2527 Repositories
Python noaa-data Libraries
Data portal client and server for NMDC.
NMDC Server and Client Portal Getting started with Docker install ldc install submodules via git submodule update --init --recursive In order to popul
 7 Dec 14, 2022
7 Dec 14, 2022
A simple web to serve data table. It is built with Vuetify, Vue, FastApi.
simple-report-data-table-vuetify A simple web to serve data table. It is built with Vuetify, Vue, FastApi. The main features: RBAC with casbin simple
 11 Dec 22, 2022
11 Dec 22, 2022
Tools, guides, and resources for blockchain analysts to interface with data on the Ergo platform.
Ergo Intelligence Objective Provide a suite of easy-to-use toolkits, guides, and resources for blockchain analysts and data scientists to quickly unde
 5 Mar 15, 2022
5 Mar 15, 2022
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
Utilize data analytics skills to solve real-world business problems using Humana’s big data
Humana-Mays-2021-HealthCare-Analytics-Case-Competition- The goal of the project is to utilize data analytics skills to solve real-world business probl
 1 Dec 27, 2021
1 Dec 27, 2021
Data Model built using Logistic Regression Algorithm on Python.
Logistic-Regression Problem Statement: Your client is a retail banking institution. Term deposits are a major source of income for a bank. A term depo
 0 Dec 25, 2021
0 Dec 25, 2021
A simply dashboard to view commodities position data based on CFTC reports
commodities-dashboard A simply dashboard to view commodities position data based on CFTC reports This is a python project using Dash and plotly to con
 71 Dec 19, 2022
71 Dec 19, 2022
A Python package to request and process seismic waveform data from Hi-net.
HinetPy is a Python package to simplify tedious data request, download and format conversion tasks related to NIED Hi-net. NIED Hi-net | Source Code |
 65 Dec 9, 2022
65 Dec 9, 2022
🍋 A Python package to process food
Pyfood is a simple Python package to process food, in different languages. Pyfood's ambition is to be the go-to library to deal with food, recipes, on
 8 Apr 4, 2022
8 Apr 4, 2022

Sequence lineage information extracted from RKI sequence data repo
Pango lineage information for German SARS-CoV-2 sequences This repository contains a join of the metadata and pango lineage tables of all German SARS-
 24 Oct 26, 2022
24 Oct 26, 2022
Python Steganography data hiding in image
Python-Steganography Python Steganography data hiding in image data encryption and decryption im here you have to import stepic module 1.open CMD 2.ty
 10 Jul 13, 2022
10 Jul 13, 2022
Pandas and Spark DataFrame comparison for humans
DataComPy DataComPy is a package to compare two Pandas DataFrames. Originally started to be something of a replacement for SAS's PROC COMPARE for Pand
 259 Dec 24, 2022
259 Dec 24, 2022

