203 Repositories
Python now-evaluation Libraries
Installation, test and evaluation of Scribosermo speech-to-text engine
Scribosermo STT Setup Scribosermo is a LGPL licensed, open-source speech recognition engine to "Train fast Speech-to-Text networks in different langua
 3 Jun 20, 2022
3 Jun 20, 2022
A toolkit for geo ML data processing and model evaluation (fork of solaris)
An open source ML toolkit for overhead imagery. This is a beta version of lunular which may continue to develop. Please report any bugs through issues
 4 Nov 4, 2021
4 Nov 4, 2021
With Google Drive API. My computer and my phone are in love now.
Channel trought Google Drive Google Drive API In this case, "Google Drive App" is the program. To install everything you need(has some extra things),
 1 Dec 15, 2021
1 Dec 15, 2021
Evaluation of TCP BBRv1 in wireless networks
The Network Simulator, Version 3 Table of Contents: An overview Building ns-3 Running ns-3 Getting access to the ns-3 documentation Working with the d
 3 Nov 1, 2021
3 Nov 1, 2021
Fonts used to be an install-and-forget thing, but many of are now updated regularly.
Your font manager. Fonts used to be an install-and-forget thing, but many of are now updated regularly. fontman helps you keep track of the fonts you
 20 Feb 7, 2022
20 Feb 7, 2022
Facilitating Database Tuning with Hyper-ParameterOptimization: A Comprehensive Experimental Evaluation
A Comprehensive Experimental Evaluation for Database Configuration Tuning This is the source code to the paper "Facilitating Database Tuning with Hype
 9 Oct 29, 2022
9 Oct 29, 2022
Unified MultiWOZ evaluation scripts for the context-to-response task.
MultiWOZ Context-to-Response Evaluation Standardized and easy to use Inform, Success, BLEU ~ See the paper ~ Easy-to-use scripts for standardized eval
 38 Dec 13, 2022
38 Dec 13, 2022
Data, model training, and evaluation code for "PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models".
PubTables-1M This repository contains training and evaluation code for the paper "PubTables-1M: Towards a universal dataset and metrics for training a
 365 Jan 4, 2023
365 Jan 4, 2023
This is a five-step framework for the development of intrusion detection systems (IDS) using machine learning (ML) considering model realization, and performance evaluation.
AB-TRAP: building invisibility shields to protect network devices The AB-TRAP framework is applicable to the development of Network Intrusion Detectio
 17 Jan 4, 2023
17 Jan 4, 2023
Federated_learning codes used for the the paper "Evaluation of Federated Learning Aggregation Algorithms" and "A Federated Learning Aggregation Algorithm for Pervasive Computing: Evaluation and Comparison"
Federated Distance (FedDist) This is the code accompanying the Percom2021 paper "A Federated Learning Aggregation Algorithm for Pervasive Computing: E
 8 Jan 3, 2023
8 Jan 3, 2023

Developed a website to analyze and generate report of students based on the curriculum that represents student’s academic performance.
Developed a website to analyze and generate report of students based on the curriculum that represents student’s academic performance. We have developed the system such that, it will automatically parse data onto the database from excel file, which will in return reduce time consumption of analysis of data.
 3 Nov 8, 2022
3 Nov 8, 2022

Source code for "Taming Visually Guided Sound Generation" (Oral at the BMVC 2021)
Taming Visually Guided Sound Generation • [Project Page] • [ArXiv] • [Poster] • • Listen for the samples on our project page. Overview We propose to t
 226 Jan 3, 2023
226 Jan 3, 2023
Anomaly detection in multi-agent trajectories: Code for training, evaluation and the OpenAI highway simulation.
Anomaly Detection in Multi-Agent Trajectories for Automated Driving This is the official project page including the paper, code, simulation, baseline
 12 Dec 2, 2022
12 Dec 2, 2022
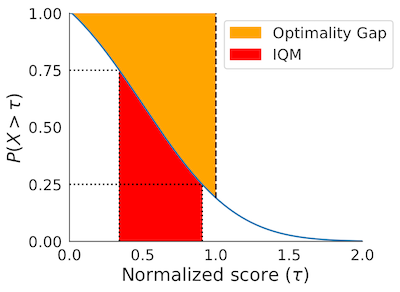
rliable is an open-source Python library for reliable evaluation, even with a handful of runs, on reinforcement learning and machine learnings benchmarks.
Open-source library for reliable evaluation on reinforcement learning and machine learning benchmarks. See NeurIPS 2021 oral for details.
 529 Jan 1, 2023
529 Jan 1, 2023
And now, for the first time, you can send alerts via action from ArcSight ESM Console to the TheHive when Correlation Rules are triggered.
ArcSight Integration with TheHive And now, for the first time, you can send alerts via action from ArcSight ESM Console to the TheHive when Correlatio
 3 Jan 19, 2022
3 Jan 19, 2022
Discord bot for name verifying. Created for TinkerHubGCEK discord server. Tinky is now deployed in heroku
Custom Discord bot This custom discord-python bot assigns roles to members joined at discord server. It looks and compares a list before verifying the
 2 Dec 16, 2021
2 Dec 16, 2021

