803 Repositories
Python fast-bert Libraries
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
An implementation of WaveNet with fast generation
pytorch-wavenet This is an implementation of the WaveNet architecture, as described in the original paper. Features Automatic creation of a dataset (t
 858 Dec 27, 2022
858 Dec 27, 2022
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022

QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
 152 Jan 2, 2023
152 Jan 2, 2023
An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models.
DeepNER An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models. This repository contains complex Deep
 9 May 30, 2022
9 May 30, 2022
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
152 Jan 2, 2023
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
 2.5k Jan 3, 2023
2.5k Jan 3, 2023

 387 Jan 4, 2023
387 Jan 4, 2023
Implementation of "Fast and Flexible Temporal Point Processes with Triangular Maps" (Oral @ NeurIPS 2020)
Fast and Flexible Temporal Point Processes with Triangular Maps This repository includes a reference implementation of the algorithms described in "Fa
 20 Dec 2, 2022
20 Dec 2, 2022
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
 15k Jan 2, 2023
15k Jan 2, 2023
Code for the paper "Improving Vision-and-Language Navigation with Image-Text Pairs from the Web" (ECCV 2020)
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh
 44 Dec 14, 2022
44 Dec 14, 2022
The official implementation of our CVPR 2021 paper - Hybrid Rotation Averaging: A Fast and Robust Rotation Averaging Approach
Graph Optimizer This repo contains the official implementation of our CVPR 2021 paper - Hybrid Rotation Averaging: A Fast and Robust Rotation Averagin
 109 Dec 23, 2022
109 Dec 23, 2022

A simple python library for fast image generation of people who do not exist.
Random Face A simple python library for fast image generation of people who do not exist. For more details, please refer to the [paper](https://arxiv.
 170 Dec 15, 2022
170 Dec 15, 2022
Pytorch version of BERT-whitening
BERT-whitening This is the Pytorch implementation of "Whitening Sentence Representations for Better Semantics and Faster Retrieval". BERT-whitening is
 255 Dec 27, 2022
255 Dec 27, 2022
Simple, fast, and parallelized symbolic regression in Python/Julia via regularized evolution and simulated annealing
Parallelized symbolic regression built on Julia, and interfaced by Python. Uses regularized evolution, simulated annealing, and gradient-free optimization.
 924 Jan 3, 2023
924 Jan 3, 2023
Weakly supervised medical named entity classification
Trove Trove is a research framework for building weakly supervised (bio)medical named entity recognition (NER) and other entity attribute classifiers
 60 Nov 18, 2022
60 Nov 18, 2022

Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch.
Faster R-CNN and Mask R-CNN in PyTorch 1.0 maskrcnn-benchmark has been deprecated. Please see detectron2, which includes implementations for all model
 9k Jan 4, 2023
9k Jan 4, 2023

Python library containing BART query generation and BERT-based Siamese models for neural retrieval.
Neural Retrieval Embedding-based Zero-shot Retrieval through Query Generation leverages query synthesis over large corpuses of unlabeled text (such as
 35 Apr 14, 2022
35 Apr 14, 2022

I-BERT: Integer-only BERT Quantization
I-BERT: Integer-only BERT Quantization HuggingFace Implementation I-BERT is also available in the master branch of HuggingFace! Visit the following li
 139 Dec 27, 2022
139 Dec 27, 2022
A fast python implementation of the SimHash algorithm.
This Python package provides hashing algorithms for computing cohort ids of users based on their browsing history. As such, it may be used to compute cohort ids of users following Google's Federated Learning of Cohorts (FLoC) proposal.
 19 Dec 15, 2022
19 Dec 15, 2022
A fast and easy implementation of Transformer with PyTorch.
FasySeq FasySeq is a shorthand as a Fast and easy sequential modeling toolkit. It aims to provide a seq2seq model to researchers and developers, which
 7 Jul 18, 2022
7 Jul 18, 2022
Django Ninja - Fast Django REST Framework
Django Ninja is a web framework for building APIs with Django and Python 3.6+ type hints.
 3.8k Jan 2, 2023
3.8k Jan 2, 2023
Python bindings to libpostal for fast international address parsing/normalization
pypostal These are the official Python bindings to https://github.com/openvenues/libpostal, a fast statistical parser/normalizer for street addresses
 651 Dec 16, 2022
651 Dec 16, 2022
Pandas Network Analysis: fast accessibility metrics and shortest paths, using contraction hierarchies :world_map:
Pandana Pandana is a Python library for network analysis that uses contraction hierarchies to calculate super-fast travel accessibility metrics and sh
 321 Jan 5, 2023
321 Jan 5, 2023

Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
Code for pre-training CharacterBERT models (as well as BERT models).
Pre-training CharacterBERT (and BERT) This is a repository for pre-training BERT and CharacterBERT. DISCLAIMER: The code was largely adapted from an o
 31 Dec 5, 2022
31 Dec 5, 2022

Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT CheXbert is an accurate, automated dee
 51 Dec 8, 2022
51 Dec 8, 2022

STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech Keon Lee, Ky
 114 Dec 12, 2022
114 Dec 12, 2022

Transformer related optimization, including BERT, GPT
This repository provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
 1.7k Jan 4, 2023
1.7k Jan 4, 2023
Adversarial Adaptation with Distillation for BERT Unsupervised Domain Adaptation
Knowledge Distillation for BERT Unsupervised Domain Adaptation Official PyTorch implementation | Paper Abstract A pre-trained language model, BERT, ha
 29 Nov 30, 2022
29 Nov 30, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
The deployment framework aims to provide a simple, lightweight, fast integrated, pipelined deployment framework that ensures reliability, high concurrency and scalability of services.
savior是一个能够进行快速集成算法模块并支持高性能部署的轻量开发框架。能够帮助将团队进行快速想法验证(PoC),避免重复的去github上找模型然后复现模型;能够帮助团队将功能进行流程拆解,很方便的提高分布式执行效率;能够有效减少代码冗余,减少不必要负担。
 125 Dec 22, 2022
125 Dec 22, 2022

Screaming-fast Python 3.5+ HTTP toolkit integrated with pipelining HTTP server based on uvloop and picohttpparser.
Screaming-fast Python 3.5+ HTTP toolkit integrated with pipelining HTTP server based on uvloop and picohttpparser.
 8.6k Jan 4, 2023
8.6k Jan 4, 2023
A fast and durable Pub/Sub channel over Websockets. FastAPI + WebSockets + PubSub == ⚡ 💪 ❤️
⚡ 🗞️ FastAPI Websocket Pub/Sub A fast and durable Pub/Sub channel over Websockets. The easiest way to create a live publish / subscribe multi-cast ov
 8 Dec 6, 2022
8 Dec 6, 2022
MashaRobot : New Generation Telegram Group Manager Bot (🔸Fast 🔸Python🔸Pyrogram 🔸Telethon 🔸Mongo db )
MashaRobot Me On Telegram ✨ MASHA ✨ This is just a demo bot.. Don't try to add to your group.. Create your own bot How To Host The easiest way to depl
 40 Oct 9, 2022
40 Oct 9, 2022
Sensitivity Analysis Library in Python (Numpy). Contains Sobol, Morris, Fractional Factorial and FAST methods.
Sensitivity Analysis Library (SALib) Python implementations of commonly used sensitivity analysis methods. Useful in systems modeling to calculate the
 663 Jan 5, 2023
663 Jan 5, 2023
Fast, flexible and easy to use probabilistic modelling in Python.
Please consider citing the JMLR-MLOSS Manuscript if you've used pomegranate in your academic work! pomegranate is a package for building probabilistic
 3k Jan 2, 2023
3k Jan 2, 2023
Fast solver for L1-type problems: Lasso, sparse Logisitic regression, Group Lasso, weighted Lasso, Multitask Lasso, etc.
celer Fast algorithm to solve Lasso-like problems with dual extrapolation. Currently, the package handles the following problems: Lasso weighted Lasso
 168 Dec 13, 2022
168 Dec 13, 2022
An optimizer that trains as fast as Adam and as good as SGD.
AdaBound An optimizer that trains as fast as Adam and as good as SGD, for developing state-of-the-art deep learning models on a wide variety of popula
 2.9k Dec 27, 2022
2.9k Dec 27, 2022

