federated learning We propose a SASE mode
 1 Nov 20, 2021
1 Nov 20, 2021

Interactive Web App with Streamlit and Scikit-learn that applies different Classification algorithms to popular datasets
Interactive Web App with Streamlit and Scikit-learn that applies different Classification algorithms to popular datasets Datasets Used: Iris dataset,
 2 Nov 18, 2021
2 Nov 18, 2021
FLIR/DJI IR Camera Data Parser, Python Version
FLIR/DJI IR Camera Data Parser, Python Version Parser infrared camera data as NumPy data. Usage Clone this respository and cd thermal_parser. Run pip
 14 Dec 23, 2022
14 Dec 23, 2022
Scikit learn library models to account for data and concept drift.
liquid_scikit_learn Scikit learn library models to account for data and concept drift. This python library focuses on solving data drift and concept d
 7 Nov 18, 2021
7 Nov 18, 2021
Python plugin/extra to load data files from an external source (such as AWS S3) to a local directory
Data Loader Plugin - Python Table of Content (ToC) Data Loader Plugin - Python Table of Content (ToC) Overview References Python module Python virtual
 2 Jan 10, 2022
2 Jan 10, 2022

Service for working with open data of the State Duma of the Russian Federation
Сервис для работы с открытыми данными Госдумы РФ Исходные данные из API Госдумы РФ извлекаются с помощью Apache Nifi и приземляются в хранилище Clickh
 2 Feb 14, 2022
2 Feb 14, 2022
MASS (Mueen's Algorithm for Similarity Search) - a python 2 and 3 compatible library used for searching time series sub-sequences under z-normalized Euclidean distance for similarity.
Introduction MASS allows you to search a time series for a subquery resulting in an array of distances. These array of distances enable you to identif
 79 Dec 31, 2022
79 Dec 31, 2022
ObsPy: A Python Toolbox for seismology/seismological observatories.
ObsPy is an open-source project dedicated to provide a Python framework for processing seismological data. It provides parsers for common file formats
 979 Jan 7, 2023
979 Jan 7, 2023
sktime companion package for deep learning based on TensorFlow
NOTE: sktime-dl is currently being updated to work correctly with sktime 0.6, and wwill be fully relaunched over the summer. The plan is Refactor and
 573 Jan 5, 2023
573 Jan 5, 2023

Luminaire is a python package that provides ML driven solutions for monitoring time series data.
A hands-off Anomaly Detection Library Table of contents What is Luminaire Quick Start Time Series Outlier Detection Workflow Anomaly Detection for Hig
 670 Jan 2, 2023
670 Jan 2, 2023
Time Series Cross-Validation -- an extension for scikit-learn
TSCV: Time Series Cross-Validation This repository is a scikit-learn extension for time series cross-validation. It introduces gaps between the traini
 222 Jan 1, 2023
222 Jan 1, 2023
Python library to download market data via Bloomberg, Eikon, Quandl, Yahoo etc.
findatapy findatapy creates an easy to use Python API to download market data from many sources including Quandl, Bloomberg, Yahoo, Google etc. using
 1.3k Jan 4, 2023
1.3k Jan 4, 2023

Portfolio analytics for quants, written in Python
QuantStats: Portfolio analytics for quants QuantStats Python library that performs portfolio profiling, allowing quants and portfolio managers to unde
 2.7k Jan 8, 2023
2.7k Jan 8, 2023
scikit-survival is a Python module for survival analysis built on top of scikit-learn.
scikit-survival scikit-survival is a Python module for survival analysis built on top of scikit-learn. It allows doing survival analysis while utilizi
 876 Jan 4, 2023
876 Jan 4, 2023
Library of Stan Models for Survival Analysis
survivalstan: Survival Models in Stan author: Jacki Novik Overview Library of Stan Models for Survival Analysis Features: Variety of standard survival
 122 Jan 6, 2023
122 Jan 6, 2023
PySurvival is an open source python package for Survival Analysis modeling
PySurvival What is Pysurvival ? PySurvival is an open source python package for Survival Analysis modeling - the modeling concept used to analyze or p
 265 Dec 27, 2022
265 Dec 27, 2022
Deep Survival Machines - Fully Parametric Survival Regression
Package: dsm Python package dsm provides an API to train the Deep Survival Machines and associated models for problems in survival analysis. The under
 10 Dec 30, 2022
10 Dec 30, 2022