Evaluation of a Monocular Eye Tracking Set-Up
Evaluation of a Monocular Eye Tracking Set-Up As part of my master thesis, I implemented a new state-of-the-art model that is based on the work of Che
 19 Dec 17, 2022
19 Dec 17, 2022

A fast implementation of bss_eval metrics for blind source separation
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
 99 Dec 13, 2022
99 Dec 13, 2022
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
fast_bss_eval is a fast implementation of the bss_eval metrics for the evaluation of blind source separation.
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
99 Dec 13, 2022

Supplementary materials for ISMIR 2021 LBD paper "Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes"
Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes Supplementary materials for ISMIR 2021 LBD submission: K. N. W
 2 Oct 25, 2021
2 Oct 25, 2021
Implementation of temporal pooling methods studied in [ICIP'20] A Comparative Evaluation Of Temporal Pooling Methods For Blind Video Quality Assessment
Implementation of temporal pooling methods studied in [ICIP'20] A Comparative Evaluation Of Temporal Pooling Methods For Blind Video Quality Assessment
 5 Sep 16, 2022
5 Sep 16, 2022
Want to play What Would Rather on your Server? Invite the bot now! 😏
What is this Bot? 👀 What You Would Rather? is a Guessing game where you guess one thing. Long Description short Take this example: You typed r!rather
 3 Oct 18, 2021
3 Oct 18, 2021
A python script to download twitter space, only works on running spaces (for now).
A python script to download twitter space, only works on running spaces (for now).
 279 Jan 2, 2023
279 Jan 2, 2023

Novel Instances Mining with Pseudo-Margin Evaluation for Few-Shot Object Detection
Novel Instances Mining with Pseudo-Margin Evaluation for Few-Shot Object Detection (NimPme) The official implementation of Novel Instances Mining with
 12 Sep 8, 2022
12 Sep 8, 2022
lazy_table - a python-tabulate wrapper for producing tables from generators
A python-tabulate wrapper for producing tables from generators. Motivation lazy_table is useful when (i) each row of your table is generated by a poss
 52 Nov 12, 2022
52 Nov 12, 2022
text-to-speach bot - You really do NOT have time for read a newsletter? Now you can listen to it
NewsletterReader You really do NOT have time for read a newsletter? Now you can listen to it The Newsletter of Filipe Deschamps is a great place to re
 8 Sep 18, 2021
8 Sep 18, 2021

Demonstration that AWS IAM policy evaluation docs are incorrect
The flowchart from the AWS IAM policy evaluation documentation page, as of 2021-09-12, and dating back to at least 2018-12-27, is the following: The f
 15 Oct 21, 2022
15 Oct 21, 2022

