352 Repositories
Python korean-sentence-bert Libraries
Pre-trained BERT Models for Ancient and Medieval Greek, and associated code for LaTeCH 2021 paper titled - "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek"
Ancient Greek BERT The first and only available Ancient Greek sub-word BERT model! State-of-the-art post fine-tuning on Part-of-Speech Tagging and Mor
 22 Dec 8, 2022
22 Dec 8, 2022
Code and data form the paper BERT Got a Date: Introducing Transformers to Temporal Tagging
BERT Got a Date: Introducing Transformers to Temporal Tagging Satya Almasian*, Dennis Aumiller*, and Michael Gertz Heidelberg University Contact us vi
 54 Dec 4, 2022
54 Dec 4, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023
CNNs for Sentence Classification in PyTorch
Introduction This is the implementation of Kim's Convolutional Neural Networks for Sentence Classification paper in PyTorch. Kim's implementation of t
 956 Dec 19, 2022
956 Dec 19, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

Search Git commits in natural language
NaLCoS - NAtural Language COmmit Search Search commit messages in your repository in natural language. NaLCoS (NAtural Language COmmit Search) is a co
 50 Mar 22, 2022
50 Mar 22, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022

This repository contains the PyTorch implementation of the paper STaCK: Sentence Ordering with Temporal Commonsense Knowledge appearing at EMNLP 2021.
STaCK: Sentence Ordering with Temporal Commonsense Knowledge This repository contains the pytorch implementation of the paper STaCK: Sentence Ordering
 23 Dec 16, 2022
23 Dec 16, 2022
Pytorch-version BERT-flow: One can apply BERT-flow to any PLM within Pytorch framework.
Pytorch-version BERT-flow: One can apply BERT-flow to any PLM within Pytorch framework.
 59 Dec 1, 2022
59 Dec 1, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
 30 Dec 12, 2022
30 Dec 12, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022

A BERT-based reverse dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end / back-end 임용
 94 Dec 8, 2022
94 Dec 8, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023

Using VideoBERT to tackle video prediction
VideoBERT This repo reproduces the results of VideoBERT (https://arxiv.org/pdf/1904.01766.pdf). Inspiration was taken from https://github.com/MDSKUL/M
 75 Dec 14, 2022
75 Dec 14, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
Code for technical report "An Improved Baseline for Sentence-level Relation Extraction".
RE_improved_baseline Code for technical report "An Improved Baseline for Sentence-level Relation Extraction". Requirements torch = 1.8.1 transformers
 74 Nov 29, 2022
74 Nov 29, 2022

Punctuation Restoration using Transformer Models for High-and Low-Resource Languages
Punctuation Restoration using Transformer Models This repository contins official implementation of the paper Punctuation Restoration using Transforme
 142 Jan 1, 2023
142 Jan 1, 2023
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022

This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
 49 Oct 30, 2022
49 Oct 30, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022
Implementing SimCSE(paper, official repository) using TensorFlow 2 and KR-BERT.
KR-BERT-SimCSE Implementing SimCSE(paper, official repository) using TensorFlow 2 and KR-BERT. Training Unsupervised python train_unsupervised.py --mi
27 Dec 12, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 3, 2023

A heterogeneous entity-augmented academic language model based on Open Academic Graph (OAG)
Library | Paper | Slack We released two versions of OAG-BERT in CogDL package. OAG-BERT is a heterogeneous entity-augmented academic language model wh
 58 Dec 17, 2022
58 Dec 17, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 43 Nov 21, 2022
43 Nov 21, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022

VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
 44 Nov 1, 2022
44 Nov 1, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022
VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
44 Nov 1, 2022
[ACL 20] Probing Linguistic Features of Sentence-level Representations in Neural Relation Extraction
REval Table of Contents Introduction Overview Requirements Installation Probing Usage Citation License 🎓 Introduction REval is a simple framework for
 13 Jan 6, 2023
13 Jan 6, 2023
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 9, 2023
1.2k Jan 9, 2023
The source codes for ACL 2021 paper 'BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data'
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data This repository provides the implementation details for
 124 Dec 27, 2022
124 Dec 27, 2022
PyTorch impelementations of BERT-based Spelling Error Correction Models
PyTorch impelementations of BERT-based Spelling Error Correction Models
 59 Jun 29, 2021
59 Jun 29, 2021
PyTorch impelementations of BERT-based Spelling Error Correction Models.
PyTorch impelementations of BERT-based Spelling Error Correction Models. 基于BERT的文本纠错模型,使用PyTorch实现。
209 Dec 30, 2022

A BERT-based reverse-dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end Quick Start C
 94 Dec 8, 2022
94 Dec 8, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
 14 Aug 24, 2022
14 Aug 24, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
14 Aug 24, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022
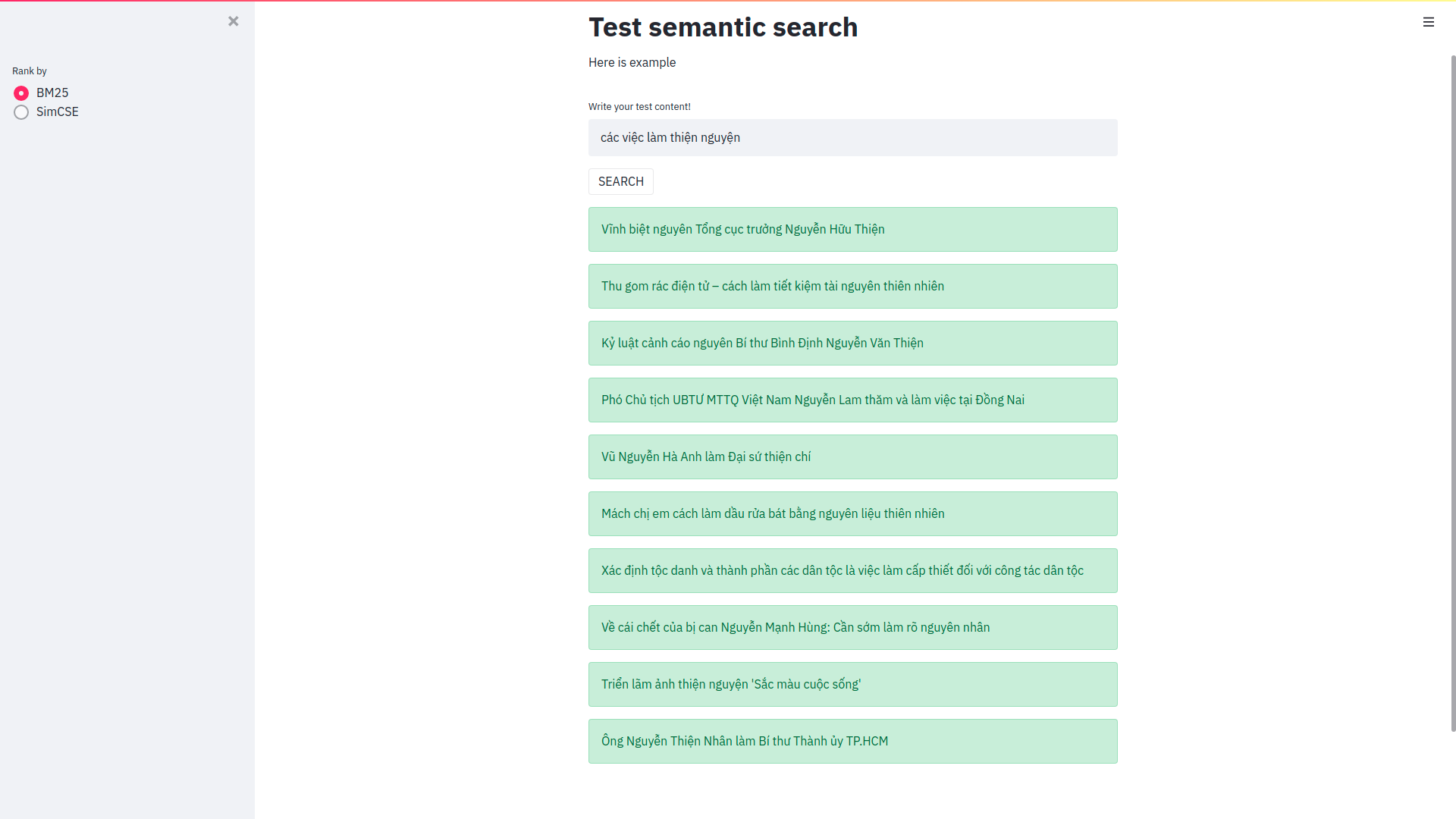
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Python Implementation of ``Modeling the Influence of Verb Aspect on the Activation of Typical Event Locations with BERT'' (Findings of ACL: ACL 2021)
BERT-for-Surprisal Python Implementation of ``Modeling the Influence of Verb Aspect on the Activation of Typical Event Locations with BERT'' (Findings
 7 Dec 5, 2022
7 Dec 5, 2022
Scalable Attentive Sentence-Pair Modeling via Distilled Sentence Embedding (AAAI 2020) - PyTorch Implementation
Scalable Attentive Sentence-Pair Modeling via Distilled Sentence Embedding PyTorch implementation for the Scalable Attentive Sentence-Pair Modeling vi
 25 Dec 2, 2022
25 Dec 2, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
What is MUSE? MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (16 languages) of Universal Sentence Encoder (USE). MUS
47 Sep 5, 2022
Baseline code for Korean open domain question answering(ODQA)
Open-Domain Question Answering(ODQA)는 다양한 주제에 대한 문서 집합으로부터 자연어 질의에 대한 답변을 찾아오는 task입니다. 이때 사용자 질의에 답변하기 위해 주어지는 지문이 따로 존재하지 않습니다. 따라서 사전에 구축되어있는 Knowl
 69 Nov 4, 2022
69 Nov 4, 2022