BisQue is a web-based platform designed to provide researchers with organizational and quantitative analysis tools for 5D image data. Users can extend BisQue by implementing containerized ML workflows.
Overview BisQue is a web-based platform specifically designed to provide researchers with organizational and quantitative analysis tools for up to 5D
 26 Nov 29, 2022
26 Nov 29, 2022
Python package to transfer data in a fast, reliable, and packetized form.
pySerialTransfer Python package to transfer data in a fast, reliable, and packetized form.
 101 Dec 7, 2022
101 Dec 7, 2022
Run python scripts and pass data between multiple python and node processes using this npm module
Run python scripts and pass data between multiple python and node processes using this npm module. process-communication has a event based architecture for interacting with python data and errors inside nodejs.
 2 Aug 6, 2021
2 Aug 6, 2021
Python package for analyzing behavioral data for Brain Observatory: Visual Behavior
Allen Institute Visual Behavior Analysis package This repository contains code for analyzing behavioral data from the Allen Brain Observatory: Visual
 16 Nov 4, 2022
16 Nov 4, 2022
Brownant is a web data extracting framework.
Brownant Brownant is a lightweight web data extracting framework. Who uses it? At the moment, dongxi.douban.com (a.k.a. Douban Dongxi) uses Brownant i
 157 Jan 6, 2022
157 Jan 6, 2022
Neptune client library - integrate your Python scripts with Neptune
Lightweight experiment tracking tool for AI/ML individuals and teams. Fits any workflow. Neptune is a lightweight experiment logging/tracking tool tha
 353 Jan 4, 2023
353 Jan 4, 2023
PYGA: Python Google Analytics (ga.js) - Data Collection API
PYGA: Python Google Analytics - Data Collection API pyga is an implementation of Google Analytics (ga.js) in Python; so that it can be used at server
 136 Sep 19, 2022
136 Sep 19, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023
Object-data mapper and advanced query manager for non relational databases
Object data mapper and advanced query manager for non relational databases. The data is owned by different, configurable back-end databases and it is
 121 Aug 11, 2022
121 Aug 11, 2022
A Pytorch Implementation of Source Data-free Domain Adaptation for a Faster R-CNN
A Pytorch Implementation of Source Data-free Domain Adaptation for a Faster R-CNN Please follow Faster R-CNN and DAF to complete the environment confi
 2 Jan 12, 2022
2 Jan 12, 2022
A Pytorch Implementation of [Source data‐free domain adaptation of object detector through domain
A Pytorch Implementation of Source data‐free domain adaptation of object detector through domain‐specific perturbation Please follow Faster R-CNN and
1 Dec 25, 2021