vFuzzer is a tool developed for fuzzing buffer overflows, For now, It can be used for fuzzing plain vanilla stack based buffer overflows
vFuzzer vFuzzer is a tool developed for fuzzing buffer overflows, For now, It can be used for fuzzing plain vanilla stack based buffer overflows, The
 5 Nov 12, 2022
5 Nov 12, 2022
Implementation of Common Image Evaluation Metrics by Sayed Nadim (sayednadim.github.io). The repo is built based on full reference image quality metrics such as L1, L2, PSNR, SSIM, LPIPS. and feature-level quality metrics such as FID, IS. It can be used for evaluating image denoising, colorization, inpainting, deraining, dehazing etc. where we have access to ground truth.
Image Quality Evaluation Metrics Implementation of some common full reference image quality metrics. The repo is built based on full reference image q
 10 Jan 1, 2023
10 Jan 1, 2023
Bot interpretation of the carbon.now.sh site
📒 Source code of the @PicodeBot 🧸 Developer: @hoosnick Run $ git clone https://github.com/hoosnick/picodebot.git $ pip install -r requirements.txt P
 13 Oct 2, 2022
13 Oct 2, 2022
Now patched 0day for force reseting an accounts password
Animal Jam 0day No-Auth Force Password Reset via API Now patched 0day for force reseting an accounts password Used until patched to cause anarchy. Pro
 10 Nov 17, 2022
10 Nov 17, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022
Our CIKM21 Paper "Incorporating Query Reformulating Behavior into Web Search Evaluation"
Reformulation-Aware-Metrics Introduction This codebase contains source-code of the Python-based implementation of our CIKM 2021 paper. Chen, Jia, et a
 5 Mar 5, 2022
5 Mar 5, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023
Evaluation suite for large-scale language models.
This repo contains code for running the evaluations and reproducing the results from the Jurassic-1 Technical Paper (see blog post), with current support for running the tasks through both the AI21 Studio API and OpenAI's GPT3 API.
 71 Dec 17, 2022
71 Dec 17, 2022

Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer Summary Explorer is a tool to visually inspect the summaries from several state-of-the-art neural summarization models across multipl
 42 Aug 14, 2022
42 Aug 14, 2022
Action Segmentation Evaluation
Reference Action Segmentation Evaluation Code This repository contains the reference code for action segmentation evaluation. If you have a bug-fix/im
 5 May 22, 2022
5 May 22, 2022
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
42 Aug 14, 2022
An Inline Telegram YouTube Downloader bot with custom, permanent thumbnail support and cancel upload facility. Make your fork now.
Inline-Tube-Mate (YouTube Downloader) An Inline Telegram bot that can download YouTube videos with permanent thumbnail support Bot need to be in Inlin
 41 Dec 14, 2022
41 Dec 14, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022

A TensorFlow implementation of SOFA, the Simulator for OFfline LeArning and evaluation.
SOFA This repository is the implementation of SOFA, the Simulator for OFfline leArning and evaluation. Keeping Dataset Biases out of the Simulation: A
 22 Nov 23, 2022
22 Nov 23, 2022

Active and Sample-Efficient Model Evaluation
Active Testing: Sample-Efficient Model Evaluation Hi, good to see you here! 👋 This is code for "Active Testing: Sample-Efficient Model Evaluation". P
 19 Oct 30, 2022
19 Oct 30, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

Bingo game now in python play as much you want :) no need to give me credit it's open as fuck
Bingo-py-game A game coded with Python Introduction This is a Terminal-based game currently in its initial stage. I am working on adding more efficien
 5 Aug 12, 2021
5 Aug 12, 2021
Double Pendulum implementation in Python, now with added pendulums and trails :D
Double Pendulum Using Curses in Python. A nice relaxing double pendulum simulation using ASCII, able to simulate multiple pendulums at once, and provi
 62 Dec 14, 2022
62 Dec 14, 2022
Reference implementation of code generation projects from Facebook AI Research. General toolkit to apply machine learning to code, from dataset creation to model training and evaluation. Comes with pretrained models.
This repository is a toolkit to do machine learning for programming languages. It implements tokenization, dataset preprocessing, model training and m
 408 Jan 1, 2023
408 Jan 1, 2023

The Hailo Model Zoo includes pre-trained models and a full building and evaluation environment
Hailo Model Zoo The Hailo Model Zoo provides pre-trained models for high-performance deep learning applications. Using the Hailo Model Zoo you can mea
 50 Dec 7, 2022
50 Dec 7, 2022
A program used to create accounts in bulk, still a work in progress as of now.
Discord Account Creator This project is still a work in progress. It will be published upon its full completion. About This project is still under dev
 8 Sep 15, 2022
8 Sep 15, 2022

A Toolbox for Image Feature Matching and Evaluations
This is a toolbox repository to help evaluate various methods that perform image matching from a pair of images.
 342 Dec 29, 2022
342 Dec 29, 2022
Semantic Scholar's Author Disambiguation Algorithm & Evaluation Suite
S2AND This repository provides access to the S2AND dataset and S2AND reference model described in the paper S2AND: A Benchmark and Evaluation System f
 54 Nov 28, 2022
54 Nov 28, 2022
A fast python implementation of DTU MVS 2014 evaluation
DTUeval-python A python implementation of DTU MVS 2014 evaluation. It only takes 1min for each mesh evaluation. And the gap between the two implementa
 82 Dec 27, 2022
82 Dec 27, 2022
SIMULEVAL A General Evaluation Toolkit for Simultaneous Translation
SimulEval SimulEval is a general evaluation framework for simultaneous translation on text and speech. Requirement python = 3.7.0 Installation git cl
48 Dec 28, 2022

