832 Repositories
Python pre-training Libraries
Code release for "Cycle Self-Training for Domain Adaptation" (NeurIPS 2021)
CST Code release for "Cycle Self-Training for Domain Adaptation" (NeurIPS 2021) Prerequisites torch=1.7.0 torchvision qpsolvers numpy prettytable tqd
 31 Jan 8, 2023
31 Jan 8, 2023
A library for preparing, training, and evaluating scalable deep learning hybrid recommender systems using PyTorch.
collie Collie is a library for preparing, training, and evaluating implicit deep learning hybrid recommender systems, named after the Border Collie do
 96 Dec 29, 2022
96 Dec 29, 2022

QuakeLabeler is a Python package to create and manage your seismic training data, processes, and visualization in a single place — so you can focus on building the next big thing.
QuakeLabeler Quake Labeler was born from the need for seismologists and developers who are not AI specialists to easily, quickly, and independently bu
 15 Nov 4, 2022
15 Nov 4, 2022

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023
Implementation of Natural Language Code Search in the project CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT-Implementation In this repo we have replicated the paper CodeBERT: A Pre-Trained Model for Programming and Natural Languages. We are interest
 4 Jul 1, 2022
4 Jul 1, 2022

Implements the training, testing and editing tools for "Pluralistic Image Completion"
Pluralistic Image Completion ArXiv | Project Page | Online Demo | Video(demo) This repository implements the training, testing and editing tools for "
 615 Dec 8, 2022
615 Dec 8, 2022
A Deep Learning based project for creating line art portraits.
ArtLine The main aim of the project is to create amazing line art portraits. Sounds Intresting,let's get to the pictures!! Model-(Smooth) Model-(Quali
 3.3k Jan 7, 2023
3.3k Jan 7, 2023
PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more
PyTorch Image Models Sponsors What's New Introduction Models Features Results Getting Started (Documentation) Train, Validation, Inference Scripts Awe
 22.9k Jan 9, 2023
22.9k Jan 9, 2023
Synthetic structured data generators
Join us on What is Synthetic Data? Synthetic data is artificially generated data that is not collected from real world events. It replicates the stati
 850 Jan 7, 2023
850 Jan 7, 2023
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

PaSST: Efficient Training of Audio Transformers with Patchout
PaSST: Efficient Training of Audio Transformers with Patchout This is the implementation for Efficient Training of Audio Transformers with Patchout Pa
 165 Dec 26, 2022
165 Dec 26, 2022

An NLP library with Awesome pre-trained Transformer models and easy-to-use interface, supporting wide-range of NLP tasks from research to industrial applications.
简体中文 | English News [2021-10-12] PaddleNLP 2.1版本已发布!新增开箱即用的NLP任务能力、Prompt Tuning应用示例与生成任务的高性能推理! 🎉 更多详细升级信息请查看Release Note。 [2021-08-22]《千言:面向事实一致性的生
 6.9k Jan 1, 2023
6.9k Jan 1, 2023
Scalable training for dense retrieval models.
Scalable implementation of dense retrieval. Training on cluster By default it trains locally: PYTHONPATH=.:$PYTHONPATH python dpr_scale/main.py traine
 90 Dec 28, 2022
90 Dec 28, 2022
NVIDIA Merlin is an open source library providing end-to-end GPU-accelerated recommender systems, from feature engineering and preprocessing to training deep learning models and running inference in production.
NVIDIA Merlin NVIDIA Merlin is an open source library designed to accelerate recommender systems on NVIDIA’s GPUs. It enables data scientists, machine
 419 Jan 3, 2023
419 Jan 3, 2023
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022
MG-GCN: Scalable Multi-GPU GCN Training Framework
MG-GCN MG-GCN: multi-GPU GCN training framework. For more information, please read our paper. After cloning our repository, run git submodule update -
 6 Oct 24, 2022
6 Oct 24, 2022
Demystifying How Self-Supervised Features Improve Training from Noisy Labels
Demystifying How Self-Supervised Features Improve Training from Noisy Labels This code is a PyTorch implementation of the paper "[Demystifying How Sel
 4 Oct 14, 2022
4 Oct 14, 2022

Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
 123 Dec 23, 2022
123 Dec 23, 2022
Codes for CIKM'21 paper 'Self-Supervised Graph Co-Training for Session-based Recommendation'.
COTREC Codes for CIKM'21 paper 'Self-Supervised Graph Co-Training for Session-based Recommendation'. Requirements: Python 3.7, Pytorch 1.6.0 Best Hype
 43 Jan 4, 2023
43 Jan 4, 2023

Designing a Practical Degradation Model for Deep Blind Image Super-Resolution (ICCV, 2021) (PyTorch) - We released the training code!
Designing a Practical Degradation Model for Deep Blind Image Super-Resolution Kai Zhang, Jingyun Liang, Luc Van Gool, Radu Timofte Computer Vision Lab
 804 Jan 8, 2023
804 Jan 8, 2023
Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training".
Mixup-Data-Dependency Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training". Running Alternating Line Exp
 0 Nov 11, 2021
0 Nov 11, 2021
Anomaly detection in multi-agent trajectories: Code for training, evaluation and the OpenAI highway simulation.
Anomaly Detection in Multi-Agent Trajectories for Automated Driving This is the official project page including the paper, code, simulation, baseline
 12 Dec 2, 2022
12 Dec 2, 2022

collect training and calibration data for gaze tracking
Collect Training and Calibration Data for Gaze Tracking This tool allows collecting gaze data necessary for personal calibration or training of eye-tr
 5 Dec 17, 2022
5 Dec 17, 2022
Code for SALT: Stackelberg Adversarial Regularization, EMNLP 2021.
SALT: Stackelberg Adversarial Regularization Code for Adversarial Regularization as Stackelberg Game: An Unrolled Optimization Approach, EMNLP 2021. R
 10 Jan 10, 2022
10 Jan 10, 2022
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
124 Jan 3, 2023

Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer
MT5_paddle Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer English | 简体中文 mT5: A Massively
 2 Oct 17, 2021
2 Oct 17, 2021

Propose a principled and practically effective framework for unsupervised accuracy estimation and error detection tasks with theoretical analysis and state-of-the-art performance.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles This project is for the paper: Detecting Errors and Estimating
 13 Nov 21, 2022
13 Nov 21, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-quality pre-trained models from torchvision, MMLabs, and soon Pytorch Image Models. It orchestrates the end-to-end deep learning workflow allowing to train networks with easy-to-use robust high-performance libraries such as Pytorch-Lightning and Fastai
 789 Dec 29, 2022
789 Dec 29, 2022
Composing methods for ML training efficiency
MosaicML Composer contains a library of methods, and ways to compose them together for more efficient ML training.
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
This is a library for training and applying sparse fine-tunings with torch and transformers.
This is a library for training and applying sparse fine-tunings with torch and transformers. Please refer to our paper Composable Sparse Fine-Tuning f
 37 Dec 30, 2022
37 Dec 30, 2022

ECCV18 Workshops - Enhanced SRGAN. Champion PIRM Challenge on Perceptual Super-Resolution. The training codes are in BasicSR.
ESRGAN (Enhanced SRGAN) [ 🚀 BasicSR] [Real-ESRGAN] ✨ New Updates. We have extended ESRGAN to Real-ESRGAN, which is a more practical algorithm for rea
 4.7k Jan 2, 2023
4.7k Jan 2, 2023
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks This repository contains a TensorFlow implementation of "
 5 Jan 8, 2023
5 Jan 8, 2023

PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training”
A new codebase for popular Scene Graph Generation methods (2020). Visualization & Scene Graph Extraction on custom images/datasets are provided. It's also a PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training CVPR 2020”
 824 Jan 3, 2023
824 Jan 3, 2023
Code for reproducing experiments in "Improved Training of Wasserstein GANs"
Improved Training of Wasserstein GANs Code for reproducing experiments in "Improved Training of Wasserstein GANs". Prerequisites Python, NumPy, Tensor
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
DeCLIP Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. Our paper is available in arxiv Updates ** Ou
 470 Dec 30, 2022
470 Dec 30, 2022
Self-Supervised Speech Pre-training and Representation Learning Toolkit.
What's New Sep 2021: We host a challenge in AAAI workshop: The 2nd Self-supervised Learning for Audio and Speech Processing! See SUPERB official site
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Explaining in Style: Official TensorFlow Colab Explaining in Style: Training a GAN to explain a classifier in StyleSpace Oran Lang, Yossi Gandelsman,
 197 Nov 8, 2022
197 Nov 8, 2022
MosaicML Composer contains a library of methods, and ways to compose them together for more efficient ML training
MosaicML Composer MosaicML Composer contains a library of methods, and ways to compose them together for more efficient ML training. We aim to ease th
2.8k Jan 6, 2023
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
Calibrate your listeners! Robust communication-based training for pragmatic speakers. Findings of EMNLP 2021.
Calibrate your listeners! Robust communication-based training for pragmatic speakers Rose E. Wang, Julia White, Jesse Mu, Noah D. Goodman Findings of
 3 Apr 2, 2022
3 Apr 2, 2022

