2732 Repositories
Python data-series Libraries

level2-data-annotation_cv-level2-cv-15 created by GitHub Classroom
[AI Tech 3기 Level2 P Stage] 글자 검출 대회 팀원 소개 김규리_T3016 박정현_T3094 석진혁_T3109 손정균_T3111 이현진_T3174 임종현_T3182 Overview OCR (Optimal Character Recognition) 기술
 6 Jun 10, 2022
6 Jun 10, 2022
dbt (data build tool) adapter for Oracle Autonomous Database
dbt-oracle version 1.0.0 dbt (data build tool) adapter for the Oracle database. dbt "adapters" are responsible for adapting dbt's functionality to a g
 22 Nov 15, 2022
22 Nov 15, 2022
DeepGNN is a framework for training machine learning models on large scale graph data.
DeepGNN Overview DeepGNN is a framework for training machine learning models on large scale graph data. DeepGNN contains all the necessary features in
 45 Jan 1, 2023
45 Jan 1, 2023
Fluxos de captura e subida de dados no datalake da Prefeitura do Rio de Janeiro.
Pipelines Este repositório contém fluxos de captura e subida de dados no datalake da Prefeitura do Rio de Janeiro. O repositório é gerido pelo Escritó
 19 Dec 15, 2022
19 Dec 15, 2022
Visualization of COVID-19 Omicron wave data in Seoul, Osaka, Tokyo, Hong Kong and Shanghai. 首尔、大阪、东京、香港、上海由新冠病毒 Omicron 变异株引起的本轮疫情数据可视化分析。
COVID-19 in East Asian Megacities This repository holds original Python code for processing and visualization COVID-19 data in East Asian megacities a
 10 May 18, 2022
10 May 18, 2022

Addon and nodes for working with structural biology and molecular data in Blender.
Molecular Nodes 🧬 🔬 💻 Buy Me a Coffee to Keep Development Going! Join a Community of Blender SciVis People! What is Molecular Nodes? Molecular Node
 456 Jan 8, 2023
456 Jan 8, 2023
Helping data scientists better understand their datasets and models in text classification. With love from ServiceNow.
Azimuth, an open-source dataset and error analysis tool for text classification, with love from ServiceNow. Overview Azimuth is an open source applica
 145 Dec 23, 2022
145 Dec 23, 2022
This library is helpful when creating accounts, it has everything you need for this
AccountGeneratorHelper Library to facilitate accounts generation. Unofficial API for temp email services. Receive SMS from free services. Parsing and
 52 Jan 7, 2023
52 Jan 7, 2023

A Flask Sentiment Analysis API, with visual implementation
The Sentiment Analysis Api was created using python flask module,it allows users to parse a text or sentence throught the (?text) arguement, then view the sentiment analysis of that sentence. It can be implementable into a web application.
 10 Jul 17, 2022
10 Jul 17, 2022
It connects to Telegram's API. It generates JSON files containing channel's data, including channel's information and posts.
It connects to Telegram's API. It generates JSON files containing channel's data, including channel's information and posts. You can search for a specific channel, or a set of channels provided in a text file (one channel per line.)
 75 Jan 2, 2023
75 Jan 2, 2023
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets.
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets. It makes dataset creation more effective and helps find essential insights from training results and improves AI performance.
 27 Oct 22, 2022
27 Oct 22, 2022
Data visualization app for H&M competition in kaggle
handm_data_visualize_app Data visualization app by streamlit for H&M competition in kaggle. competition page: https://www.kaggle.com/competitions/h-an
 12 Apr 30, 2022
12 Apr 30, 2022

Snakemake worflow to process and filter long read data from Oxford Nanopore Technologies.
Nanopore-Workflow Snakemake workflow to process and filter long read data from Oxford Nanopore Technologies. It is designed to compare whole human gen
 5 May 13, 2022
5 May 13, 2022

This repository contains the data and code for the paper "Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors" (SPNLP@ACL2022)
GP-VAE This repository provides datasets and code for preprocessing, training and testing models for the paper: Diverse Text Generation via Variationa
 18 Dec 29, 2022
18 Dec 29, 2022

