237 Repositories
Python evaluation-metrics Libraries

Open-Source CI/CD platform for ML teams. Deliver ML products, better & faster. ⚡️🧑🔧
Deliver ML products, better & faster Giskard is an Open-Source CI/CD platform for ML teams. Inspect ML models visually from your Python notebook 📗 Re
 335 Jan 4, 2023
335 Jan 4, 2023

KwaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%)
KuaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%) KuaiRec is a real-world dataset collected from the recommendation log
 70 Dec 28, 2022
70 Dec 28, 2022

My Solutions to 120 commonly asked data science interview questions.
Data_Science_Interview_Questions Introduction 👋 Here are the answers to 120 Data Science Interview Questions The above answer some is modified based
 181 Dec 31, 2022
181 Dec 31, 2022

Evaluation and Benchmarking of Speech Super-resolution Methods
Speech Super-resolution Evaluation and Benchmarking What this repo do: A toolbox for the evaluation of speech super-resolution algorithms. Unify the e
 84 Dec 20, 2022
84 Dec 20, 2022
A benchmark for evaluation and comparison of various NLP tasks in Persian language.
Persian NLP Benchmark The repository aims to track existing natural language processing models and evaluate their performance on well-known datasets.
 68 Dec 19, 2022
68 Dec 19, 2022

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022
Provide baselines and evaluation metrics of the task: traffic flow prediction
Note: This repo is adpoted from https://github.com/UNIMIBInside/Smart-Mobility-Prediction. Due to technical reasons, I did not fork their code. Introd
 11 Nov 2, 2022
11 Nov 2, 2022
Bcc2telegraf: An integration that sends ebpf-based bcc histogram metrics to telegraf daemon
bcc2telegraf bcc2telegraf is an integration that sends ebpf-based bcc histogram
 2 Feb 17, 2022
2 Feb 17, 2022
Nflmetrics - Johns Hopkins Spring 2022 Sports Analytics research project about NFL Draft Metrics
nflmetrics GitHub repo for Johns Hopkins Spring 2022 Sports Analytics research p
 4 Feb 24, 2022
4 Feb 24, 2022
fair-test is a library to build and deploy FAIR metrics tests APIs supporting the specifications used by the FAIRMetrics working group.
☑️ FAIR test fair-test is a library to build and deploy FAIR metrics tests APIs supporting the specifications used by the FAIRMetrics working group. I
 6 Oct 30, 2022
6 Oct 30, 2022
Object detection evaluation metrics using Python.
Object detection evaluation metrics using Python.
 2 Sep 6, 2022
2 Sep 6, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 36 Feb 13, 2022
36 Feb 13, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
98 Dec 15, 2022
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model About This repository contains the code to replicate the syn
 12 Dec 7, 2022
12 Dec 7, 2022
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation This reposi
 1 Aug 21, 2022
1 Aug 21, 2022

DimReductionClustering - Dimensionality Reduction + Clustering + Unsupervised Score Metrics
Dimensionality Reduction + Clustering + Unsupervised Score Metrics Introduction
 11 Nov 15, 2022
11 Nov 15, 2022
Evaluation framework for testing segmentation networks in PyTorch
Evaluation framework for testing segmentation networks in PyTorch. What segmentation network to choose for next Kaggle competition? This benchmark knows the answer!
 37 Apr 27, 2022
37 Apr 27, 2022

Automatically capture your Ookla Speedtest metrics and display them in a Grafana dashboard
Speedtest All-In-One Automatically capture your Ookla Speedtest metrics and display them in a Grafana dashboard. Getting Started About This Code This
 2 Feb 22, 2022
2 Feb 22, 2022

