341 Repositories
Python huggingface-datasets Libraries
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
115 Dec 16, 2022
Example notebooks for working with SageMaker Studio Lab. Sign up for an account at the link below!
SageMaker Studio Lab Sample Notebooks Available today in public preview. If you are looking for a no-cost compute environment to run Jupyter notebooks
 304 Jan 1, 2023
304 Jan 1, 2023

Easy-to-use library to boost AI inference leveraging state-of-the-art optimization techniques.
NEW RELEASE How Nebullvm Works • Tutorials • Benchmarks • Installation • Get Started • Optimization Examples Discord | Website | LinkedIn | Twitter Ne
 1.7k Dec 31, 2022
1.7k Dec 31, 2022
HugsVision is a easy to use huggingface wrapper for state-of-the-art computer vision
HugsVision is an open-source and easy to use all-in-one huggingface wrapper for computer vision. The goal is to create a fast, flexible and user-frien
 166 Nov 27, 2022
166 Nov 27, 2022
🤗🖼️ HuggingPics: Fine-tune Vision Transformers for anything using images found on the web.
🤗 🖼️ HuggingPics Fine-tune Vision Transformers for anything using images found on the web. Check out the video below for a walkthrough of this proje
 185 Dec 21, 2022
185 Dec 21, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023
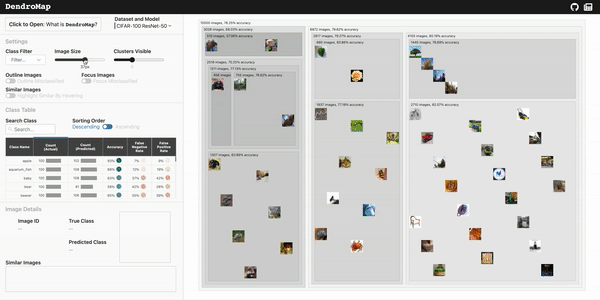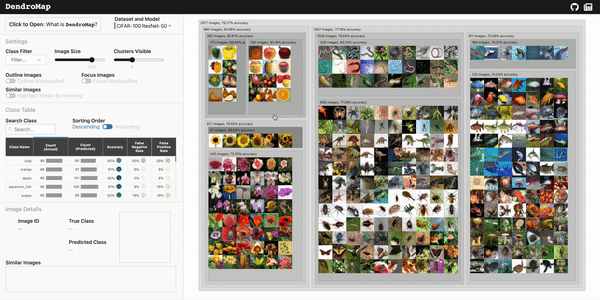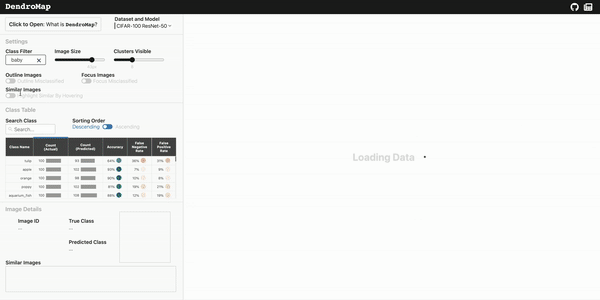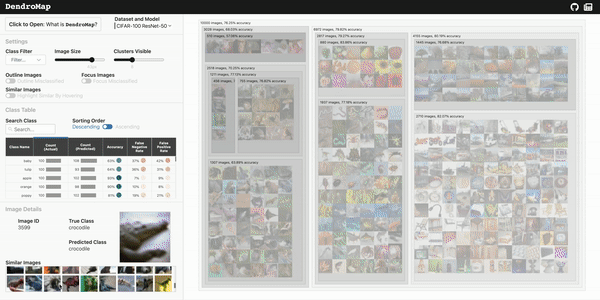
This repository contains the DendroMap implementation for scalable and interactive exploration of image datasets in machine learning.
DendroMap DendroMap is an interactive tool to explore large-scale image datasets used for machine learning. A deep understanding of your data can be v
 33 Dec 30, 2022
33 Dec 30, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022

PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI
data2vec-pytorch PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI (F
 105 Jan 4, 2023
105 Jan 4, 2023