Fast, general, and tested differentiable structured prediction in PyTorch
Torch-Struct: Structured Prediction Library A library of tested, GPU implementations of core structured prediction algorithms for deep learning applic
 1.1k Jan 7, 2023
1.1k Jan 7, 2023
PyTorch extensions for fast R&D prototyping and Kaggle farming
Pytorch-toolbelt A pytorch-toolbelt is a Python library with a set of bells and whistles for PyTorch for fast R&D prototyping and Kaggle farming: What
 1.3k Jan 5, 2023
1.3k Jan 5, 2023
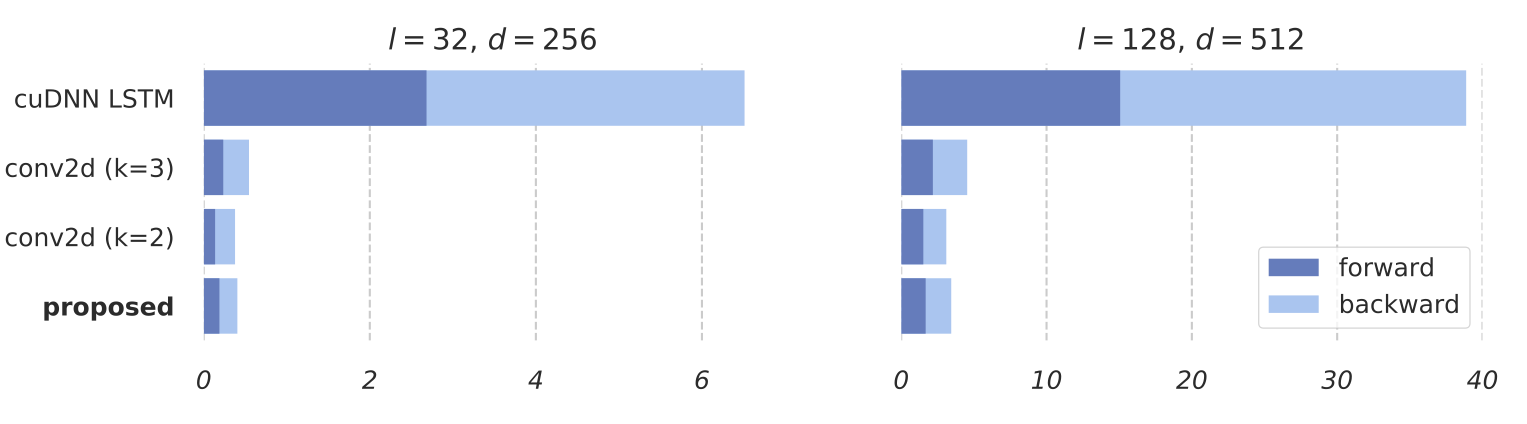
Training RNNs as Fast as CNNs (https://arxiv.org/abs/1709.02755)
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023

General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and optimized for advanced GPU data processing usecases.
Vulkan Kompute The general purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabl
 1k Dec 26, 2022
1k Dec 26, 2022

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
4.2k Jan 8, 2023

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 5, 2023
399 Jan 5, 2023
TextBoxes: A Fast Text Detector with a Single Deep Neural Network https://github.com/MhLiao/TextBoxes 基于SSD改进的文本检测算法,textBoxes_note记录了之前整理的笔记。
TextBoxes: A Fast Text Detector with a Single Deep Neural Network Introduction This paper presents an end-to-end trainable fast scene text detector, n
 24 Apr 28, 2022
24 Apr 28, 2022

