832 Repositories
Python pre-training Libraries

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
 228 Nov 21, 2022
228 Nov 21, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022

A Fast Knowledge Distillation Framework for Visual Recognition
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
 129 Dec 24, 2022
129 Dec 24, 2022
Codebase for Inducing Causal Structure for Interpretable Neural Networks
Interchange Intervention Training (IIT) Codebase for Inducing Causal Structure for Interpretable Neural Networks Release Notes 12/01/2021: Code and Pa
 6 Oct 10, 2022
6 Oct 10, 2022
A PyTorch Toolbox for Face Recognition
FaceX-Zoo FaceX-Zoo is a PyTorch toolbox for face recognition. It provides a training module with various supervisory heads and backbones towards stat
 1.1k Dec 3, 2021
1.1k Dec 3, 2021
A fast, pure python implementation of the MuyGPs Gaussian process realization and training algorithm.
Fast implementation of the MuyGPs Gaussian process hyperparameter estimation algorithm MuyGPs is a GP estimation method that affords fast hyperparamet
 13 Dec 2, 2022
13 Dec 2, 2022
PyTorch implementation of paper A Fast Knowledge Distillation Framework for Visual Recognition.
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
129 Dec 24, 2022
A simple framwork to streamline the Domain Adaptation training process.
FastDA Introduction This is a simple framework for domain adaptation training. You can use it to build your own training process. It heavily relies on
 7 Nov 22, 2022
7 Nov 22, 2022
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022
Code and pre-trained models for "ReasonBert: Pre-trained to Reason with Distant Supervision", EMNLP'2021
ReasonBERT Code and pre-trained models for ReasonBert: Pre-trained to Reason with Distant Supervision, EMNLP'2021 Pretrained Models The pretrained mod
 29 Dec 19, 2022
29 Dec 19, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
Source code for "Efficient Training of BERT by Progressively Stacking"
Introduction This repository is the code to reproduce the result of Efficient Training of BERT by Progressively Stacking. The code is based on Fairseq
 101 Dec 2, 2022
101 Dec 2, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022

Understanding the Difficulty of Training Transformers
Admin Understanding the Difficulty of Training Transformers Guided by our analyses, we propose Adaptive Model Initialization (Admin), which successful
 300 Dec 29, 2022
300 Dec 29, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
8.4k Dec 28, 2022
[ACL-IJCNLP 2021] "EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets"
EarlyBERT This is the official implementation for the paper in ACL-IJCNLP 2021 "EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets" by
13 May 11, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022

Revisiting Self-Training for Few-Shot Learning of Language Model.
SFLM This is the implementation of the paper Revisiting Self-Training for Few-Shot Learning of Language Model. SFLM is short for self-training for few
 15 Nov 19, 2022
15 Nov 19, 2022
![[EMNLP 2021] Improving and Simplifying Pattern Exploiting Training](https://github.com/rrmenon10/ADAPET/raw/master/img/ADAPET_update.png)
[EMNLP 2021] Improving and Simplifying Pattern Exploiting Training
ADAPET This repository contains the official code for the paper: "Improving and Simplifying Pattern Exploiting Training". The model improves and simpl
 138 Dec 26, 2022
138 Dec 26, 2022
EMNLP 2021 paper "Pre-train or Annotate? Domain Adaptation with a Constrained Budget".
Pre-train or Annotate? Domain Adaptation with a Constrained Budget This repo contains code and data associated with EMNLP 2021 paper "Pre-train or Ann
 8 Dec 17, 2021
8 Dec 17, 2021

Source code for the ACL-IJCNLP 2021 paper entitled "T-DNA: Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adaptation" by Shizhe Diao et al.
T-DNA Source code for the ACL-IJCNLP 2021 paper entitled Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adapta
 17 Dec 22, 2022
17 Dec 22, 2022
The code is the training example of AAAI2022 Security AI Challenger Program Phase 8: Data Centric Robot Learning on ML models.
Example code of [Tianchi AAAI2022 Security AI Challenger Program Phase 8]
 22 Oct 14, 2022
22 Oct 14, 2022
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
 45 Dec 3, 2021
45 Dec 3, 2021