CoWIN Vaccination slot booking telegram bot with auto captcha resolver & alerting feature.Now, never miss a slot.
COWIN VACCINATION SLOT AUTO BOOKING (Bot with captcha solving & alerting capabilities. Never miss the vaccine slot.) June-10-2021/ 0030 hrs: 23 succes
 17 Nov 12, 2022
17 Nov 12, 2022

YoloV5 implemented by TensorFlow2 , with support for training, evaluation and inference.
Efficient implementation of YOLOV5 in TensorFlow2
 202 Jan 6, 2023
202 Jan 6, 2023

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022

PyTorch evaluation code for Delving Deep into the Generalization of Vision Transformers under Distribution Shifts.
Out-of-distribution Generalization Investigation on Vision Transformers This repository contains PyTorch evaluation code for Delving Deep into the Gen
 72 Dec 13, 2022
72 Dec 13, 2022

NAS Benchmark in "Prioritized Architecture Sampling with Monto-Carlo Tree Search", CVPR2021
NAS-Bench-Macro This repository includes the benchmark and code for NAS-Bench-Macro in paper "Prioritized Architecture Sampling with Monto-Carlo Tree
 35 Jan 3, 2023
35 Jan 3, 2023
Now you'll never be late for your Webinars or Meetings on the GoToWebinar Platform
GoToWebinar Launcher : Now you'll never be late for your Webinars or Meetings on the GoToWebinar Platform About Are you popular for always being late
 6 Jun 7, 2022
6 Jun 7, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022
Evaluation Pipeline for our ECCV2020: Journey Towards Tiny Perceptual Super-Resolution.
Journey Towards Tiny Perceptual Super-Resolution Test code for our ECCV2020 paper: https://arxiv.org/abs/2007.04356 Our x4 upscaling pre-trained model
 6 Mar 30, 2022
6 Mar 30, 2022

Intruder detection systems are common place now, and readily available in industry, but how do they work? They must detect people and large animals, but not generate false alarms in the presence of small animals, changes in lighting, environmental motion such as trees, or melting snow. To work correctly, the system must learn the background, in order to differentiate foreground objects.
Intruder-Detection Intruder detection systems are common place now, and readily available in industry, but how do they work? They must detect people a
 4 Jul 18, 2021
4 Jul 18, 2021

QuanTaichi evaluation suite
QuanTaichi: A Compiler for Quantized Simulations (SIGGRAPH 2021) Yuanming Hu, Jiafeng Liu, Xuanda Yang, Mingkuan Xu, Ye Kuang, Weiwei Xu, Qiang Dai, W
 120 Jan 4, 2023
120 Jan 4, 2023

Framework for joint representation learning, evaluation through multimodal registration and comparison with image translation based approaches
CoMIR: Contrastive Multimodal Image Representation for Registration Framework 🖼 Registration of images in different modalities with Deep Learning 🤖
 55 Dec 9, 2022
55 Dec 9, 2022
The repo of the preprinting paper "Labels Are Not Perfect: Inferring Spatial Uncertainty in Object Detection"
Inferring Spatial Uncertainty in Object Detection A teaser version of the code for the paper Labels Are Not Perfect: Inferring Spatial Uncertainty in
 21 Mar 3, 2022
21 Mar 3, 2022
An evaluation toolkit for voice conversion models.
Voice-conversion-evaluation An evaluation toolkit for voice conversion models. Sample test pair Generate the metadata for evaluating models. The direc
 30 Aug 29, 2022
30 Aug 29, 2022
An evaluation toolkit for voice conversion models.
Voice-conversion-evaluation An evaluation toolkit for voice conversion models. Sample test pair Generate the metadata for evaluating models. The direc
30 Aug 29, 2022