This is the repository for our paper Ditch the Gold Standard: Re-evaluating Conversational Question Answering
Ditch the Gold Standard: Re-evaluating Conversational Question Answering This is the repository for our paper Ditch the Gold Standard: Re-evaluating C
 38 Dec 16, 2022
38 Dec 16, 2022
FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python
☑️ FAIR Enough metrics for research FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python, conforming to the specifications
3 Jul 6, 2022
SuRE Evaluation: A Supplementary Material
SuRE Evaluation: A Supplementary Material This repository contains supplementary material regarding the evaluations presented in the paper Visual Expl
 0 Dec 14, 2021
0 Dec 14, 2021
The open-source and free to use Python package miseval was developed to establish a standardized medical image segmentation evaluation procedure
miseval: a metric library for Medical Image Segmentation EVALuation The open-source and free to use Python package miseval was developed to establish
 59 Dec 10, 2022
59 Dec 10, 2022
Official repository for the paper "On Evaluation Metrics for Graph Generative Models"
On Evaluation Metrics for Graph Generative Models Authors: Rylee Thompson, Boris Knyazev, Elahe Ghalebi, Jungtaek Kim, Graham Taylor This is the offic
 5 Jan 26, 2022
5 Jan 26, 2022
This repository contains pre-trained models and some evaluation code for our paper Towards Unsupervised Dense Information Retrieval with Contrastive Learning
Contriever: Towards Unsupervised Dense Information Retrieval with Contrastive Learning This repository contains pre-trained models and some evaluation
 207 Jan 8, 2023
207 Jan 8, 2023
Image Segmentation Evaluation
Image Segmentation Evaluation Martin Keršner, m.kersner@gmail.com Evaluation metrics for image segmentation inspired by paper Fully Convolutional Netw
 273 Oct 28, 2022
273 Oct 28, 2022
On Evaluation Metrics for Graph Generative Models
On Evaluation Metrics for Graph Generative Models Authors: Rylee Thompson, Boris Knyazev, Elahe Ghalebi, Jungtaek Kim, Graham Taylor This is the offic
13 Jan 7, 2023

A collection of automation aids to connect various database systems into Lookout for Metrics
A collection of automation aids to connect various database systems into Lookout for Metrics
 3 Apr 28, 2022
3 Apr 28, 2022
Add you own metrics to your celery backend
Add you own metrics to your celery backend
 1 Dec 16, 2022
1 Dec 16, 2022

Project made in Qt Designer + Python, for evaluation in the subject Introduction to Programming in IFPE - Paulista campus.
Project made in Qt Designer + Python, for evaluation in the subject Introduction to Programming in IFPE - Paulista campus.
 2 Apr 13, 2022
2 Apr 13, 2022

NLG evaluation via Statistical Measures of Similarity: BaryScore, DepthScore, InfoLM
NLG evaluation via Statistical Measures of Similarity: BaryScore, DepthScore, InfoLM Automatic Evaluation Metric described in the papers BaryScore (EM
 28 Dec 28, 2022
28 Dec 28, 2022
PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluation of Visual Stories via Semantic Consistency"
Improving Generation and Evaluation of Visual Stories via Semantic Consistency PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluat
 28 Dec 8, 2022
28 Dec 8, 2022
Data collection, enhancement, and metrics calculation.
l3_data_collection Data collection, enhancement, and metrics calculation. Summary Repository containing code for QuantDAO's JDT data collection task.
 3 Dec 23, 2022
3 Dec 23, 2022
📚 A collection of all the Deep Learning Metrics that I came across which are not accuracy/loss.
📚 A collection of all the Deep Learning Metrics that I came across which are not accuracy/loss.
 1 Jan 17, 2022
1 Jan 17, 2022
A Python application that helps users determine their calorie intake, and automatically generates customized weekly meal and workout plans based on metrics computed using their physical parameters
A Python application that helps users determine their calorie intake, and automatically generates customized weekly meal and workout plans based on metrics computed using their physical parameters
 1 Jan 13, 2022
1 Jan 13, 2022
An Evaluation of Generative Adversarial Networks for Collaborative Filtering.
An Evaluation of Generative Adversarial Networks for Collaborative Filtering. This repository was developed by Fernando B. Pérez Maurera. Fernando is
 0 Jan 19, 2022
0 Jan 19, 2022
Semantic similarity computation with different state-of-the-art metrics
Semantic similarity computation with different state-of-the-art metrics Description • Installation • Usage • License Description TaxoSS is a semantic
 6 Jun 22, 2022
6 Jun 22, 2022

