488 Repositories
Python natural Libraries
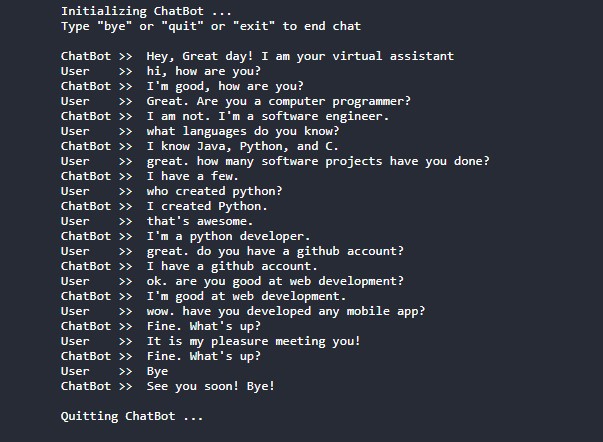
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022

A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
 335 Jan 4, 2023
335 Jan 4, 2023
Flybirds - BDD-driven natural language automated testing framework, present by Trip Flight
Flybird | English Version 行为驱动开发(Behavior-driven development,缩写BDD),是一种软件过程的思想或者
 706 Dec 30, 2022
706 Dec 30, 2022

Natural Language Processing for Adverse Drug Reaction (ADR) Detection
Natural Language Processing for Adverse Drug Reaction (ADR) Detection This repo contains code from a project to identify ADRs in discharge summaries a
 21 Aug 5, 2022
21 Aug 5, 2022
Adversarial Attacks are Reversible via Natural Supervision
Adversarial Attacks are Reversible via Natural Supervision ICCV2021 Citation @InProceedings{Mao_2021_ICCV, author = {Mao, Chengzhi and Chiquier
 20 May 22, 2022
20 May 22, 2022
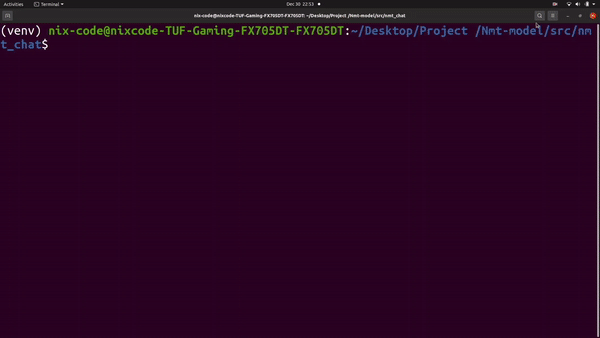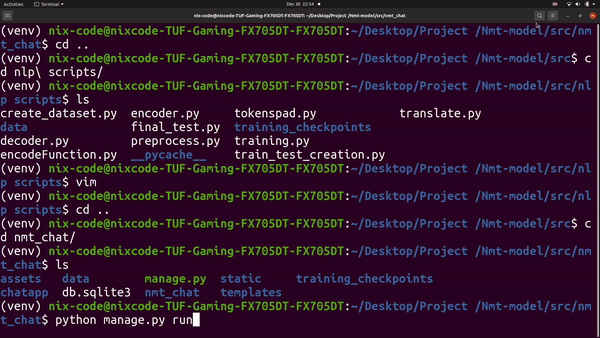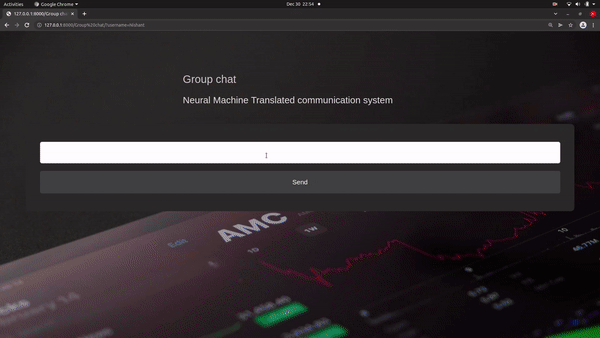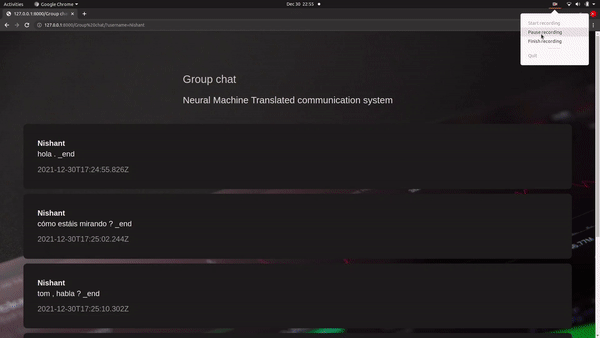
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
 7 Sep 22, 2022
7 Sep 22, 2022
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
MixText This repo contains codes for the following paper: Jiaao Chen, Zichao Yang, Diyi Yang: MixText: Linguistically-Informed Interpolation of Hidden
 309 Dec 12, 2022
309 Dec 12, 2022
Ecco is a python library for exploring and explaining Natural Language Processing models using interactive visualizations.
Visualize, analyze, and explore NLP language models. Ecco creates interactive visualizations directly in Jupyter notebooks explaining the behavior of Transformer-based language models (like GPT2, BERT, RoBERTA, T5, and T0).
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Python library for parsing resumes using natural language processing and machine learning
CVParser Python library for parsing resumes using natural language processing and machine learning. Setup Installation on Linux and Mac OS Follow the
 0 Jul 29, 2021
0 Jul 29, 2021
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
 2 Oct 22, 2022
2 Oct 22, 2022
Fast, DB Backed pretrained word embeddings for natural language processing.
Embeddings Embeddings is a python package that provides pretrained word embeddings for natural language processing and machine learning. Instead of lo
 212 Nov 21, 2022
212 Nov 21, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.
ALiBi PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. Quickstart Clone this reposit
 4 Jul 27, 2022
4 Jul 27, 2022
🍋 A Python package to process food
Pyfood is a simple Python package to process food, in different languages. Pyfood's ambition is to be the go-to library to deal with food, recipes, on
 8 Apr 4, 2022
8 Apr 4, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology (EARIST)
🤖 Coeus - EARIST A.C.E 💬 Coeus is an Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology,
 3 Oct 14, 2022
3 Oct 14, 2022
[PNAS2021] The neural architecture of language: Integrative modeling converges on predictive processing
The neural architecture of language: Integrative modeling converges on predictive processing Code accompanying the paper The neural architecture of la
 36 Dec 1, 2022
36 Dec 1, 2022
Source code of SIGIR2021 Paper 'One Chatbot Per Person: Creating Personalized Chatbots based on Implicit Profiles'
DHAP Source code of SIGIR2021 Long Paper: One Chatbot Per Person: Creating Personalized Chatbots based on Implicit User Profiles . Preinstallation Fir
 32 Dec 6, 2022
32 Dec 6, 2022

