366 Repositories
Python hard-example-mining Libraries
Code and models used in "MUSS Multilingual Unsupervised Sentence Simplification by Mining Paraphrases".
Multilingual Unsupervised Sentence Simplification Code and pretrained models to reproduce experiments in "MUSS: Multilingual Unsupervised Sentence Sim
 81 Dec 29, 2022
81 Dec 29, 2022
A repo that contains all the mesh keys needed for mesh backend, along with a code example of how to use them in python
Mesh-Keys A repo that contains all the mesh keys needed for mesh backend, along with a code example of how to use them in python Have been seeing alot
 53 Dec 13, 2022
53 Dec 13, 2022
Source code for the Paper: CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints}
CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints Installation Run pipenv install (at your own risk with --skip-lo
 65 Dec 27, 2022
65 Dec 27, 2022

Quick example of a todo list application using Django and HTMX
django-htmx-todo-list Quick example of a todo list application using Django and HTMX Background Modified & expanded from https://github.com/jaredlockh
 54 Dec 10, 2022
54 Dec 10, 2022
Packages of Example Data for The Effect
causaldata This repository will contain R, Stata, and Python packages, all called causaldata, which contain data sets that can be used to implement th
 103 Dec 24, 2022
103 Dec 24, 2022
DC3: A Learning Method for Optimization with Hard Constraints
DC3: A learning method for optimization with hard constraints This repository is by Priya L. Donti, David Rolnick, and J. Zico Kolter and contains the
 57 Dec 26, 2022
57 Dec 26, 2022

Instant Real-Time Example-Based Style Transfer to Facial Videos
FaceBlit: Instant Real-Time Example-Based Style Transfer to Facial Videos The official implementation of FaceBlit: Instant Real-Time Example-Based Sty
 131 Dec 19, 2022
131 Dec 19, 2022
🏅 The Most Comprehensive List of Kaggle Solutions and Ideas 🏅
🏅 Collection of Kaggle Solutions and Ideas 🏅
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
Automated Phrase Mining from Massive Text Corpora in Python.
Automated Phrase Mining from Massive Text Corpora in Python.
 28 Apr 15, 2021
28 Apr 15, 2021