Whisper is a file-based time-series database format for Graphite.
Whisper Overview Whisper is one of three components within the Graphite project: Graphite-Web, a Django-based web application that renders graphs and
 1.2k Dec 25, 2022
1.2k Dec 25, 2022
The Turing Change Point Detection Benchmark: An Extensive Benchmark Evaluation of Change Point Detection Algorithms on real-world data
Turing Change Point Detection Benchmark Welcome to the repository for the Turing Change Point Detection Benchmark, a benchmark evaluation of change po
 85 Dec 28, 2022
85 Dec 28, 2022
General Assembly's 2015 Data Science course in Washington, DC
DAT8 Course Repository Course materials for General Assembly's Data Science course in Washington, DC (8/18/15 - 10/29/15). Instructor: Kevin Markham (
 1.6k Jan 7, 2023
1.6k Jan 7, 2023

Automatic caption evaluation metric based on typicality analysis.
SeMantic and linguistic UndeRstanding Fusion (SMURF) Automatic caption evaluation metric described in the paper "SMURF: SeMantic and linguistic UndeRs
 6 Jan 9, 2022
6 Jan 9, 2022
Text Summarization - WCN — Weighted Contextual N-gram method for evaluation of Text Summarization
Text Summarization WCN — Weighted Contextual N-gram method for evaluation of Text Summarization In this project, I fine tune T5 model on Extreme Summa
 1 Jan 3, 2022
1 Jan 3, 2022

Most popular metrics used to evaluate object detection algorithms.
Most popular metrics used to evaluate object detection algorithms.
 4.4k Dec 25, 2022
4.4k Dec 25, 2022
Excel-report-evaluator - A simple Python GUI application to aid with bulk evaluation of Microsoft Excel reports.
Excel Report Evaluator Simple Python GUI with Tkinter for evaluating Microsoft Excel reports (.xlsx-Files). Usage Start main.py and choose one of the
 1 Dec 29, 2021
1 Dec 29, 2021
Metrics-advisor - Analyze reshaped metrics from TiDB cluster Prometheus and give some advice about anomalies and correlation.
metrics-advisor Analyze reshaped metrics from TiDB cluster Prometheus and give some advice about anomalies and correlation. Team freedeaths mashenjun
 3 Jan 7, 2022
3 Jan 7, 2022
Image Matching Evaluation
Image Matching Evaluation (IME) IME provides to test any feature matching algorithm on datasets containing ground-truth homographies. Also, one can re
 32 Nov 17, 2022
32 Nov 17, 2022

An efficient PyTorch implementation of the evaluation metrics in recommender systems.
recsys_metrics An efficient PyTorch implementation of the evaluation metrics in recommender systems. Overview • Installation • How to use • Benchmark
 12 Dec 2, 2022
12 Dec 2, 2022
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022
Place holder for HOPE: a human-centric and task-oriented MT evaluation framework using professional post-editing
HOPE: A Task-Oriented and Human-Centric Evaluation Framework Using Professional Post-Editing Towards More Effective MT Evaluation Place holder for dat
 1 Apr 25, 2022
1 Apr 25, 2022
C/C++ Dependency Analyzer: a rewrite of John Lakos' dep_utils (adep/cdep/ldep) from
cppdep performs dependency analysis among components/packages/package groups of a large C/C++ project. This is a rewrite of dep_utils(adep/cdep/ldep), which is provided by John Lakos' book "Large-Scale C++ Software Design", Addison Wesley (1996).
 125 Sep 21, 2022
125 Sep 21, 2022
Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters.
modeval Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters. Basic U
 2 Jan 1, 2022
2 Jan 1, 2022
Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters.
modeval Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters. Basic U
2 Jan 1, 2022
Latte: Cross-framework Python Package for Evaluation of Latent-based Generative Models
Cross-framework Python Package for Evaluation of Latent-based Generative Models Latte Latte (for LATent Tensor Evaluation) is a cross-framework Python
 30 Sep 8, 2022
30 Sep 8, 2022

