662 Repositories
Python stability-training Libraries
A library for preparing, training, and evaluating scalable deep learning hybrid recommender systems using PyTorch.
collie Collie is a library for preparing, training, and evaluating implicit deep learning hybrid recommender systems, named after the Border Collie do
 96 Dec 29, 2022
96 Dec 29, 2022

QuakeLabeler is a Python package to create and manage your seismic training data, processes, and visualization in a single place — so you can focus on building the next big thing.
QuakeLabeler Quake Labeler was born from the need for seismologists and developers who are not AI specialists to easily, quickly, and independently bu
 15 Nov 4, 2022
15 Nov 4, 2022

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023

Implements the training, testing and editing tools for "Pluralistic Image Completion"
Pluralistic Image Completion ArXiv | Project Page | Online Demo | Video(demo) This repository implements the training, testing and editing tools for "
 615 Dec 8, 2022
615 Dec 8, 2022
A Deep Learning based project for creating line art portraits.
ArtLine The main aim of the project is to create amazing line art portraits. Sounds Intresting,let's get to the pictures!! Model-(Smooth) Model-(Quali
 3.3k Jan 7, 2023
3.3k Jan 7, 2023
PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more
PyTorch Image Models Sponsors What's New Introduction Models Features Results Getting Started (Documentation) Train, Validation, Inference Scripts Awe
 22.9k Jan 9, 2023
22.9k Jan 9, 2023
Synthetic structured data generators
Join us on What is Synthetic Data? Synthetic data is artificially generated data that is not collected from real world events. It replicates the stati
 850 Jan 7, 2023
850 Jan 7, 2023
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

PaSST: Efficient Training of Audio Transformers with Patchout
PaSST: Efficient Training of Audio Transformers with Patchout This is the implementation for Efficient Training of Audio Transformers with Patchout Pa
 165 Dec 26, 2022
165 Dec 26, 2022
Scalable training for dense retrieval models.
Scalable implementation of dense retrieval. Training on cluster By default it trains locally: PYTHONPATH=.:$PYTHONPATH python dpr_scale/main.py traine
 90 Dec 28, 2022
90 Dec 28, 2022
NVIDIA Merlin is an open source library providing end-to-end GPU-accelerated recommender systems, from feature engineering and preprocessing to training deep learning models and running inference in production.
NVIDIA Merlin NVIDIA Merlin is an open source library designed to accelerate recommender systems on NVIDIA’s GPUs. It enables data scientists, machine
 419 Jan 3, 2023
419 Jan 3, 2023
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022
MG-GCN: Scalable Multi-GPU GCN Training Framework
MG-GCN MG-GCN: multi-GPU GCN training framework. For more information, please read our paper. After cloning our repository, run git submodule update -
 6 Oct 24, 2022
6 Oct 24, 2022
Demystifying How Self-Supervised Features Improve Training from Noisy Labels
Demystifying How Self-Supervised Features Improve Training from Noisy Labels This code is a PyTorch implementation of the paper "[Demystifying How Sel
 4 Oct 14, 2022
4 Oct 14, 2022

Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
 123 Dec 23, 2022
123 Dec 23, 2022
Codes for CIKM'21 paper 'Self-Supervised Graph Co-Training for Session-based Recommendation'.
COTREC Codes for CIKM'21 paper 'Self-Supervised Graph Co-Training for Session-based Recommendation'. Requirements: Python 3.7, Pytorch 1.6.0 Best Hype
 43 Jan 4, 2023
43 Jan 4, 2023

Designing a Practical Degradation Model for Deep Blind Image Super-Resolution (ICCV, 2021) (PyTorch) - We released the training code!
Designing a Practical Degradation Model for Deep Blind Image Super-Resolution Kai Zhang, Jingyun Liang, Luc Van Gool, Radu Timofte Computer Vision Lab
 804 Jan 8, 2023
804 Jan 8, 2023
Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training".
Mixup-Data-Dependency Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training". Running Alternating Line Exp
 0 Nov 11, 2021
0 Nov 11, 2021
This library contains a Tensorflow implementation of the paper Stability Analysis of Unfolded WMMSE for Power Allocation
UWMMSE-stability Tensorflow implementation of Stability Analysis of UWMMSE Overview This library contains a Tensorflow implementation of the paper Sta
 1 Nov 16, 2022
1 Nov 16, 2022
Anomaly detection in multi-agent trajectories: Code for training, evaluation and the OpenAI highway simulation.
Anomaly Detection in Multi-Agent Trajectories for Automated Driving This is the official project page including the paper, code, simulation, baseline
 12 Dec 2, 2022
12 Dec 2, 2022

