2224 Repositories
Python language-generation-dataset Libraries

Slice a single image into multiple pieces and create a dataset from them
OpenCV Image to Dataset Converter Slice a single image of Persian digits into mu
 14 Dec 29, 2022
14 Dec 29, 2022

A bulk pdf generator. This application can generate PDFs in bulk by using just one click.
A bulk html pdf generator. This application can generate PDFs in bulk by using just one click. Screenshots Requirements 🧱 Your system must have the f
 3 Apr 23, 2022
3 Apr 23, 2022
A markdown generation library for Python.
Welcome to SnakeMD SnakeMD is your ticket to generating Markdown in Python. To prove it to you, we've generated this entire README using SnakeMD. See
 22 Dec 8, 2022
22 Dec 8, 2022
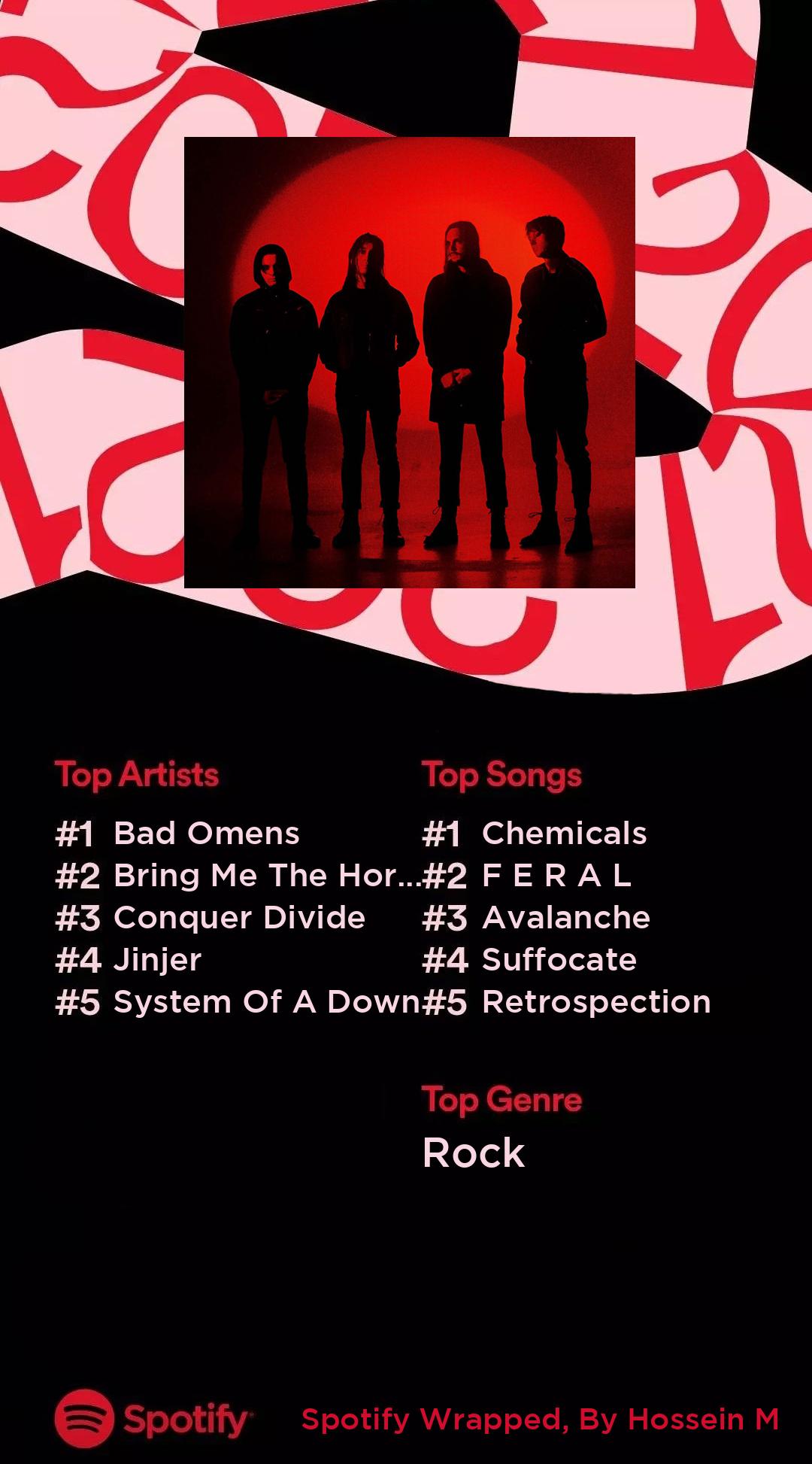
A project in order to analyze user's favorite musics, artists and genre
Spotify-Wrapped This is a project about Spotify Wrapped (which is an extra option for premium accounts, but you don't need to be premium here) This pr
 19 Jan 4, 2023
19 Jan 4, 2023
GDSHelpers is an open-source package for automatized pattern generation for nano-structuring.
GDSHelpers GDSHelpers in an open-source package for automatized pattern generation for nano-structuring. It allows exporting the pattern in the GDSII-
 76 Dec 16, 2022
76 Dec 16, 2022
Quickly download, clean up, and install public datasets into a database management system
Finding data is one thing. Getting it ready for analysis is another. Acquiring, cleaning, standardizing and importing publicly available data is time
 274 Jan 4, 2023
274 Jan 4, 2023
Python library for parsing resumes using natural language processing and machine learning
CVParser Python library for parsing resumes using natural language processing and machine learning. Setup Installation on Linux and Mac OS Follow the
 0 Jul 29, 2021
0 Jul 29, 2021

