1246 Repositories
Python speech-nlp-datasets Libraries
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023

Galois is an auto code completer for code editors (or any text editor) based on OpenAI GPT-2.
Galois is an auto code completer for code editors (or any text editor) based on OpenAI GPT-2. It is trained (finetuned) on a curated list of approximately 45K Python (~470MB) files gathered from the Github. Currently, it just works properly on Python but not bad at other languages (thanks to GPT-2's power).
 91 Sep 23, 2022
91 Sep 23, 2022

The pyrelational package offers a flexible workflow to enable active learning with as little change to the models and datasets as possible
pyrelational is a python active learning library developed by Relation Therapeutics for rapidly implementing active learning pipelines from data management, model development (and Bayesian approximation), to creating novel active learning strategies.
 95 Dec 27, 2022
95 Dec 27, 2022

I³ Tracker for Essential Open Innovation Datasets
I³ Tracker for Essential Open Innovation Datasets This repository is set up to track, version, and contribute updates to the I³ Essential Open Innovat
 1 Feb 8, 2022
1 Feb 8, 2022

BCI datasets and algorithms
Brainda Welcome! First and foremost, Welcome! Thank you for visiting the Brainda repository which was initially released at this repo and reorganized
 52 Jan 4, 2023
52 Jan 4, 2023

HAIS_2GNN: 3D Visual Grounding with Graph and Attention
HAIS_2GNN: 3D Visual Grounding with Graph and Attention This repository is for the HAIS_2GNN research project. Tao Gu, Yue Chen Introduction The motiv
 1 Nov 26, 2022
1 Nov 26, 2022

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023
Speech Emotion Recognition with Fusion of Acoustic- and Linguistic-Feature-Based Decisions
APSIPA-SER-with-A-and-T This code is the implementation of Speech Emotion Recognition (SER) with acoustic and linguistic features. The network model i
 3 Jan 4, 2023
3 Jan 4, 2023
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
 0 Feb 8, 2022
0 Feb 8, 2022
Estimation of the CEFR complexity score of a given word, sentence or text.
NLP-Swedish … allows to estimate CEFR (Common European Framework of References) complexity score of a given word, sentence or text. CEFR scores come f
 3 Apr 30, 2022
3 Apr 30, 2022

Implementation of the method described in the Speech Resynthesis from Discrete Disentangled Self-Supervised Representations.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations Implementation of the method described in the Speech Resynthesis from Di
 4 Mar 11, 2022
4 Mar 11, 2022

Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5
NLP-Summarizer Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5 This project aimed to provide in
 1 Feb 7, 2022
1 Feb 7, 2022
TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech
TFPNER TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech Named entity recognition (NER), which aims at identifyin
 1 Feb 7, 2022
1 Feb 7, 2022
Application to help find best train itinerary, uses speech to text, has a spam filter to segregate invalid inputs, NLP and Pathfinding algos.
T-IAI-901-MSC2022 - GROUP 18 Gestion de projet Notre travail a été organisé et réparti dans un Trello. https://trello.com/b/X3s2fpPJ/ia-projet Install
 1 Feb 5, 2022
1 Feb 5, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
 2 Jun 10, 2022
2 Jun 10, 2022
A voice control utility for Spotify
Spotify Voice Control A voice control utility for Spotify · Report Bug · Request
 27 Jan 1, 2023
27 Jan 1, 2023
GraphNLI: A Graph-based Natural Language Inference Model for Polarity Prediction in Online Debates
GraphNLI: A Graph-based Natural Language Inference Model for Polarity Prediction in Online Debates Vibhor Agarwal, Sagar Joglekar, Anthony P. Young an
 2 Jun 30, 2022
2 Jun 30, 2022
Final Project for the Intel AI Readiness Boot Camp NLP (Jan)
NLP Boot Camp (Jan) Synopsis Full Name: Prameya Mohanty Name of your School: Delhi Public School, Rourkela Class: VIII Title of the Project: iTransect
 1 Feb 1, 2022
1 Feb 1, 2022

