394 Repositories
Python pre-commit-sample Libraries

Code for KDD'20 "Generative Pre-Training of Graph Neural Networks"
GPT-GNN: Generative Pre-Training of Graph Neural Networks GPT-GNN is a pre-training framework to initialize GNNs by generative pre-training. It can be
 346 Dec 19, 2022
346 Dec 19, 2022
![[ICML 2020] DrRepair: Learning to Repair Programs from Error Messages](https://github.com/michiyasunaga/DrRepair/raw/master/DrRepair-overview.png)
[ICML 2020] DrRepair: Learning to Repair Programs from Error Messages
DrRepair: Learning to Repair Programs from Error Messages This repo provides the source code & data of our paper: Graph-based, Self-Supervised Program
 155 Jan 8, 2023
155 Jan 8, 2023
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022

A Sample App to Demonstrate React Native and FastAPI Integration
React Native - Service Integration with FastAPI Backend. A Sample App to Demonstrate React Native and FastAPI Integration UI Based on NativeBase toolk
 4 Nov 17, 2022
4 Nov 17, 2022
Getting my gitlab commit history into github
This is a mock repository. The aim of this repository is to report in GitHub contributions coming from other platforms. It has been automatically crea
 1 Dec 24, 2021
1 Dec 24, 2021
Changelog CI is a GitHub Action that enables a project to automatically generate changelogs
What is Changelog CI? Changelog CI is a GitHub Action that enables a project to automatically generate changelogs. Changelog CI can be triggered on pu
 106 Dec 25, 2022
106 Dec 25, 2022
PyTorch implementation of Rethinking Positional Encoding in Language Pre-training
TUPE PyTorch implementation of Rethinking Positional Encoding in Language Pre-training. Quickstart Clone this repository. git clone https://github.com
 5 Jan 27, 2022
5 Jan 27, 2022
An executor that performs standard pre-processing and normalization on images.
An executor that performs standard pre-processing and normalization on images.
 6 Jun 30, 2022
6 Jun 30, 2022

Code release for SLIP Self-supervision meets Language-Image Pre-training
SLIP: Self-supervision meets Language-Image Pre-training What you can find in this repo: Pre-trained models (with ViT-Small, Base, Large) and code to
 621 Dec 31, 2022
621 Dec 31, 2022
Some out-of-the-box hooks for pre-commit
pre-commit-hooks Some out-of-the-box hooks for pre-commit. See also: https://github.com/pre-commit/pre-commit Using pre-commit-hooks with pre-commit A
 3.6k Dec 29, 2022
3.6k Dec 29, 2022

coURLan: Clean, filter, normalize, and sample URLs
coURLan: Clean, filter, normalize, and sample URLs Why coURLan? “Given that the bandwidth for conducting crawls is neither infinite nor free, it is be
 20 Dec 14, 2022
20 Dec 14, 2022

Ansible Automation Example: JSNAPY PRE/POST Upgrade Validation
Ansible Automation Example: JSNAPY PRE/POST Upgrade Validation Overview This example will show how to validate the status of our firewall before and a
 1 Jan 7, 2022
1 Jan 7, 2022
This is the new and improved Plex Automatic Pre-roll script with a GUI
Plex-Automatic-Pre-roll-GUI This is the new and improved Plex Automatic Pre-roll script with a GUI! It should be stable but if you find a bug please l
 164 Nov 4, 2022
164 Nov 4, 2022

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022
Resources related to our paper "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain"
CLIN-X (CLIN-X-ES) & (CLIN-X-EN) This repository holds the companion code for the system reported in the paper: "CLIN-X: pre-trained language models a
 4 Dec 5, 2022
4 Dec 5, 2022

Automatic labeling, conversion of different data set formats, sample size statistics, model cascade
Simple Gadget Collection for Object Detection Tasks Automatic image annotation Conversion between different annotation formats Obtain statistical info
 4 Aug 24, 2022
4 Aug 24, 2022

A custom qq-plot for two sample data comparision
QQ-Plot 2 Sample Just a gist to include the custom code to draw a qq-plot in python when dealing with a "two sample problem". This means when u try to
 1 Dec 20, 2021
1 Dec 20, 2021
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Table of contents Introduction Using BARTpho with fairseq Using BARTpho with transformers Notes BARTpho: Pre-trained Sequence-to-Sequence Models for V
 58 Dec 23, 2022
58 Dec 23, 2022