The official implementation of You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient.
You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient (paper) @misc{zhang2021compress,
 46 Dec 7, 2022
46 Dec 7, 2022

Source code for NAACL 2021 paper "TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference"
TR-BERT Source code and dataset for "TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference". The code is based on huggaface's transformers.
 37 Oct 30, 2022
37 Oct 30, 2022
Using context-free grammar formalism to parse English sentences to determine their structure to help computer to better understand the meaning of the sentence.
Sentance Parser Executing the Program Make sure Python 3.6+ is installed. Install requirements $ pip install requirements.txt Run the program:
 12 Sep 28, 2022
12 Sep 28, 2022
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
 478 Dec 25, 2022
478 Dec 25, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
478 Dec 25, 2022

Code for the ACL2021 paper "Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter"
Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter Code and checkpoints for the ACL2021 paper "Lexicon Enhanced Chinese Sequence Labelling
 274 Dec 6, 2022
274 Dec 6, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023
(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
248 Dec 4, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
44 Jan 6, 2023
A collection of Korean Text Datasets ready to use using Tensorflow-Datasets.
tfds-korean A collection of Korean Text Datasets ready to use using Tensorflow-Datasets. TensorFlow-Datasets를 이용한 한국어/한글 데이터셋 모음입니다. Dataset Catalog |
20 Jul 11, 2022
source code for paper: WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach.
WhiteningBERT Source code and data for paper WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach. Preparation git clone https://github.com
 49 Dec 17, 2022
49 Dec 17, 2022
Train 🤗transformers with DeepSpeed: ZeRO-2, ZeRO-3
Fork from https://github.com/huggingface/transformers/tree/86d5fb0b360e68de46d40265e7c707fe68c8015b/examples/pytorch/language-modeling at 2021.05.17.
 12 Oct 26, 2022
12 Oct 26, 2022
Code and models used in "MUSS Multilingual Unsupervised Sentence Simplification by Mining Paraphrases".
Multilingual Unsupervised Sentence Simplification Code and pretrained models to reproduce experiments in "MUSS: Multilingual Unsupervised Sentence Sim
 81 Dec 29, 2022
81 Dec 29, 2022
![[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.](https://github.com/cambridgeltl/sapbert/raw/main/sapbert_front_graphs_v6.png?raw=true)
[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.
SapBERT: Self-alignment pretraining for BERT This repo holds code for the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining
 104 Dec 7, 2022
104 Dec 7, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
Integrating the Best of TF into PyTorch, for Machine Learning, Natural Language Processing, and Text Generation. This is part of the CASL project: http://casl-project.ai/
Texar-PyTorch is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar
 726 Dec 30, 2022
726 Dec 30, 2022