Banpei is a Python package of the anomaly detection.
Banpei Banpei is a Python package of the anomaly detection. Anomaly detection is a technique used to identify unusual patterns that do not conform to
 282 Jan 3, 2023
282 Jan 3, 2023
A framework for using LSTMs to detect anomalies in multivariate time series data. Includes spacecraft anomaly data and experiments from the Mars Science Laboratory and SMAP missions.
Telemanom (v2.0) v2.0 updates: Vectorized operations via numpy Object-oriented restructure, improved organization Merge branches into single branch fo
 844 Dec 28, 2022
844 Dec 28, 2022
A Python package for modular causal inference analysis and model evaluations
Causal Inference 360 A Python package for inferring causal effects from observational data. Description Causal inference analysis enables estimating t
 506 Dec 19, 2022
506 Dec 19, 2022
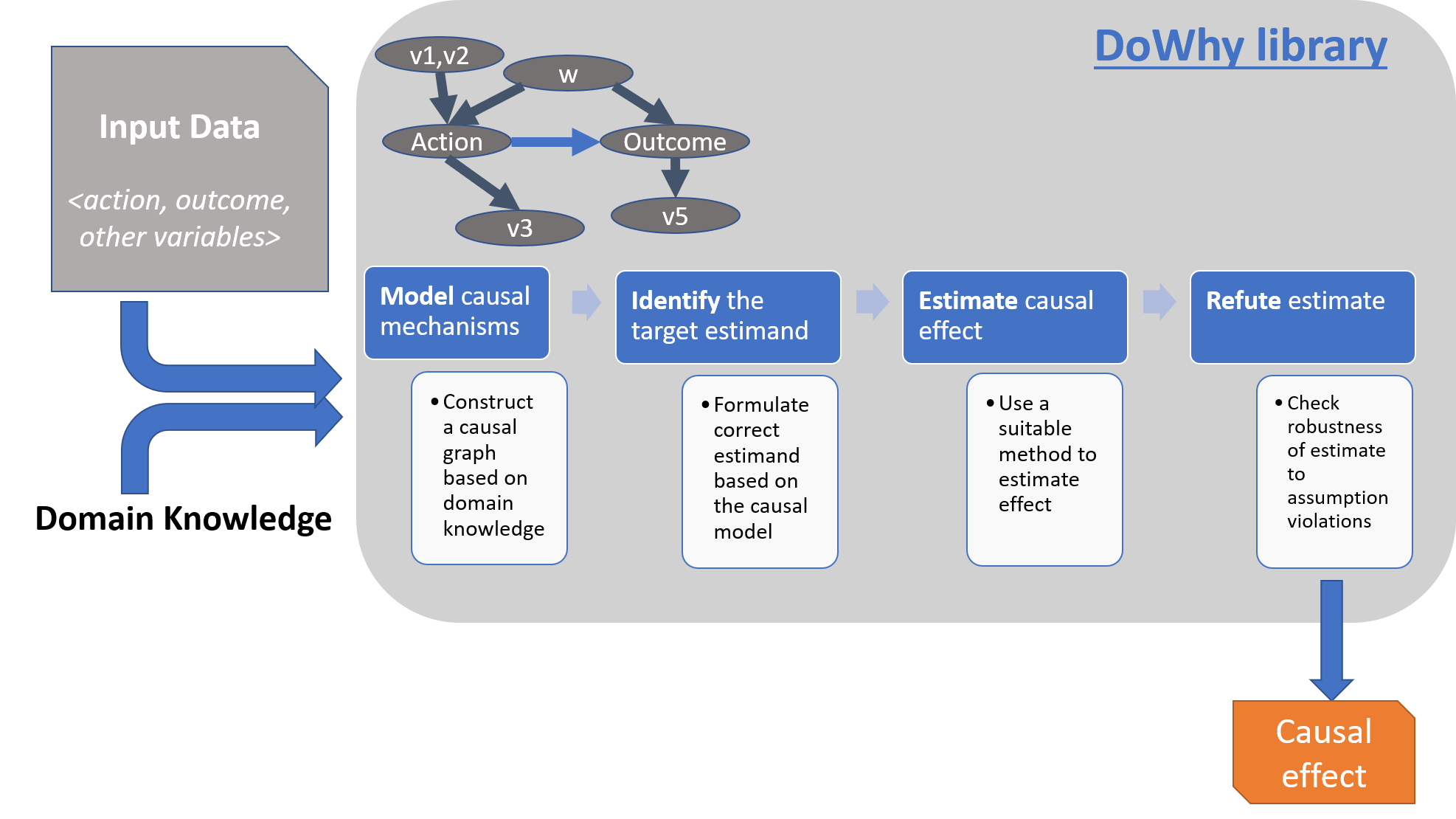
DoWhy is a Python library for causal inference that supports explicit modeling and testing of causal assumptions. DoWhy is based on a unified language for causal inference, combining causal graphical models and potential outcomes frameworks.
DoWhy | An end-to-end library for causal inference Amit Sharma, Emre Kiciman Introducing DoWhy and the 4 steps of causal inference | Microsoft Researc
 5.6k Jan 7, 2023
5.6k Jan 7, 2023