A PyTorch-based model pruning toolkit for pre-trained language models
English | 中文说明 TextPruner是一个为预训练语言模型设计的模型裁剪工具包,通过轻量、快速的裁剪方法对模型进行结构化剪枝,从而实现压缩模型体积、提升模型速度。 其他相关资源: 知识蒸馏工具TextBrewer:https://github.com/airaria/TextBrewe
 231 Jan 8, 2023
231 Jan 8, 2023
On the Complementarity between Pre-Training and Back-Translation for Neural Machine Translation (Findings of EMNLP 2021))
PTvsBT On the Complementarity between Pre-Training and Back-Translation for Neural Machine Translation (Findings of EMNLP 2021) Citation Please cite a
 10 Nov 25, 2022
10 Nov 25, 2022
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding Official Pytorch implementation of Negative Sample Matter
 69 Dec 26, 2022
69 Dec 26, 2022
A scanner and a proof of sample exploit for log4j RCE CVE-2021-44228
1.Create a Sample Vulnerable Application . 2.Start a netcat listner . 3.Run the exploit . 5.Use jdk1.8.0_20 for better results . Exploit-db - https://
 7 Aug 6, 2022
7 Aug 6, 2022

Industrial Image Anomaly Localization Based on Gaussian Clustering of Pre-trained Feature
Industrial Image Anomaly Localization Based on Gaussian Clustering of Pre-trained Feature Q. Wan, L. Gao, X. Li and L. Wen, "Industrial Image Anomaly
 6 Dec 25, 2022
6 Dec 25, 2022
Some pre-commit hooks for OpenMMLab projects
pre-commit-hooks Some pre-commit hooks for OpenMMLab projects. Using pre-commit-hooks with pre-commit Add this to your .pre-commit-config.yaml - rep
 16 Nov 29, 2022
16 Nov 29, 2022

Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
2D-TAN (Optimized) Introduction This is an optimized re-implementation repository for AAAI'2020 paper: Learning 2D Temporal Localization Networks for
 112 Dec 31, 2022
112 Dec 31, 2022
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Rotary Transformer is an MLM pre-trained language model with rotary position embedding (RoPE)
[中文|English] Rotary Transformer Rotary Transformer is an MLM pre-trained language model with rotary position embedding (RoPE). The RoPE is a relative
 211 Dec 8, 2021
211 Dec 8, 2021
ByT5: Towards a token-free future with pre-trained byte-to-byte models
ByT5: Towards a token-free future with pre-trained byte-to-byte models ByT5 is a tokenizer-free extension of the mT5 model. Instead of using a subword
 409 Jan 6, 2023
409 Jan 6, 2023

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models
PEGASUS library Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised
1.4k Dec 22, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Unsupervised Language Model Pre-training for French
FlauBERT and FLUE FlauBERT is a French BERT trained on a very large and heterogeneous French corpus. Models of different sizes are trained using the n
 212 Dec 10, 2022
212 Dec 10, 2022
Code for EMNLP20 paper: "ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training"
ProphetNet-X This repo provides the code for reproducing the experiments in ProphetNet. In the paper, we propose a new pre-trained language model call
394 Dec 17, 2022
CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT This repo provides the code for reproducing the experiments in CodeBERT: A Pre-Trained Model for Programming and Natural Languages. CodeBERT
1k Jan 3, 2023
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022
Reimplementation of NeurIPS'19: "Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting" by Shu et al.
[Re] Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting Reimplementation of NeurIPS'19: "Meta-Weight-Net: Learning an Explicit Mapping
 1 Mar 13, 2020
1 Mar 13, 2020
CVE-2021-39685 Description and sample exploit for Linux USB Gadget overflow vulnerability
CVE-2021-39685 Description and sample exploit for Linux USB Gadget overflow vulnerability
 8 May 25, 2022
8 May 25, 2022