NLP project that works with news (NER, context generation, news trend analytics)
СоАвтор СоАвтор – платформа и открытый набор инструментов для редакций и журналистов-фрилансеров, который призван сделать процесс создания контента ма
 38 Jan 4, 2023
38 Jan 4, 2023

A simple interpreted language for creating basic mathematical graphs.
graphr Introduction graphr is a small language written to create basic mathematical graphs. It is an interpreted language written in python and essent
 2 Dec 26, 2021
2 Dec 26, 2021
Catbird is an open source paraphrase generation toolkit based on PyTorch.
Catbird is an open source paraphrase generation toolkit based on PyTorch. Quick Start Requirements and Installation The project is based on PyTorch 1.
 5 Dec 15, 2022
5 Dec 15, 2022
Code for "Intra-hour Photovoltaic Generation Forecasting based on Multi-source Data and Deep Learning Methods."
pv_predict_unet-lstm Code for "Intra-hour Photovoltaic Generation Forecasting based on Multi-source Data and Deep Learning Methods." IEEE Transactions
 8 Oct 8, 2022
8 Oct 8, 2022

Align and Prompt: Video-and-Language Pre-training with Entity Prompts
ALPRO Align and Prompt: Video-and-Language Pre-training with Entity Prompts [Paper] Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, Steven C.H
 127 Dec 21, 2022
127 Dec 21, 2022

N-Omniglot is a large neuromorphic few-shot learning dataset
N-Omniglot [Paper] || [Dataset] N-Omniglot is a large neuromorphic few-shot learning dataset. It reconstructs strokes of Omniglot as videos and uses D
 11 Dec 5, 2022
11 Dec 5, 2022

An Official Repo of CVPR '20 "MSeg: A Composite Dataset for Multi-Domain Segmentation"
This is the code for the paper: MSeg: A Composite Dataset for Multi-domain Semantic Segmentation (CVPR 2020, Official Repo) [CVPR PDF] [Journal PDF] J
 226 Nov 5, 2022
226 Nov 5, 2022
![[ICML 2020] DrRepair: Learning to Repair Programs from Error Messages](https://github.com/michiyasunaga/DrRepair/raw/master/DrRepair-overview.png)
[ICML 2020] DrRepair: Learning to Repair Programs from Error Messages
DrRepair: Learning to Repair Programs from Error Messages This repo provides the source code & data of our paper: Graph-based, Self-Supervised Program
 155 Jan 8, 2023
155 Jan 8, 2023
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
 2 Oct 22, 2022
2 Oct 22, 2022
Visualization of the World Religion Data dataset by Correlates of War Project.
World Religion Data Visualization Visualization of the World Religion Data dataset by Correlates of War Project. Mostly personal project to famirializ
 1 Oct 15, 2022
1 Oct 15, 2022