Algorithmic trading using machine learning.
Algorithmic Trading This machine learning algorithm was built using Python 3 and scikit-learn with a Decision Tree Classifier. The program gathers sto
 101 Nov 10, 2022
101 Nov 10, 2022
Polyglot Machine Learning example for scraping similar news articles.
Polyglot Machine Learning example for scraping similar news articles In this example, we will see how we can work with Machine Learning applications w
 15 Mar 28, 2022
15 Mar 28, 2022
The (Python-based) mining software required for the Game Boy mining project.
ntgbtminer - Game Boy edition This is a version of ntgbtminer that works with the Game Boy bitcoin miner. ntgbtminer ntgbtminer is a no thrills getblo
 31 Nov 4, 2022
31 Nov 4, 2022
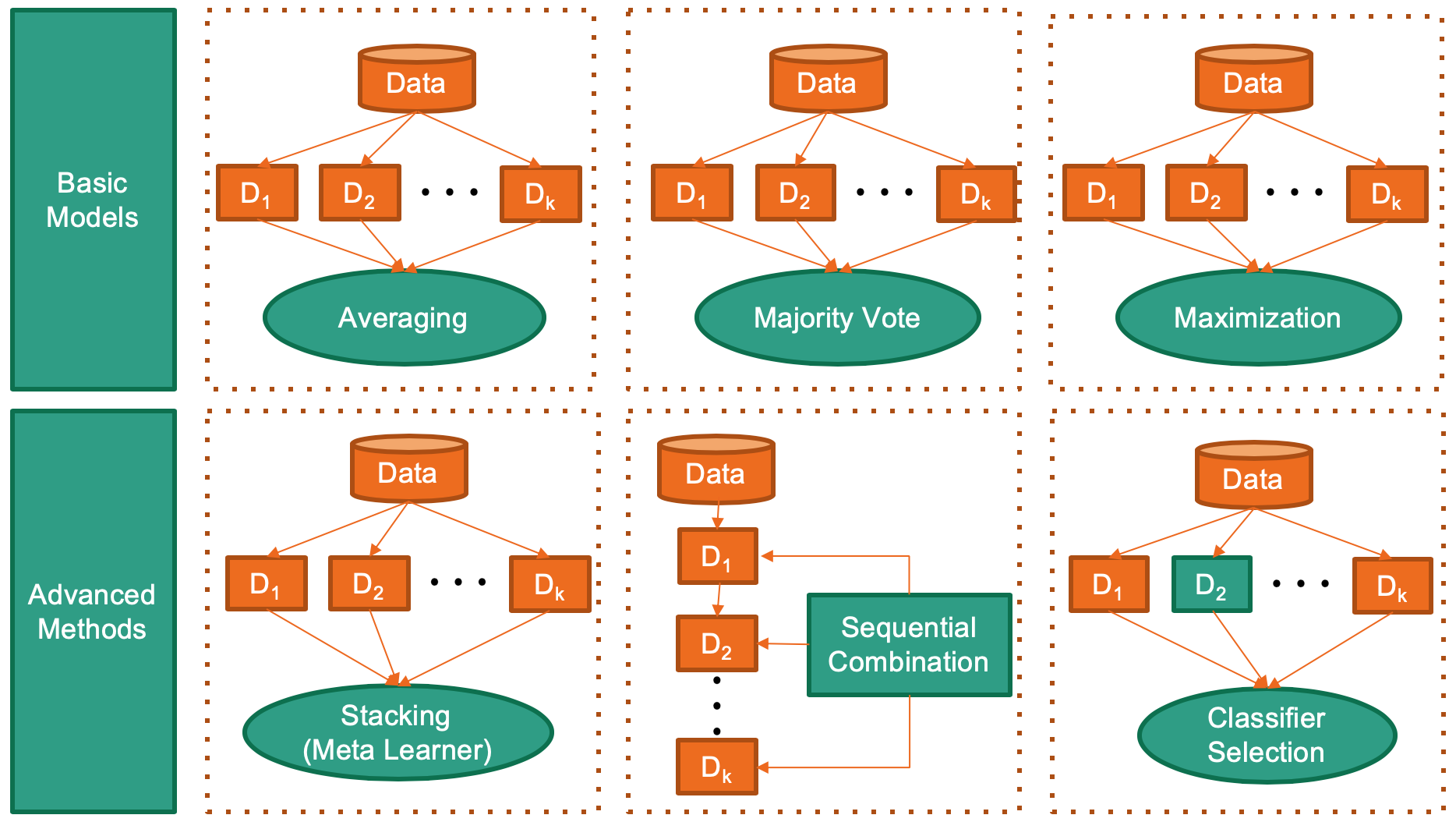
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
 4.2k Dec 28, 2022
4.2k Dec 28, 2022

General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and optimized for advanced GPU data processing usecases.
Vulkan Kompute The general purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabl
 1k Dec 26, 2022
1k Dec 26, 2022
STUMPY is a powerful and scalable Python library for computing a Matrix Profile, which can be used for a variety of time series data mining tasks
STUMPY STUMPY is a powerful and scalable library that efficiently computes something called the matrix profile, which can be used for a variety of tim
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
 6k Jan 6, 2023
6k Jan 6, 2023

CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent performances in several models such as Faster R-CNN, YOLOv4, RetinaNet and . There is a maximum AP improvement of 1.9% and an average AP of 0.8% improvement on MS COCO dataset, compared to traditional evaluation-feedback modules. Here we just use as an example to illustrate the code.
CDIoU-CDIoUloss CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent p
 24 Jul 19, 2022
24 Jul 19, 2022

An efficient and effective learning to rank algorithm by mining information across ranking candidates. This repository contains the tensorflow implementation of SERank model. The code is developed based on TF-Ranking.
SERank An efficient and effective learning to rank algorithm by mining information across ranking candidates. This repository contains the tensorflow
 44 Oct 20, 2022
44 Oct 20, 2022

Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding for Zero-Example Video Retrieval.
Dual Encoding for Video Retrieval by Text Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding
 81 Dec 1, 2022
81 Dec 1, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023
Modular, cohesive, transparent and fast web server template
kingdom-python-server 🐍 Modular, transparent, batteries (half) included, lightning fast web server. Features a functional, isolated business layer wi
 20 Feb 8, 2022
20 Feb 8, 2022
An automated algorithm to extract the linear blend skinning (LBS) from a set of example poses
Dem Bones This repository contains an implementation of Smooth Skinning Decomposition with Rigid Bones, an automated algorithm to extract the Linear B
 684 Dec 26, 2022
684 Dec 26, 2022
Toy example of an applied ML pipeline for me to experiment with MLOps tools.
Toy Machine Learning Pipeline Table of Contents About Getting Started ML task description and evaluation procedure Dataset description Repository stru
 190 Dec 21, 2022
190 Dec 21, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 7, 2023
14.5k Jan 7, 2023
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
4.2k Dec 29, 2022

🍊 :bar_chart: :bulb: Orange: Interactive data analysis
Orange Data Mining Orange is a data mining and visualization toolbox for novice and expert alike. To explore data with Orange, one requires no program
 3.9k Jan 5, 2023
3.9k Jan 5, 2023
Example of integrating Poetry with Docker leveraging multi-stage builds.
Poetry managed Python FastAPI application with Docker multi-stage builds This repo serves as a minimal reference on setting up docker multi-stage buil
 266 Dec 27, 2022
266 Dec 27, 2022
python fastapi example connection to mysql
Quickstart Then run the following commands to bootstrap your environment with poetry: git clone https://github.com/xiaozl/fastapi-realworld-example-ap
 55 Dec 15, 2022
55 Dec 15, 2022
Minimal example utilizing fastapi and celery with RabbitMQ for task queue, Redis for celery backend and flower for monitoring the celery tasks.
FastAPI with Celery Minimal example utilizing FastAPI and Celery with RabbitMQ for task queue, Redis for Celery backend and flower for monitoring the
 371 Jan 1, 2023
371 Jan 1, 2023
FastAPI Learning Example,对应中文视频学习教程:https://space.bilibili.com/396891097
视频教学地址 中文学习教程 1、本教程每一个案例都可以独立跑,前提是安装好依赖包。 2、本教程并未按照官方教程顺序,而是按照实际使用顺序编排。 Video Teaching Address FastAPI Learning Example 1.Each case in this tutorial c
 381 Dec 11, 2022
381 Dec 11, 2022
Example app using FastAPI and JWT
FastAPI-Auth Example app using FastAPI and JWT virtualenv -p python3 venv source venv/bin/activate pip3 install -r requirements.txt mv config.yaml.exa
 28 Oct 25, 2022
28 Oct 25, 2022
A simple Ethereum mining pool
A simple getWork pool for ethereum mining
 93 Oct 5, 2022
93 Oct 5, 2022
A simple Ethereum mining pool
A simple getWork pool for ethereum mining Payouts are still manual. TODO: write payouts when someone mines 10 blocks. Also, make the submit actually
93 Oct 5, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021

Exploring Cross-Image Pixel Contrast for Semantic Segmentation
Exploring Cross-Image Pixel Contrast for Semantic Segmentation Exploring Cross-Image Pixel Contrast for Semantic Segmentation, Wenguan Wang, Tianfei Z
 510 Jan 2, 2023
510 Jan 2, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
2.7k Jan 8, 2023
Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
2k Dec 27, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
5.7k Feb 12, 2021
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
14.5k Jan 8, 2023
Tink is a multi-language, cross-platform, open source library that provides cryptographic APIs that are secure, easy to use correctly, and hard(er) to misuse.
Tink A multi-language, cross-platform library that provides cryptographic APIs that are secure, easy to use correctly, and hard(er) to misuse. Ubuntu
 12.9k Jan 5, 2023
12.9k Jan 5, 2023
Library to scrape and clean web pages to create massive datasets.
lazynlp A straightforward library that allows you to crawl, clean up, and deduplicate webpages to create massive monolingual datasets. Using this libr
 2.1k Jan 6, 2023
2.1k Jan 6, 2023