Making self-supervised learning work on molecules by using their 3D geometry to pre-train GNNs. Implemented in DGL and Pytorch Geometric.
3D Infomax improves GNNs for Molecular Property Prediction Video | Paper We pre-train GNNs to understand the geometry of molecules given only their 2D
 95 Dec 30, 2022
95 Dec 30, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

Code for the paper Relation Prediction as an Auxiliary Training Objective for Improving Multi-Relational Graph Representations (AKBC 2021).
Relation Prediction as an Auxiliary Training Objective for Knowledge Base Completion This repo provides the code for the paper Relation Prediction as
85 Jan 2, 2023
Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
 282 Jan 9, 2023
282 Jan 9, 2023
Pre-training BERT masked language models with custom vocabulary
Pre-training BERT Masked Language Models (MLM) This repository contains the method to pre-train a BERT model using custom vocabulary. It was used to p
 14 Nov 2, 2022
14 Nov 2, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
Unofficial PyTorch implementation of DeepMind's Perceiver IO with PyTorch Lightning scripts for distributed training
Unofficial PyTorch implementation of DeepMind's Perceiver IO with PyTorch Lightning scripts for distributed training
 251 Dec 25, 2022
251 Dec 25, 2022
ICLR 2021: Pre-Training for Context Representation in Conversational Semantic Parsing
SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing This repository contains code for the ICLR 2021 paper "SCoRE: Pre-Tr
28 Oct 2, 2022

DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect. It handles Algerian
 117 Jan 7, 2023
117 Jan 7, 2023
Training vision models with full-batch gradient descent and regularization
Stochastic Training is Not Necessary for Generalization -- Training competitive vision models without stochasticity This repository implements trainin
 32 Jan 6, 2023
32 Jan 6, 2023
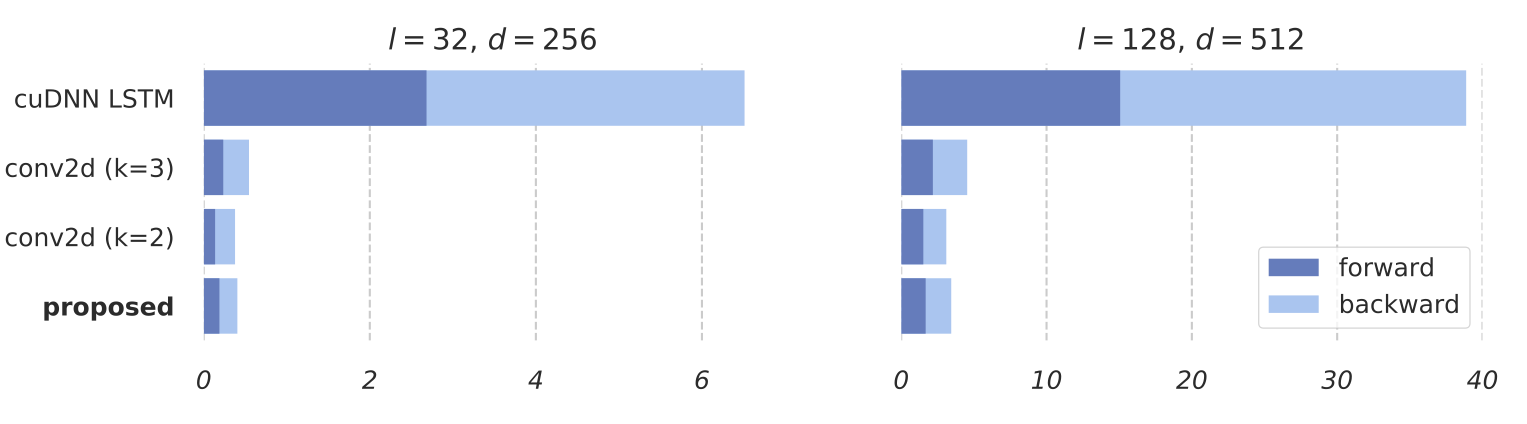
Training RNNs as Fast as CNNs
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022