TensorFlow Implementation of FOTS, Fast Oriented Text Spotting with a Unified Network.
FOTS: Fast Oriented Text Spotting with a Unified Network I am still working on this repo. updates and detailed instructions are coming soon! Table of
 52 Nov 11, 2022
52 Nov 11, 2022
An Implementation of the FOTS: Fast Oriented Text Spotting with a Unified Network
FOTS: Fast Oriented Text Spotting with a Unified Network Introduction This is a pytorch re-implementation of FOTS: Fast Oriented Text Spotting with a
 171 Aug 4, 2022
171 Aug 4, 2022
Lightning Fast Language Prediction 🚀
whatthelang Lightning Fast Language Prediction 🚀 Dependencies The dependencies can be installed using the requirements.txt file: $ pip install -r req
 152 Oct 16, 2022
152 Oct 16, 2022
Modular, cohesive, transparent and fast web server template
kingdom-python-server 🐍 Modular, transparent, batteries (half) included, lightning fast web server. Features a functional, isolated business layer wi
 20 Feb 8, 2022
20 Feb 8, 2022

Komodo Edit is a fast and free multi-language code editor. Written in JS, Python, C++ and based on the Mozilla platform.
Komodo Edit This readme explains how to get started building, using and developing with the Komodo Edit source base. Whilst the main Komodo Edit sourc
 2k Dec 28, 2022
2k Dec 28, 2022
OpenMMLab Detection Toolbox and Benchmark
MMDetection is an open source object detection toolbox based on PyTorch. It is a part of the OpenMMLab project.
 22.5k Jan 5, 2023
22.5k Jan 5, 2023
Implementation of "Slow-Fast Auditory Streams for Audio Recognition, ICASSP, 2021" in PyTorch
Auditory Slow-Fast This repository implements the model proposed in the paper: Evangelos Kazakos, Arsha Nagrani, Andrew Zisserman, Dima Damen, Slow-Fa
 57 Dec 7, 2022
57 Dec 7, 2022

CUAD
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
 273 Dec 17, 2022
273 Dec 17, 2022
cysimdjson - Very fast Python JSON parsing library
Fast JSON parsing library for Python, 7-12 times faster than standard Python JSON parser.
 235 Dec 29, 2022
235 Dec 29, 2022

FLAVR is a fast, flow-free frame interpolation method capable of single shot multi-frame prediction
FLAVR is a fast, flow-free frame interpolation method capable of single shot multi-frame prediction. It uses a customized encoder decoder architecture with spatio-temporal convolutions and channel gating to capture and interpolate complex motion trajectories between frames to generate realistic high frame rate videos. This repository contains original source code for the paper accepted to CVPR 2021.
 280 Dec 23, 2022
280 Dec 23, 2022
gunicorn 'Green Unicorn' is a WSGI HTTP Server for UNIX, fast clients and sleepy applications.
Gunicorn Gunicorn 'Green Unicorn' is a Python WSGI HTTP Server for UNIX. It's a pre-fork worker model ported from Ruby's Unicorn project. The Gunicorn
 8.7k Jan 8, 2023
8.7k Jan 8, 2023
Functional TensorFlow Implementation of Singular Value Decomposition for paper Fast Graph Learning
tf-fsvd TensorFlow Implementation of Functional Singular Value Decomposition for paper Fast Graph Learning with Unique Optimal Solutions Cite If you f
 14 Nov 25, 2021
14 Nov 25, 2021
Contract Understanding Atticus Dataset
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
273 Dec 17, 2022

DeFMO: Deblurring and Shape Recovery of Fast Moving Objects (CVPR 2021)
Evaluation, Training, Demo, and Inference of DeFMO DeFMO: Deblurring and Shape Recovery of Fast Moving Objects (CVPR 2021) Denys Rozumnyi, Martin R. O
 139 Dec 26, 2022
139 Dec 26, 2022
Minimalist BERT implementation assignment for CS11-747
minbert Assignment by Zhengbao Jiang, Shuyan Zhou, and Ritam Dutt This is an exercise in developing a minimalist version of BERT, part of Carnegie Mel
 51 Jan 3, 2023
51 Jan 3, 2023