Responsible Machine Learning with Python
Examples of techniques for training interpretable ML models, explaining ML models, and debugging ML models for accuracy, discrimination, and security.
 624 Jan 6, 2023
624 Jan 6, 2023

LOFO (Leave One Feature Out) Importance calculates the importances of a set of features based on a metric of choice,
LOFO (Leave One Feature Out) Importance calculates the importances of a set of features based on a metric of choice, for a model of choice, by iteratively removing each feature from the set, and evaluating the performance of the model, with a validation scheme of choice, based on the chosen metric.
 691 Dec 23, 2022
691 Dec 23, 2022
moDel Agnostic Language for Exploration and eXplanation
moDel Agnostic Language for Exploration and eXplanation Overview Unverified black box model is the path to the failure. Opaqueness leads to distrust.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet buil
 3.4k Jan 7, 2023
3.4k Jan 7, 2023
An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
NNI Doc | 简体中文 NNI (Neural Network Intelligence) is a lightweight but powerful toolkit to help users automate Feature Engineering, Neural Architecture
12.4k Dec 31, 2022
🌊 River is a Python library for online machine learning.
River is a Python library for online machine learning. It is the result of a merger between creme and scikit-multiflow. River's ambition is to be the go-to library for doing machine learning on streaming data.
 4k Jan 3, 2023
4k Jan 3, 2023
Hangar is version control for tensor data. Commit, branch, merge, revert, and collaborate in the data-defined software era.
Overview docs tests package Hangar is version control for tensor data. Commit, branch, merge, revert, and collaborate in the data-defined software era
 193 Nov 29, 2022
193 Nov 29, 2022
Transpile trained scikit-learn estimators to C, Java, JavaScript and others.
sklearn-porter Transpile trained scikit-learn estimators to C, Java, JavaScript and others. It's recommended for limited embedded systems and critical
 1.2k Jan 5, 2023
1.2k Jan 5, 2023
ModelChimp is an experiment tracker for Deep Learning and Machine Learning experiments.
ModelChimp What is ModelChimp? ModelChimp is an experiment tracker for Deep Learning and Machine Learning experiments. ModelChimp provides the followi
 124 Dec 21, 2022
124 Dec 21, 2022
An orchestration platform for the development, production, and observation of data assets.
Dagster An orchestration platform for the development, production, and observation of data assets. Dagster lets you define jobs in terms of the data f
 6.2k Jan 8, 2023
6.2k Jan 8, 2023