Enterprise Scale NLP with Hugging Face & SageMaker Workshop series
Workshop: Enterprise-Scale NLP with Hugging Face & Amazon SageMaker Earlier this year we announced a strategic collaboration with Amazon to make it ea
 161 Dec 16, 2022
161 Dec 16, 2022
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022
Framework for evaluating ANNS algorithms on billion scale datasets.
Billion-Scale ANN http://big-ann-benchmarks.com/ Install The only prerequisite is Python (tested with 3.6) and Docker. Works with newer versions of Py
 132 Dec 24, 2022
132 Dec 24, 2022
![[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets](https://github.com/autonomousvision/stylegan_xl/raw/main/media/banner.png)
[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
[Project] [PDF] This repository contains code for our SIGGRAPH'22 paper "StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets" by Axel Sauer, Katja
 742 Jan 4, 2023
742 Jan 4, 2023

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
 66 Dec 14, 2022
66 Dec 14, 2022
Implementation of Basic Machine Learning Algorithms on small datasets using Scikit Learn.
Basic Machine Learning Algorithms All the basic Machine Learning Algorithms are implemented in Python using libraries Acknowledgements Machine Learnin
 47 Oct 16, 2022
47 Oct 16, 2022
Helping data scientists better understand their datasets and models in text classification. With love from ServiceNow.
Azimuth, an open-source dataset and error analysis tool for text classification, with love from ServiceNow. Overview Azimuth is an open source applica
 145 Dec 23, 2022
145 Dec 23, 2022
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets.
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets. It makes dataset creation more effective and helps find essential insights from training results and improves AI performance.
 27 Oct 22, 2022
27 Oct 22, 2022

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
An extension package of 🤗 Datasets that provides support for executing arbitrary SQL queries on HF datasets
datasets_sql A 🤗 Datasets extension package that provides support for executing arbitrary SQL queries on HF datasets. It uses DuckDB as a SQL engine
 19 Dec 15, 2022
19 Dec 15, 2022
This is a general repo that helps you develop fast/effective NLP classifiers using Huggingface
NLP Classifier Introduction This project trains a bert model on any NLP classifcation model. And uses the model in make predictions on new data using
 3 Mar 11, 2022
3 Mar 11, 2022
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
 2 Feb 14, 2022
2 Feb 14, 2022
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data"
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data" You can download the pretrained
 3 May 7, 2022
3 May 7, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022

Datasets and pretrained Models for StyleGAN3 ...
Datasets and pretrained Models for StyleGAN3 ... Dear arfiticial friend, this is a collection of artistic datasets and models that we have put togethe
 34 Oct 6, 2022
34 Oct 6, 2022
Notebook and code to synthesize complex and highly dimensional datasets using Gretel APIs.
Gretel Trainer This code is designed to help users successfully train synthetic models on complex datasets with high row and column counts. The code w
 24 Nov 3, 2022
24 Nov 3, 2022
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023

The pyrelational package offers a flexible workflow to enable active learning with as little change to the models and datasets as possible
pyrelational is a python active learning library developed by Relation Therapeutics for rapidly implementing active learning pipelines from data management, model development (and Bayesian approximation), to creating novel active learning strategies.
 95 Dec 27, 2022
95 Dec 27, 2022

I³ Tracker for Essential Open Innovation Datasets
I³ Tracker for Essential Open Innovation Datasets This repository is set up to track, version, and contribute updates to the I³ Essential Open Innovat
 1 Feb 8, 2022
1 Feb 8, 2022

BCI datasets and algorithms
Brainda Welcome! First and foremost, Welcome! Thank you for visiting the Brainda repository which was initially released at this repo and reorganized
 52 Jan 4, 2023
52 Jan 4, 2023