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP)
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP) predictions: part-of-speech (POS) tags, chunking (CHK), name entity recognition (NER), semantic role labeling (SRL) and syntactic parsing (PSG) with skip-gram all in Python and still more features will be added. The website give is for downlarding Senna tool
 20 Apr 30, 2022
20 Apr 30, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023

Scrapegoat is a python library that can be used to scrape the websites from internet based on the relevance of the given topic irrespective of language using Natural Language Processing
Scrapegoat is a python library that can be used to scrape the websites from internet based on the relevance of the given topic irrespective of language using Natural Language Processing. It can be mainly used for non-English language to get accurate and relevant scraped text.
 10 Jul 6, 2022
10 Jul 6, 2022
🏆 • 5050 most frequent words in 109 languages
🏆 Most Common Words Multilingual 5000 most frequent words in 109 languages. Uses wordfrequency.info as a source. 🔗 License source code license data
 14 Nov 24, 2022
14 Nov 24, 2022

Healthsea is a spaCy pipeline for analyzing user reviews of supplementary products for their effects on health.
Welcome to Healthsea ✨ Create better access to health with spaCy. Healthsea is a pipeline for analyzing user reviews to supplement products by extract
 75 Dec 19, 2022
75 Dec 19, 2022
BERT, LDA, and TFIDF based keyword extraction in Python
BERT, LDA, and TFIDF based keyword extraction in Python kwx is a toolkit for multilingual keyword extraction based on Google's BERT and Latent Dirichl
 41 Dec 27, 2022
41 Dec 27, 2022

BERT-based Financial Question Answering System
BERT-based Financial Question Answering System In this example, we use Jina, PyTorch, and Hugging Face transformers to build a production-ready BERT-b
 61 Sep 18, 2022
61 Sep 18, 2022