Evaluation toolkit of the informative tracking benchmark comprising 9 scenarios, 180 diverse videos, and new challenges.
Informative-tracking-benchmark Informative tracking benchmark (ITB) higher diversity. It contains 9 representative scenarios and 180 diverse videos. m
 15 Nov 26, 2022
15 Nov 26, 2022
Prometheus exporter for metrics from the MyAudi API
Prometheus Audi Exporter This Prometheus exporter exports metrics that it fetches from the MyAudi API. Usage Checkout submodules Install dependencies
 7 Dec 19, 2022
7 Dec 19, 2022

Github Traffic Insights as Prometheus metrics.
github-traffic Github Traffic collects your repository's traffic data and exposes it as Prometheus metrics. Grafana dashboard that displays the metric
 34 Oct 27, 2022
34 Oct 27, 2022
Implementation for paper BLEU: a Method for Automatic Evaluation of Machine Translation
BLEU Score Implementation for paper: BLEU: a Method for Automatic Evaluation of Machine Translation Author: Ba Ngoc from ProtonX BLEU score is a popul
 6 Oct 7, 2021
6 Oct 7, 2021
Evaluation of file formats in the context of geo-referenced 3D geometries.
Geo-referenced Geometry File Formats Classic geometry file formats as .obj, .off, .ply, .stl or .dae do not support the utilization of coordinate syst
 11 Mar 2, 2022
11 Mar 2, 2022

Training and Evaluation Code for Neural Volumes
Neural Volumes This repository contains training and evaluation code for the paper Neural Volumes. The method learns a 3D volumetric representation of
370 Dec 8, 2022

The RDT protocol (RDT3.0,GBN,SR) implementation and performance evaluation code using socket
소켓을 이용한 RDT protocols (RDT3.0,GBN,SR) 구현 및 성능 평가 코드 입니다. 코드를 실행할때 리시버를 먼저 실행하세요. 성능 평가 코드는 패킷 전송 과정을 제외하고 시간당 전송률을 출력합니다. RDT3.0 GBN SR(버그 발견으로 구현중 입니
 0 Dec 20, 2021
0 Dec 20, 2021
Exports osu! user stats to prometheus metrics for a specified set of users
osu! to prometheus exporter This tool exports osu! user statistics into prometheus metrics for a specified set of user ids. Just copy the config.json.
 1 Feb 24, 2022
1 Feb 24, 2022
Evaluation toolkit of the informative tracking benchmark comprising 9 scenarios, 180 diverse videos, and new challenges.
Informative-tracking-benchmark Informative tracking benchmark (ITB) higher diversity. It contains 9 representative scenarios and 180 diverse videos. m
15 Nov 26, 2022

Leverage Twitter API v2 to analyze tweet metrics such as impressions and profile clicks over time.
Tweetmetric Tweetmetric allows you to track various metrics on your most recent tweets, such as impressions, retweets and clicks on your profile. The
 29 Oct 18, 2022
29 Oct 18, 2022
A PyTorch library and evaluation platform for end-to-end compression research
CompressAI CompressAI (compress-ay) is a PyTorch library and evaluation platform for end-to-end compression research. CompressAI currently provides: c
 680 Jan 6, 2023
680 Jan 6, 2023

Ballcone is a fast and lightweight server-side Web analytics solution.
Ballcone Ballcone is a fast and lightweight server-side Web analytics solution. It requires no JavaScript on your website. Screenshots Design Goals Si
 49 Dec 11, 2022
49 Dec 11, 2022