collect training and calibration data for gaze tracking
Collect Training and Calibration Data for Gaze Tracking This tool allows collecting gaze data necessary for personal calibration or training of eye-tr
 5 Dec 17, 2022
5 Dec 17, 2022
Code for SALT: Stackelberg Adversarial Regularization, EMNLP 2021.
SALT: Stackelberg Adversarial Regularization Code for Adversarial Regularization as Stackelberg Game: An Unrolled Optimization Approach, EMNLP 2021. R
 10 Jan 10, 2022
10 Jan 10, 2022
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
124 Jan 3, 2023

Propose a principled and practically effective framework for unsupervised accuracy estimation and error detection tasks with theoretical analysis and state-of-the-art performance.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles This project is for the paper: Detecting Errors and Estimating
 13 Nov 21, 2022
13 Nov 21, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-quality pre-trained models from torchvision, MMLabs, and soon Pytorch Image Models. It orchestrates the end-to-end deep learning workflow allowing to train networks with easy-to-use robust high-performance libraries such as Pytorch-Lightning and Fastai
 789 Dec 29, 2022
789 Dec 29, 2022
Composing methods for ML training efficiency
MosaicML Composer contains a library of methods, and ways to compose them together for more efficient ML training.
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
This is a library for training and applying sparse fine-tunings with torch and transformers.
This is a library for training and applying sparse fine-tunings with torch and transformers. Please refer to our paper Composable Sparse Fine-Tuning f
 37 Dec 30, 2022
37 Dec 30, 2022

ECCV18 Workshops - Enhanced SRGAN. Champion PIRM Challenge on Perceptual Super-Resolution. The training codes are in BasicSR.
ESRGAN (Enhanced SRGAN) [ 🚀 BasicSR] [Real-ESRGAN] ✨ New Updates. We have extended ESRGAN to Real-ESRGAN, which is a more practical algorithm for rea
 4.7k Jan 2, 2023
4.7k Jan 2, 2023
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks This repository contains a TensorFlow implementation of "
 5 Jan 8, 2023
5 Jan 8, 2023

PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training”
A new codebase for popular Scene Graph Generation methods (2020). Visualization & Scene Graph Extraction on custom images/datasets are provided. It's also a PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training CVPR 2020”
 824 Jan 3, 2023
824 Jan 3, 2023
Code for reproducing experiments in "Improved Training of Wasserstein GANs"
Improved Training of Wasserstein GANs Code for reproducing experiments in "Improved Training of Wasserstein GANs". Prerequisites Python, NumPy, Tensor
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
DeCLIP Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. Our paper is available in arxiv Updates ** Ou
 470 Dec 30, 2022
470 Dec 30, 2022
Self-Supervised Speech Pre-training and Representation Learning Toolkit.
What's New Sep 2021: We host a challenge in AAAI workshop: The 2nd Self-supervised Learning for Audio and Speech Processing! See SUPERB official site
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
Codebase of deep learning models for inferring stability of mRNA molecules
Kaggle OpenVaccine Models Codebase of deep learning models for inferring stability of mRNA molecules, corresponding to the Kaggle Open Vaccine Challen
 40 Dec 29, 2022
40 Dec 29, 2022
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Explaining in Style: Official TensorFlow Colab Explaining in Style: Training a GAN to explain a classifier in StyleSpace Oran Lang, Yossi Gandelsman,
 197 Nov 8, 2022
197 Nov 8, 2022
MosaicML Composer contains a library of methods, and ways to compose them together for more efficient ML training
MosaicML Composer MosaicML Composer contains a library of methods, and ways to compose them together for more efficient ML training. We aim to ease th
2.8k Jan 6, 2023
Calibrate your listeners! Robust communication-based training for pragmatic speakers. Findings of EMNLP 2021.
Calibrate your listeners! Robust communication-based training for pragmatic speakers Rose E. Wang, Julia White, Jesse Mu, Noah D. Goodman Findings of
 3 Apr 2, 2022
3 Apr 2, 2022