Official repository of the paper Privacy-friendly Synthetic Data for the Development of Face Morphing Attack Detectors
SMDD-Synthetic-Face-Morphing-Attack-Detection-Development-dataset Official repository of the paper Privacy-friendly Synthetic Data for the Development
 10 Dec 12, 2022
10 Dec 12, 2022

scAR (single-cell Ambient Remover) is a package for data denoising in single-cell omics.
scAR scAR (single cell Ambient Remover) is a package for denoising multiple single cell omics data. It can be used for multiple tasks, such as, sgRNA
 19 Nov 28, 2022
19 Nov 28, 2022
This is the data scrapped of all the pitches made up potential startup's to established bussiness tycoons of India with all the details of Investments made, equity share, Name of investor etc.
SharkTankInvestor This is the data scrapped of all the pitches made up potential startup's to established bussiness tycoons of India with all the deta
 2 Aug 2, 2022
2 Aug 2, 2022
Train CNNs for the fruits360 data set in NTOU CS「Machine Vision」class.
CNNs fruits360 Train CNNs for the fruits360 data set in NTOU CS「Machine Vision」class. CNN on a pretrained model Build a CNN on a pretrained model, Res
 1 Mar 7, 2022
1 Mar 7, 2022

This is a Text Data Analysis Project Involving (YouTube Case Study).
Text_Data_Analysis This is a Text Data Analysis Project Involving (YouTube Case Study). Problem Statement = Sentiment Analysis. Package1: There are m
 1 Mar 5, 2022
1 Mar 5, 2022
Implementaion of our ACL 2022 paper Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation This is the implementaion of our paper: Bridging the
 20 Dec 12, 2022
20 Dec 12, 2022
DataAnalysis: Some data analysis projects in charles_pikachu
DataAnalysis DataAnalysis: Some data analysis projects in charles_pikachu You can star this repository to keep track of the project if it's helpful fo
 9 Nov 4, 2022
9 Nov 4, 2022

An algorithmic trading bot that learns and adapts to new data and evolving markets using Financial Python Programming and Machine Learning.
ALgorithmic_Trading_with_ML An algorithmic trading bot that learns and adapts to new data and evolving markets using Financial Python Programming and
 1 Mar 14, 2022
1 Mar 14, 2022
Semantic Data Management - Property Graphs 📈
SDM - Lab 1 @ UPC 👨🏻💻 Table of contents Introduction Property Graph Dataset 1. Introduction This repo is all about what we have done in SDM lab 1
 1 Mar 20, 2022
1 Mar 20, 2022
Code for the Open Data Day 2022 publicbodies.org Nepal data scraping activities.
Open Data Day Publicbodies.org Nepal We've gathered on Saturday, 5th March 2022 with Open Knowledge Nepal in order to try and automate the collection
 2 Mar 12, 2022
2 Mar 12, 2022
Arcpy Tool developed for ArcMap 10.x that checks DVOF points against TDS data and creates an output feature class as well as a check database.
DVOF_check_tool Arcpy Tool developed for ArcMap 10.x that checks DVOF points against TDS data and creates an output feature class as well as a check d
 3 Apr 18, 2022
3 Apr 18, 2022
Scrapping malaysianpaygap & Extracting data from the Instagram posts
Scrapping malaysianpaygap & Extracting data from the posts Recently @malaysianpaygap has gotten quite famous as a platform that enables workers throug
 65 Nov 9, 2022
65 Nov 9, 2022
A series of Python scripts to access measurements from Fluke 28X meters. Fluke IR Remote Interface required.
Fluke289_data_access A series of Python scripts to access measurements from Fluke 28X meters. Fluke IR Remote Interface required. Created from informa
 3 Dec 8, 2022
3 Dec 8, 2022
Linking data between GBIF, Biodiverse, and Open Tree of Life
GBIF-biodiverse-OpenTree Linking data between GBIF, Biodiverse, and Open Tree of Life The python scripts will rely on opentree and Dendropy. To set up
 2 Oct 3, 2022
2 Oct 3, 2022
A Python module to encrypt and decrypt data with AES-128 CFB mode.
cryptocfb A Python module to encrypt and decrypt data with AES-128 CFB mode. This module supports 8/64/128-bit CFB mode. It can encrypt and decrypt la
 2 Sep 23, 2022
2 Sep 23, 2022
LeetComp - Background tasks powering the static content at LeetComp
LeetComp Analysing compensations mentioned on the Leetcode forums (https://kuuts
 125 Dec 21, 2022
125 Dec 21, 2022
Data Structures and Algorithms Python - Practice data structures and algorithms in python with few small projects
Data Structures and Algorithms All the essential resources and template code nee
 13 Dec 1, 2022
13 Dec 1, 2022
WebScraping - Scrapes Job website for python developer jobs and exports the data to a csv file
WebScraping Web scraping Pyton program that scrapes Job website for python devel
 2 Jul 22, 2022
2 Jul 22, 2022