Atari2600 Training / Evaluation with RLlib
Training Atari2600 by Reinforcement Learning Train Atari2600 and check how it works! How to Setup You can setup packages on your local env. $ make set
 1 Dec 12, 2021
1 Dec 12, 2021
Official implementation of the paper "Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering"
Light Field Networks Project Page | Paper | Data | Pretrained Models Vincent Sitzmann*, Semon Rezchikov*, William Freeman, Joshua Tenenbaum, Frédo Dur
 130 Dec 29, 2022
130 Dec 29, 2022
HDMapNet: A Local Semantic Map Learning and Evaluation Framework
HDMapNet_devkit Devkit for HDMapNet. HDMapNet: A Local Semantic Map Learning and Evaluation Framework Qi Li, Yue Wang, Yilun Wang, Hang Zhao [Paper] [
 421 Jan 4, 2023
421 Jan 4, 2023

ZEBRA: Zero Evidence Biometric Recognition Assessment
ZEBRA: Zero Evidence Biometric Recognition Assessment license: LGPLv3 - please reference our paper version: 2020-06-11 author: Andreas Nautsch (EURECO
 2 Dec 12, 2021
2 Dec 12, 2021
django app that allows capture application metrics by each user individually
Django User Metrics django app that allows capture application metrics by each user individually, so after you can generate reports with aggregation o
 42 Apr 28, 2022
42 Apr 28, 2022
Generalise Prometheus metrics. takes out server specific, replaces variables and such.
Generalise Prometheus metrics. takes out server specific, replaces variables and such. makes it easier to copy from Prometheus console straight to Grafana.
 5 Mar 28, 2022
5 Mar 28, 2022
The evaluator covering all of the metrics required by tasks within the DUE Benchmark.
DUE Evaluator The repository contains the evaluator covering all of the metrics required by tasks within the DUE Benchmark, i.e., set-based F1 (for KI
 4 Jan 21, 2022
4 Jan 21, 2022
Process GPX files (adding sensor metrics, uploading to InfluxDB, etc.) exported from imxingzhe.com
Xingzhe GPX Processor 行者轨迹处理工具 Xingzhe sells cheap GPS bike meters with sensor support including cadence, heart rate and power. But the GPX files expo
 8 Sep 23, 2022
8 Sep 23, 2022

A library of metrics for evaluating recommender systems
recmetrics A python library of evalulation metrics and diagnostic tools for recommender systems. **This library is activly maintained. My goal is to c
 458 Jan 6, 2023
458 Jan 6, 2023

Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking and Jupyter notebook analysis.
sklearn-evaluation Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking, and Jupyter notebook analysis. Suppo
 354 Dec 31, 2022
354 Dec 31, 2022
A comprehensive set of fairness metrics for datasets and machine learning models, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
AI Fairness 360 (AIF360) The AI Fairness 360 toolkit is an extensible open-source library containg techniques developed by the research community to h
 1.9k Jan 6, 2023
1.9k Jan 6, 2023
Team collaborative evaluation tracker.
Team collaborative evaluation tracker.
 2 Dec 19, 2021
2 Dec 19, 2021
TextWorld is a sandbox learning environment for the training and evaluation of reinforcement learning (RL) agents on text-based games.
TextWorld A text-based game generator and extensible sandbox learning environment for training and testing reinforcement learning (RL) agents. Also ch
 983 Dec 23, 2022
983 Dec 23, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
Official Repository for "Robust On-Policy Data Collection for Data Efficient Policy Evaluation" (NeurIPS 2021 Workshop on OfflineRL).
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation Source code of Robust On-Policy Data Collection for Data-Efficient Policy Evalua
 2 Oct 9, 2022
2 Oct 9, 2022

(NeurIPS 2021) Realistic Evaluation of Transductive Few-Shot Learning
Realistic evaluation of transductive few-shot learning Introduction This repo contains the code for our NeurIPS 2021 submitted paper "Realistic evalua
 14 Dec 13, 2022
14 Dec 13, 2022
Hubble - Network, Service & Security Observability for Kubernetes using eBPF
Network, Service & Security Observability for Kubernetes What is Hubble? Getting Started Features Service Dependency Graph Metrics & Monitoring Flow V
 2.4k Jan 4, 2023
2.4k Jan 4, 2023