Manage large and heterogeneous data spaces on the file system.
signac - simple data management The signac framework helps users manage and scale file-based workflows, facilitating data reuse, sharing, and reproduc
 109 Dec 14, 2022
109 Dec 14, 2022
LynxKite: a complete graph data science platform for very large graphs and other datasets.
LynxKite is a complete graph data science platform for very large graphs and other datasets. It seamlessly combines the benefits of a friendly graphical interface and a powerful Python API.
 124 Dec 14, 2022
124 Dec 14, 2022
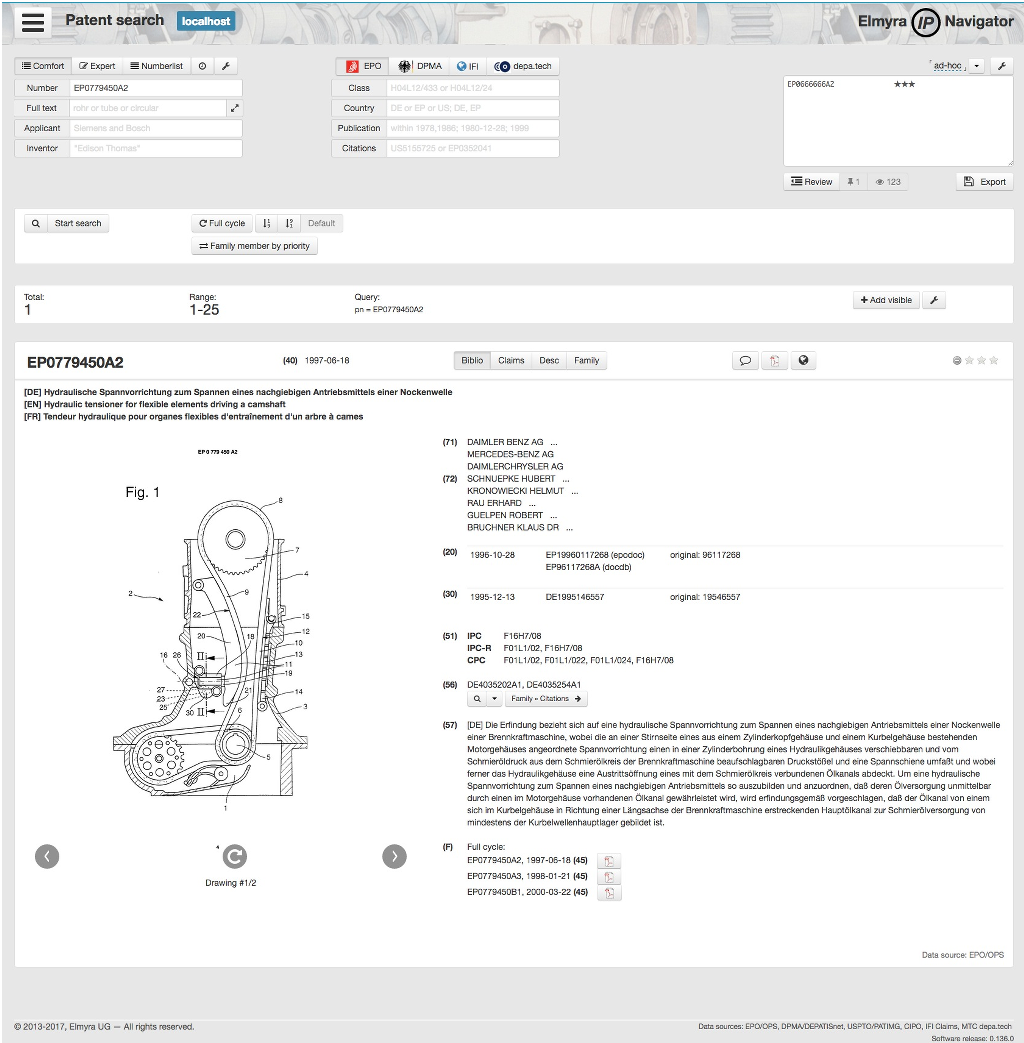
PatZilla is a modular patent information research platform and data integration toolkit with a modern user interface and access to multiple data sources.
PatZilla is a modular patent information research platform and data integration toolkit with a modern user interface and access to multiple data sources.
 68 Dec 14, 2022
68 Dec 14, 2022
Picka: A Python module for data generation and randomization.
Picka: A Python module for data generation and randomization. Author: Anthony Long Version: 1.0.1 - Fixed the broken image stuff. Whoops What is Picka
 108 Nov 30, 2021
108 Nov 30, 2021
A flexible data historian based on InfluxDB, Grafana, MQTT and more. Free, open, simple.
Kotori Telemetry data acquisition and sensor networks for humans. Documentation: https://getkotori.org/ Source Code: https://github.com/daq-tools/koto
 83 Nov 26, 2022
83 Nov 26, 2022
Terkin is a flexible data logger application for MicroPython and CPython environments.
Terkin Data logging for humans, written in MicroPython. Documentation: https://terkin.org/ Source Code: https://github.com/hiveeyes/terkin-datalogger
 45 Dec 15, 2022
45 Dec 15, 2022
FauxFactory generates random data for your automated tests easily!
FauxFactory FauxFactory generates random data for your automated tests easily! There are times when you're writing tests for your application when you
 37 Sep 23, 2022
37 Sep 23, 2022
Zen-Knit is a formal (PDF), informal (HTML) report generator for data analyst and data scientist who wants to use python.
About Zen-Knit: Zen-Knit is a formal (PDF), informal (HTML) report generator for data analyst and data scientist who wants to use python. Inspired fro
 27 Jul 13, 2022
27 Jul 13, 2022

This application works with serial communication. Use a simple gui to send and receive serial data from arduino and control leds and motor direction
This application works with serial communication. Use a simple gui to send and receive serial data from arduino and control leds and motor direction
 2 Jul 18, 2022
2 Jul 18, 2022
Spaghetti: an open-source Python library for the analysis of network-based spatial data
pysal/spaghetti SPAtial GrapHs: nETworks, Topology, & Inference Spaghetti is an open-source Python library for the analysis of network-based spatial d
 203 Jan 3, 2023
203 Jan 3, 2023
Resources for teaching & learning practical data visualization with python.
Practical Data Visualization with Python Overview All views expressed on this site are my own and do not represent the opinions of any entity with whi
 98 Sep 24, 2022
98 Sep 24, 2022
Bringing sanity to world of messed-up data
Sanitize sanitize is a Python module for making sure various things (e.g. HTML) are safe to use. It was originally written by Mark Pilgrim and is dist
 63 Oct 26, 2021
63 Oct 26, 2021
This library is a location of the LegacyLogger for PyTorch Lightning.
neptune-contrib Documentation See neptune-contrib documentation site Installation Get prerequisites python versions 3.5.6/3.6 are supported Install li
26 Oct 7, 2021
Data Structure With Python
Data-Structure-With-Python- Python programs also include in this repo Stack A stack is a linear data structure that stores items in a Last-In/First-Ou
 2 Jan 9, 2022
2 Jan 9, 2022