ZeroGen: Efficient Zero-shot Learning via Dataset Generation
ZEROGEN This repository contains the code for our paper “ZeroGen: Efficient Zero
 31 Dec 30, 2022
31 Dec 30, 2022
})
Hl classification bc - A Network-Based High-Level Data Classification Algorithm Using Betweenness Centrality
A Network-Based High-Level Data Classification Algorithm Using Betweenness Centr
 3 Dec 1, 2022
3 Dec 1, 2022
Rootski - Full codebase for rootski.io (without the data)
📣 Welcome to the Rootski codebase! This is the codebase for the application run
 20 Nov 18, 2022
20 Nov 18, 2022

Job-Recommend-Competition - Vectorwise Interpretable Attentions for Multimodal Tabular Data
SiD - Simple Deep Model Vectorwise Interpretable Attentions for Multimodal Tabul
 40 Dec 22, 2022
40 Dec 22, 2022
Comp445 project - Data Communications & Computer Networks
COMP-445 Data Communications & Computer Networks Change Python version in Conda
 2 Oct 3, 2022
2 Oct 3, 2022
Faune proche - Retrieval of Faune-France data near a google maps location
faune_proche Récupération des données de Faune-France près d'un lieu google maps
 4 Feb 15, 2022
4 Feb 15, 2022
LotteryBuyPredictionWebApp - Lottery Purchase Prediction Model
Lottery Purchase Prediction Model Objective and Goal Predict the lottery type th
 2 Feb 14, 2022
2 Feb 14, 2022
Gesture recognition on Event Data
Event based Gesture Recognition Gesture recognition on Event Data usually involv
 2 Feb 14, 2022
2 Feb 14, 2022
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
 2 Feb 14, 2022
2 Feb 14, 2022
Explore-bikeshare-data - GitHub project as part of the Programming for Data Science with Python Nanodegree from Udacity
Date created February 10, 2022 Project Title Explore US Bikeshare Data Descripti
 1 Feb 14, 2022
1 Feb 14, 2022
An arduino/ESP project that can play back G-Force data previously recorded
An arduino/ESP project that can play back G-Force data previously recorded
 7 Apr 12, 2022
7 Apr 12, 2022
The LaTeX and Python code for generating the paper, experiments' results and visualizations reported in each paper is available (whenever possible) in the paper's directory
This repository contains the software implementation of most algorithms used or developed in my research. The LaTeX and Python code for generating the
 3 Jan 3, 2023
3 Jan 3, 2023
Python Create Your Own Tool Series
Python Create Your Own Tool Series Hey there! This is an additional Github repository that contains the final product files for each video in my Youtu
 21 Dec 2, 2022
21 Dec 2, 2022
Skforecast is a python library that eases using scikit-learn regressors as multi-step forecasters
Skforecast is a python library that eases using scikit-learn regressors as multi-step forecasters. It also works with any regressor compatible with the scikit-learn API (pipelines, CatBoost, LightGBM, XGBoost, Ranger...).
 297 Jan 9, 2023
297 Jan 9, 2023
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data"
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data" You can download the pretrained
 3 May 7, 2022
3 May 7, 2022