Efficient training of deep recommenders on cloud.
HybridBackend Introduction HybridBackend is a training framework for deep recommenders which bridges the gap between evolving cloud infrastructure and
 111 Dec 23, 2022
111 Dec 23, 2022

Official Implementation of DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation
DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation [Arxiv] [Paper] As acquiring pixel-wise an
 305 Dec 29, 2022
305 Dec 29, 2022
Code for "Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis
HAABSAStar Code for "Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis". This project builds on the code from https://gith
 1 Sep 14, 2020
1 Sep 14, 2020
![[NeurIPS 2021] Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples | ⛰️⚠️](https://github.com/sungyoon-lee/LossLandscapeMatters/raw/master/media/fig.png)
[NeurIPS 2021] Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples | ⛰️⚠️
Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples This repository is the official implementation of "Tow
 4 Jul 12, 2022
4 Jul 12, 2022
Official implementation of the NeurIPS 2021 paper Online Learning Of Neural Computations From Sparse Temporal Feedback
Online Learning Of Neural Computations From Sparse Temporal Feedback This repository is the official implementation of the NeurIPS 2021 paper Online L
 3 Dec 15, 2021
3 Dec 15, 2021
Official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive
TTT++ This is an official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive? TL;DR: Online Feature Alignment + Str
 39 Dec 25, 2022
39 Dec 25, 2022
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models This repository is the official implementation of the fol
 41 Dec 6, 2022
41 Dec 6, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
124 Jan 2, 2023
Minimalistic PyTorch training loop
Backbone for PyTorch training loop Will try to keep it minimalistic. pip install back from back import Bone Features Progress bar Checkpoints saving/l
 4 Jan 16, 2020
4 Jan 16, 2020
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Code of our paper "Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning"
CCOP Code of our paper Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning Requirement Install OpenSelfSup Install Detectron2
 5 Nov 30, 2021
5 Nov 30, 2021

The official implementation for "FQ-ViT: Fully Quantized Vision Transformer without Retraining".
FQ-ViT [arXiv] This repo contains the official implementation of "FQ-ViT: Fully Quantized Vision Transformer without Retraining". Table of Contents In
 132 Jan 8, 2023
132 Jan 8, 2023

Code implementing "Improving Deep Learning Interpretability by Saliency Guided Training"
Saliency Guided Training Code implementing "Improving Deep Learning Interpretability by Saliency Guided Training" by Aya Abdelsalam Ismail, Hector Cor
 8 Sep 22, 2022
8 Sep 22, 2022

Pre-Training 3D Point Cloud Transformers with Masked Point Modeling
Point-BERT: Pre-Training 3D Point Cloud Transformers with Masked Point Modeling Created by Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zho
 306 Jan 6, 2023
306 Jan 6, 2023
League of Legends Reinforcement Learning Environment (LoLRLE) multiple training scenarios using PPO.
League of Legends Reinforcement Learning Environment (LoLRLE) About This repo contains code to train an agent to play league of legends in a distribut
 2 Aug 19, 2022
2 Aug 19, 2022
Pre-trained Deep Learning models and demos (high quality and extremely fast)
OpenVINO™ Toolkit - Open Model Zoo repository This repository includes optimized deep learning models and a set of demos to expedite development of hi
 3.4k Dec 31, 2022
3.4k Dec 31, 2022
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics.
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics. By Andres Milioto @ University of Bonn. (for the new P
 314 Dec 30, 2022
314 Dec 30, 2022
PyTorch common framework to accelerate network implementation, training and validation
pytorch-framework PyTorch common framework to accelerate network implementation, training and validation. This framework is inspired by works from MML
 3 Dec 19, 2022
3 Dec 19, 2022
Code of our paper "Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning"
CCOP Code of our paper Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning Requirement Install OpenSelfSup Install Detectron2
21 Dec 13, 2022
Single-step adversarial training (AT) has received wide attention as it proved to be both efficient and robust.
Subspace Adversarial Training Single-step adversarial training (AT) has received wide attention as it proved to be both efficient and robust. However,
 15 Sep 2, 2022
15 Sep 2, 2022
This repo contains simple to use, pretrained/training-less models for speaker diarization.
PyDiar This repo contains simple to use, pretrained/training-less models for speaker diarization. Supported Models Binary Key Speaker Modeling Based o
 12 Jan 20, 2022
12 Jan 20, 2022