Pytorch-Named-Entity-Recognition-with-BERT
BERT NER Use google BERT to do CoNLL-2003 NER ! Train model using Python and Inference using C++ ALBERT-TF2.0 BERT-NER-TENSORFLOW-2.0 BERT-SQuAD Requi
 1.1k Dec 25, 2022
1.1k Dec 25, 2022
InferSent sentence embeddings
InferSent InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language in
2.2k Dec 27, 2022
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
GenSen Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning Sandeep Subramanian, Adam Trischler, Yoshua B
 309 Oct 19, 2022
309 Oct 19, 2022
Language-Agnostic SEntence Representations
LASER Language-Agnostic SEntence Representations LASER is a library to calculate and use multilingual sentence embeddings. NEWS 2019/11/08 CCMatrix is
3.2k Jan 4, 2023
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022

QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
 152 Jan 2, 2023
152 Jan 2, 2023
An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models.
DeepNER An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models. This repository contains complex Deep
 9 May 30, 2022
9 May 30, 2022
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
152 Jan 2, 2023
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
2.5k Jan 3, 2023

 387 Jan 4, 2023
387 Jan 4, 2023
Code for the paper "Improving Vision-and-Language Navigation with Image-Text Pairs from the Web" (ECCV 2020)
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh
 44 Dec 14, 2022
44 Dec 14, 2022

SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Jan 7, 2023
2.5k Jan 7, 2023
Sentence boundary disambiguation tool for Japanese texts (日本語文境界判定器)
Bunkai Bunkai is a sentence boundary (SB) disambiguation tool for Japanese texts. Quick Start $ pip install bunkai $ echo -e '宿を予約しました♪!まだ2ヶ月も先だけど。早すぎ
 160 Dec 23, 2022
160 Dec 23, 2022
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022
State of the art Semantic Sentence Embeddings
Contrastive Tension State of the art Semantic Sentence Embeddings Published Paper · Huggingface Models · Report Bug Overview This is the official code
 88 Dec 30, 2022
88 Dec 30, 2022
Pytorch version of BERT-whitening
BERT-whitening This is the Pytorch implementation of "Whitening Sentence Representations for Better Semantics and Faster Retrieval". BERT-whitening is
 255 Dec 27, 2022
255 Dec 27, 2022
Weakly supervised medical named entity classification
Trove Trove is a research framework for building weakly supervised (bio)medical named entity recognition (NER) and other entity attribute classifiers
 60 Nov 18, 2022
60 Nov 18, 2022

Python library containing BART query generation and BERT-based Siamese models for neural retrieval.
Neural Retrieval Embedding-based Zero-shot Retrieval through Query Generation leverages query synthesis over large corpuses of unlabeled text (such as
 35 Apr 14, 2022
35 Apr 14, 2022

I-BERT: Integer-only BERT Quantization
I-BERT: Integer-only BERT Quantization HuggingFace Implementation I-BERT is also available in the master branch of HuggingFace! Visit the following li
139 Dec 27, 2022