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022
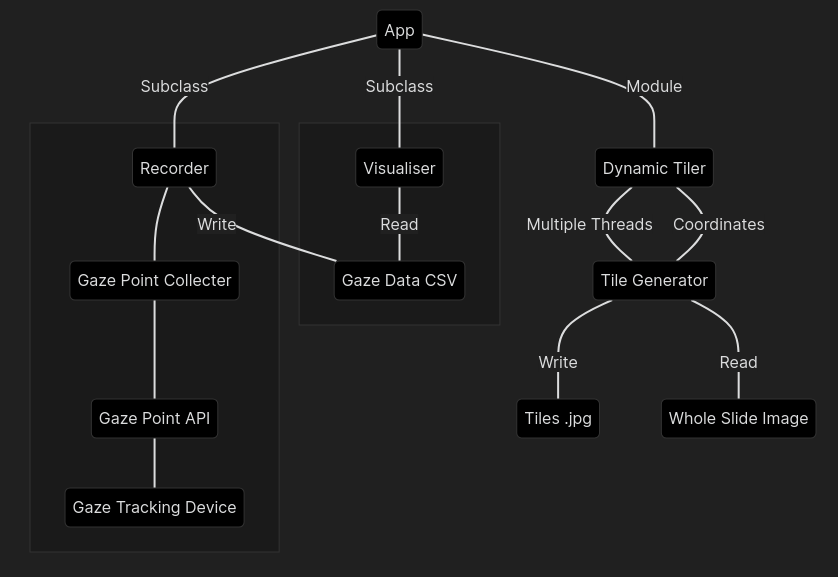
VISNOTATE: An Opensource tool for Gaze-based Annotation of WSI Data
VISNOTATE: An Opensource tool for Gaze-based Annotation of WSI Data Introduction Requirements Installation and Setup Supported Hardware and Software R
 1 Jun 14, 2022
1 Jun 14, 2022

Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track)
Kcse-Data-Analysis Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track) Findings The performance of
 1 Feb 23, 2022
1 Feb 23, 2022
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022
Data science/Analysis Health Care Portfolio
Health-Care-DS-Projects Data Science/Analysis Health Care Portfolio Consists Of 3 Projects: Mexico Covid-19 project, analyze the patient medical histo
 1 Feb 13, 2022
1 Feb 13, 2022

Automatic game data translator for RPGMaker-MV
RPGMaker-MV Translator 🕹️ 🎮 Use AI to translate all the dialogs and texts of your RPGMaker automatically. 👊 You worked hard to make your game, now
 11 Dec 26, 2022
11 Dec 26, 2022
This repository contnains sample problems with test cases using Cormen-Lib
Cormen Lib Sample Problems Description This repository contnains sample problems with test cases using Cormen-Lib. These problems were made for the pu
 3 Jun 30, 2022
3 Jun 30, 2022

This repository contains code from the paper "TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network"
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network This repository contains code from the paper "TTS-GAN: A Transformer-based Tim
 108 Dec 29, 2022
108 Dec 29, 2022
Implementation of ToeplitzLDA for spatiotemporal stationary time series data.
Code for the ToeplitzLDA classifier proposed in here. The classifier conforms sklearn and can be used as a drop-in replacement for other LDA classifiers. For in-depth usage refer to the learning from label proportions (LLP) example or the example script.
 5 Nov 7, 2022
5 Nov 7, 2022
LightGBM + Optuna: no brainer
AutoLGBM LightGBM + Optuna: no brainer auto train lightgbm directly from CSV files auto tune lightgbm using optuna auto serve best lightgbm model usin
 22 Dec 15, 2022
22 Dec 15, 2022

An Optical Character Recognition system using Pytesseract/Extracting data from Blood Pressure Reports.
Optical_Character_Recognition An Optical Character Recognition system using Pytesseract/Extracting data from Blood Pressure Reports. As an IOT/Compute
 1 Feb 12, 2022
1 Feb 12, 2022
This repository has a implementations of data augmentation for NLP for Japanese.
daaja This repository has a implementations of data augmentation for NLP for Japanese: EDA: Easy Data Augmentation Techniques for Boosting Performance
 60 Nov 11, 2022
60 Nov 11, 2022