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
Few-shot Natural Language Generation for Task-Oriented Dialog
Few-shot Natural Language Generation for Task-Oriented Dialog This repository contains the dataset, source code and trained model for the following pa
 172 Dec 13, 2022
172 Dec 13, 2022
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Dis
 1.2k Jan 3, 2023
1.2k Jan 3, 2023
CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT This repo provides the code for reproducing the experiments in CodeBERT: A Pre-Trained Model for Programming and Natural Languages. CodeBERT
1k Jan 3, 2023

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
PyContinual (An Easy and Extendible Framework for Continual Learning)
PyContinual (An Easy and Extendible Framework for Continual Learning) Easy to Use You can sumply change the baseline, backbone and task, and then read
 176 Jan 5, 2023
176 Jan 5, 2023
The King is Naked: on the Notion of Robustness for Natural Language Processing
the-king-is-naked: on the notion of robustness for natural language processing AAAI2022 DISCLAIMER:This repo will be updated soon with instructions on
 1 Nov 24, 2022
1 Nov 24, 2022

The projects lets you extract glossary words and their definitions from a given piece of text automatically using NLP techniques
Unsupervised technique to Glossary and Definition Extraction Code Files GPT2-DefinitionModel.ipynb - GPT-2 model for definition generation. Data_Gener
 28 May 25, 2021
28 May 25, 2021

A toolkit for document-level event extraction, containing some SOTA model implementations
❤️ A Toolkit for Document-level Event Extraction with & without Triggers Hi, there 👋 . Thanks for your stay in this repo. This project aims at buildi
 159 Dec 22, 2022
159 Dec 22, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Official implementation of the paper "Lightweight Deep CNN for Natural Image Matting via Similarity Preserving Knowledge Distillation"
Lightweight-Deep-CNN-for-Natural-Image-Matting-via-Similarity-Preserving-Knowledge-Distillation Introduction Accepted at IEEE Signal Processing Letter
 19 Jun 7, 2022
19 Jun 7, 2022
These are the materials for the paper "Few-Shot Out-of-Domain Transfer Learning of Natural Language Explanations"
Few-shot-NLEs These are the materials for the paper "Few-Shot Out-of-Domain Transfer Learning of Natural Language Explanations". You can find the smal
 0 Oct 21, 2022
0 Oct 21, 2022
Tools for teachers and students using nng (Natural Number Game)
nngtools Usage Place your nngsave.json to the directory in which you want to extract the level files. Place nngmap.json on the same directory. Run nng
 1 Dec 12, 2021
1 Dec 12, 2021

📜Generate poetry with gcc diagnostics
gado (gcc awesome diagnostics orchestrator) is a wrapper of gcc that outputs its errors and warnings in a more poetic format.
 19 Jun 25, 2022
19 Jun 25, 2022

In-memory Graph Database and Knowledge Graph with Natural Language Interface, compatible with Pandas
CogniPy for Pandas - In-memory Graph Database and Knowledge Graph with Natural Language Interface Whats in the box Reasoning, exploration of RDF/OWL,
 34 Dec 13, 2022
34 Dec 13, 2022
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

State-of-the-art NLP through transformer models in a modular design and consistent APIs.
Trapper (Transformers wRAPPER) Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps h
 42 Sep 21, 2022
42 Sep 21, 2022
This repository implements a brute-force spellchecker utilizing the Damerau-Levenshtein edit distance.
About spellchecker.py Implementing a highly-accurate, brute-force, and dynamically programmed spellchecking program that utilizes the Damerau-Levensht
 1 Dec 11, 2021
1 Dec 11, 2021
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
922 Dec 10, 2021

CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks
CALVIN CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks Oier Mees, Lukas Hermann, Erick Rosete,
 107 Dec 26, 2022
107 Dec 26, 2022

Hashformers is a framework for hashtag segmentation with transformers.
Hashtag segmentation is the task of automatically inserting the missing spaces between the words in a hashtag. Hashformers applies Transformer models
 41 Nov 9, 2022
41 Nov 9, 2022