Cisco IOS-XE Operations Program. Shows operational data using restconf and yang
XE-Ops View operational and config data from devices running Cisco IOS-XE software. NoteS The build folder is the latest build. All other files are fo
 18 Jul 23, 2022
18 Jul 23, 2022
Create Data & AI apps in 20 lines of code with Shimoku
Install with: pip install shimoku-api-python Start with: from os import getenv import shimoku_api_python.client as Shimoku
 5 Nov 7, 2022
5 Nov 7, 2022
A websocket client for Source Filmmaker intended to trasmit scene and frame data to other applications.
SFM SOCK A websocket client for Source Filmmaker intended to trasmit scene and frame data to other applications. This software can be used to transmit
 2 Jan 8, 2022
2 Jan 8, 2022

Program Input Data Mahasiswa Oop
PROGRAM INPUT NILAI MAHASISWA MENGGUNAKAN OOP PENGERTIAN OOP object-oriented-programing/OOP adalah paradigma pemrograman berdasarkan konsep "objek", y
 1 Jan 5, 2022
1 Jan 5, 2022
BioThings API framework - Making high-performance API for biological annotation data
BioThings SDK Quick Summary BioThings SDK provides a Python-based toolkit to build high-performance data APIs (or web services) from a single data sou
 39 Jan 4, 2023
39 Jan 4, 2023

A web-based app that allows easy, simple - and if desired high-throughput - analysis of qPCR data
qpcr-Analyser A web-based GUI for the qpcr package that allows easy, simple and high-throughput analysis of qPCR data. As is described in more detail
 1 Sep 13, 2022
1 Sep 13, 2022

Example Code Notebooks for Data Visualization in Python
This repository contains sample code scripts for creating awesome data visualizations from scratch using different python libraries (such as matplotli
 27 Jan 4, 2023
27 Jan 4, 2023
Python package for the analysis and visualisation of finite-difference fields.
discretisedfield Marijan Beg1,2, Martin Lang2, Samuel Holt3, Ryan A. Pepper4, Hans Fangohr2,5,6 1 Department of Earth Science and Engineering, Imperia
 12 Dec 14, 2022
12 Dec 14, 2022
Combine XPath, CSS Selectors and JSONPath for Web data extracting.
Data Extractor Combine XPath, CSS Selectors and JSONPath for Web data extracting. Quickstarts Installation Install the stable version from PYPI. pip i
 27 Oct 22, 2022
27 Oct 22, 2022
A query expression for extracting data from JSON.
JSONPATH A selector expression for extracting data from JSON. Quickstarts Installation Install the stable version from PYPI. pip install jsonpath-extr
33 Oct 22, 2022
Elasticsearch tool for easily collecting and batch inserting Python data and pandas DataFrames
ElasticBatch Elasticsearch buffer for collecting and batch inserting Python data and pandas DataFrames Overview ElasticBatch makes it easy to efficien
 21 Mar 16, 2022
21 Mar 16, 2022
Python API for HotBits random data generator
HotBits Python API Python API for HotBits random data generator. Description This project is random data generator. It uses is HotBits API web service
 2 Sep 11, 2020
2 Sep 11, 2020
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
Redash is designed to enable anyone, regardless of the level of technical sophistication, to harness the power of data big and small. SQL users levera
 22.4k Dec 30, 2022
22.4k Dec 30, 2022
Python3 command-line tool for the inference of Boolean rules and pathway analysis on omics data
BONITA-Python3 BONITA was originally written in Python 2 and tested with Python 2-compatible packages. This version of the packages ports BONITA to Py
 1 Dec 22, 2021
1 Dec 22, 2021