MoCap-Solver: A Neural Solver for Optical Motion Capture Data
MoCap-Solver is a data-driven-based robust marker denoising method, which takes raw mocap markers as input and outputs corresponding clean markers and skeleton motions.
 55 Dec 28, 2022
55 Dec 28, 2022

Image-to-image regression with uncertainty quantification in PyTorch
Image-to-image regression with uncertainty quantification in PyTorch. Take any dataset and train a model to regress images to images with rigorous, distribution-free uncertainty quantification.
 25 Dec 26, 2022
25 Dec 26, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022
Supplementary Data for Evolving Reinforcement Learning Algorithms
evolvingrl Supplementary Data for Evolving Reinforcement Learning Algorithms This dataset contains 1000 loss graphs from two experiments: 500 unique g
 42 Sep 21, 2022
42 Sep 21, 2022
Course materials for Fall 2021 "CIS6930 Topics in Computing for Data Science" at New College of Florida
Fall 2021 CIS6930 Topics in Computing for Data Science This repository hosts course materials used for a 13-week course "CIS6930 Topics in Computing f
 101 Nov 30, 2022
101 Nov 30, 2022
Customizing Visual Styles in Plotly
Customizing Visual Styles in Plotly Code for a workshop originally developed for an Unconference session during the Outlier Conference hosted by Data
 9 Aug 3, 2022
9 Aug 3, 2022
NCAR/UCAR virtual Python Tutorial Seminar Series lesson on MetPy.
The Project Pythia Python Tutorial Seminar Series continues with a lesson on MetPy on Wednesday, 2 February 2022 at 1 PM Mountain Standard Time.
 6 Oct 9, 2022
6 Oct 9, 2022

Geospatial data-science analysis on reasons behind delay in Grab ride-share services
Grab x Pulis Detailed analysis done to investigate possible reasons for delay in Grab services for NUS Data Analytics Competition 2022, to be found in
 6 Jun 7, 2022
6 Jun 7, 2022

metedraw is a project mainly for data visualization projects of Atmospheric Science, Marine Science, Environmental Science or other majors
It is mainly for data visualization projects of Atmospheric Science, Marine Science, Environmental Science or other majors.
 11 Jul 5, 2022
11 Jul 5, 2022

OpenStats is a library built on top of streamlit that extracts data from the Github API and shows the main KPIs
Open Stats Discover and share the KPIs of your OpenSource project. OpenStats is a library built on top of streamlit that extracts data from the Github
 4 Apr 3, 2022
4 Apr 3, 2022

A research of IT labor market based especially on hh.ru. Salaries, rate of technologies and etc.
hh_ru_research Проект реализован в учебных целях анализа рынка труда, в особенности по hh.ru Input data В качестве входных данных используются сериали
 3 Sep 7, 2022
3 Sep 7, 2022