TensorFlow implementation of "Attention is all you need (Transformer)"
[TensorFlow 2] Attention is all you need (Transformer) TensorFlow implementation of "Attention is all you need (Transformer)" Dataset The MNIST datase
 4 Jan 5, 2022
4 Jan 5, 2022
Official implementation for paper Knowledge Bridging for Empathetic Dialogue Generation (AAAI 2021).
Knowledge Bridging for Empathetic Dialogue Generation This is the official implementation for paper Knowledge Bridging for Empathetic Dialogue Generat
 50 Dec 20, 2022
50 Dec 20, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023
A deep learning model for style-specific music generation.
DeepJ: A model for style-specific music generation https://arxiv.org/abs/1801.00887 Abstract Recent advances in deep neural networks have enabled algo
 704 Nov 23, 2022
704 Nov 23, 2022
Fast, DB Backed pretrained word embeddings for natural language processing.
Embeddings Embeddings is a python package that provides pretrained word embeddings for natural language processing and machine learning. Instead of lo
 212 Nov 21, 2022
212 Nov 21, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
Medical-Image-Triage-and-Classification-System-Based-on-COVID-19-CT-and-X-ray-Scan-Dataset
Medical-Image-Triage-and-Classification-System-Based-on-COVID-19-CT-and-X-ray-Sc
 2 Dec 26, 2021
2 Dec 26, 2021

Automatic meme generation model using Tensorflow Keras.
Memefly You can find the project at MemeflyAI. Contributors Nick Buukhalter Harsh Desai Han Lee Project Overview Trello Board Product Canvas Automatic
 2 Jan 13, 2022
2 Jan 13, 2022

Implementation of Memory-Efficient Neural Networks with Multi-Level Generation, ICCV 2021
Memory-Efficient Multi-Level In-Situ Generation (MLG) By Jiaqi Gu, Hanqing Zhu, Chenghao Feng, Mingjie Liu, Zixuan Jiang, Ray T. Chen and David Z. Pan
 2 Jan 4, 2022
2 Jan 4, 2022
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.
ALiBi PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. Quickstart Clone this reposit
 4 Jul 27, 2022
4 Jul 27, 2022
Adds integration of the Chameleon template language to FastAPI.
fastapi-chameleon Adds integration of the Chameleon template language to FastAPI. If you are interested in Jinja instead, see the sister project: gith
 124 Nov 26, 2022
124 Nov 26, 2022
Adds integration of the Jinja template language to FastAPI.
fastapi-jinja Adds integration of the Jinja template language to FastAPI. This is inspired and based off fastapi-chamelon by Mike Kennedy. Check that
 58 Nov 29, 2022
58 Nov 29, 2022
🍋 A Python package to process food
Pyfood is a simple Python package to process food, in different languages. Pyfood's ambition is to be the go-to library to deal with food, recipes, on
 8 Apr 4, 2022
8 Apr 4, 2022

Sequence lineage information extracted from RKI sequence data repo
Pango lineage information for German SARS-CoV-2 sequences This repository contains a join of the metadata and pango lineage tables of all German SARS-
 24 Oct 26, 2022
24 Oct 26, 2022
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022
Weather telegram bot with aiogram, on Russian language
weather_bot Weather telegram bot with aiogram, on Russian language #RU Бот по определению погоды в Telegram, написана на библиотеке aiogram, весь инте
 0 Jan 6, 2022
0 Jan 6, 2022
Rule based classification A hotel s customers dataset
Rule-based-classification-A-hotel-s-customers-dataset- Aim: Categorize new customers by segment and predict how much revenue they can generate This re
 4 Jan 2, 2022
4 Jan 2, 2022