Turn any live video stream or locally stored video into a dataset of interesting samples for ML training, or any other type of analysis.
Sieve Video Data Collection Example Find samples that are interesting within hours of raw video, for free and completely automatically using Sieve API
 72 Aug 1, 2022
72 Aug 1, 2022

Code for MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks This is the code for the paper: MentorNet: Learning Data-Driven Curriculum fo
 302 Dec 23, 2022
302 Dec 23, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
AKShare is an elegant and simple financial data interface library for Python, built for human beings
AKShare is an elegant and simple financial data interface library for Python, built for human beings
 5.8k Dec 30, 2022
5.8k Dec 30, 2022
Tools and data for measuring the popularity & growth of various programming languages.
growth-data Tools and data for measuring the popularity & growth of various programming languages. Install the dependencies $ pip install -r requireme
 3 Jan 6, 2022
3 Jan 6, 2022
Monitor the stability of a pandas or spark dataframe ⚙︎
Population Shift Monitoring popmon is a package that allows one to check the stability of a dataset. popmon works with both pandas and spark datasets.
 403 Dec 7, 2022
403 Dec 7, 2022
CleverCSV is a Python package for handling messy CSV files.
CleverCSV is a Python package for handling messy CSV files. It provides a drop-in replacement for the builtin CSV module with improved dialect detection, and comes with a handy command line application for working with CSV files.
 1k Dec 19, 2022
1k Dec 19, 2022

This repository provides data for the VAW dataset as described in the CVPR 2021 paper titled "Learning to Predict Visual Attributes in the Wild"
Visual Attributes in the Wild (VAW) This repository provides data for the VAW dataset as described in the CVPR 2021 Paper: Learning to Predict Visual
 36 Dec 30, 2022
36 Dec 30, 2022
A CLI tool to reduce the friction between data scientists by reducing git conflicts removing notebook metadata and gracefully resolving git conflicts.
databooks is a package for reducing the friction data scientists while using Jupyter notebooks, by reducing the number of git conflicts between different notebooks and assisting in the resolution of the conflicts.
 86 Dec 25, 2022
86 Dec 25, 2022

Credo AI Lens is a comprehensive assessment framework for AI systems. Lens standardizes model and data assessment, and acts as a central gateway to assessments created in the open source community.
Lens by Credo AI - Responsible AI Assessment Framework Lens is a comprehensive assessment framework for AI systems. Lens standardizes model and data a
 27 Dec 14, 2022
27 Dec 14, 2022
A Python wrapper API for operating and working with the Neo4j Graph Data Science (GDS) library
gdsclient NOTE: This is a work in progress and many GDS features are known to be missing or not working properly. This repo hosts the sources for gdsc
 100 Dec 20, 2022
100 Dec 20, 2022
All course materials for the Zero to Mastery Machine Learning and Data Science course.
Zero to Mastery Machine Learning Welcome! This repository contains all of the code, notebooks, images and other materials related to the Zero to Maste
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
Repositório do Projeto de Jogo da Resília Educação.
Jogo da Segurança das Indústrias Acme Descrição Este jogo faz parte do projeto de entrega do primeiro módulo da Resilia Educação, referente ao curso d
 2 Apr 28, 2022
2 Apr 28, 2022
🔮 A usefull set of scripts to dig into your Discord data package.
Discord DataExtractor 🔮 Discord DataExtractor is a set of scripts that allows you to dig into your Discord Data package. Repository guide ☕ Coffee_Ga
 3 Dec 29, 2021
3 Dec 29, 2021
🍰 ConnectMP - An easy and efficient way to share data between Processes in Python.
ConnectMP - Taking Multi-Process Data Sharing to the moon 🚀 Contribute · Community · Documentation 🎫 Introduction : 🍤 ConnectMP is the easiest and
 1 Dec 24, 2021
1 Dec 24, 2021
A Python wrapper API for operating and working with the Neo4j Graph Data Science (GDS) library
gdsclient This repo hosts the sources for gdsclient, a Python wrapper API for operating and working with the Neo4j Graph Data Science (GDS) library. g
 101 Jan 5, 2023
101 Jan 5, 2023