To build a regression model to predict the concrete compressive strength based on the different features in the training data.
Cement-Strength-Prediction Problem Statement To build a regression model to predict the concrete compressive strength based on the different features
 4 Jun 11, 2022
4 Jun 11, 2022
A Python implementation of red-black trees
Python red-black trees A Python implementation of red-black trees. This code was originally copied from programiz.com, but I have made a few tweaks to
 7 Oct 20, 2022
7 Oct 20, 2022
Contains a Jupyter Notebook for calculating remaining plants required based on field/lathhouse data.
Davis-Sunflowers-Su21 Project goals: Plants influence their reproduction and mating system in many ways. Various factors such as time of flowering, ab
 1 Feb 10, 2022
1 Feb 10, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Implementation of SOMs (Self-Organizing Maps) with neighborhood-based map topologies.
py-self-organizing-maps Simple implementation of self-organizing maps (SOMs) A SOM is an unsupervised method for learning a mapping from a discrete ne
 6 Nov 22, 2022
6 Nov 22, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022
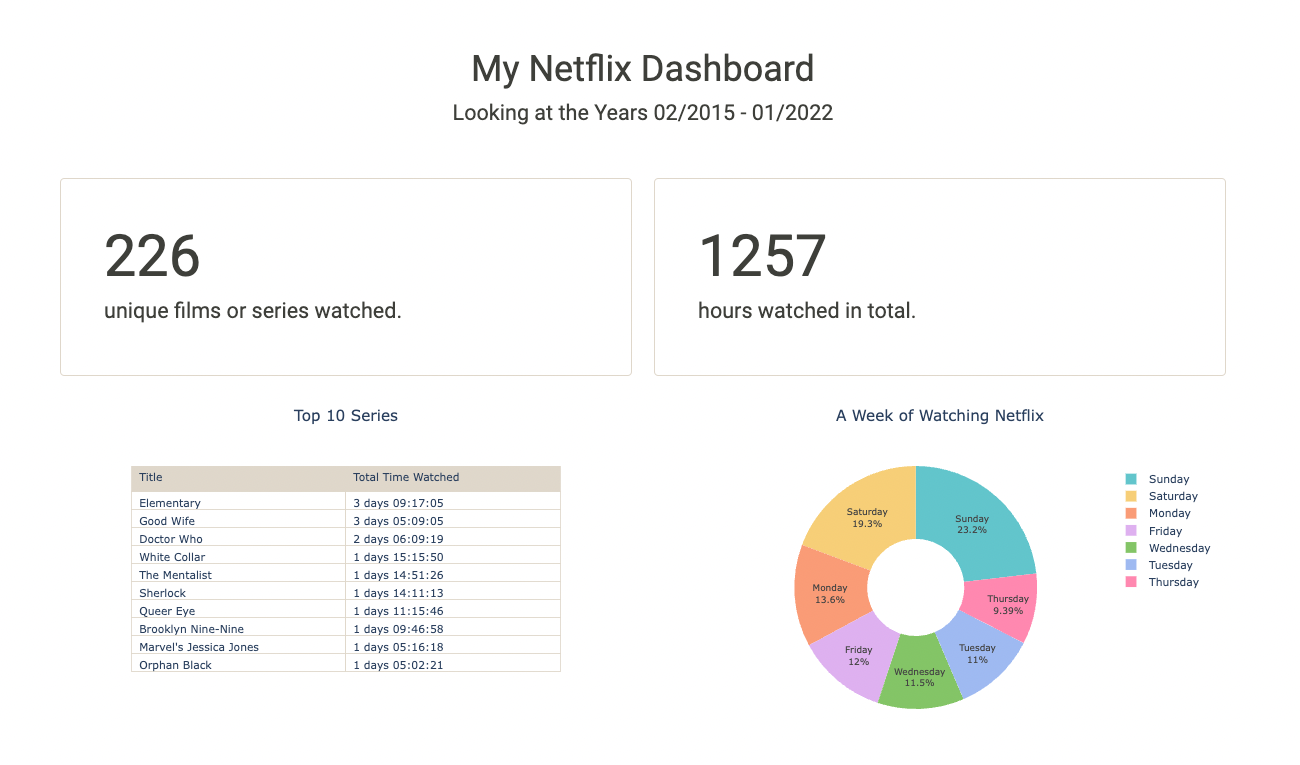
Project: Netflix Data Analysis and Visualization with Python
Project: Netflix Data Analysis and Visualization with Python Table of Contents General Info Installation Demo Usage and Main Functionalities Contribut
 2 Feb 13, 2022
2 Feb 13, 2022
PLStream: A Framework for Fast Polarity Labelling of Massive Data Streams
PLStream: A Framework for Fast Polarity Labelling of Massive Data Streams Motivation When dataset freshness is critical, the annotating of high speed
 4 Aug 2, 2022
4 Aug 2, 2022
A tool to find good RCE From my series: A powerful Burp extension to make bounties rain
A tool to find good RCE From my series: A powerful Burp extension to make bounties rain
 52 Dec 16, 2022
52 Dec 16, 2022