Web scraping library and command-line tool for text discovery and extraction (main content, metadata, comments)
trafilatura: Web scraping tool for text discovery and retrieval Description Trafilatura is a Python package and command-line tool which seamlessly dow
 704 Jan 6, 2023
704 Jan 6, 2023

Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
Pattern Pattern is a web mining module for Python. It has tools for: Data Mining: web services (Google, Twitter, Wikipedia), web crawler, HTML DOM par
 8.4k Jan 8, 2023
8.4k Jan 8, 2023
Example python package with pybind11 cpp extension
Developing C++ extension in Python using pybind11 This is a summary of the commands used in the tutorial.
 55 Sep 4, 2022
55 Sep 4, 2022
This repository contains code examples and documentation for learning how applications can be developed with Kubernetes
BigBitBus KAT Components Click on the diagram to enlarge, or follow this link for detailed documentation Introduction Welcome to the BigBitBus Kuberne
 51 Oct 16, 2022
51 Oct 16, 2022
A compendium of useful, interesting, inspirational usage of pandas functions, each example will be an ipynb file
Pandas_by_examples A compendium of useful/interesting/inspirational usage of pandas functions, each example will be an ipynb file What is this reposit
 32 Nov 20, 2022
32 Nov 20, 2022
Python wrapper for the Sportradar APIs ⚽️🏈
Sportradar APIs This is a Python wrapper for the sports APIs provided by Sportradar. You'll need to sign up for an API key to use the service. Sportra
 39 Jan 1, 2023
39 Jan 1, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
14.5k Jan 8, 2023
Multi-class confusion matrix library in Python
Table of contents Overview Installation Usage Document Try PyCM in Your Browser Issues & Bug Reports Todo Outputs Dependencies Contribution References
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 2, 2023
Fast topic modeling platform
The state-of-the-art platform for topic modeling. Full Documentation User Mailing List Download Releases User survey What is BigARTM? BigARTM is a pow