Espial is an engine for automated organization and discovery of personal knowledge
Live Demo (currently not running, on it) Espial is an engine for automated organization and discovery in knowledge bases. It can be adapted to run wit
 159 Dec 30, 2022
159 Dec 30, 2022
Mednlp - Medical natural language parsing and utility library
Medical natural language parsing and utility library A natural language medical
 3 Aug 24, 2022
3 Aug 24, 2022
Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech
epub2audiobook Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech Input examples qual a pasta do seu
 7 Aug 25, 2022
7 Aug 25, 2022
LSTM model - IMDB review sentiment analysis
NLP - Movie review sentiment analysis The colab notebook contains the code for building a LSTM Recurrent Neural Network that gives 87-88% accuracy on
 1 Jan 29, 2022
1 Jan 29, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022
List of Land Cover datasets in the GEE Catalog
List of Land Cover datasets in the GEE Catalog A list of all the Land Cover (or discrete) datasets in Google Earth Engine. Values, Colors and Descript
 5 Aug 24, 2022
5 Aug 24, 2022
In this workshop we will be exploring NLP state of the art transformers, with SOTA models like T5 and BERT, then build a model using HugginFace transformers framework.
Transformers are all you need In this workshop we will be exploring NLP state of the art transformers, with SOTA models like T5 and BERT, then build a
 8 Apr 13, 2022
8 Apr 13, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022
Pytorch Implementation of Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
NANSY: Unofficial Pytorch Implementation of Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations Notice Papers' D
 104 Dec 23, 2022
104 Dec 23, 2022
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
 10 Oct 13, 2022
10 Oct 13, 2022
NLP applications using deep learning.
NLP-Natural-Language-Processing NLP applications using deep learning like text generation etc. 1- Poetry Generation: Using a collection of Irish Poem
 1 Jan 27, 2022
1 Jan 27, 2022
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 1, 2023
213 Jan 1, 2023
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022
Leaf: Multiple-Choice Question Generation
Leaf: Multiple-Choice Question Generation Easy to use and understand multiple-choice question generation algorithm using T5 Transformers. The applicat
 62 Dec 20, 2022
62 Dec 20, 2022
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques This repository is derived from the NMTGMinor
 1 Sep 7, 2022
1 Sep 7, 2022
Code for the paper titled "Prabhupadavani: A Code-mixed Speech Translation Data for 25 languages"
Prabhupadavani: A Code-mixed Speech Translation Data for 25 languages Code for the paper titled "Prabhupadavani: A Code-mixed Speech Translation Data
 12 Dec 1, 2022
12 Dec 1, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022

Predict the spans of toxic posts that were responsible for the toxic label of the posts
toxic-spans-detection An attempt at the SemEval 2021 Task 5: Toxic Spans Detection. The Toxic Spans Detection task of SemEval2021 required participant
 3 Jul 24, 2022
3 Jul 24, 2022
Election Exit Poll Prediction and U.S.A Presidential Speech Analysis using Machine Learning
Machine_Learning Election Exit Poll Prediction and U.S.A Presidential Speech Analysis using Machine Learning This project is based on 2 case-studies:
 1 Jan 27, 2022
1 Jan 27, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023

This Repository is an up-to-date version of Harvard nlp's Legacy code and a Refactoring of the jupyter notebook version as a shell script version.
This Repository is an up-to-date version of Harvard nlp's Legacy code and a Refactoring of the jupyter notebook version as a shell script version.
 17 Sep 25, 2022
17 Sep 25, 2022
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

Twitter bot that uses NLP models to summarize news articles referenced in a user's twitter timeline
Twitter-News-Summarizer Twitter bot that uses NLP models to summarize news articles referenced in a user's twitter timeline 1.) Extracts all tweets fr
 1 Jan 27, 2022
1 Jan 27, 2022