Vietnamese Language Detection and Recognition
Table of Content Introduction (Khôi viết) Dataset (đổi link thui thành 3k5 ảnh mình) Getting Started (An Viết) Requirements Usage Example Training & E
 6 May 27, 2022
6 May 27, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
Datasets with Softcatalà website content
softcatala-web-dataset This repository contains Sofcatalà web site content (articles and programs descriptions). Dataset are available in the dataset
 2 Dec 26, 2021
2 Dec 26, 2021
MindF**k it's a programming language as BrainFuck, but with some cool features.
MindF**k Description MindF**k it's a programming language as BrainFuck, but with some cool features. Symbol What does symbol mean Next slot Previo
 0 Jun 15, 2022
0 Jun 15, 2022
A Pytorch loader for MVTecAD dataset.
MVTecAD A Pytorch loader for MVTecAD dataset. It strictly follows the code style of common Pytorch datasets, such as torchvision.datasets.CIFAR10. The
 1 Dec 27, 2021
1 Dec 27, 2021
Build a medical knowledge graph based on Unified Language Medical System (UMLS)
UMLS-Graph Build a medical knowledge graph based on Unified Language Medical System (UMLS) Requisite Install MySQL Server 5.6 and import UMLS data int
 6 Dec 25, 2022
6 Dec 25, 2022
pyinsim is a InSim module for the Python programming language.
PYINSIM pyinsim is a InSim module for the Python programming language. It creates socket connection with LFS and provides many classes, functions and
 2 May 12, 2022
2 May 12, 2022
Picka: A Python module for data generation and randomization.
Picka: A Python module for data generation and randomization. Author: Anthony Long Version: 1.0.1 - Fixed the broken image stuff. Whoops What is Picka
 108 Nov 30, 2021
108 Nov 30, 2021
PyTorch implementation of Rethinking Positional Encoding in Language Pre-training
TUPE PyTorch implementation of Rethinking Positional Encoding in Language Pre-training. Quickstart Clone this repository. git clone https://github.com
5 Jan 27, 2022
A next-generation CLI and TUI that aims to be your personal assistant for everything competitive programming related. 🚀
Competitive Programming Tool Kit The Competitive Programming Tool Kit (cptk for short), is a command line and terminal user interface (CLI and TUI) th
 4 May 21, 2022
4 May 21, 2022
Official repository of the AAAI'2022 paper "Contrast and Generation Make BART a Good Dialogue Emotion Recognizer"
CoG-BART Contrast and Generation Make BART a Good Dialogue Emotion Recognizer Quick Start: To run the model on test sets of four datasets, Download th
 39 Dec 24, 2022
39 Dec 24, 2022
Simple Python script to scrape youtube channles of "Parity Technologies and Web3 Foundation" and translate them to well-known braille language or any language
Simple Python script to scrape youtube channles of "Parity Technologies and Web3 Foundation" and translate them to well-known braille language or any
 1 Apr 28, 2022
1 Apr 28, 2022

Code release for SLIP Self-supervision meets Language-Image Pre-training
SLIP: Self-supervision meets Language-Image Pre-training What you can find in this repo: Pre-trained models (with ViT-Small, Base, Large) and code to
 621 Dec 31, 2022
621 Dec 31, 2022
Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology (EARIST)
🤖 Coeus - EARIST A.C.E 💬 Coeus is an Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology,
 3 Oct 14, 2022
3 Oct 14, 2022
[PNAS2021] The neural architecture of language: Integrative modeling converges on predictive processing
The neural architecture of language: Integrative modeling converges on predictive processing Code accompanying the paper The neural architecture of la
 36 Dec 1, 2022
36 Dec 1, 2022
The official start-up code for paper "FFA-IR: Towards an Explainable and Reliable Medical Report Generation Benchmark."
FFA-IR The official start-up code for paper "FFA-IR: Towards an Explainable and Reliable Medical Report Generation Benchmark." The framework is inheri
 28 Dec 16, 2022
28 Dec 16, 2022
Source code of SIGIR2021 Paper 'One Chatbot Per Person: Creating Personalized Chatbots based on Implicit Profiles'
DHAP Source code of SIGIR2021 Long Paper: One Chatbot Per Person: Creating Personalized Chatbots based on Implicit User Profiles . Preinstallation Fir
 32 Dec 6, 2022
32 Dec 6, 2022