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
Training open neural machine translation models
Train Opus-MT models This package includes scripts for training NMT models using MarianNMT and OPUS data for OPUS-MT. More details are given in the Ma
 167 Jan 3, 2023
167 Jan 3, 2023
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
 799 Dec 28, 2022
799 Dec 28, 2022

High performance distributed framework for training deep learning recommendation models based on PyTorch.
PERSIA (Parallel rEcommendation tRaining System with hybrId Acceleration) is developed by AI platform@Kuaishou Technology, collaborating with ETH. It
 113 Nov 28, 2021
113 Nov 28, 2021
Automatically download the cwru data set, and then divide it into training data set and test data set
Automatically download the cwru data set, and then divide it into training data set and test data set.自动下载cwru数据集,然后分训练数据集和测试数据集
 6 Jun 27, 2022
6 Jun 27, 2022
Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script.
clip-text-decoder Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script. Example Predi
 36 Dec 21, 2022
36 Dec 21, 2022

Make differentially private training of transformers easy for everyone
private-transformers This codebase facilitates fast experimentation of differentially private training of Hugging Face transformers. What is this? Why
 73 Dec 28, 2022
73 Dec 28, 2022
Pytorch library for end-to-end transformer models training and serving
Pytorch library for end-to-end transformer models training and serving
 768 Jan 1, 2023
768 Jan 1, 2023
Code accompanying paper: Meta-Learning to Improve Pre-Training
Meta-Learning to Improve Pre-Training This folder contains code to run experiments in the paper Meta-Learning to Improve Pre-Training, NeurIPS 2021. P
 28 Dec 31, 2022
28 Dec 31, 2022
Scikit-Learn useful pre-defined Pipelines Hub
Scikit-Pipes Scikit-Learn useful pre-defined Pipelines Hub Usage: Install scikit-pipes It's advised to install sklearn-genetic using a virtual env, in
 1 Apr 26, 2022
1 Apr 26, 2022
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
105 Jan 8, 2022
Provides guideline on how to configure pre-commit hooks in your own python project
Pre-commit Configuration Guide The main aim of this repository is to act as a guide on how to configure the pre-commit hooks in your existing python p
 2 Mar 31, 2022
2 Mar 31, 2022