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022
List of Land Cover datasets in the GEE Catalog
List of Land Cover datasets in the GEE Catalog A list of all the Land Cover (or discrete) datasets in Google Earth Engine. Values, Colors and Descript
 5 Aug 24, 2022
5 Aug 24, 2022
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023
ChatBot-Pytorch - A GPT-2 ChatBot implemented using Pytorch and Huggingface-transformers
ChatBot-Pytorch A GPT-2 ChatBot implemented using Pytorch and Huggingface-transf
 42 Dec 9, 2022
42 Dec 9, 2022
Use AutoModelForSeq2SeqLM in Huggingface Transformers to train COMET
Training COMET using seq2seq setting Use AutoModelForSeq2SeqLM in Huggingface Transformers to train COMET. The codes are modified from run_summarizati
 9 Dec 17, 2022
9 Dec 17, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022
Awesome AI Learning with +100 AI Cheat-Sheets, Free online Books, Top Courses, Best Videos and Lectures, Papers, Tutorials, +99 Researchers, Premium Websites, +121 Datasets, Conferences, Frameworks, Tools
All about AI with Cheat-Sheets(+100 Cheat-sheets), Free Online Books, Courses, Videos and Lectures, Papers, Tutorials, Researchers, Websites, Datasets
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
Few-Shot-Intent-Detection includes popular challenging intent detection datasets with/without OOS queries and state-of-the-art baselines and results.
Few-Shot-Intent-Detection Few-Shot-Intent-Detection is a repository designed for few-shot intent detection with/without Out-of-Scope (OOS) intents. It
 73 Dec 26, 2022
73 Dec 26, 2022

Python Auto-ML Package for Tabular Datasets
Tabular-AutoML AutoML Package for tabular datasets Tabular dataset tuning is now hassle free! Run one liner command and get best tuning and processed
 18 Nov 20, 2022
18 Nov 20, 2022
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes The codes for simu
 1 Jan 12, 2022
1 Jan 12, 2022
[ WSDM '22 ] On Sampling Collaborative Filtering Datasets
On Sampling Collaborative Filtering Datasets This repository contains the implementation of many popular sampling strategies, along with various expli
 17 Dec 8, 2022
17 Dec 8, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023
Cl datasets - PyTorch image dataloaders and utility functions to load datasets for supervised continual learning
Continual learning datasets Introduction This repository contains PyTorch image
 5 Aug 28, 2022
5 Aug 28, 2022
Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis
Introduction This is an implementation of our paper Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis.
 24 Dec 6, 2022
24 Dec 6, 2022
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022

A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets
HOW TO USE THIS PROJECT A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets Based on DeepLabCut toolbox, we run wit
 1 Jan 10, 2022
1 Jan 10, 2022
![[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021](https://github.com/hasanirtiza/Pedestron/raw/master/gifs/1.gif)
[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021
Pedestron Pedestron is a MMdetection based repository, that focuses on the advancement of research on pedestrian detection. We provide a list of detec
 594 Jan 5, 2023
594 Jan 5, 2023
Exploration of BERT-based models on twitter sentiment classifications
twitter-sentiment-analysis Explore the relationship between twitter sentiment of Tesla and its stock price/return. Explore the effect of different BER
 2 Oct 2, 2022
2 Oct 2, 2022

A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
 65 Dec 19, 2022
65 Dec 19, 2022
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023
A general and strong 3D object detection codebase that supports more methods, datasets and tools (debugging, recording and analysis).
ALLINONE-Det ALLINONE-Det is a general and strong 3D object detection codebase built on OpenPCDet, which supports more methods, datasets and tools (de
 5 Nov 3, 2022
5 Nov 3, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022

Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
 5.3k Dec 30, 2022
5.3k Dec 30, 2022

Repository for Project Insight: NLP as a Service
Project Insight NLP as a Service Contents Introduction Features Installation Setup and Documentation Project Details Demonstration Directory Details H
 286 Dec 6, 2022
286 Dec 6, 2022
A Streamlit web app that generates Rick and Morty stories using GPT2.
Rick and Morty Story Generator This project uses a pre-trained GPT2 model, which was fine-tuned on Rick and Morty transcripts, to generate new stories
 33 Oct 13, 2022
33 Oct 13, 2022

Rhyme with AI
Local development Create a conda virtual environment and activate it: conda env create --file environment.yml conda activate rhyme-with-ai Install the
 28 Nov 21, 2022
28 Nov 21, 2022

Streamlit tool to explore coco datasets
What is this This tool given a COCO annotations file and COCO predictions file will let you explore your dataset, visualize results and calculate impo
 75 Dec 16, 2022
75 Dec 16, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022

Interactive dimensionality reduction for large datasets
BlosSOM 🌼 BlosSOM is a graphical environment for running semi-supervised dimensionality reduction with EmbedSOM. You can use it to explore multidimen
 19 Dec 14, 2022
19 Dec 14, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022

