1246 Repositories
Python speech-nlp-datasets Libraries
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022

A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets
HOW TO USE THIS PROJECT A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets Based on DeepLabCut toolbox, we run wit
 1 Jan 10, 2022
1 Jan 10, 2022
![[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021](https://github.com/hasanirtiza/Pedestron/raw/master/gifs/1.gif)
[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021
Pedestron Pedestron is a MMdetection based repository, that focuses on the advancement of research on pedestrian detection. We provide a list of detec
 594 Jan 5, 2023
594 Jan 5, 2023
Exploration of BERT-based models on twitter sentiment classifications
twitter-sentiment-analysis Explore the relationship between twitter sentiment of Tesla and its stock price/return. Explore the effect of different BER
 2 Oct 2, 2022
2 Oct 2, 2022

A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
 65 Dec 19, 2022
65 Dec 19, 2022
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023
Code and data accompanying Natural Language Processing with PyTorch
Natural Language Processing with PyTorch Build Intelligent Language Applications Using Deep Learning By Delip Rao and Brian McMahan Welcome. This is a
 1.8k Jan 1, 2023
1.8k Jan 1, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

Fancy console logger and wise assistant within your python projects
Fancy console logger and wise assistant within your python projects. Made to save tons of hours for common routines.
 5 Apr 1, 2022
5 Apr 1, 2022
Implementation of paper "DCS-Net: Deep Complex Subtractive Neural Network for Monaural Speech Enhancement"
DCS-Net This is the implementation of "DCS-Net: Deep Complex Subtractive Neural Network for Monaural Speech Enhancement" Steps to run the model Edit V
 10 Apr 4, 2022
10 Apr 4, 2022
End-to-end speech secognition toolkit
End-to-end speech secognition toolkit This is an E2E ASR toolkit modified from Espnet1 (version 0.9.9). This is the official implementation of paper:
 147 Dec 28, 2022
147 Dec 28, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022

Speech Recognition Database Management with python
Speech Recognition Database Management The main aim of this project is to recogn
 2 Feb 2, 2022
2 Feb 2, 2022
Auto_code_complete is a auto word-completetion program which allows you to customize it on your needs
auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the model for this program is one of the deep-learning NLP(Natural Language Process) model structure called 'GRU(gated recurrent unit)'.
 2 Feb 22, 2022
2 Feb 22, 2022

Speech to text streamlit app
Speech to text Streamlit-app! 👄 This speech to text recognition is powered by t
 9 Jan 1, 2023
9 Jan 1, 2023
A general and strong 3D object detection codebase that supports more methods, datasets and tools (debugging, recording and analysis).
ALLINONE-Det ALLINONE-Det is a general and strong 3D object detection codebase built on OpenPCDet, which supports more methods, datasets and tools (de
 5 Nov 3, 2022
5 Nov 3, 2022
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
 431 Jan 7, 2023
431 Jan 7, 2023

Beyond Accuracy: Behavioral Testing of NLP models with CheckList
CheckList This repository contains code for testing NLP Models as described in the following paper: Beyond Accuracy: Behavioral Testing of NLP models
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch
Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch. Topics: Face detection with Detectron 2, Time Series anomaly detection with LSTM Autoencoders, Object Detection with YOLO v5, Build your first Neural Network, Time Series forecasting for Coronavirus daily cases, Sentiment Analysis with BERT.
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
Mycroft Core, the Mycroft Artificial Intelligence platform.
Mycroft Mycroft is a hackable open source voice assistant. Table of Contents Getting Started Running Mycroft Using Mycroft Home Device and Account Man
 6.1k Jan 9, 2023
6.1k Jan 9, 2023
A list of NLP(Natural Language Processing) tutorials
NLP Tutorial A list of NLP(Natural Language Processing) tutorials built on PyTorch. Table of Contents A step-by-step tutorial on how to implement and
 1.3k Dec 25, 2022
1.3k Dec 25, 2022

The official code for the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates".
SpeechDrivesTemplates The official repo for the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates". [arxiv
 53 Dec 23, 2022
53 Dec 23, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022