This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs".
CrossSum This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summ
 29 Nov 19, 2022
29 Nov 19, 2022
Official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.
GLIDE This is the official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing w
 2.9k Jan 4, 2023
2.9k Jan 4, 2023

Quick tutorial on orchest.io that shows how to build multiple deep learning models on your data with a single line of code using python
Deep AutoViML Pipeline for orchest.io Quickstart Build Deep Learning models with a single line of code: deep_autoviml Deep AutoViML helps you build te
 6 Oct 2, 2022
6 Oct 2, 2022
📜 GPT-2 Rhyming Limerick and Haiku models using data augmentation
Well-formed Limericks and Haikus with GPT2 📜 GPT-2 Rhyming Limerick and Haiku models using data augmentation In collaboration with Matthew Korahais &
 2 May 26, 2022
2 May 26, 2022
A desktop application developed in Python with PyQt5 to predict demand and help monitor and schedule brewing processes for Barnaby's Brewhouse.
brewhouse-management A desktop application developed in Python with PyQt5 to predict demand and help monitor and schedule brewing processes for Barnab
 2 Jul 9, 2022
2 Jul 9, 2022
Data Platform com AWS CDK
Welcome to your CDK Python project! This is a blank project for Python development with CDK. The cdk.json file tells the CDK Toolkit how to execute yo
 8 Jul 2, 2022
8 Jul 2, 2022
Get MODBUS data from Sofar (K-TLX) inverter through LSW-3 or LSE module
SOFAR Inverter + LSW-3/LSE Small utility to read data from SOFAR K-TLX inverters through the Solarman (LSW-3/LSE) datalogger. Two scripts to get inver
 58 Dec 29, 2022
58 Dec 29, 2022

Data and analysis relating to the 5.8M Melbourne quake of 2021
quake2021 Data and analysis relating to the 5.8M Melbourne quake of 2021 Monash University Woodside Living Lab Building The building is located here T
 6 May 16, 2022
6 May 16, 2022
Automatic data visualization in atom with the nteract data-explorer
Data Explorer Interactively explore your data directly in atom with hydrogen! The nteract data-explorer provides automatic data visualization, so you
 65 Dec 1, 2022
65 Dec 1, 2022

Tidy data structures, summaries, and visualisations for missing data
naniar naniar provides principled, tidy ways to summarise, visualise, and manipulate missing data with minimal deviations from the workflows in ggplot
 611 Dec 22, 2022
611 Dec 22, 2022
Streaming over lightweight data transformations
Description Data augmentation libarary for Deep Learning, which supports images, segmentation masks, labels and keypoints. Furthermore, SOLT is fast a
 256 Jan 8, 2023
256 Jan 8, 2023
A knowledge base construction engine for richly formatted data
Fonduer is a Python package and framework for building knowledge base construction (KBC) applications from richly formatted data. Note that Fonduer is
 386 Dec 5, 2022
386 Dec 5, 2022

Automatic labeling, conversion of different data set formats, sample size statistics, model cascade
Simple Gadget Collection for Object Detection Tasks Automatic image annotation Conversion between different annotation formats Obtain statistical info
 4 Aug 24, 2022
4 Aug 24, 2022
This is a web crawler that works on employ email data by gmane.org and visualizes it in different ways.
crawler_to_visual_gmane Analyzing an EMAIL Archive from gmane and vizualizing the data using the D3 JavaScript library. This is a set of tools that al
 1 Dec 20, 2021
1 Dec 20, 2021
Base on browser-time to get har from network, and use python to analyze the data .
base on browser-time to get har from network, and use python to analyze the data
 1 Dec 20, 2021
1 Dec 20, 2021

A custom qq-plot for two sample data comparision
QQ-Plot 2 Sample Just a gist to include the custom code to draw a qq-plot in python when dealing with a "two sample problem". This means when u try to
 1 Dec 20, 2021
1 Dec 20, 2021
This script provides LIVE feedback for On-The-Fly data collection with RELION
README This script provides LIVE feedback for On-The-Fly data collection with RELION (very useful to explore already processed datasets too!) Creating
 6 Jul 14, 2022
6 Jul 14, 2022