A Python library for electronic structure pre/post-processing
PyProcar PyProcar is a robust, open-source Python library used for pre- and post-processing of the electronic structure data coming from DFT calculati
 124 Dec 7, 2022
124 Dec 7, 2022
Discovering Explanatory Sentences in Legal Case Decisions Using Pre-trained Language Models.
Statutory Interpretation Data Set This repository contains the data set created for the following research papers: Savelka, Jaromir, and Kevin D. Ashl
 17 Dec 23, 2022
17 Dec 23, 2022
flake8 plugin which checks that typing imports are properly guarded
flake8-typing-imports flake8 plugin which checks that typing imports are properly guarded installation pip install flake8-typing-imports flake8 codes
 50 Nov 1, 2022
50 Nov 1, 2022

CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability
This is the official repository of the paper: CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability A private copy of the
 33 Dec 31, 2022
33 Dec 31, 2022
Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts
t5-japanese Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts. The following is a list of models that
 1 Dec 13, 2021
1 Dec 13, 2021

Neural-PIL: Neural Pre-Integrated Lighting for Reflectance Decomposition - NeurIPS2021
Neural-PIL: Neural Pre-Integrated Lighting for Reflectance Decomposition Project Page | Video | Paper Implementation for Neural-PIL. A novel method wh
 64 Dec 29, 2022
64 Dec 29, 2022
A python code to convert Keras pre-trained weights to Pytorch version
Weights_Keras_2_Pytorch 最近想在Pytorch项目里使用一下谷歌的NIMA,但是发现没有预训练好的pytorch权重,于是整理了一下将Keras预训练权重转为Pytorch的代码,目前是支持Keras的Conv2D, Dense, DepthwiseConv2D, Batch
 2 Dec 16, 2021
2 Dec 16, 2021
Python script to commit to your github for a perfect commit streak. This is purely for education purposes, please don't use this script to do bad stuff.
Daily-Git-Commit Commit to repo every day for the perfect commit streak Requirments pip install -r requirements.txt Setup Download this repository. Cr
 34 Dec 14, 2022
34 Dec 14, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021
Run isort, pyupgrade, mypy, pylint, flake8, and more on Jupyter Notebooks
Run isort, pyupgrade, mypy, pylint, flake8, mdformat, black, blacken-docs, and more on Jupyter Notebooks ✅ handles IPython magics robustly ✅ respects
 663 Jan 8, 2023
663 Jan 8, 2023

A Github Action for sending messages to a Matrix Room.
matrix-commit A Github Action for sending messages to a Matrix Room. Screenshot: Example Usage: # .github/workflows/matrix-commit.yml on: push:
 3 Sep 11, 2022
3 Sep 11, 2022
Official Implementation of SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Official Implementation of SimIPU SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations Since
 37 Dec 1, 2022
37 Dec 1, 2022

VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
 14 Dec 10, 2021
14 Dec 10, 2021

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

RuleBERT: Teaching Soft Rules to Pre-Trained Language Models
RuleBERT: Teaching Soft Rules to Pre-Trained Language Models (Paper) (Slides) (Video) RuleBERT is a pre-trained language model that has been fine-tune
 16 Aug 24, 2022
16 Aug 24, 2022
NeurIPS'19: Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting (Pytorch implementation for noisy labels).
Meta-Weight-Net NeurIPS'19: Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting (Official Pytorch implementation for noisy labels). The
 243 Jan 3, 2023
243 Jan 3, 2023

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Sample python script for monitoring Rocketchat database and get statistics of users.
rocketchat-DB-monitoring Sample python script for monitoring Rocketchat database and get statistics of users. 1. Update python: yum check-update && yu
 1 Apr 12, 2022
1 Apr 12, 2022
iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
435 Jan 6, 2023
Template for pre-commit hooks
Pre-commit hook template This repo is a template for a pre-commit hook. Try it out by running: pre-commit try-repo https://github.com/stefsmeets/pre-c
 1 Dec 9, 2021
1 Dec 9, 2021