Code for the paper Relation Prediction as an Auxiliary Training Objective for Improving Multi-Relational Graph Representations (AKBC 2021).
Relation Prediction as an Auxiliary Training Objective for Knowledge Base Completion This repo provides the code for the paper Relation Prediction as
85 Jan 2, 2023
Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
 282 Jan 9, 2023
282 Jan 9, 2023
Pre-training BERT masked language models with custom vocabulary
Pre-training BERT Masked Language Models (MLM) This repository contains the method to pre-train a BERT model using custom vocabulary. It was used to p
 14 Nov 2, 2022
14 Nov 2, 2022
Unofficial PyTorch implementation of DeepMind's Perceiver IO with PyTorch Lightning scripts for distributed training
Unofficial PyTorch implementation of DeepMind's Perceiver IO with PyTorch Lightning scripts for distributed training
 251 Dec 25, 2022
251 Dec 25, 2022
ICLR 2021: Pre-Training for Context Representation in Conversational Semantic Parsing
SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing This repository contains code for the ICLR 2021 paper "SCoRE: Pre-Tr
28 Oct 2, 2022
Training vision models with full-batch gradient descent and regularization
Stochastic Training is Not Necessary for Generalization -- Training competitive vision models without stochasticity This repository implements trainin
 32 Jan 6, 2023
32 Jan 6, 2023
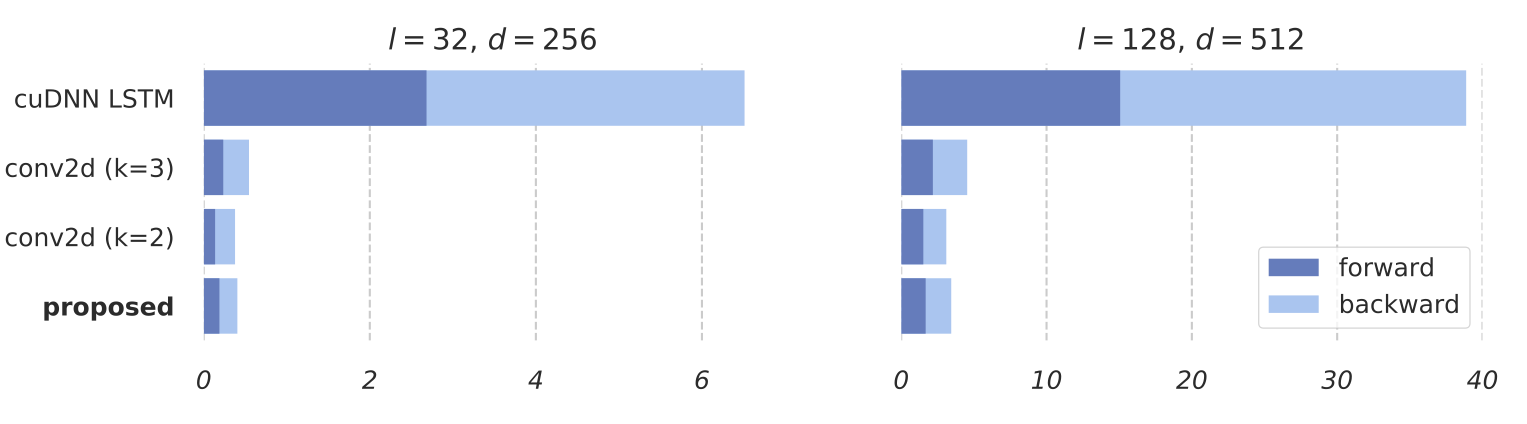
Training RNNs as Fast as CNNs
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023

A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You can find two approaches for achieving this in this repo.
multitask-learning-transformers A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You
 48 Jan 2, 2023
48 Jan 2, 2023