Fast methods to work with hydro- and topography data in pure Python.
PyFlwDir Intro PyFlwDir contains a series of methods to work with gridded DEM and flow direction datasets, which are key to many workflows in many ear
 27 Dec 7, 2022
27 Dec 7, 2022
Pytorch library for seismic data augmentation
Pytorch library for seismic data augmentation
 27 Nov 22, 2022
27 Nov 22, 2022

A Parameter-free Deep Embedded Clustering Method for Single-cell RNA-seq Data
A Parameter-free Deep Embedded Clustering Method for Single-cell RNA-seq Data Overview Clustering analysis is widely utilized in single-cell RNA-seque
 3 May 8, 2022
3 May 8, 2022
Highly decentralized and censorship-resistant way to store key data
Beacon coin Beacon coin is a Chia singelton coin that can store data that needs to be: always available censorship resistant versioned potentially imm
 24 Oct 4, 2022
24 Oct 4, 2022
Convert Table data to approximate values with GUI
Table_Editor Convert Table data to approximate values with GUIs... usage - Import methods for extension Tables. Imported method supposed to have only
 1 Jan 10, 2022
1 Jan 10, 2022
Python SDK for LUSID by FINBOURNE, a bi-temporal investment management data platform with portfolio accounting capabilities.
LUSID® Python SDK This is the Python SDK for LUSID by FINBOURNE, a bi-temporal investment management data platform with portfolio accounting capabilit
 6 Dec 24, 2022
6 Dec 24, 2022
simple way to build the declarative and destributed data pipelines with python
unipipeline simple way to build the declarative and distributed data pipelines. Why you should use it Declarative strict config Scaffolding Fully type
 0 Jan 26, 2022
0 Jan 26, 2022
Python library for creating data pipelines with chain functional programming
PyFunctional Features PyFunctional makes creating data pipelines easy by using chained functional operators. Here are a few examples of what it can do
 2.1k Jan 5, 2023
2.1k Jan 5, 2023
Automation that uses Github Actions, Google Drive API, YouTube Data API and youtube-dl together to feed BackJam app with new music
Automation that uses Github Actions, Google Drive API, YouTube Data API and youtube-dl together to feed BackJam app with new music
 1 Nov 21, 2021
1 Nov 21, 2021
Evaluation of file formats in the context of geo-referenced 3D geometries.
Geo-referenced Geometry File Formats Classic geometry file formats as .obj, .off, .ply, .stl or .dae do not support the utilization of coordinate syst
 11 Mar 2, 2022
11 Mar 2, 2022

Fast Python reader and editor for ASAM MDF / MF4 (Measurement Data Format) files
asammdf is a fast parser and editor for ASAM (Association for Standardization of Automation and Measuring Systems) MDF (Measurement Data Format) files
 440 Dec 31, 2022
440 Dec 31, 2022
🌎 The Modern Declarative Data Flow Framework for the AI Empowered Generation.
🌎 JSONClasses JSONClasses is a declarative data flow pipeline and data graph framework. Official Website: https://www.jsonclasses.com Official Docume
 53 Dec 9, 2022
53 Dec 9, 2022

A full pipeline AutoML tool for tabular data
HyperGBM Doc | 中文 We Are Hiring! Dear folks,we are offering challenging opportunities located in Beijing for both professionals and students who are k
 240 Jan 3, 2023
240 Jan 3, 2023
Feature Store for Machine Learning
Overview Feast is an open source feature store for machine learning. Feast is the fastest path to productionizing analytic data for model training and
 3.8k Dec 30, 2022
3.8k Dec 30, 2022

A distributed block-based data storage and compute engine
Nebula is an extremely-fast end-to-end interactive big data analytics solution. Nebula is designed as a high-performance columnar data storage and tabular OLAP engine.
 131 Dec 26, 2022
131 Dec 26, 2022

Use .csv files to record, play and evaluate motion capture data.
Purpose These scripts allow you to record mocap data to, and play from .csv files. This approach facilitates parsing of body movement data in statisti
 21 Dec 12, 2022
21 Dec 12, 2022