GLIP: Grounded Language-Image Pre-training
GLIP: Grounded Language-Image Pre-training Updates 12/06/2021: GLIP paper on arxiv https://arxiv.org/abs/2112.03857. Code and Model are under internal
862 Jan 1, 2023
Exploit grafana Pre-Auth LFI
Grafana-LFI-8.x Exploit grafana Pre-Auth LFI How to use python3
 2 Jul 25, 2022
2 Jul 25, 2022
A sample project that exists for PyPUG's "Tutorial on Packaging and Distributing Projects"
A sample Python project A sample project that exists as an aid to the Python Packaging User Guide's Tutorial on Packaging and Distributing Projects. T
 4.5k Dec 30, 2022
4.5k Dec 30, 2022
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
32 Oct 24, 2022
A fast and easy python virtual environment creator for linux with some pre-installed libraries.
python-venv-creator A fast and easy python virtual environment created for linux with some optional pre-installed libraries. Dependencies: The followi
 2 Apr 19, 2022
2 Apr 19, 2022
Sample exploits for Zephyr CVE-2021-3625
CVE-2021-3625 This repository contains a few example exploits for CVE-2021-3625. All Zephyr-based usb devices up to (and including) version 2.5.0 suff
7 Nov 10, 2022
Flask pre-setup architecture. This can be used in any flask project for a faster and better project code structure.
Flask pre-setup architecture. This can be used in any flask project for a faster and better project code structure. All the required libraries are already installed easily to use in any big project.
 5 Jun 14, 2022
5 Jun 14, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
0 Mar 20, 2022
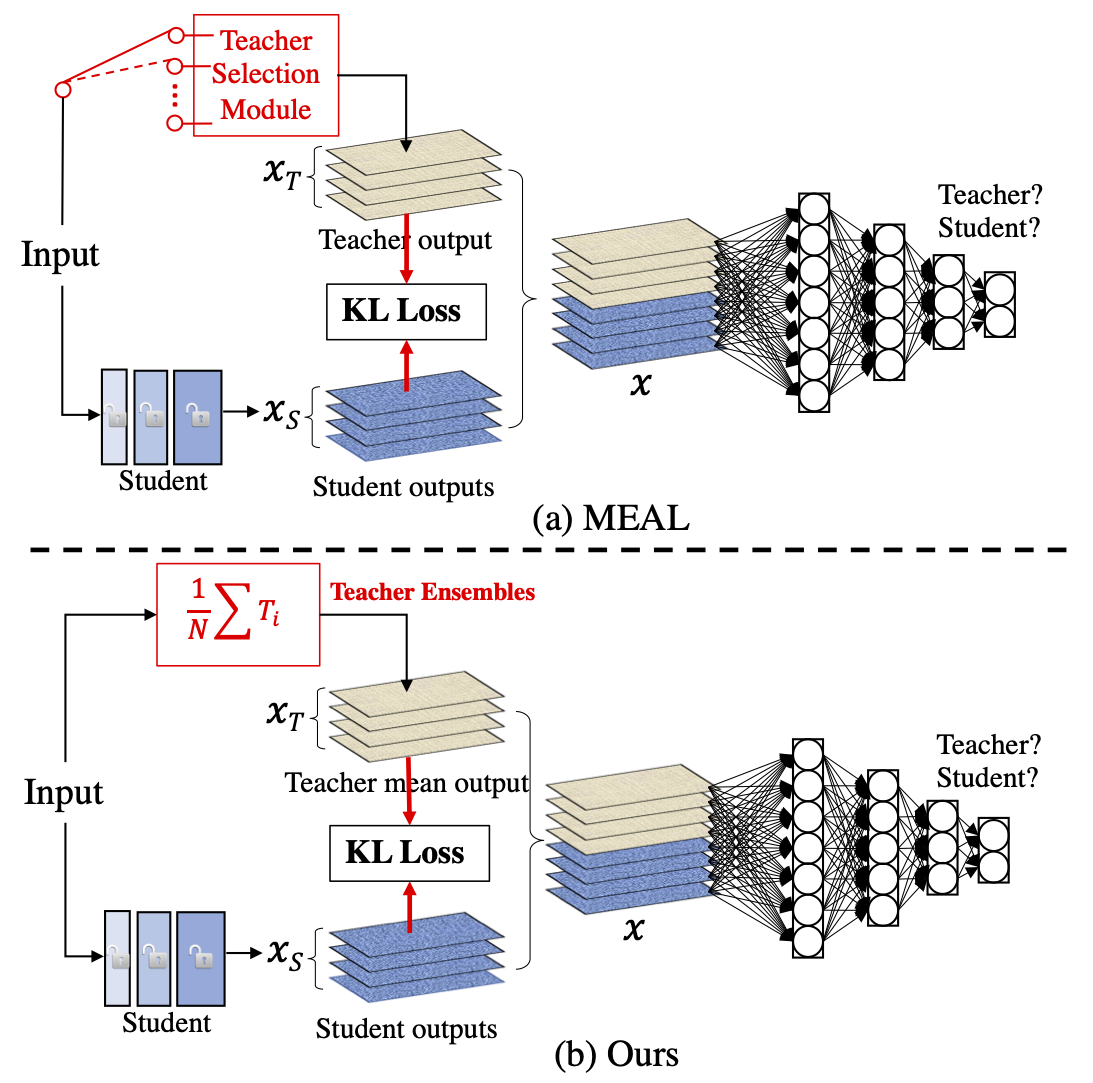
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022