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022
A curated list of python programming language blogs
Python Blogs A curated list of python programming language blogs Contribute Companies/Organization # A B C D E F G H I J K L M N O P Q R S T U V W X Y
 48 Nov 15, 2022
48 Nov 15, 2022
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 8 Nov 21, 2022
8 Nov 21, 2022

Random Programming Language Project
Crastle Random Programming Language Project Freedom of expression Are you a fan of curly brace languages? Then use curly braces! Not a fan of curly br
 2 Dec 23, 2021
2 Dec 23, 2021
ANKIT-OS/STYLISH-TEXT is a special repository. Its Is A Telegram Bot Which Can Translate Your Text Into 100+ Language
🔥 ᴳᴼᴼᴳᴸᴱ⁻ᵀᴿᴬᴺᔆᴸᴬᵀᴱᴿ 🔥 The owner would not be responsible for any kind of bans due to the bot. • ⚡ INSTALLING ⚡ • • 🛠️ Lᴀɴɢᴜᴀɢᴇs Aɴᴅ Tᴏᴏʟs 🔰 • If
 1 Dec 23, 2021
1 Dec 23, 2021
American Sign Language (ASL) to Text Converter
Signterpreter American Sign Language (ASL) to Text Converter Recommendations Although there is grayscale and gaussian blur, we recommend that you use
 0 Feb 20, 2022
0 Feb 20, 2022
The Sudachi synonym dictionary in Solar format.
solr-sudachi-synonyms The Sudachi synonym dictionary in Solar format. Summary Run a script that checks for updates to the Sudachi dictionary every hou
 3 Aug 19, 2022
3 Aug 19, 2022
A partial-transpiler that converts a subset of Python to the Folders esoteric programming language
Py2Folders A partial-transpiler that converts a subset of Python to the Folders esoteric programming language Folders Folders is an esoteric programmi
 1 Dec 23, 2021
1 Dec 23, 2021
Interpreting-compiling programming language.
HoneyASM The programming language written on Python, which can be as interpreted as compiled. HoneyASM is easy for use very optimized PL, which can so
 1 Dec 25, 2021
1 Dec 25, 2021

PyTorch implementation of the paper: Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding This repository contains the official PyTorch implementation of th
 26 Dec 14, 2022
26 Dec 14, 2022
A Simple Telegram Bot That Can Generate Strong Password With Many Features Written In Python Using Pyrogram
Password-Generator-Bot A Simple Telegram Bot That Can Generate Strong Password With Many Features Written In Python Using Pyrogram Features Random Pas
 17 Dec 23, 2022
17 Dec 23, 2022
Ked interpreter built with Lex, Yacc and Python
Ked Ked is the first programming language known to hail from The People's Republic of Cork. It was first discovered and partially described by Adam Ly
 1 Feb 8, 2022
1 Feb 8, 2022
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP)
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP) predictions: part-of-speech (POS) tags, chunking (CHK), name entity recognition (NER), semantic role labeling (SRL) and syntactic parsing (PSG) with skip-gram all in Python and still more features will be added. The website give is for downlarding Senna tool
 20 Apr 30, 2022
20 Apr 30, 2022
Simple multilingual lemmatizer for Python, especially useful for speed and efficiency
Simplemma: a simple multilingual lemmatizer for Python Purpose Lemmatization is the process of grouping together the inflected forms of a word so they
70 Dec 29, 2022
Faster, modernized fork of the language identification tool langid.py
py3langid py3langid is a fork of the standalone language identification tool langid.py by Marco Lui. Original license: BSD-2-Clause. Fork license: BSD
12 Nov 5, 2022
Hotpile: High Order Turing Machine Language Compiler
Hotpile: High Order Turing Machine Language Compiler Build and Run Requirements: Python 3.6+, bison, flex, and GCC installed. Needs to be run under UN
 4 Dec 29, 2021
4 Dec 29, 2021