YOLOv4-v3 Training Automation API for Linux
This repository allows you to get started with training a state-of-the-art Deep Learning model with little to no configuration needed! You provide your labeled dataset or label your dataset using our BMW-LabelTool-Lite and you can start the training right away and monitor it in many different ways like TensorBoard or a custom REST API and GUI. NoCode training with YOLOv4 and YOLOV3 has never been so easy.
 626 Dec 31, 2022
626 Dec 31, 2022
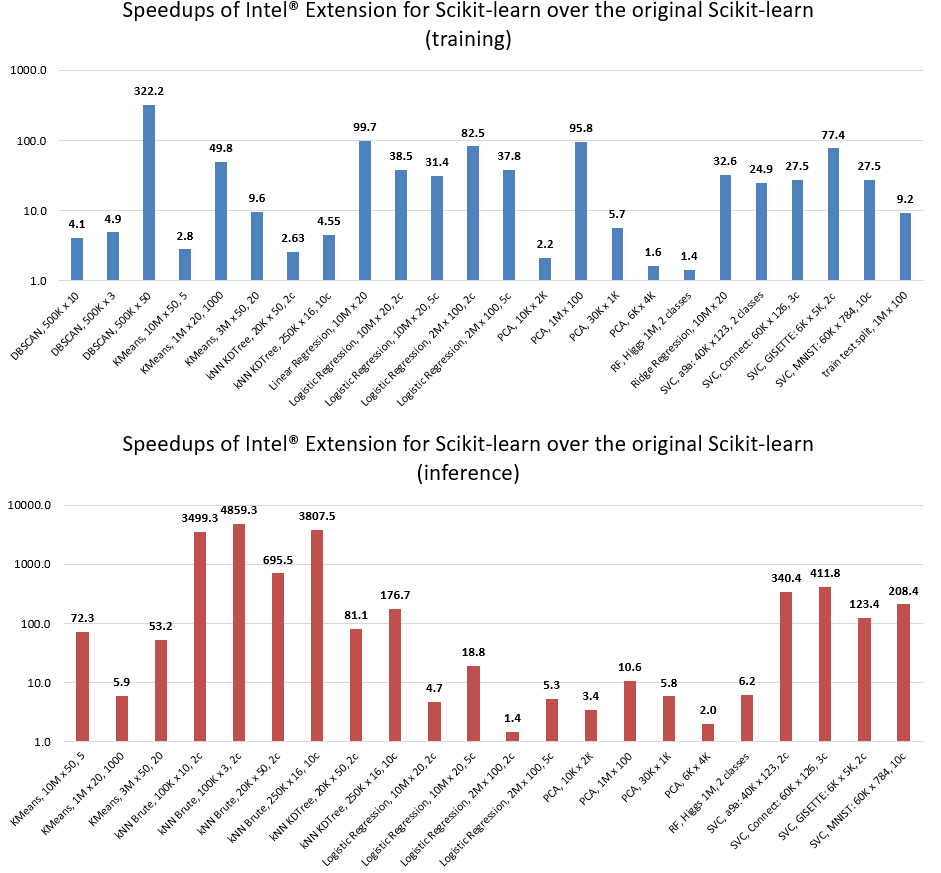
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Softlearning is a reinforcement learning framework for training maximum entropy policies in continuous domains. Includes the official implementation of the Soft Actor-Critic algorithm.
Softlearning Softlearning is a deep reinforcement learning toolbox for training maximum entropy policies in continuous domains. The implementation is
 997 Dec 30, 2022
997 Dec 30, 2022
This is a simple Tic-Tac-Toe game.
Tic-Tac-Toe Nosso famoso e tradicional Jogo da Velha, mas agora em Python. Development setup Para rodar o programa, basta instalar python em sua maqui
 1 Oct 10, 2022
1 Oct 10, 2022

Training code and evaluation benchmarks for the "Self-Supervised Policy Adaptation during Deployment" paper.
Self-Supervised Policy Adaptation during Deployment PyTorch implementation of PAD and evaluation benchmarks from Self-Supervised Policy Adaptation dur
 101 Nov 1, 2022
101 Nov 1, 2022
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
116 Jan 4, 2023
A colab notebook for training Stylegan2-ada on colab, transfer learning onto your own dataset.
Stylegan2-Ada-Google-Colab-Starter-Notebook A no thrills colab notebook for training Stylegan2-ada on colab. transfer learning onto your own dataset h
 66 Dec 16, 2022
66 Dec 16, 2022
Code to reprudece NeurIPS paper: Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N:M Transposable Masks
Accelerated Sparse Neural Training: A Provable and Efficient Method to FindN:M Transposable Masks Recently, researchers proposed pruning deep neural n
 4 Feb 23, 2022
4 Feb 23, 2022

Delve is a Python package for analyzing the inference dynamics of your PyTorch model.
Delve is a Python package for analyzing the inference dynamics of your PyTorch model.
 73 Dec 12, 2022
73 Dec 12, 2022
fastai ulmfit - Pretraining the Language Model, Fine-Tuning and training a Classifier
fast.ai ULMFiT with SentencePiece from pretraining to deployment Motivation: Why even bother with a non-BERT / Transformer language model? Short answe
 26 May 27, 2022
26 May 27, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023

This is the official PyTorch implementation for "Mesa: A Memory-saving Training Framework for Transformers".
A Memory-saving Training Framework for Transformers This is the official PyTorch implementation for Mesa: A Memory-saving Training Framework for Trans
 105 Dec 6, 2022
105 Dec 6, 2022
Live training loss plot in Jupyter Notebook for Keras, PyTorch and others
livelossplot Don't train deep learning models blindfolded! Be impatient and look at each epoch of your training! (RECENT CHANGES, EXAMPLES IN COLAB, A
 1.2k Jan 8, 2023
1.2k Jan 8, 2023