Graphical Password Authentication System.
Graphical Password Authentication System. This is used to increase the protection/security of a website. Our system is divided into further 4 layers of protection. Each layer is totally different and diverse than the others. This not only increases protection, but also makes sure that no non-human can log in to your account using different activities such as Brute Force Algorithm and so on.
 12 Dec 16, 2022
12 Dec 16, 2022
ConferencingSpeech2022; Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge
ConferencingSpeech 2022 challenge This repository contains the datasets list and scripts required for the ConferencingSpeech 2022 challenge. For more
 21 Dec 2, 2022
21 Dec 2, 2022

Keras implementation of "One pixel attack for fooling deep neural networks" using differential evolution on Cifar10 and ImageNet
One Pixel Attack How simple is it to cause a deep neural network to misclassify an image if an attacker is only allowed to modify the color of one pix
 1.2k Dec 26, 2022
1.2k Dec 26, 2022

Automagically synchronize subtitles with video.
FFsubsync Language-agnostic automatic synchronization of subtitles with video, so that subtitles are aligned to the correct starting point within the
 5.7k Jan 6, 2023
5.7k Jan 6, 2023

Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
 5.3k Dec 30, 2022
5.3k Dec 30, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023

Repository for Project Insight: NLP as a Service
Project Insight NLP as a Service Contents Introduction Features Installation Setup and Documentation Project Details Demonstration Directory Details H
 286 Dec 6, 2022
286 Dec 6, 2022
Simple translation demo showcasing our headliner package.
Headliner Demo This is a demo showcasing our Headliner package. In particular, we trained a simple seq2seq model on an English-German dataset. We didn
 16 Nov 24, 2022
16 Nov 24, 2022

Rhyme with AI
Local development Create a conda virtual environment and activate it: conda env create --file environment.yml conda activate rhyme-with-ai Install the
 28 Nov 21, 2022
28 Nov 21, 2022

Streamlit tool to explore coco datasets
What is this This tool given a COCO annotations file and COCO predictions file will let you explore your dataset, visualize results and calculate impo
 75 Dec 16, 2022
75 Dec 16, 2022
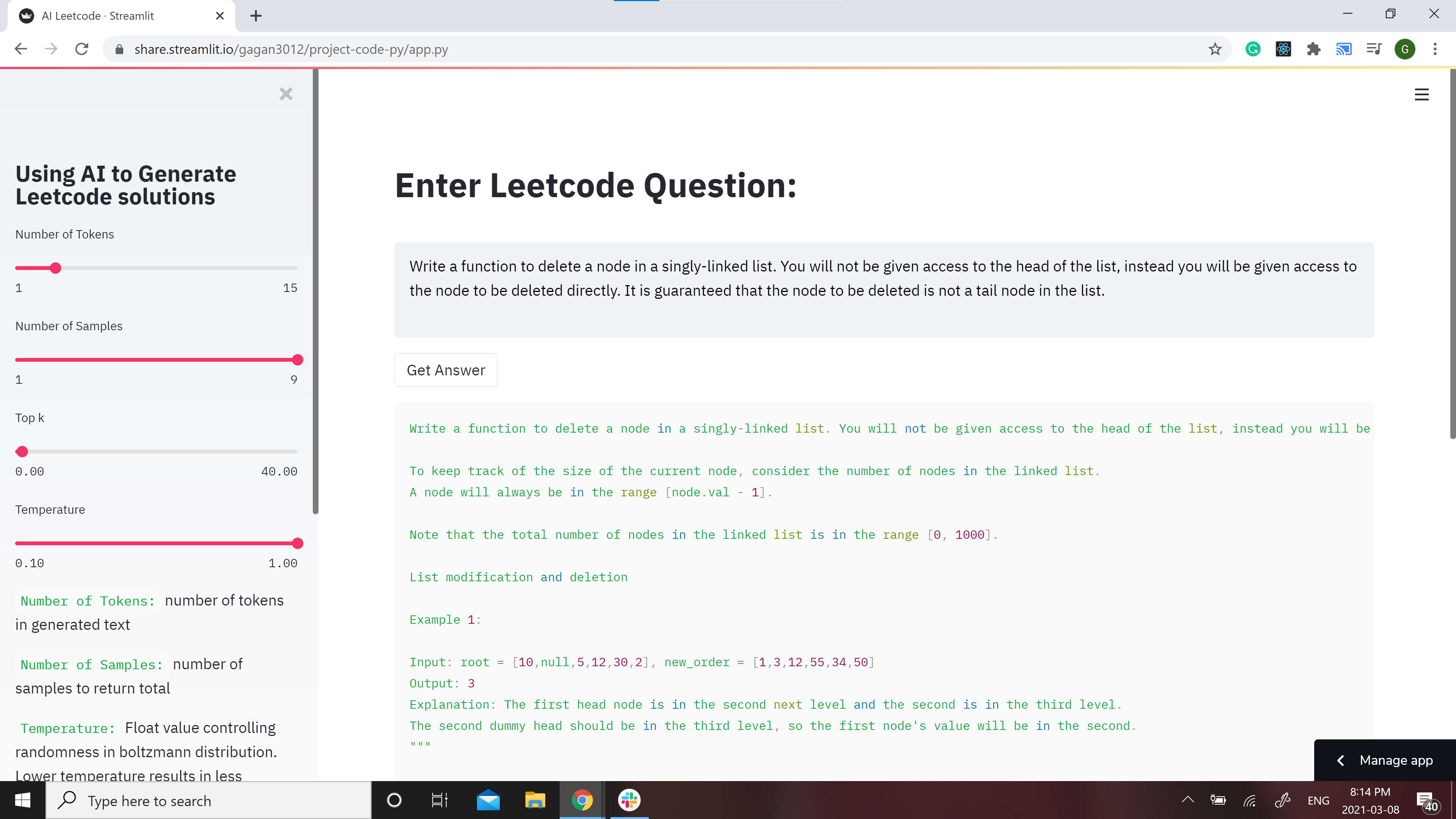
GPT-2 Model for Leetcode Questions in python
Leetcode using AI 🤖 GPT-2 Model for Leetcode Questions in python New demo here: https://huggingface.co/spaces/gagan3012/project-code-py Note: the Ans
 100 Dec 12, 2022
100 Dec 12, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022