🧬 Training the car to do self-parking using a genetic algorithm
🧬 Training the car to do self-parking using a genetic algorithm
 652 Jan 3, 2023
652 Jan 3, 2023
Model factory is a ML training platform to help engineers to build ML models at scale
Model Factory Machine learning today is powering many businesses today, e.g., search engine, e-commerce, news or feed recommendation. Training high qu
 16 Sep 23, 2022
16 Sep 23, 2022
🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
3.1k Jan 2, 2023
Training Confidence-Calibrated Classifier for Detecting Out-of-Distribution Samples / ICLR 2018
Training Confidence-Calibrated Classifier for Detecting Out-of-Distribution Samples This project is for the paper "Training Confidence-Calibrated Clas
 168 Nov 29, 2022
168 Nov 29, 2022

NEATEST: Evolving Neural Networks Through Augmenting Topologies with Evolution Strategy Training
NEATEST: Evolving Neural Networks Through Augmenting Topologies with Evolution Strategy Training
 16 Dec 5, 2022
16 Dec 5, 2022

RobustART: Benchmarking Robustness on Architecture Design and Training Techniques
The first comprehensive Robustness investigation benchmark on large-scale dataset ImageNet regarding ARchitecture design and Training techniques towards diverse noises.
 132 Dec 23, 2022
132 Dec 23, 2022

Reimplement of SimSwap training code
SimSwap-train Reimplement of SimSwap training code Instructions 1.Environment Preparation (1)Refer to the README document of SIMSWAP to configure the
 111 Dec 31, 2022
111 Dec 31, 2022
![A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]](https://user-images.githubusercontent.com/33194443/104581604-2592cb00-56a2-11eb-9610-5eaa0afb6e1f.png)
A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]
PINTO_model_zoo Please read the contents of the LICENSE file located directly under each folder before using the model. My model conversion scripts ar
 2.4k Jan 5, 2023
2.4k Jan 5, 2023
ConvNet training using pytorch
Convolutional networks using PyTorch This is a complete training example for Deep Convolutional Networks on various datasets (ImageNet, Cifar10, Cifar
 336 Dec 30, 2022
336 Dec 30, 2022

PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.)
pytorch-fcn PyTorch implementation of Fully Convolutional Networks. Requirements pytorch = 0.2.0 torchvision = 0.1.8 fcn = 6.1.5 Pillow scipy tqdm
 1.6k Jan 4, 2023
1.6k Jan 4, 2023

Scripts for training an AI to play the endless runner Subway Surfers using a supervised machine learning approach by imitation and a convolutional neural network (CNN) for image classification
About subwAI subwAI - a project for training an AI to play the endless runner Subway Surfers using a supervised machine learning approach by imitation
 82 Jan 1, 2023
82 Jan 1, 2023

Code for paper "Which Training Methods for GANs do actually Converge? (ICML 2018)"
GAN stability This repository contains the experiments in the supplementary material for the paper Which Training Methods for GANs do actually Converg
 885 Jan 1, 2023
885 Jan 1, 2023
Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models.
Tevatron Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models. The toolkit has a modularized
 193 Jan 4, 2023
193 Jan 4, 2023
PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.)
pytorch-fcn PyTorch implementation of Fully Convolutional Networks. Requirements pytorch = 0.2.0 torchvision = 0.1.8 fcn = 6.1.5 Pillow scipy tqdm
1.6k Jan 7, 2023

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
A2T: Towards Improving Adversarial Training of NLP Models (EMNLP 2021 Findings)
A2T: Towards Improving Adversarial Training of NLP Models This is the source code for the EMNLP 2021 (Findings) paper "Towards Improving Adversarial T
17 Oct 15, 2022
A machine learning library for spiking neural networks. Supports training with both torch and jax pipelines, and deployment to neuromorphic hardware.
Rockpool Rockpool is a Python package for developing signal processing applications with spiking neural networks. Rockpool allows you to build network
 21 Dec 14, 2022
21 Dec 14, 2022

Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
2k Dec 31, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
67 Dec 1, 2022