Metaflow is a human-friendly Python/R library that helps scientists and engineers build and manage real-life data science projects
Metaflow Metaflow is a human-friendly Python/R library that helps scientists and engineers build and manage real-life data science projects. Metaflow
 6.3k Jan 3, 2023
6.3k Jan 3, 2023
Handle, manipulate, and convert data with units in Python
unyt A package for handling numpy arrays with units. Often writing code that deals with data that has units can be confusing. A function might return
 304 Jan 2, 2023
304 Jan 2, 2023
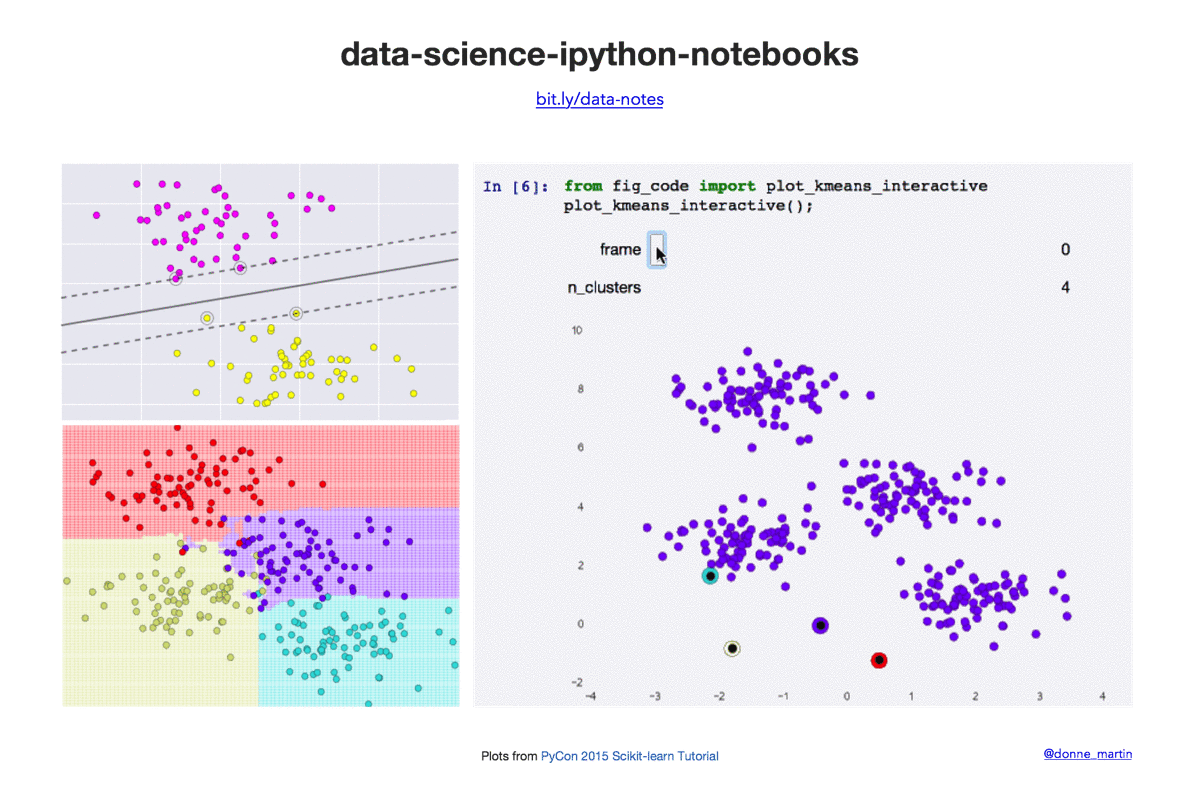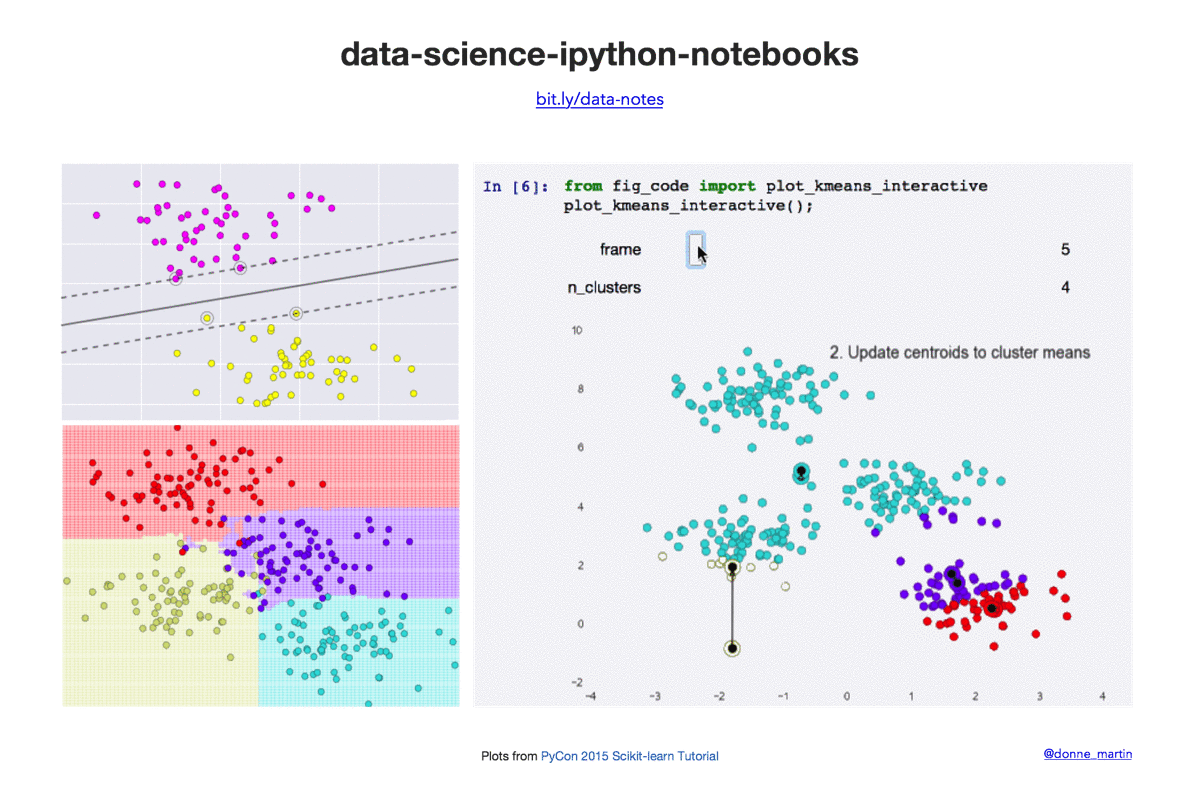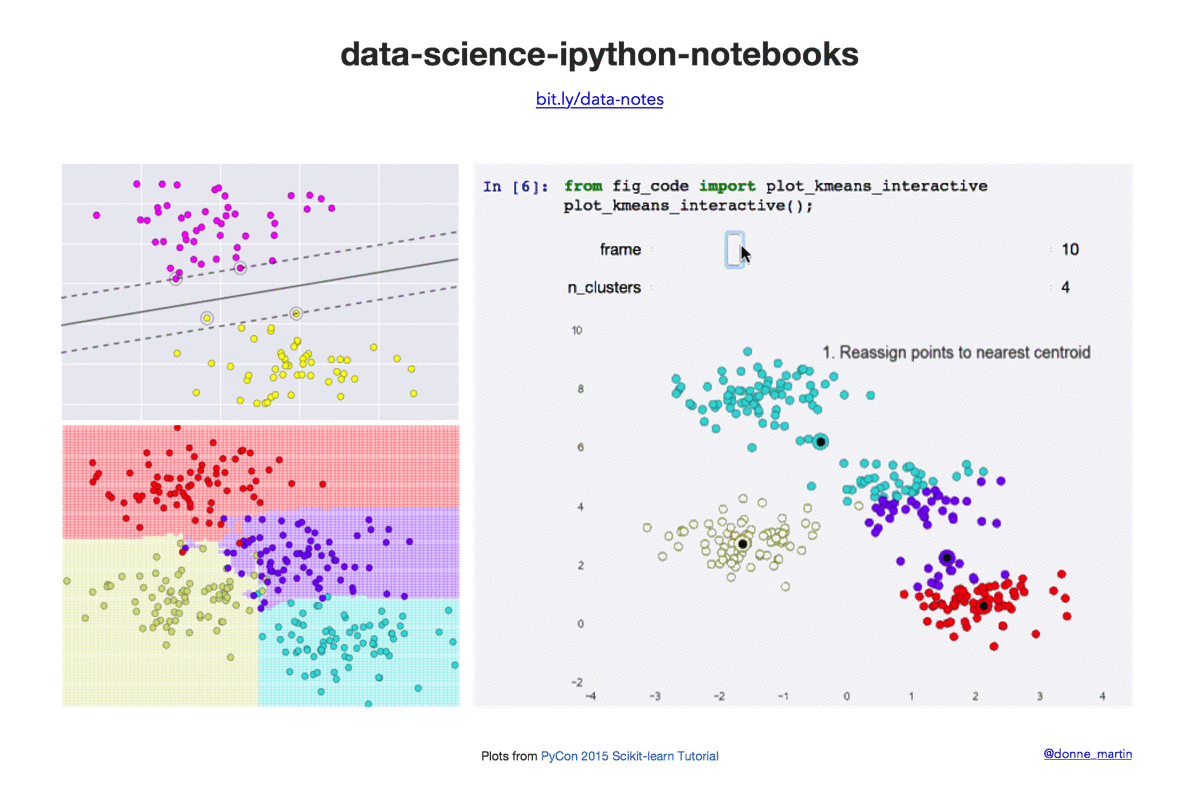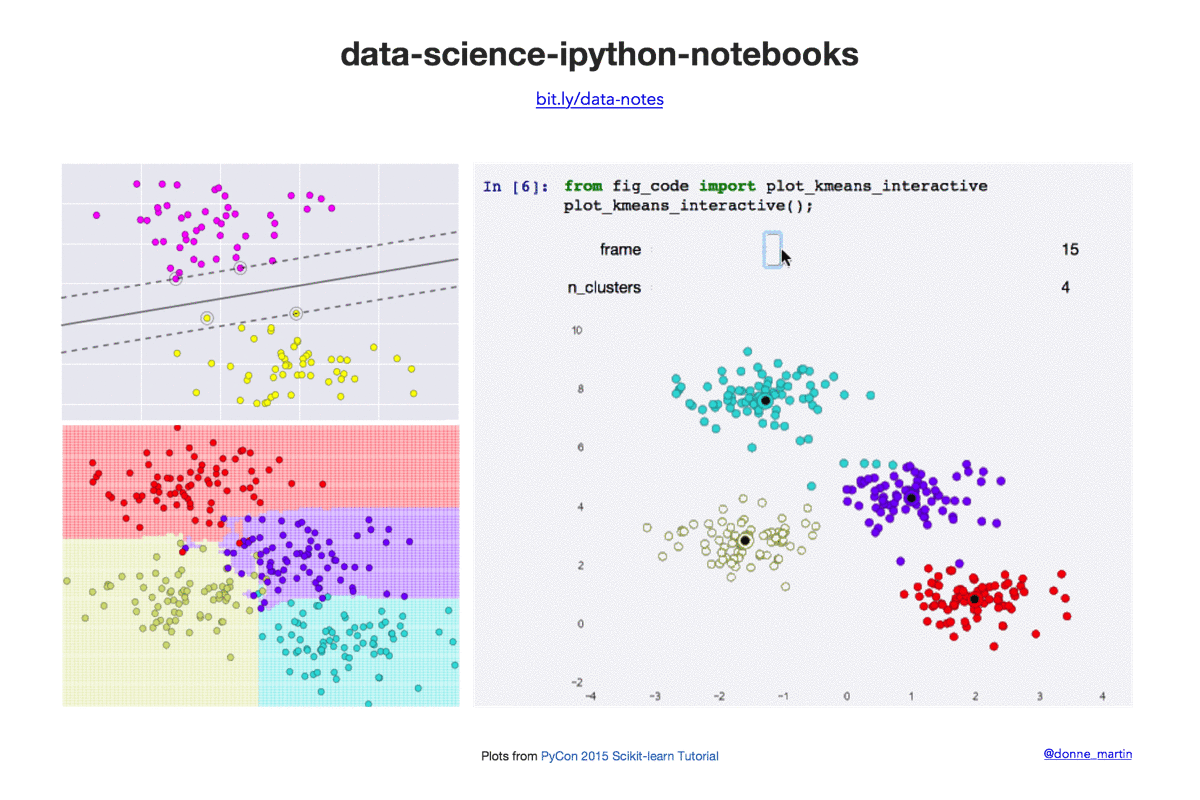
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
 24.5k Jan 9, 2023
24.5k Jan 9, 2023