Interactive dimensionality reduction for large datasets
BlosSOM 🌼 BlosSOM is a graphical environment for running semi-supervised dimensionality reduction with EmbedSOM. You can use it to explore multidimen
 19 Dec 14, 2022
19 Dec 14, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Using BERT-based models for toxic span detection
SemEval 2021 Task 5: Toxic Spans Detection: Task: Link to SemEval-2021: Task 5 Toxic Span Detection is https://competitions.codalab.org/competitions/2
 1 Jan 4, 2022
1 Jan 4, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023
Asr abc - Automatic speech recognition(ASR),中文语音识别
语音识别的简单示例,主要在课堂演示使用 创建python虚拟环境 在linux 和macos 上验证通过 # 如果已经有pyhon3.6 环境,跳过该步骤,使用
 8 Nov 11, 2022
8 Nov 11, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023

NLP-Project - Used an API to scrape 2000 reddit posts, then used NLP analysis and created a classification model to mixed succcess
Project 3: Web APIs & NLP Problem Statement How do r/Libertarian and r/Neoliberal differ on Biden post-inaguration? The goal of the project is to see
 2 Mar 29, 2022
2 Mar 29, 2022
NLP-SentimentAnalysis - Coursera Course ( Duration : 5 weeks ) offered by DeepLearning.AI
Coursera Natural Language Processing Specialization This repository contains material related to Coursera Natural Language Processing Specialization.
 1 Jun 5, 2022
1 Jun 5, 2022
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it. Study notes and a curated list of awesome resources of such topics.
 1.2k Jan 7, 2023
1.2k Jan 7, 2023

Amazing-Python-Scripts - 🚀 Curated collection of Amazing Python scripts from Basics to Advance with automation task scripts.
📑 Introduction A curated collection of Amazing Python scripts from Basics to Advance with automation task scripts. This is your Personal space to fin
 1.1k Dec 29, 2022
1.1k Dec 29, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