SPT_LSA_ViT - Implementation for Visual Transformer for Small-size Datasets
Vision Transformer for Small-Size Datasets Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song | Paper Inha University Abstract Recently, the Vision
 87 Jan 1, 2023
87 Jan 1, 2023
StyleGAN2-ADA-training-jupyter - Training custom datasets in styleGAN2-ADA by NVIDIA using Jupyter
styleGAN2-ADA-training-jupyter Training custom datasets in styleGAN2-ADA on Jupyter Official StyleGAN2-ADA by NIVIDIA Paper Training Generative Advers
 2 Feb 24, 2022
2 Feb 24, 2022
Datasets for new state-of-the-art challenge in disentanglement learning
High resolution disentanglement datasets This repository contains the Falcor3D and Isaac3D datasets, which present a state-of-the-art challenge for co
 37 May 26, 2022
37 May 26, 2022
Quickly download, clean up, and install public datasets into a database management system
Finding data is one thing. Getting it ready for analysis is another. Acquiring, cleaning, standardizing and importing publicly available data is time
 274 Jan 4, 2023
274 Jan 4, 2023
Python script that analyses the given datasets and comes up with the best polynomial regression representation with the smallest polynomial degree possible
Python script that analyses the given datasets and comes up with the best polynomial regression representation with the smallest polynomial degree possible, to be the most reliable with the least complexity possible
 2 Aug 1, 2022
2 Aug 1, 2022
A NASA MEaSUREs project to provide automated, low latency, global glacier flow and elevation change datasets
Notebooks A NASA MEaSUREs project to provide automated, low latency, global glacier flow and elevation change datasets This repository provides tools
 27 Oct 25, 2022
27 Oct 25, 2022

Code to generate datasets used in "How Useful is Self-Supervised Pretraining for Visual Tasks?"
Synthetic dataset rendering Framework for producing the synthetic datasets used in: How Useful is Self-Supervised Pretraining for Visual Tasks? Alejan
 21 Apr 29, 2022
21 Apr 29, 2022

Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
 689 Dec 25, 2022
689 Dec 25, 2022
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
Datasets with Softcatalà website content
softcatala-web-dataset This repository contains Sofcatalà web site content (articles and programs descriptions). Dataset are available in the dataset
 2 Dec 26, 2021
2 Dec 26, 2021
LynxKite: a complete graph data science platform for very large graphs and other datasets.
LynxKite is a complete graph data science platform for very large graphs and other datasets. It seamlessly combines the benefits of a friendly graphical interface and a powerful Python API.
 124 Dec 14, 2022
124 Dec 14, 2022
A Python library that simplifies the extraction of datasets from XML content.
xmldataset: simple xml parsing 🗃️ XML Dataset: simple xml parsing Documentation: https://xmldataset.readthedocs.io A Python library that simplifies t
 75 Dec 30, 2022
75 Dec 30, 2022
Index different CKAN entities in Solr, not just datasets
ckanext-sitesearch Index different CKAN entities in Solr, not just datasets Requirements This extension requires CKAN 2.9 or higher and Python 3 Featu
 3 Dec 2, 2022
3 Dec 2, 2022
Train BPE with fastBPE, and load to Huggingface Tokenizer.
BPEer Train BPE with fastBPE, and load to Huggingface Tokenizer. Description The BPETrainer of Huggingface consumes a lot of memory when I am training
 1 Dec 23, 2021
1 Dec 23, 2021
Final project code: Implementing MAE with downscaled encoders and datasets, for ESE546 FA21 at University of Pennsylvania
546 Final Project: Masked Autoencoder Haoran Tang, Qirui Wu 1. Training To train the network, please run mae_pretraining.py. Please modify folder path
 0 Apr 22, 2022
0 Apr 22, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
AKShare is an elegant and simple financial data interface library for Python, built for human beings
AKShare is an elegant and simple financial data interface library for Python, built for human beings
 5.8k Dec 30, 2022
5.8k Dec 30, 2022
An elaborate and exhaustive paper list for Named Entity Recognition (NER)
Named-Entity-Recognition-NER-Papers by Pengfei Liu, Jinlan Fu and other contributors. An elaborate and exhaustive paper list for Named Entity Recognit
 388 Dec 18, 2022
388 Dec 18, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022