This is a NLP based project to extract effective date of the contract from their text files.
Date-Extraction-from-Contracts This is a NLP based project to extract effective date of the contract from their text files. Problem statement This is
 1 Jan 26, 2022
1 Jan 26, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
 68 Dec 16, 2022
68 Dec 16, 2022
Toward Model Interpretability in Medical NLP
Toward Model Interpretability in Medical NLP LING380: Topics in Computational Linguistics Final Project James Cross ([email protected]) and Daniel Kim
 1 Mar 4, 2022
1 Mar 4, 2022
Wikipedia-Utils: Preprocessing Wikipedia Texts for NLP
Wikipedia-Utils: Preprocessing Wikipedia Texts for NLP This repository maintains some utility scripts for retrieving and preprocessing Wikipedia text
 44 Oct 19, 2022
44 Oct 19, 2022
BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions
BERTopic BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable
 3.6k Jan 7, 2023
3.6k Jan 7, 2023

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023
Some utils for auto speech recognition
About Some utils for auto speech recognition. Utils Util Description Script Reset audio Reset sample rate, sample width, etc of audios.
 1 Jan 24, 2022
1 Jan 24, 2022
Stanford CoreNLP provides a set of natural language analysis tools written in Java
Stanford CoreNLP Stanford CoreNLP provides a set of natural language analysis tools written in Java. It can take raw human language text input and giv
 8.8k Jan 7, 2023
8.8k Jan 7, 2023
Simple Text-To-Speech Bot For Discord
Simple Text-To-Speech Bot For Discord This is a very simple TTS bot for discord made with python. For this bot you need FFMPEG, see installation to se
 1 Sep 26, 2022
1 Sep 26, 2022
Japanese NLP Library
Japanese NLP Library Back to Home Contents 1 Requirements 1.1 Links 1.2 Install 1.3 History 2 Libraries and Modules 2.1 Tokenize jTokenize.py 2.2 Cabo
 144 Dec 27, 2022
144 Dec 27, 2022

Open solution to the Toxic Comment Classification Challenge
Starter code: Kaggle Toxic Comment Classification Challenge More competitions 🎇 Check collection of public projects 🎁 , where you can find multiple
 153 Jun 22, 2022
153 Jun 22, 2022
Deep Learning Topics with Computer Vision & NLP
Deep learning Udacity Course Deep Learning Topics with Computer Vision & NLP for the AWS Machine Learning Engineer Nanodegree Program Tasks are mostly
 1 Jan 20, 2022
1 Jan 20, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022
Blackstone is a spaCy model and library for processing long-form, unstructured legal text
Blackstone Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project f
 579 Jan 8, 2023
579 Jan 8, 2023

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Original Implementation of Prompt Tuning from Lester, et al, 2021
Prompt Tuning This is the code to reproduce the experiments from the EMNLP 2021 paper "The Power of Scale for Parameter-Efficient Prompt Tuning" (Lest
 282 Dec 28, 2022
282 Dec 28, 2022
Awesome AI Learning with +100 AI Cheat-Sheets, Free online Books, Top Courses, Best Videos and Lectures, Papers, Tutorials, +99 Researchers, Premium Websites, +121 Datasets, Conferences, Frameworks, Tools
All about AI with Cheat-Sheets(+100 Cheat-sheets), Free Online Books, Courses, Videos and Lectures, Papers, Tutorials, Researchers, Websites, Datasets
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022

A real-time speech emotion recognition application using Scikit-learn and gradio
Speech-Emotion-Recognition-App A real-time speech emotion recognition application using Scikit-learn and gradio. Requirements librosa==0.6.3 numpy sou
 6 Oct 4, 2022
6 Oct 4, 2022
A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk.
Simple-Vosk A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk. Check out the official Vosk G
 2 Jun 19, 2022
2 Jun 19, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
84 Dec 20, 2022

TCNN Temporal convolutional neural network for real-time speech enhancement in the time domain
TCNN Pandey A, Wang D L. TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain[C]//ICASSP 2019-2019 IEEE Int
 16 Dec 30, 2022
16 Dec 30, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022

In this project, we compared Spanish BERT and Multilingual BERT in the Sentiment Analysis task.
Applying BERT Fine Tuning to Sentiment Classification on Amazon Reviews Abstract Sentiment analysis has made great progress in recent years, due to th
 5 Jan 3, 2022
5 Jan 3, 2022