KoBERT - Korean BERT pre-trained cased (KoBERT)
KoBERT KoBERT Korean BERT pre-trained cased (KoBERT) Why'?' Training Environment Requirements How to install How to use Using with PyTorch Using with
 1k Jan 2, 2023
1k Jan 2, 2023
News-Articles-and-Essays - NLP (Topic Modeling and Clustering)
NLP T5 Project proposal Topic Modeling and Clustering of News-Articles-and-Essays Students: Nasser Alshehri Abdullah Bushnag Abdulrhman Alqurashi OVER
 2 Jan 18, 2022
2 Jan 18, 2022
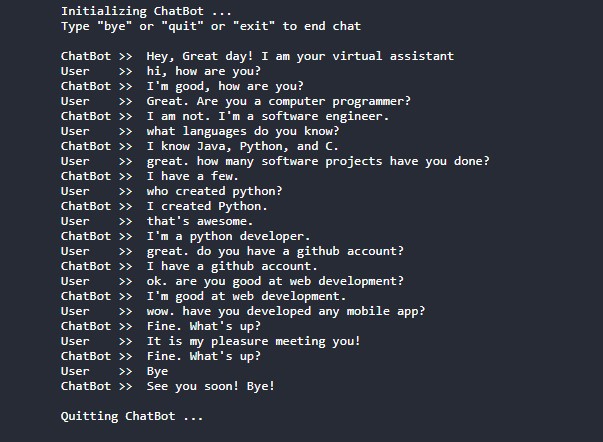
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022
A recommendation system for suggesting new books given similar books.
Book Recommendation System A recommendation system for suggesting new books given similar books. Datasets Dataset Kaggle Dataset Notebooks goodreads-E
 2 Jan 6, 2022
2 Jan 6, 2022

SPT_LSA_ViT - Implementation for Visual Transformer for Small-size Datasets
Vision Transformer for Small-Size Datasets Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song | Paper Inha University Abstract Recently, the Vision
 87 Jan 1, 2023
87 Jan 1, 2023
StyleGAN2-ADA-training-jupyter - Training custom datasets in styleGAN2-ADA by NVIDIA using Jupyter
styleGAN2-ADA-training-jupyter Training custom datasets in styleGAN2-ADA on Jupyter Official StyleGAN2-ADA by NIVIDIA Paper Training Generative Advers
 2 Feb 24, 2022
2 Feb 24, 2022

Search-Engine - 📖 AI based search engine
Search Engine AI based search engine that was trained on 25000 samples, feel free to train on up to 1.2M sample from kaggle dataset, link below StackS
 2 Nov 29, 2022
2 Nov 29, 2022

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
 335 Jan 4, 2023
335 Jan 4, 2023

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022

Natural Language Processing for Adverse Drug Reaction (ADR) Detection
Natural Language Processing for Adverse Drug Reaction (ADR) Detection This repo contains code from a project to identify ADRs in discharge summaries a
 21 Aug 5, 2022
21 Aug 5, 2022

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022
Datasets for new state-of-the-art challenge in disentanglement learning
High resolution disentanglement datasets This repository contains the Falcor3D and Isaac3D datasets, which present a state-of-the-art challenge for co
 37 May 26, 2022
37 May 26, 2022
Ecco is a python library for exploring and explaining Natural Language Processing models using interactive visualizations.
Visualize, analyze, and explore NLP language models. Ecco creates interactive visualizations directly in Jupyter notebooks explaining the behavior of Transformer-based language models (like GPT2, BERT, RoBERTA, T5, and T0).
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
基于百度的语音识别,用python实现,pyaudio+pyqt
Speech-recognition 基于百度的语音识别,python3.8(conda)+pyaudio+pyqt+baidu-aip 百度有面向python
 1 Jan 3, 2022
1 Jan 3, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
Quickly download, clean up, and install public datasets into a database management system
Finding data is one thing. Getting it ready for analysis is another. Acquiring, cleaning, standardizing and importing publicly available data is time
 274 Jan 4, 2023
274 Jan 4, 2023
Python library for parsing resumes using natural language processing and machine learning
CVParser Python library for parsing resumes using natural language processing and machine learning. Setup Installation on Linux and Mac OS Follow the
 0 Jul 29, 2021
0 Jul 29, 2021