Meandering In Networks of Entities to Reach Verisimilar Answers
MINERVA Meandering In Networks of Entities to Reach Verisimilar Answers Code and models for the paper Go for a Walk and Arrive at the Answer - Reasoni
 271 Dec 13, 2022
271 Dec 13, 2022
![[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining](https://github.com/microsoft/COCO-LM/raw/main/coco-lm.png)
[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
COCO-LM This repository contains the scripts for fine-tuning COCO-LM pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: COCO-LM: Correcting an
106 Dec 12, 2022
A design of MIDI language for music generation task, specifically for Natural Language Processing (NLP) models.
MIDI Language Introduction Reference Paper: Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions: code This
 3 May 25, 2022
3 May 25, 2022
NL-Augmenter 🦎 → 🐍 A Collaborative Repository of Natural Language Transformations
NL-Augmenter 🦎 → 🐍 The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformat
 684 Jan 9, 2023
684 Jan 9, 2023
Train and use generative text models in a few lines of code.
blather Train and use generative text models in a few lines of code. To see blather in action check out the colab notebook! Installation Use the packa
 16 Nov 7, 2022
16 Nov 7, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

This repository provides code for "On Interaction Between Augmentations and Corruptions in Natural Corruption Robustness".
On Interaction Between Augmentations and Corruptions in Natural Corruption Robustness This repository provides the code for the paper On Interaction B
 33 Dec 8, 2022
33 Dec 8, 2022
Natural Language Processing Tasks and Examples.
Natural Language Processing Tasks and Examples With the advancement of A.I. technology in recent years, natural language processing technology has bee
 53 Dec 20, 2022
53 Dec 20, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
 463 Dec 30, 2022
463 Dec 30, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
7.1k Jan 1, 2023
Code for Editing Factual Knowledge in Language Models
KnowledgeEditor Code for Editing Factual Knowledge in Language Models (https://arxiv.org/abs/2104.08164). @inproceedings{decao2021editing, title={Ed
 86 Nov 28, 2022
86 Nov 28, 2022
A Model for Natural Language Attack on Text Classification and Inference
TextFooler A Model for Natural Language Attack on Text Classification and Inference This is the source code for the paper: Jin, Di, et al. "Is BERT Re
 418 Dec 16, 2022
418 Dec 16, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022
Code associated with the Don't Stop Pretraining ACL 2020 paper
dont-stop-pretraining Code associated with the Don't Stop Pretraining ACL 2020 paper Citation @inproceedings{dontstoppretraining2020, author = {Suchi
 449 Jan 4, 2023
449 Jan 4, 2023
Multi-Task Deep Neural Networks for Natural Language Understanding
New Release We released Adversarial training for both LM pre-training/finetuning and f-divergence. Large-scale Adversarial training for LMs: ALUM code
 2.1k Dec 30, 2022
2.1k Dec 30, 2022

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022
This repository contains the code for "Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference"
Pattern-Exploiting Training (PET) This repository contains the code for Exploiting Cloze Questions for Few-Shot Text Classification and Natural Langua
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022
PyContinual (An Easy and Extendible Framework for Continual Learning)
PyContinual (An Easy and Extendible Framework for Continual Learning) Easy to Use You can sumply change the baseline, backbone and task, and then read
176 Jan 5, 2023

Code for models used in Bashiri et al., "A Flow-based latent state generative model of neural population responses to natural images".
A Flow-based latent state generative model of neural population responses to natural images Code for "A Flow-based latent state generative model of ne
 5 Aug 26, 2022
5 Aug 26, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
 124 Jan 2, 2023
124 Jan 2, 2023
Various Algorithms for Short Text Mining
Short Text Mining in Python Introduction This package shorttext is a Python package that facilitates supervised and unsupervised learning for short te
 466 Dec 6, 2022
466 Dec 6, 2022
This repository contains the implementation of the paper: Federated Distillation of Natural Language Understanding with Confident Sinkhorns
Federated Distillation of Natural Language Understanding with Confident Sinkhorns This repository provides an alternative method for ensembled distill
 11 Nov 16, 2022
11 Nov 16, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

Official implementation for: Blended Diffusion for Text-driven Editing of Natural Images.
Blended Diffusion for Text-driven Editing of Natural Images Blended Diffusion for Text-driven Editing of Natural Images Omri Avrahami, Dani Lischinski
 328 Dec 30, 2022
328 Dec 30, 2022

Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Vedaldi, Andrew Zisserman, CVPR 2016.
SynthText Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Ved
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