Turn any live video stream or locally stored video into a dataset of interesting samples for ML training, or any other type of analysis.
Sieve Video Data Collection Example Find samples that are interesting within hours of raw video, for free and completely automatically using Sieve API
 72 Aug 1, 2022
72 Aug 1, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
 13.6k Jan 5, 2023
13.6k Jan 5, 2023
Keras implementation of PersonLab for Multi-Person Pose Estimation and Instance Segmentation.
PersonLab This is a Keras implementation of PersonLab for Multi-Person Pose Estimation and Instance Segmentation. The model predicts heatmaps and vari
 160 Dec 21, 2022
160 Dec 21, 2022
A 30000+ Chinese MRC dataset - Delta Reading Comprehension Dataset
Delta Reading Comprehension Dataset 台達閱讀理解資料集 Delta Reading Comprehension Dataset (DRCD) 屬於通用領域繁體中文機器閱讀理解資料集。 本資料集期望成為適用於遷移學習之標準中文閱讀理解資料集。 本資料集從2,108篇
 272 Dec 15, 2022
272 Dec 15, 2022
Open clone of OpenAI's unreleased WebText dataset scraper.
Open clone of OpenAI's unreleased WebText dataset scraper. This version uses pushshift.io files instead of the API for speed.
 471 Dec 30, 2022
471 Dec 30, 2022

Codes for “A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection”
DSAMNet The pytorch implementation for "A Deeply-supervised Attention Metric-based Network and an Open Aerial Image Dataset for Remote Sensing Change
 41 Dec 14, 2022
41 Dec 14, 2022

This repository provides data for the VAW dataset as described in the CVPR 2021 paper titled "Learning to Predict Visual Attributes in the Wild"
Visual Attributes in the Wild (VAW) This repository provides data for the VAW dataset as described in the CVPR 2021 Paper: Learning to Predict Visual
 36 Dec 30, 2022
36 Dec 30, 2022

StyleSwin: Transformer-based GAN for High-resolution Image Generation
StyleSwin This repo is the official implementation of "StyleSwin: Transformer-based GAN for High-resolution Image Generation". By Bowen Zhang, Shuyang
 349 Dec 28, 2022
349 Dec 28, 2022
Official code for the publication "HyFactor: Hydrogen-count labelled graph-based defactorization Autoencoder".
HyFactor Graph-based architectures are becoming increasingly popular as a tool for structure generation. Here, we introduce a novel open-source archit
 11 Oct 10, 2022
11 Oct 10, 2022
This project consists of a collaborative filtering algorithm to predict movie reviews ratings from a dataset of Netflix ratings.
Collaborative Filtering - Netflix movie reviews Description This project consists of a collaborative filtering algorithm to predict movie reviews rati
 1 Dec 21, 2021
1 Dec 21, 2021

This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs".
CrossSum This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summ
 29 Nov 19, 2022
29 Nov 19, 2022