Twitter-NLP-Analysis - Twitter Natural Language Processing Analysis
Twitter-NLP-Analysis Business Problem I got last @turk_politika 3000 tweets with
 7 Mar 12, 2022
7 Mar 12, 2022
Repositório do trabalho de introdução a NLP
Trabalho da disciplina de BI NLP Repositório do trabalho da disciplina Introdução a Processamento de Linguagem Natural da pós BI-Master da PUC-RIO. Eq
 1 Jan 18, 2022
1 Jan 18, 2022
In this Notebook I've build some machine-learning and deep-learning to classify corona virus tweets, in both multi class classification and binary classification.
Hello, This Notebook Contains Example of Corona Virus Tweets Multi Class Classification. - Classes is: Extremely Positive, Positive, Extremely Negativ
 3 Dec 6, 2022
3 Dec 6, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
Few-Shot-Intent-Detection includes popular challenging intent detection datasets with/without OOS queries and state-of-the-art baselines and results.
Few-Shot-Intent-Detection Few-Shot-Intent-Detection is a repository designed for few-shot intent detection with/without Out-of-Scope (OOS) intents. It
 73 Dec 26, 2022
73 Dec 26, 2022

Python Auto-ML Package for Tabular Datasets
Tabular-AutoML AutoML Package for tabular datasets Tabular dataset tuning is now hassle free! Run one liner command and get best tuning and processed
 18 Nov 20, 2022
18 Nov 20, 2022
A natural language processing model for sequential sentence classification in medical abstracts.
NLP PubMed Medical Research Paper Abstract (Randomized Controlled Trial) A natural language processing model for sequential sentence classification in
 1 Jan 17, 2022
1 Jan 17, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 847 Dec 19, 2022
847 Dec 19, 2022

In this project, we aim to achieve the task of predicting emojis from tweets. We aim to investigate the relationship between words and emojis.
Making Emojis More Predictable by Karan Abrol, Karanjot Singh and Pritish Wadhwa, Natural Language Processing (CSE546) under the guidance of Dr. Shad
 2 Jan 17, 2022
2 Jan 17, 2022
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes The codes for simu
 1 Jan 12, 2022
1 Jan 12, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
 26 Jan 16, 2022
26 Jan 16, 2022
[ WSDM '22 ] On Sampling Collaborative Filtering Datasets
On Sampling Collaborative Filtering Datasets This repository contains the implementation of many popular sampling strategies, along with various expli
 17 Dec 8, 2022
17 Dec 8, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023
An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're feeling.
Disease detection API for MediSearch An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're fe
 1 Jan 15, 2022
1 Jan 15, 2022
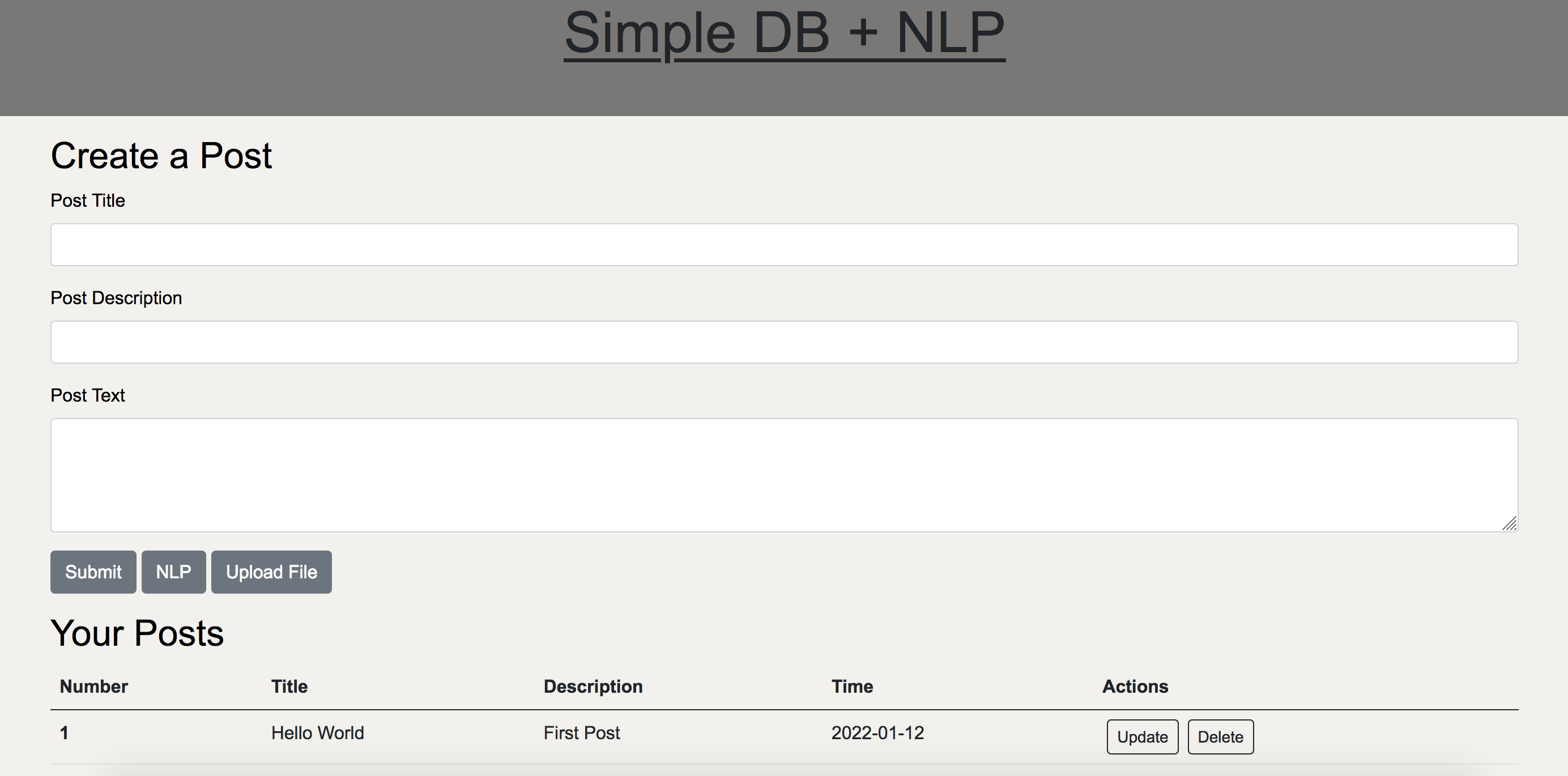
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
 1 Jan 15, 2022
1 Jan 15, 2022
NLP: SLU tagging
NLP: SLU tagging
 3 Jan 14, 2022
3 Jan 14, 2022