Resources for the "Evaluating the Factual Consistency of Abstractive Text Summarization" paper
Evaluating the Factual Consistency of Abstractive Text Summarization Authors: Wojciech Kryściński, Bryan McCann, Caiming Xiong, and Richard Socher Int
 165 Dec 21, 2022
165 Dec 21, 2022
Findings of ACL 2021
Assessing Dialogue Systems with Distribution Distances [arXiv][code] We propose to measure the performance of a dialogue system by computing the distr
 16 Feb 24, 2022
16 Feb 24, 2022
Task-based datasets, preprocessing, and evaluation for sequence models.
SeqIO: Task-based datasets, preprocessing, and evaluation for sequence models. SeqIO is a library for processing sequential data to be fed into downst
 290 Dec 26, 2022
290 Dec 26, 2022
[CVPR 2021] MiVOS - Mask Propagation module. Reproduced STM (and better) with training code :star2:. Semi-supervised video object segmentation evaluation.
MiVOS (CVPR 2021) - Mask Propagation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [arXiv] [Paper PDF] [Project Page] [Papers with Code] This repo impleme
 106 Jan 3, 2023
106 Jan 3, 2023
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
 15k Jan 2, 2023
15k Jan 2, 2023
🤟The VC Music Source code of @DaisyXBot ❤️ v3 Out now
DAISYXMUSIC V3 🎵 A bot that can play music on telegram group's voice call Available on telegram as @DaisyXbot Whats new 🔥 Thumbnail Support Playlist
 207 Dec 5, 2022
207 Dec 5, 2022
OCTIS: Comparing Topic Models is Simple! A python package to optimize and evaluate topic models (accepted at EACL2021 demo track)
OCTIS : Optimizing and Comparing Topic Models is Simple! OCTIS (Optimizing and Comparing Topic models Is Simple) aims at training, analyzing and compa
 478 Jan 1, 2023
478 Jan 1, 2023

A Python package that provides evaluation and visualization tools for the DexYCB dataset
DexYCB Toolkit DexYCB Toolkit is a Python package that provides evaluation and visualization tools for the DexYCB dataset. The dataset and results wer
 107 Dec 26, 2022
107 Dec 26, 2022

Provided is code that demonstrates the training and evaluation of the work presented in the paper: "On the Detection of Digital Face Manipulation" published in CVPR 2020.
FFD Source Code Provided is code that demonstrates the training and evaluation of the work presented in the paper: "On the Detection of Digital Face M
 88 Nov 22, 2022
88 Nov 22, 2022
The best (and now open source) Discord selfbot.
React Selfbot Yes, for real Why am I making this open source? Because can't stop calling my product a rat, tokenlogger and what else not. But there is
 30 Nov 13, 2022
30 Nov 13, 2022
中文空间语义理解评测
中文空间语义理解评测 最新消息 2021-04-10 🚩 排行榜发布: Leaderboard 2021-04-05 基线系统发布: SpaCE2021-Baseline 2021-04-05 开放数据提交: 提交结果 2021-04-01 开放报名: 我要报名 2021-04-01 数据集 pa
 40 Jan 4, 2023
40 Jan 4, 2023
Source code for the GPT-2 story generation models in the EMNLP 2020 paper "STORIUM: A Dataset and Evaluation Platform for Human-in-the-Loop Story Generation"
Storium GPT-2 Models This is the official repository for the GPT-2 models described in the EMNLP 2020 paper [STORIUM: A Dataset and Evaluation Platfor
 27 Dec 20, 2022
27 Dec 20, 2022
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks,
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks, which unifies general text transformation, task-specific transformation, adversarial attack, sub-population, and their combinations to provide a comprehensive robustness analysis.
 587 Dec 20, 2022
587 Dec 20, 2022
Code for paper "A Critical Assessment of State-of-the-Art in Entity Alignment" (https://arxiv.org/abs/2010.16314)
A Critical Assessment of State-of-the-Art in Entity Alignment This repository contains the source code for the paper A Critical Assessment of State-of
 16 Oct 14, 2022
16 Oct 14, 2022
Petastorm library enables single machine or distributed training and evaluation of deep learning models from datasets in Apache Parquet format. It supports ML frameworks such as Tensorflow, Pytorch, and PySpark and can be used from pure Python code.
Petastorm Contents Petastorm Installation Generating a dataset Plain Python API Tensorflow API Pytorch API Spark Dataset Converter API Analyzing petas
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
Automatically build ARIMA, SARIMAX, VAR, FB Prophet and XGBoost Models on Time Series data sets with a Single Line of Code. Now updated with Dask to handle millions of rows.
Auto_TS: Auto_TimeSeries Automatically build multiple Time Series models using a Single Line of Code. Now updated with Dask. Auto_timeseries is a comp
 519 Jan 3, 2023
519 Jan 3, 2023

CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent performances in several models such as Faster R-CNN, YOLOv4, RetinaNet and . There is a maximum AP improvement of 1.9% and an average AP of 0.8% improvement on MS COCO dataset, compared to traditional evaluation-feedback modules. Here we just use as an example to illustrate the code.
CDIoU-CDIoUloss CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent p
 24 Jul 19, 2022
24 Jul 19, 2022
UNION: An Unreferenced Metric for Evaluating Open-ended Story Generation
UNION Automatic Evaluation Metric described in the paper UNION: An UNreferenced MetrIc for Evaluating Open-eNded Story Generation (EMNLP 2020). Please
50 Dec 30, 2022

An OCR evaluation tool
dinglehopper dinglehopper is an OCR evaluation tool and reads ALTO, PAGE and text files. It compares a ground truth (GT) document page with a OCR resu
 40 Dec 20, 2022
40 Dec 20, 2022

TedEval: A Fair Evaluation Metric for Scene Text Detectors
TedEval: A Fair Evaluation Metric for Scene Text Detectors Official Python 3 implementation of TedEval | paper | slides Chae Young Lee, Youngmin Baek,
 167 Nov 20, 2022
167 Nov 20, 2022
This repository provides train&test code, dataset, det.&rec. annotation, evaluation script, annotation tool, and ranking.
SCUT-CTW1500 Datasets We have updated annotations for both train and test set. Train: 1000 images [images][annos] Additional point annotation for each
 600 Dec 18, 2022
600 Dec 18, 2022
Deploy tensorflow graphs for fast evaluation and export to tensorflow-less environments running numpy.
Deploy tensorflow graphs for fast evaluation and export to tensorflow-less environments running numpy. Now with tensorflow 1.0 support. Evaluation usa
 349 Aug 6, 2022
349 Aug 6, 2022
Lightweight, configurable Sphinx theme. Now the Sphinx default!
What is Alabaster? Alabaster is a visually (c)lean, responsive, configurable theme for the Sphinx documentation system. It is Python 2+3 compatible. I
 670 Dec 19, 2022
670 Dec 19, 2022
Better directory iterator and faster os.walk(), now in the Python 3.5 stdlib
scandir, a better directory iterator and faster os.walk() scandir() is a directory iteration function like os.listdir(), except that instead of return
 506 Dec 29, 2022
506 Dec 29, 2022
A calendaring app for Django. It is now stable, Please feel free to use it now. Active development has been taken over by bartekgorny.
Django-schedule A calendaring/scheduling application, featuring: one-time and recurring events calendar exceptions (occurrences changed or cancelled)
 814 Dec 26, 2022
814 Dec 26, 2022
Markdown parser, done right. 100% CommonMark support, extensions, syntax plugins & high speed. Now in Python!
markdown-it-py Markdown parser done right. Follows the CommonMark spec for baseline parsing Configurable syntax: you can add new rules and even replac
 398 Dec 24, 2022
398 Dec 24, 2022
(Now finding maintainer) 🐍A Pythonic way to provide JWT authentication for Flask-GraphQL
Flask-GraphQL-Auth What is Flask-GraphQL-Auth? Flask-GraphQL-Auth is JWT decorator for flask-graphql inspired from Flask-JWT-Extended. all you have to
 64 Feb 19, 2022
64 Feb 19, 2022
Your Google Recon is Now Automated
GRecon : GRecon (Greei-Conn) is a simple python tool that automates the process of Google Based Recon AKA Google Dorking The current Version 1.0 Run 7
 189 Dec 21, 2022
189 Dec 21, 2022
Python Proof of Concept for retrieving Now Playing on YouTube Music with TabFS
Youtube Music TabFS Python Proof of Concept for retrieving Now Playing on YouTube Music with TabFS. music_information = get_now_playing() pprint(music
 41 Nov 6, 2022
41 Nov 6, 2022
A folder automation made using Watch-dog, it only works in linux for now but I assume, it will be adaptable to mac and PC as well
folder-automation A folder automation made using Watch-dog, it only works in linux for now but I assume, it will be adaptable to mac and PC as well Th
 31 May 28, 2021
31 May 28, 2021
Multi-class confusion matrix library in Python
Table of contents Overview Installation Usage Document Try PyCM in Your Browser Issues & Bug Reports Todo Outputs Dependencies Contribution References
 1.3k Dec 31, 2022
1.3k Dec 31, 2022