List of Data Science Cheatsheets to rule the world
Data Science Cheatsheets List of Data Science Cheatsheets to rule the world. Table of Contents Business Science Business Science Problem Framework Dat
 11.7k Dec 30, 2022
11.7k Dec 30, 2022

Code for our paper "Multi-scale Guided Attention for Medical Image Segmentation"
Medical Image Segmentation with Guided Attention This repository contains the code of our paper: "'Multi-scale self-guided attention for medical image
 394 Dec 28, 2022
394 Dec 28, 2022

A Kitti Road Segmentation model implemented in tensorflow.
KittiSeg KittiSeg performs segmentation of roads by utilizing an FCN based model. The model achieved first place on the Kitti Road Detection Benchmark
 890 Jan 4, 2023
890 Jan 4, 2023
A combination of autoregressors and autoencoders using XLNet for sentiment analysis
A combination of autoregressors and autoencoders using XLNet for sentiment analysis Abstract In this paper sentiment analysis has been performed in or
 2 Nov 20, 2021
2 Nov 20, 2021

PyTorch implementation of Federated Learning with Non-IID Data, and federated learning algorithms, including FedAvg, FedProx.
Federated Learning with Non-IID Data This is an implementation of the following paper: Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, Vik
 48 Dec 29, 2022
48 Dec 29, 2022
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells.
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells. The project retrains itself after every prediction, making it more robust and generalized over time.
 2 Jul 1, 2022
2 Jul 1, 2022
A package to fetch sentinel 2 Satellite data from Google.
Sentinel 2 Data Fetcher Installation Create a Virtual Environment and activate it. python3 -m venv venv . venv/bin/activate Install the Package via pi
 1 Nov 18, 2021
1 Nov 18, 2021
MVP monorepo to rapidly develop scalable, reliable, high-quality components for Amazon Linux instance configuration management
Ansible Amazon Base Repository Ansible Amazon Base Repository About Setting Up Ansible Environment Configuring Python VENV and Ansible Editor Configur
 1 Aug 6, 2022
1 Aug 6, 2022
Very simple encoding scheme that will encode data as a series of OwOs or UwUs.
OwO Encoder Very simple encoding scheme that will encode data as a series of OwOs or UwUs. The encoder is a simple state machine. Still needs a decode
 1 Nov 15, 2021
1 Nov 15, 2021
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
 3 Jul 5, 2022
3 Jul 5, 2022
Python based framework for Automatic AI for Regression and Classification over numerical data.
Python based framework for Automatic AI for Regression and Classification over numerical data. Performs model search, hyper-parameter tuning, and high-quality Jupyter Notebook code generation.
 141 Dec 21, 2022
141 Dec 21, 2022