NLP project that works with news (NER, context generation, news trend analytics)
СоАвтор СоАвтор – платформа и открытый набор инструментов для редакций и журналистов-фрилансеров, который призван сделать процесс создания контента ма
 38 Jan 4, 2023
38 Jan 4, 2023
Python script that analyses the given datasets and comes up with the best polynomial regression representation with the smallest polynomial degree possible
Python script that analyses the given datasets and comes up with the best polynomial regression representation with the smallest polynomial degree possible, to be the most reliable with the least complexity possible
 2 Aug 1, 2022
2 Aug 1, 2022
A NASA MEaSUREs project to provide automated, low latency, global glacier flow and elevation change datasets
Notebooks A NASA MEaSUREs project to provide automated, low latency, global glacier flow and elevation change datasets This repository provides tools
 27 Oct 25, 2022
27 Oct 25, 2022

For storing the complete exploration of Visual Question Answering for our B.Tech Project
Multi-Image vqa @authors: Akhilesh, Janhavi, Harsh Paper summary, Ideas tried and their corresponding results: on wiki Other discussions: on discussio
 3 Jun 16, 2022
3 Jun 16, 2022
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022

Code to generate datasets used in "How Useful is Self-Supervised Pretraining for Visual Tasks?"
Synthetic dataset rendering Framework for producing the synthetic datasets used in: How Useful is Self-Supervised Pretraining for Visual Tasks? Alejan
 21 Apr 29, 2022
21 Apr 29, 2022
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
 2 Oct 22, 2022
2 Oct 22, 2022

Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
 689 Dec 25, 2022
689 Dec 25, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

🚀Clone a voice in 5 seconds to generate arbitrary speech in real-time
English | 中文 Features 🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc. ?
 25.6k Dec 31, 2022
25.6k Dec 31, 2022
txtai: Build AI-powered semantic search applications in Go
txtai: Build AI-powered semantic search applications in Go txtai executes machine-learning workflows to transform data and build AI-powered semantic s
 49 Dec 6, 2022
49 Dec 6, 2022
Fast, DB Backed pretrained word embeddings for natural language processing.
Embeddings Embeddings is a python package that provides pretrained word embeddings for natural language processing and machine learning. Instead of lo
 212 Nov 21, 2022
212 Nov 21, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger In this project, our aim is to tune, compare, and contrast the perf
 0 Dec 25, 2021
0 Dec 25, 2021
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022
An automated program that helps customers of Pizza Palour place their pizza orders
PIzza_Order_Assistant Introduction An automated program that helps customers of Pizza Palour place their pizza orders. The program uses voice commands
 1 Dec 26, 2021
1 Dec 26, 2021
jiant is an NLP toolkit
🚨 Update 🚨 : As of 2021/10/17, the jiant project is no longer being actively maintained. This means there will be no plans to add new models, tasks,
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
A modified Sequential and NLP based Bot
A modified Sequential and NLP based Bot I improvised this bot a bit with some implementations as a part of my own hobby project :) Note: I do not own
 2 Jan 7, 2022
2 Jan 7, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
Datasets with Softcatalà website content
softcatala-web-dataset This repository contains Sofcatalà web site content (articles and programs descriptions). Dataset are available in the dataset
 2 Dec 26, 2021
2 Dec 26, 2021
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
 76 Nov 30, 2022
76 Nov 30, 2022
LynxKite: a complete graph data science platform for very large graphs and other datasets.
LynxKite is a complete graph data science platform for very large graphs and other datasets. It seamlessly combines the benefits of a friendly graphical interface and a powerful Python API.
 124 Dec 14, 2022
124 Dec 14, 2022
A Python library that simplifies the extraction of datasets from XML content.
xmldataset: simple xml parsing 🗃️ XML Dataset: simple xml parsing Documentation: https://xmldataset.readthedocs.io A Python library that simplifies t
 75 Dec 30, 2022
75 Dec 30, 2022

Prososdy Morph: A python library for manipulating pitch and duration in an algorithmic way, for resynthesizing speech.
ProMo (Prosody Morph) Questions? Comments? Feedback? Chat with us on gitter! A library for manipulating pitch and duration in an algorithmic way, for
 71 Jan 2, 2023
71 Jan 2, 2023

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021