 3 Nov 23, 2021
3 Nov 23, 2021

This is the official PyTorch implementation for "Mesa: A Memory-saving Training Framework for Transformers".
Mesa: A Memory-saving Training Framework for Transformers This is the official PyTorch implementation for Mesa: A Memory-saving Training Framework for
105 Dec 6, 2022
The pure and clear PyTorch Distributed Training Framework.
The pure and clear PyTorch Distributed Training Framework. Introduction Requirements and Usage Dependency Dataset Basic Usage Slurm Cluster Usage Base
 208 Dec 20, 2022
208 Dec 20, 2022
Scheme for training and applying a label propagation framework
Factorisation-based Image Labelling Overview This is a scheme for training and applying the factorisation-based image labelling (FIL) framework. Some
 2 Dec 17, 2021
2 Dec 17, 2021
This toolkit provides codes to download and pre-process the SLUE datasets, train the baseline models, and evaluate SLUE tasks.
slue-toolkit We introduce Spoken Language Understanding Evaluation (SLUE) benchmark. This toolkit provides codes to download and pre-process the SLUE
 39 Sep 21, 2022
39 Sep 21, 2022

A tutorial on training a DarkNet YOLOv4 model for the CrowdHuman dataset
YOLOv4 CrowdHuman Tutorial This is a tutorial demonstrating how to train a YOLOv4 people detector using Darknet and the CrowdHuman dataset. Table of c
 118 Nov 10, 2022
118 Nov 10, 2022
Code for "Training Neural Networks with Fixed Sparse Masks" (NeurIPS 2021).
Code for "Training Neural Networks with Fixed Sparse Masks" (NeurIPS 2021).
 7 Nov 22, 2021
7 Nov 22, 2021

Neural network graphs and training metrics for PyTorch, Tensorflow, and Keras.
HiddenLayer A lightweight library for neural network graphs and training metrics for PyTorch, Tensorflow, and Keras. HiddenLayer is simple, easy to ex
 1.7k Dec 31, 2022
1.7k Dec 31, 2022
SageMaker Python SDK is an open source library for training and deploying machine learning models on Amazon SageMaker.
SageMaker Python SDK SageMaker Python SDK is an open source library for training and deploying machine learning models on Amazon SageMaker. With the S
 1.8k Jan 1, 2023
1.8k Jan 1, 2023
TensorFlow code and pre-trained models for BERT
BERT ***** New March 11th, 2020: Smaller BERT Models ***** This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece
32.9k Jan 8, 2023
Code for the paper "SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness" (NeurIPS 2021)
SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness (NeurIPS2021) This repository contains code for the paper "Smo
 17 Dec 27, 2022
17 Dec 27, 2022
Official PyTorch implementation for "Low Precision Decentralized Distributed Training with Heterogenous Data"
Low Precision Decentralized Training with Heterogenous Data Official PyTorch implementation for "Low Precision Decentralized Distributed Training with
 0 Nov 23, 2021
0 Nov 23, 2021
Code for "Training Neural Networks with Fixed Sparse Masks" (NeurIPS 2021).
Fisher Induced Sparse uncHanging (FISH) Mask This repo contains the code for Fisher Induced Sparse uncHanging (FISH) Mask training, from "Training Neu
37 Dec 30, 2022
A pre-trained language model for social media text in Spanish
RoBERTuito A pre-trained language model for social media text in Spanish READ THE FULL PAPER Github Repository RoBERTuito is a pre-trained language mo
 25 Dec 29, 2022
25 Dec 29, 2022
Simulation code and tutorial for BBHnet training data
Simulation Dataset for BBHnet NOTE: OLD README, UPDATE IN PROGRESS We generate simulation dataset to train BBHnet, our deep learning framework for det
 0 May 31, 2022
0 May 31, 2022