A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You can find two approaches for achieving this in this repo.
multitask-learning-transformers A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You
 48 Jan 2, 2023
48 Jan 2, 2023

🧬 Training the car to do self-parking using a genetic algorithm
🧬 Training the car to do self-parking using a genetic algorithm
 652 Jan 3, 2023
652 Jan 3, 2023
Model factory is a ML training platform to help engineers to build ML models at scale
Model Factory Machine learning today is powering many businesses today, e.g., search engine, e-commerce, news or feed recommendation. Training high qu
 16 Sep 23, 2022
16 Sep 23, 2022
Pre-trained BERT Models for Ancient and Medieval Greek, and associated code for LaTeCH 2021 paper titled - "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek"
Ancient Greek BERT The first and only available Ancient Greek sub-word BERT model! State-of-the-art post fine-tuning on Part-of-Speech Tagging and Mor
 22 Dec 8, 2022
22 Dec 8, 2022
DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect.
117 Jan 7, 2023
🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
3.1k Jan 2, 2023
Training Confidence-Calibrated Classifier for Detecting Out-of-Distribution Samples / ICLR 2018
Training Confidence-Calibrated Classifier for Detecting Out-of-Distribution Samples This project is for the paper "Training Confidence-Calibrated Clas
 168 Nov 29, 2022
168 Nov 29, 2022

NEATEST: Evolving Neural Networks Through Augmenting Topologies with Evolution Strategy Training
NEATEST: Evolving Neural Networks Through Augmenting Topologies with Evolution Strategy Training
 16 Dec 5, 2022
16 Dec 5, 2022

RobustART: Benchmarking Robustness on Architecture Design and Training Techniques
The first comprehensive Robustness investigation benchmark on large-scale dataset ImageNet regarding ARchitecture design and Training techniques towards diverse noises.
 132 Dec 23, 2022
132 Dec 23, 2022

Reimplement of SimSwap training code
SimSwap-train Reimplement of SimSwap training code Instructions 1.Environment Preparation (1)Refer to the README document of SIMSWAP to configure the
 111 Dec 31, 2022
111 Dec 31, 2022
![A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]](https://user-images.githubusercontent.com/33194443/104581604-2592cb00-56a2-11eb-9610-5eaa0afb6e1f.png)
A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]
PINTO_model_zoo Please read the contents of the LICENSE file located directly under each folder before using the model. My model conversion scripts ar
 2.4k Jan 5, 2023
2.4k Jan 5, 2023
ConvNet training using pytorch
Convolutional networks using PyTorch This is a complete training example for Deep Convolutional Networks on various datasets (ImageNet, Cifar10, Cifar
 336 Dec 30, 2022
336 Dec 30, 2022

PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.)
pytorch-fcn PyTorch implementation of Fully Convolutional Networks. Requirements pytorch = 0.2.0 torchvision = 0.1.8 fcn = 6.1.5 Pillow scipy tqdm
 1.6k Jan 4, 2023
1.6k Jan 4, 2023
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022

Scripts for training an AI to play the endless runner Subway Surfers using a supervised machine learning approach by imitation and a convolutional neural network (CNN) for image classification
About subwAI subwAI - a project for training an AI to play the endless runner Subway Surfers using a supervised machine learning approach by imitation
 82 Jan 1, 2023
82 Jan 1, 2023

Code for paper "Which Training Methods for GANs do actually Converge? (ICML 2018)"
GAN stability This repository contains the experiments in the supplementary material for the paper Which Training Methods for GANs do actually Converg
 885 Jan 1, 2023
885 Jan 1, 2023

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
Git Hooks Tutorial.
Git Hooks Tutorial My public talk about this project at Sberloga: Git Hooks Is All You Need 1. Git Hooks 101 Init git repo: mkdir git_repo cd git_repo
 17 Oct 12, 2022
17 Oct 12, 2022
Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models.
Tevatron Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models. The toolkit has a modularized
 193 Jan 4, 2023
193 Jan 4, 2023