Non official, but friendly QvaPay library for the Python language.
Python SDK for the QvaPay API Non official, but friendly QvaPay library for the Python language. Setup You can install this package by using the pip t
 17 Nov 25, 2022
17 Nov 25, 2022
Official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.
GLIDE This is the official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing w
 2.9k Jan 4, 2023
2.9k Jan 4, 2023

fhempy is a FHEM binding to write modules in Python language
fhempy (BETA) fhempy allows the usage of Python 3 (NOT 2!) language to write FHEM modules. Python 3.7 or higher is required, therefore I recommend usi
 27 Dec 14, 2022
27 Dec 14, 2022
Resources related to our paper "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain"
CLIN-X (CLIN-X-ES) & (CLIN-X-EN) This repository holds the companion code for the system reported in the paper: "CLIN-X: pre-trained language models a
 4 Dec 5, 2022
4 Dec 5, 2022
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction The dataset contains 3 million attribute-value annotations across 1257 unique ca
 89 Jan 8, 2023
89 Jan 8, 2023
The source code of "Language Models are Few-shot Multilingual Learners" (MRL @ EMNLP 2021)
Language Models are Few-shot Multilingual Learners Paper This is the source code of the paper [Arxiv] [ACL Anthology]: This code has been written usin
 45 Nov 21, 2022
45 Nov 21, 2022
Lightweight utility tools for the detection of multiple spellings, meanings, and language-specific terminology in British and American English
Breame ( British English and American English) Breame is a lightweight Python package with a number of utility tools to aid in the detection of words
 8 Oct 10, 2022
8 Oct 10, 2022

Scrapegoat is a python library that can be used to scrape the websites from internet based on the relevance of the given topic irrespective of language using Natural Language Processing
Scrapegoat is a python library that can be used to scrape the websites from internet based on the relevance of the given topic irrespective of language using Natural Language Processing. It can be mainly used for non-English language to get accurate and relevant scraped text.
 10 Jul 6, 2022
10 Jul 6, 2022

LSTM model trained on a small dataset of 3000 names written in PyTorch
LSTM model trained on a small dataset of 3000 names. Model generates names from model by selecting one out of top 3 letters suggested by model at a time until an EOS (End Of Sentence) character is not encountered.
 1 Dec 20, 2021
1 Dec 20, 2021
A gamey, snakey esoteric programming language
Snak Snak is an esolang based on the classic snake game. Installation You will need python3. To use the visualizer, you will need the curses module. T
 3 Oct 10, 2022
3 Oct 10, 2022
An AI for Music Generation
An AI for Music Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Le dataset des images du projet d'IA de 2021
face-mask-dataset-ilc-2021 Le dataset des images du projet d'IA de 2021, Indiquez vos id git dans la issue pour les droits TL;DR: Choisir 200 images J
 7 Nov 15, 2021
7 Nov 15, 2021
Human Activity Recognition example using TensorFlow on smartphone sensors dataset and an LSTM RNN. Classifying the type of movement amongst six activity categories - Guillaume Chevalier
LSTMs for Human Activity Recognition Human Activity Recognition (HAR) using smartphones dataset and an LSTM RNN. Classifying the type of movement amon
 3.1k Dec 30, 2022
3.1k Dec 30, 2022

TensorFlow Implementation of Unsupervised Cross-Domain Image Generation
Domain Transfer Network (DTN) TensorFlow implementation of Unsupervised Cross-Domain Image Generation. Requirements Python 2.7 TensorFlow 0.12 Pickle
 864 Dec 30, 2022
864 Dec 30, 2022

TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
902 Nov 29, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022

CPPE - 5 (Medical Personal Protective Equipment) is a new challenging object detection dataset
CPPE - 5 CPPE - 5 (Medical Personal Protective Equipment) is a new challenging dataset with the goal to allow the study of subordinate categorization
 53 Dec 17, 2022
53 Dec 17, 2022
🏆 • 5050 most frequent words in 109 languages
🏆 Most Common Words Multilingual 5000 most frequent words in 109 languages. Uses wordfrequency.info as a source. 🔗 License source code license data
 14 Nov 24, 2022
14 Nov 24, 2022
LTGen provides classic algorithms used in Language Theory.
LTGen LTGen stands for Language Theory GENerator and provides tools to implement language theory. Command Line LTGen is a collection of tools to imple
 1 Jan 7, 2022
1 Jan 7, 2022