This project uses ViT to perform image classification tasks on DATA set CIFAR10.
Vision-Transformer-Multiprocess-DistributedDataParallel-Apex Introduction This project uses ViT to perform image classification tasks on DATA set CIFA
 3 Jun 3, 2022
3 Jun 3, 2022

CLASSIX is a fast and explainable clustering algorithm based on sorting
CLASSIX Fast and explainable clustering based on sorting CLASSIX is a fast and explainable clustering algorithm based on sorting. Here are a few highl
 69 Jan 6, 2023
69 Jan 6, 2023
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023
Geowifi 📡 💘 🌎 Search WiFi geolocation data by BSSID and SSID on different public databases.
Geowifi 📡 💘 🌎 Search WiFi geolocation data by BSSID and SSID on different public databases.
 441 Dec 23, 2022
441 Dec 23, 2022

Python code to fuse multiple RGB-D images into a TSDF voxel volume.
Volumetric TSDF Fusion of RGB-D Images in Python This is a lightweight python script that fuses multiple registered color and depth images into a proj
 845 Jan 3, 2023
845 Jan 3, 2023

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022

Interactive Dashboard for Visualizing OSM Data Change
Dashboard and intuitive data downloader for more interactive experience with interpreting osm change data.
 1 Feb 20, 2022
1 Feb 20, 2022
Data Analysis: Data Visualization of Airlines
Data Analysis: Data Visualization of Airlines Anderson Cruz | London-UK | Linkedin | Nowa Capital Project: Traffic Airlines Airline Reporting Carrier
 1 Feb 10, 2022
1 Feb 10, 2022
This program will help you to properly scrape all data from a specific website
This program will help you to properly scrape all data from a specific website
 0 May 15, 2022
0 May 15, 2022

Extract GoPro highlights and GPMF data.
Python script that parses the gpmd stream for GOPRO moov track (MP4) and extract the GPS info into a GPX (and kml) file.
 2 May 13, 2022
2 May 13, 2022
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
 3 Nov 15, 2022
3 Nov 15, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022
Python package for concise, transparent, and accurate predictive modeling
Python package for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use. 📚 docs • 📖 demo notebooks Modern
 983 Jan 1, 2023
983 Jan 1, 2023
Nested cross-validation is necessary to avoid biased model performance in embedded feature selection in high-dimensional data with tiny sample sizes
Pruner for nested cross-validation - Sphinx-Doc Nested cross-validation is necessary to avoid biased model performance in embedded feature selection i
 1 Dec 15, 2021
1 Dec 15, 2021
Data and code accompanying the paper Politics and Virality in the Time of Twitter
Politics and Virality in the Time of Twitter Data and code accompanying the paper Politics and Virality in the Time of Twitter. In specific: the code
 3 Jul 2, 2022
3 Jul 2, 2022

Image Data Augmentation in Keras
Image data augmentation is a technique that can be used to artificially expand the size of a training dataset by creating modified versions of images in the dataset.
 3 Feb 15, 2022
3 Feb 15, 2022

Data Augmentation Using Keras and Python
Data-Augmentation-Using-Keras-and-Python Data augmentation is the process of increasing the number of training dataset. Keras library offers a simple
 3 Feb 15, 2022
3 Feb 15, 2022
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python An easy-to-follow comprehensive guide on integrating Amazon RDS, MySQL Workbe
 6 Aug 17, 2022
6 Aug 17, 2022
Structured Data Gradient Pruning (SDGP)
Structured Data Gradient Pruning (SDGP) Weight pruning is a technique to make Deep Neural Network (DNN) inference more computationally efficient by re
 10 Nov 11, 2022
10 Nov 11, 2022

LinkScope allows you to perform online investigations by representing information as discrete pieces of data, called Entities.
LinkScope Client Description This is the repository for the LinkScope Client Online Investigation software. LinkScope allows you to perform online inv
 108 Jan 4, 2023
108 Jan 4, 2023

N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting Recent progress in neural forecasting instigated significant improvements in the
 82 Jan 4, 2023
82 Jan 4, 2023