Python Single Object Tracking Evaluation
pysot-toolkit The purpose of this repo is to provide evaluation API of Current Single Object Tracking Dataset, including VOT2016 VOT2018 VOT2018-LT OT
 348 Dec 22, 2022
348 Dec 22, 2022

Tightness-aware Evaluation Protocol for Scene Text Detection
TIoU-metric Release on 27/03/2019. This repository is built on the ICDAR 2015 evaluation code. If you propose a better metric and require further eval
 206 Nov 18, 2022
206 Nov 18, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022

Prevent `CUDA error: out of memory` in just 1 line of code.
🐨 Koila Koila solves CUDA error: out of memory error painlessly. Fix it with just one line of code, and forget it. 🚀 Features 🙅 Prevents CUDA error
 1.7k Jan 2, 2023
1.7k Jan 2, 2023
GradAttack is a Python library for easy evaluation of privacy risks in public gradients in Federated Learning
GradAttack is a Python library for easy evaluation of privacy risks in public gradients in Federated Learning, as well as corresponding mitigation strategies.
 129 Dec 30, 2022
129 Dec 30, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
Pytorch Pedestrian Attribute Recognition: A strong PyTorch baseline of pedestrian attribute recognition and multi-label classification.
 79 Dec 18, 2022
79 Dec 18, 2022
Gathers data and displays metrics related to climate change and resource depletion on a PowerBI report.
Apocalypse Status Dashboard Purpose Climate change and resource depletion are grave long-term dangers. The code in this repository will pull data from
 1 Nov 12, 2021
1 Nov 12, 2021
Metrics to evaluate quality and efficacy of synthetic datasets.
An Open Source Project from the Data to AI Lab, at MIT Metrics for Synthetic Data Generation Projects Website: https://sdv.dev Documentation: https://
 129 Jan 3, 2023
129 Jan 3, 2023

Training code and evaluation benchmarks for the "Self-Supervised Policy Adaptation during Deployment" paper.
Self-Supervised Policy Adaptation during Deployment PyTorch implementation of PAD and evaluation benchmarks from Self-Supervised Policy Adaptation dur
 101 Nov 1, 2022
101 Nov 1, 2022
Semi-Supervised Learning for Fine-Grained Classification
Semi-Supervised Learning for Fine-Grained Classification This repo contains the code of: A Realistic Evaluation of Semi-Supervised Learning for Fine-G
 25 Nov 8, 2022
25 Nov 8, 2022