本项目是作者们根据个人面试和经验总结出的自然语言处理(NLP)面试准备的学习笔记与资料,该资料目前包含 自然语言处理各领域的 面试题积累。
【关于 NLP】那些你不知道的事 作者:杨夕、芙蕖、李玲、陈海顺、twilight、LeoLRH、JimmyDU、艾春辉、张永泰、金金金 介绍 本项目是作者们根据个人面试和经验总结出的自然语言处理(NLP)面试准备的学习笔记与资料,该资料目前包含 自然语言处理各领域的 面试题积累。 目录架构 一、【
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
Code associated with the "Data Augmentation using Pre-trained Transformer Models" paper
Data Augmentation using Pre-trained Transformer Models Code associated with the Data Augmentation using Pre-trained Transformer Models paper Code cont
 44 Dec 31, 2022
44 Dec 31, 2022
Fast image augmentation library and easy to use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about library: https://www.mdpi.com/2078-2489/11/2/125
Albumentations Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to inc
 11.4k Jan 2, 2023
11.4k Jan 2, 2023
A Genetic Programming platform for Python with TensorFlow for wicked-fast CPU and GPU support.
Karoo GP Karoo GP is an evolutionary algorithm, a genetic programming application suite written in Python which supports both symbolic regression and
 149 Jan 9, 2023
149 Jan 9, 2023
Dopamine is a research framework for fast prototyping of reinforcement learning algorithms.
Dopamine Dopamine is a research framework for fast prototyping of reinforcement learning algorithms. It aims to fill the need for a small, easily grok
 10k Jan 7, 2023
10k Jan 7, 2023
A fast xgboost feature selection algorithm
BoostARoota A Fast XGBoost Feature Selection Algorithm (plus other sklearn tree-based classifiers) Why Create Another Algorithm? Automated processes l
 187 Dec 22, 2022
187 Dec 22, 2022
Deploy tensorflow graphs for fast evaluation and export to tensorflow-less environments running numpy.
Deploy tensorflow graphs for fast evaluation and export to tensorflow-less environments running numpy. Now with tensorflow 1.0 support. Evaluation usa
 349 Aug 6, 2022
349 Aug 6, 2022
ThunderGBM: Fast GBDTs and Random Forests on GPUs
Documentations | Installation | Parameters | Python (scikit-learn) interface What's new? ThunderGBM won 2019 Best Paper Award from IEEE Transactions o
 648 Dec 16, 2022
648 Dec 16, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 7, 2023
14.5k Jan 7, 2023
ThunderSVM: A Fast SVM Library on GPUs and CPUs
What's new We have recently released ThunderGBM, a fast GBDT and Random Forest library on GPUs. add scikit-learn interface, see here Overview The miss
1.4k Dec 22, 2022
High performance implementation of Extreme Learning Machines (fast randomized neural networks).
High Performance toolbox for Extreme Learning Machines. Extreme learning machines (ELM) are a particular kind of Artificial Neural Networks, which sol
 174 Dec 7, 2022
174 Dec 7, 2022
A Fast Broken Link Hijacker Tool written in Python
Broken Link Hijacker BrokenLinkHijacker(BLH) is a Fast Broken Link Hijacker Tool written in Python.
 70 Nov 30, 2022
70 Nov 30, 2022
A fast MoE impl for PyTorch
An easy-to-use and efficient system to support the Mixture of Experts (MoE) model for PyTorch.
 873 Jan 9, 2023
873 Jan 9, 2023

msgspec is a fast and friendly implementation of the MessagePack protocol for Python 3.8+
msgspec msgspec is a fast and friendly implementation of the MessagePack protocol for Python 3.8+. In addition to serialization/deserializat
 414 Jan 6, 2023
414 Jan 6, 2023
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
LightSpeech UnOfficial PyTorch implementation of LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search.
 54 Dec 3, 2022
54 Dec 3, 2022
A free & open modern, fast email client with user-friendly encryption and privacy features
Welcome to Mailpile! Introduction Mailpile (https://www.mailpile.is/) is a modern, fast web-mail client with user-friendly encryption and privacy feat
 8.7k Jan 4, 2023
8.7k Jan 4, 2023
Publish Xarray Datasets via a REST API.
Xpublish Publish Xarray Datasets via a REST API. Serverside: Publish a Xarray Dataset through a rest API ds.rest.serve(host="0.0.0.0", port=9000) Clie
 106 Jan 6, 2023
106 Jan 6, 2023
[rewrite 중] 코로나바이러스감염증-19(COVID-19)의 국내/국외 발생 동향 조회 API | Coronavirus Infectious Disease-19 (COVID-19) outbreak trend inquiry API
COVID-19API 코로나 바이러스 감염증-19(COVID-19, SARS-CoV-2)의 국내/외 발생 동향 조회 API Corona Virus Infectious Disease-19 (COVID-19, SARS-CoV-2) outbreak trend inquiry
 28 Oct 29, 2022
28 Oct 29, 2022
An ultra fast cross-platform multiple screenshots module in pure Python using ctypes.
Python MSS from mss import mss # The simplest use, save a screen shot of the 1st monitor with mss() as sct: sct.shot() An ultra fast cross-platfo
 799 Dec 30, 2022
799 Dec 30, 2022

NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
 184 Feb 10, 2021
184 Feb 10, 2021
Kashgari is a production-level NLP Transfer learning framework built on top of tf.keras for text-labeling and text-classification, includes Word2Vec, BERT, and GPT2 Language Embedding.
Kashgari Overview | Performance | Installation | Documentation | Contributing 🎉 🎉 🎉 We released the 2.0.0 version with TF2 Support. 🎉 🎉 🎉 If you
 2k Feb 9, 2021
2k Feb 9, 2021
:house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering.
(Framework for Adapting Representation Models) What is it? FARM makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built u
 1.1k Feb 14, 2021
1.1k Feb 14, 2021
Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow. This is part of the CASL project: http://casl-project.ai/
Texar is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar provides
 2.1k Feb 17, 2021
2.1k Feb 17, 2021
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.6k Feb 18, 2021
2.6k Feb 18, 2021

Super easy library for BERT based NLP models
Fast-Bert New - Learning Rate Finder for Text Classification Training (borrowed with thanks from https://github.com/davidtvs/pytorch-lr-finder) Suppor
 1.5k Feb 18, 2021
1.5k Feb 18, 2021
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
 903 Feb 17, 2021
903 Feb 17, 2021
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
2.2k Feb 18, 2021
:mag: End-to-End Framework for building natural language search interfaces to data by utilizing Transformers and the State-of-the-Art of NLP. Supporting DPR, Elasticsearch, HuggingFace’s Modelhub and much more!
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
1.4k Feb 18, 2021
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
 4.2k Feb 18, 2021
4.2k Feb 18, 2021
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production
Provides an implementation of today's most used tokenizers, with a focus on performance and versatility. Main features: Train new vocabularies and tok
4.3k Feb 18, 2021
Library for fast text representation and classification.
fastText fastText is a library for efficient learning of word representations and sentence classification. Table of contents Resources Models Suppleme
22.2k Feb 18, 2021
🤗Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0 🤗 Transformers provides thousands of pretrained models to perform tasks o
40.9k Feb 18, 2021
nptsne is a numpy compatible python binary package that offers a number of APIs for fast tSNE calculation.
nptsne nptsne is a numpy compatible python binary package that offers a number of APIs for fast tSNE calculation and HSNE modelling. For more detail s
 24 Feb 3, 2021
24 Feb 3, 2021
Fast data visualization and GUI tools for scientific / engineering applications
PyQtGraph A pure-Python graphics library for PyQt5/PyQt6/PySide2/PySide6 Copyright 2020 Luke Campagnola, University of North Carolina at Chapel Hill h
 2.3k Feb 17, 2021
2.3k Feb 17, 2021
Pyroomacoustics is a package for audio signal processing for indoor applications. It was developed as a fast prototyping platform for beamforming algorithms in indoor scenarios.
Summary Pyroomacoustics is a software package aimed at the rapid development and testing of audio array processing algorithms. The content of the pack
 1k Jan 9, 2023
1k Jan 9, 2023
A fast MDCT implementation using SciPy and FFTs
MDCT A fast MDCT implementation using SciPy and FFTs Installation As usual pip install mdct Dependencies NumPy SciPy STFT Usage import mdct spectrum
 43 Sep 2, 2022
43 Sep 2, 2022