An optimized prompt tuning strategy comparable to fine-tuning across model scales and tasks.
P-tuning v2 P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks An optimized prompt tuning strategy achievi
 162 Nov 29, 2021
162 Nov 29, 2021
Training open neural machine translation models
Train Opus-MT models This package includes scripts for training NMT models using MarianNMT and OPUS data for OPUS-MT. More details are given in the Ma
 167 Jan 3, 2023
167 Jan 3, 2023
A lightweight Python module and command-line tool for generating NATO APP-6(D) compliant military symbols from both ID codes and natural language names
Python military symbols This is a lightweight Python module, including a command-line script, to generate NATO APP-6(D) compliant military symbol icon
 5 Dec 27, 2022
5 Dec 27, 2022
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021

Official pytorch implementation of the paper: "SinGAN: Learning a Generative Model from a Single Natural Image"
SinGAN Project | Arxiv | CVF | Supplementary materials | Talk (ICCV`19) Official pytorch implementation of the paper: "SinGAN: Learning a Generative M
 3.2k Dec 25, 2022
3.2k Dec 25, 2022
A paper list for aspect based sentiment analysis.
Aspect-Based-Sentiment-Analysis A paper list for aspect based sentiment analysis. Survey [IEEE-TAC-20]: Issues and Challenges of Aspect-based Sentimen
 419 Dec 20, 2022
419 Dec 20, 2022

Official repository for Natural Image Matting via Guided Contextual Attention
GCA-Matting: Natural Image Matting via Guided Contextual Attention The source codes and models of Natural Image Matting via Guided Contextual Attentio
 349 Dec 26, 2022
349 Dec 26, 2022
🧪 Cutting-edge experimental spaCy components and features
spacy-experimental: Cutting-edge experimental spaCy components and features This package includes experimental components and features for spaCy v3.x,
65 Dec 30, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
State of the art faster Natural Language Processing in Tensorflow 2.0 .
tf-transformers: faster and easier state-of-the-art NLP in TensorFlow 2.0 ****************************************************************************
 74 Dec 5, 2022
74 Dec 5, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
A natural language modeling framework based on PyTorch
Overview PyText is a deep-learning based NLP modeling framework built on PyTorch. PyText addresses the often-conflicting requirements of enabling rapi
6.4k Jan 8, 2023
CEI Natural Disaster Tracking Portal
CEI Natural Disaster Tracking Portal (cc) Climatic Eye of ISCI We are an initiative that conducts studies in the field of Space Science, publishes pro
 7 Dec 24, 2022
7 Dec 24, 2022

Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models.
Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models. Solve a variety of tasks with pre-trained models or finetune them in
 227 Dec 10, 2022
227 Dec 10, 2022

This repo contains implementation of different architectures for emotion recognition in conversations.
Emotion Recognition in Conversations Updates 🔥 🔥 🔥 Date Announcements 03/08/2021 🎆 🎆 We have released a new dataset M2H2: A Multimodal Multiparty
1k Dec 30, 2022

BookNLP, a natural language processing pipeline for books
BookNLP BookNLP is a natural language processing pipeline that scales to books and other long documents (in English), including: Part-of-speech taggin
 654 Jan 2, 2023
654 Jan 2, 2023
Stanza: A Python NLP Library for Many Human Languages
Official Stanford NLP Python Library for Many Human Languages
 5.8k Nov 22, 2021
5.8k Nov 22, 2021
How to use TensorLayer
How to use TensorLayer While research in Deep Learning continues to improve the world, we use a bunch of tricks to implement algorithms with TensorLay
 349 Dec 7, 2022
349 Dec 7, 2022

BERT score for text generation
BERTScore Automatic Evaluation Metric described in the paper BERTScore: Evaluating Text Generation with BERT (ICLR 2020). News: Features to appear in
 1k Jan 8, 2023
1k Jan 8, 2023
NLP and Text Generation Experiments in TensorFlow 2.x / 1.x
Code has been run on Google Colab, thanks Google for providing computational resources Contents Natural Language Processing(自然语言处理) Text Classificati
 1.5k Nov 14, 2022
1.5k Nov 14, 2022
TensorFlow code and pre-trained models for BERT
BERT ***** New March 11th, 2020: Smaller BERT Models ***** This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece
 32.9k Jan 8, 2023
32.9k Jan 8, 2023
Example code for "Real-World Natural Language Processing"
Real-World Natural Language Processing This repository contains example code for the book "Real-World Natural Language Processing." AllenNLP (2.5.0 or
 303 Dec 17, 2022
303 Dec 17, 2022