Sentiment analysis on streaming twitter data using Spark Structured Streaming & Python
Sentiment analysis on streaming twitter data using Spark Structured Streaming & Python This project is a good starting point for those who have little
 2 Dec 4, 2021
2 Dec 4, 2021

A meta plugin for processing timelapse data timepoint by timepoint in napari
napari-time-slicer A meta plugin for processing timelapse data timepoint by timepoint. It enables a list of napari plugins to process 2D+t or 3D+t dat
 2 Oct 13, 2022
2 Oct 13, 2022
Data and code for the paper "Importance of Kernel Bandwidth in Quantum Machine Learning"
Reproducibility materials for "Importance of Kernel Bandwidth in Quantum Machine Learning" Repo structure: code contains Python scripts used to genera
 3 Oct 23, 2022
3 Oct 23, 2022
Understanding the Generalization Benefit of Model Invariance from a Data Perspective
Understanding the Generalization Benefit of Model Invariance from a Data Perspective This is the code for our NeurIPS2021 paper "Understanding the Gen
 1 Jan 15, 2022
1 Jan 15, 2022

RMTD: Robust Moving Target Defence Against False Data Injection Attacks in Power Grids
RMTD: Robust Moving Target Defence Against False Data Injection Attacks in Power Grids Real-time detection performance. This repo contains the code an
 0 Nov 10, 2021
0 Nov 10, 2021
Important dataframe statistics with a single command
quick_eda Receiving dataframe statistics with one command Project description A python package for Data Scientists, Students, ML Engineers and anyone
 2 Dec 19, 2021
2 Dec 19, 2021
AWS Lambda - Parsing Cloudwatch Data and sending the response via email.
AWS Lambda - Parsing Cloudwatch Data and sending the response via email. Author: Evan Erickson Language: Python Backend: AWS / Serverless / AWS Lambda
 1 Nov 14, 2021
1 Nov 14, 2021

Data Scientist in Simple Stock Analysis of PT Bukalapak.com Tbk for Long Term Investment
Data Scientist in Simple Stock Analysis of PT Bukalapak.com Tbk for Long Term Investment Brief explanation of PT Bukalapak.com Tbk Bukalapak was found
 2 Feb 10, 2022
2 Feb 10, 2022
App to get data from popular polish pages with job offers
Job board parser I written simple app to get me data from popular pages with job offers, because I wanted to knew immidietly if there is some new offe
 0 Jan 4, 2022
0 Jan 4, 2022

Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
 2 Nov 20, 2021
2 Nov 20, 2021
Single machine, multiple cards training; mix-precision training; DALI data loader.
Template Script Category Description Category script comparison script train.py, loader.py for single-machine-multiple-cards training train_DP.py, tra
 2 Jun 27, 2022
2 Jun 27, 2022

 1 Dec 7, 2021
1 Dec 7, 2021
Numerical Analysis toolkit centred around PDEs, for demonstration and understanding purposes not production
Numerics Numerical Analysis toolkit centred around PDEs, for demonstration and understanding purposes not production Use procedure: Initialise a new i
 1 Nov 13, 2021
1 Nov 13, 2021
A Python Covid-19 cases tracker that scrapes data off the web and presents the number of Cases, Recovered Cases, and Deaths that occurred because of the pandemic.
A Python Covid-19 cases tracker that scrapes data off the web and presents the number of Cases, Recovered Cases, and Deaths that occurred because of the pandemic.
 1 Nov 13, 2021
1 Nov 13, 2021
Early version for manipulate Geo localization data trough API REST.
Backend para obtener los datos (beta) Descripción El servidor está diseñado para recibir y almacenar datos enviados en forma de JSON por una aplicació
 1 Nov 14, 2021
1 Nov 14, 2021