The functions we created are included in a script. The necessary parts for pre-processing were taken. Analysis complete.
Feature-Engineering The functions we created are included in a script. The necessary parts for pre-processing were taken. Analysis complete. Business
 4 Oct 17, 2021
4 Oct 17, 2021

Code for EMNLP 2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training"
SCAPT-ABSA Code for EMNLP2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training" Overvie
 66 Dec 4, 2022
66 Dec 4, 2022
Sample Prior Guided Robust Model Learning to Suppress Noisy Labels
PGDF This repo is the official implementation of our paper "Sample Prior Guided Robust Model Learning to Suppress Noisy Labels ". Citation If you use
 22 Dec 23, 2022
22 Dec 23, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
228 Nov 21, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022
Code and pre-trained models for "ReasonBert: Pre-trained to Reason with Distant Supervision", EMNLP'2021
ReasonBERT Code and pre-trained models for ReasonBert: Pre-trained to Reason with Distant Supervision, EMNLP'2021 Pretrained Models The pretrained mod
 29 Dec 19, 2022
29 Dec 19, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022
EMNLP 2021 paper "Pre-train or Annotate? Domain Adaptation with a Constrained Budget".
Pre-train or Annotate? Domain Adaptation with a Constrained Budget This repo contains code and data associated with EMNLP 2021 paper "Pre-train or Ann
 8 Dec 17, 2021
8 Dec 17, 2021

Source code for the ACL-IJCNLP 2021 paper entitled "T-DNA: Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adaptation" by Shizhe Diao et al.
T-DNA Source code for the ACL-IJCNLP 2021 paper entitled Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adapta
 17 Dec 22, 2022
17 Dec 22, 2022
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
 45 Dec 3, 2021
45 Dec 3, 2021
Sample Code for "Pessimism Meets Invariance: Provably Efficient Offline Mean-Field Multi-Agent RL"
Sample Code for "Pessimism Meets Invariance: Provably Efficient Offline Mean-Field Multi-Agent RL" This is the official codebase for Pessimism Meets I
 3 Sep 19, 2022
3 Sep 19, 2022

PyTorch implementation of "Debiased Visual Question Answering from Feature and Sample Perspectives" (NeurIPS 2021)
D-VQA We provide the PyTorch implementation for Debiased Visual Question Answering from Feature and Sample Perspectives (NeurIPS 2021). Dependencies P
 19 Dec 22, 2022
19 Dec 22, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
124 Jan 2, 2023
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022
Code of our paper "Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning"
CCOP Code of our paper Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning Requirement Install OpenSelfSup Install Detectron2
 5 Nov 30, 2021
5 Nov 30, 2021

Pre-Training 3D Point Cloud Transformers with Masked Point Modeling
Point-BERT: Pre-Training 3D Point Cloud Transformers with Masked Point Modeling Created by Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zho
 306 Jan 6, 2023
306 Jan 6, 2023
Pre-trained Deep Learning models and demos (high quality and extremely fast)
OpenVINO™ Toolkit - Open Model Zoo repository This repository includes optimized deep learning models and a set of demos to expedite development of hi
 3.4k Dec 31, 2022
3.4k Dec 31, 2022