A Python package for causal inference using Synthetic Controls
Synthetic Control Methods A Python package for causal inference using synthetic controls This Python package implements a class of approaches to estim
 107 Dec 28, 2022
107 Dec 28, 2022
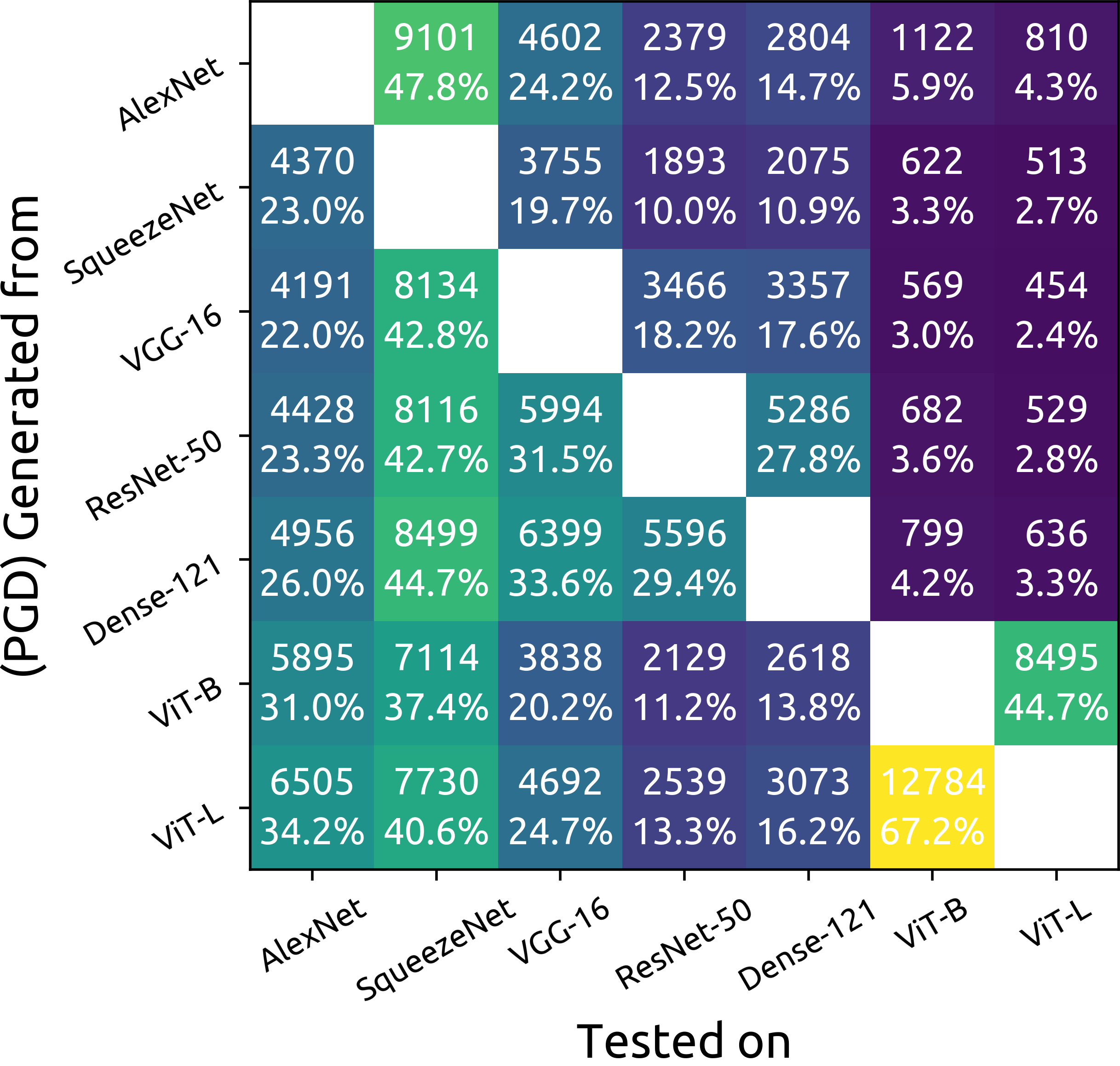
ImageNet Adversarial Image Evaluation
ImageNet Adversarial Image Evaluation This repository contains the code and some materials used in the experimental work presented in the following pa
 11 Dec 26, 2022
11 Dec 26, 2022

Neural network graphs and training metrics for PyTorch, Tensorflow, and Keras.
HiddenLayer A lightweight library for neural network graphs and training metrics for PyTorch, Tensorflow, and Keras. HiddenLayer is simple, easy to ex
 1.7k Dec 31, 2022
1.7k Dec 31, 2022

MRQy is a quality assurance and checking tool for quantitative assessment of magnetic resonance imaging (MRI) data.
Front-end View Backend View Table of Contents Description Prerequisites Running Basic Information Measurements User Interface Feedback and usage Descr
 58 Dec 2, 2022
58 Dec 2, 2022

Accelerating model creation and evaluation.
EmeraldML A machine learning library for streamlining the process of (1) cleaning and splitting data, (2) training, optimizing, and testing various mo
 0 Dec 6, 2021
0 Dec 6, 2021