auto_code_complete is a auto word-completetion program which allows you to customize it on your need
auto_code_complete v1.3 purpose and usage auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the m
 2 Feb 22, 2022
2 Feb 22, 2022
Cl datasets - PyTorch image dataloaders and utility functions to load datasets for supervised continual learning
Continual learning datasets Introduction This repository contains PyTorch image
 5 Aug 28, 2022
5 Aug 28, 2022

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
👄 The most accurate natural language detection library for Python, suitable for long and short text alike
1. What does this library do? Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a prepr
 334 Dec 30, 2022
334 Dec 30, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
118 Jan 6, 2023

Sentiment-Analysis and EDA on the IMDB Movie Review Dataset
Sentiment-Analysis and EDA on the IMDB Movie Review Dataset The main part of the work focuses on the exploration and study of different approaches whi
 1 Jan 12, 2022
1 Jan 12, 2022
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023

I-Spy is a discord and twitter bot 🤖 that keeps a check on usage foul language, hate-speech and NSFW contents
I-Spy is a discord and twitter bot 🤖 that keeps a check on usage foul language, hate-speech and NSFW contents. It is the one stop solution to monitor your discord servers and twitter handles against community demons by offering content moderation.
 5 Nov 16, 2022
5 Nov 16, 2022

PyTorch implementation of Lip to Speech Synthesis with Visual Context Attentional GAN (NeurIPS2021)
Lip to Speech Synthesis with Visual Context Attentional GAN This repository contains the PyTorch implementation of the following paper: Lip to Speech
 6 Nov 2, 2022
6 Nov 2, 2022
Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis
Introduction This is an implementation of our paper Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis.
 24 Dec 6, 2022
24 Dec 6, 2022