 633 Dec 21, 2022
633 Dec 21, 2022
A Python package implementing a new model for text classification with visualization tools for Explainable AI :octocat:
A Python package implementing a new model for text classification with visualization tools for Explainable AI 🍣 Online live demos: http://tworld.io/s
 285 Jan 2, 2023
285 Jan 2, 2023
Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
Pattern Pattern is a web mining module for Python. It has tools for: Data Mining: web services (Google, Twitter, Wikipedia), web crawler, HTML DOM par
8.4k Dec 30, 2022
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
6k Jan 8, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
6.9k Jan 4, 2023
Machine Learning From Scratch. Bare bones NumPy implementations of machine learning models and algorithms with a focus on accessibility. Aims to cover everything from linear regression to deep learning.
Machine Learning From Scratch About Python implementations of some of the fundamental Machine Learning models and algorithms from scratch. The purpose
 21.8k Jan 9, 2023
21.8k Jan 9, 2023
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2020 Links Doc
4.2k Jan 2, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 3, 2023
Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
Pattern Pattern is a web mining module for Python. It has tools for: Data Mining: web services (Google, Twitter, Wikipedia), web crawler, HTML DOM par
8.4k Jan 3, 2023
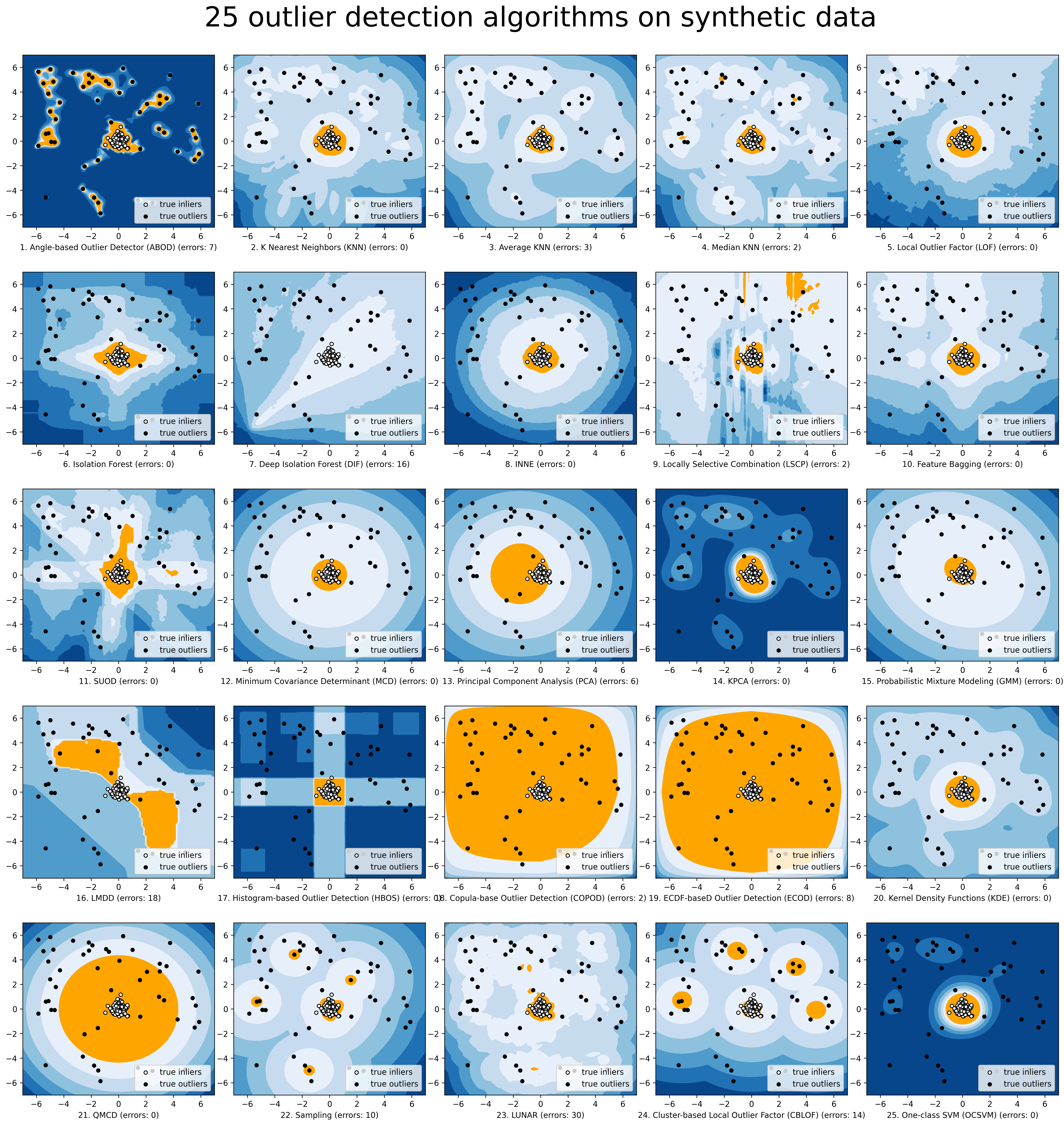
(JMLR'19) A Python Toolbox for Scalable Outlier Detection (Anomaly Detection)
Python Outlier Detection (PyOD) Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License PyOD is a comprehensive and sca
6.6k Jan 3, 2023

Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chinese, Arabic, Devanagari, Cyrillic and etc.
EasyOCR Ready-to-use OCR with 80+ languages supported including Chinese, Japanese, Korean and Thai. What's new 1 February 2021 - Version 1.2.3 Add set
 16.7k Jan 3, 2023
16.7k Jan 3, 2023