High level network definitions with pre-trained weights in TensorFlow
TensorNets High level network definitions with pre-trained weights in TensorFlow (tested with 2.1.0 = TF = 1.4.0). Guiding principles Applicability.
 1k Dec 13, 2022
1k Dec 13, 2022
PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.)
pytorch-fcn PyTorch implementation of Fully Convolutional Networks. Requirements pytorch = 0.2.0 torchvision = 0.1.8 fcn = 6.1.5 Pillow scipy tqdm
1.6k Jan 7, 2023

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
The uncompromising Python code formatter
The Uncompromising Code Formatter “Any color you like.” Black is the uncompromising Python code formatter. By using it, you agree to cede control over
 30.7k Jan 3, 2023
30.7k Jan 3, 2023
A2T: Towards Improving Adversarial Training of NLP Models (EMNLP 2021 Findings)
A2T: Towards Improving Adversarial Training of NLP Models This is the source code for the EMNLP 2021 (Findings) paper "Towards Improving Adversarial T
17 Oct 15, 2022
A machine learning library for spiking neural networks. Supports training with both torch and jax pipelines, and deployment to neuromorphic hardware.
Rockpool Rockpool is a Python package for developing signal processing applications with spiking neural networks. Rockpool allows you to build network
 21 Dec 14, 2022
21 Dec 14, 2022
The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing".
BMC The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing". BibTex entry available here. B
 383 Dec 16, 2022
383 Dec 16, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
1.3k Dec 30, 2022
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022

Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
2k Dec 31, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
67 Dec 1, 2022

The training code for the 4th place model at MDX 2021 leaderboard A.
The training code for the 4th place model at MDX 2021 leaderboard A.
 32 Dec 18, 2022
32 Dec 18, 2022
FireFlyer Record file format, writer and reader for DL training samples.
FFRecord The FFRecord format is a simple format for storing a sequence of binary records developed by HFAiLab, which supports random access and Linux
 77 Jan 4, 2023
77 Jan 4, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022
Must-read papers on improving efficiency for pre-trained language models.
Must-read papers on improving efficiency for pre-trained language models.
 89 Jan 3, 2023
89 Jan 3, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022

A stock information collector and parser for Taiwan and US market. Automatically send LINE message if the pre-defined rules are triggered.
agastock 開發動機 就在海運飆漲的2021年7月,差點跪在地上喜迎財富自由的當下,EPS超高好消息不斷的長榮竟然套在202元一去不回,有圖有真相(哭) 忽然體會到追高殺低不是辦法,魯蛇我得靠邏輯分析也能出頭天,經過三個月無數個不出門的周末,產出簡單的爬蟲和分析工具。 上過金融研訓院的量化交易
 12 Nov 16, 2022
12 Nov 16, 2022
NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking
pretrain4ir_tutorial NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking 用作NLPIR实验室, Pre-training
 12 Apr 7, 2022
12 Apr 7, 2022
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
 323 Jan 1, 2023
323 Jan 1, 2023
[EMNLP 2021] Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
RoSTER The source code used for Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training, p
 60 Dec 30, 2022
60 Dec 30, 2022
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Real-ESRGAN Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data Ported from https://github.com/xinntao/Real-ESRGAN Depend
 44 Dec 27, 2022
44 Dec 27, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023
Galileo library for large scale graph training by JD
近年来,图计算在搜索、推荐和风控等场景中获得显著的效果,但也面临超大规模异构图训练,与现有的深度学习框架Tensorflow和PyTorch结合等难题。 Galileo(伽利略)是一个图深度学习框架,具备超大规模、易使用、易扩展、高性能、双后端等优点,旨在解决超大规模图算法在工业级场景的落地难题,提
 128 Nov 29, 2022
128 Nov 29, 2022
Optimized code based on M2 for faster image captioning training
Transformer Captioning This repository contains the code for Transformer-based image captioning. Based on meshed-memory-transformer, we further optimi
 16 Dec 16, 2022
16 Dec 16, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023

CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection
CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection Usage usage: cve-2021-26084_confluence_rce.py [-h] --url URL [--cmd CMD] [--shell] CVE-2021-2
 92 Jul 20, 2022
92 Jul 20, 2022