The training code for the 4th place model at MDX 2021 leaderboard A.
The training code for the 4th place model at MDX 2021 leaderboard A.
 32 Dec 18, 2022
32 Dec 18, 2022
FireFlyer Record file format, writer and reader for DL training samples.
FFRecord The FFRecord format is a simple format for storing a sequence of binary records developed by HFAiLab, which supports random access and Linux
 77 Jan 4, 2023
77 Jan 4, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
 323 Jan 1, 2023
323 Jan 1, 2023
[EMNLP 2021] Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
RoSTER The source code used for Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training, p
 60 Dec 30, 2022
60 Dec 30, 2022
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Real-ESRGAN Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data Ported from https://github.com/xinntao/Real-ESRGAN Depend
 44 Dec 27, 2022
44 Dec 27, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023
Galileo library for large scale graph training by JD
近年来,图计算在搜索、推荐和风控等场景中获得显著的效果,但也面临超大规模异构图训练,与现有的深度学习框架Tensorflow和PyTorch结合等难题。 Galileo(伽利略)是一个图深度学习框架,具备超大规模、易使用、易扩展、高性能、双后端等优点,旨在解决超大规模图算法在工业级场景的落地难题,提
 128 Nov 29, 2022
128 Nov 29, 2022
Optimized code based on M2 for faster image captioning training
Transformer Captioning This repository contains the code for Transformer-based image captioning. Based on meshed-memory-transformer, we further optimi
 16 Dec 16, 2022
16 Dec 16, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023

Demonstration of the Model Training as a CI/CD System in Vertex AI
Model Training as a CI/CD System This project demonstrates the machine model training as a CI/CD system in GCP platform. You will see more detailed wo
 19 Dec 28, 2022
19 Dec 28, 2022
Codes for CIKM'21 paper 'Self-Supervised Graph Co-Training for Session-based Recommendation'.
COTREC Codes for CIKM'21 paper 'Self-Supervised Graph Co-Training for Session-based Recommendation'. Requirements: Python 3.7, Pytorch 1.6.0 Best Hype
42 Dec 9, 2022
TAPEX: Table Pre-training via Learning a Neural SQL Executor
TAPEX: Table Pre-training via Learning a Neural SQL Executor The official repository which contains the code and pre-trained models for our paper TAPE
157 Dec 28, 2022

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022

A pytorch implementation of Paper "Improved Training of Wasserstein GANs"
WGAN-GP An pytorch implementation of Paper "Improved Training of Wasserstein GANs". Prerequisites Python, NumPy, SciPy, Matplotlib A recent NVIDIA GPU
 1.4k Dec 14, 2022
1.4k Dec 14, 2022
Code used to generate the results appearing in "Train longer, generalize better: closing the generalization gap in large batch training of neural networks"
Train longer, generalize better - Big batch training This is a code repository used to generate the results appearing in "Train longer, generalize bet
145 Sep 16, 2022
Accelerate Neural Net Training by Progressively Freezing Layers
FreezeOut A simple technique to accelerate neural net training by progressively freezing layers. This repository contains code for the extended abstra
 203 Jun 19, 2022
203 Jun 19, 2022

Pytorch implementation of "Forward Thinking: Building and Training Neural Networks One Layer at a Time"
forward-thinking-pytorch Pytorch implementation of Forward Thinking: Building and Training Neural Networks One Layer at a Time Requirements Python 2.7
 65 Oct 6, 2022
65 Oct 6, 2022

Unofficial Alias-Free GAN implementation. Based on rosinality's version with expanded training and inference options.
Alias-Free GAN An unofficial version of Alias-Free Generative Adversarial Networks (https://arxiv.org/abs/2106.12423). This repository was heavily bas
 75 Dec 12, 2022
75 Dec 12, 2022
![[Preprint]](https://github.com/VITA-Group/Deep_GCN_Benchmarking/raw/main/figs/combo.png)
[Preprint] "Bag of Tricks for Training Deeper Graph Neural Networks A Comprehensive Benchmark Study" by Tianlong Chen*, Kaixiong Zhou*, Keyu Duan, Wenqing Zheng, Peihao Wang, Xia Hu, Zhangyang Wang
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study Codes for [Preprint] Bag of Tricks for Training Deeper Graph
 101 Dec 29, 2022
101 Dec 29, 2022
Experiments on Flood Segmentation on Sentinel-1 SAR Imagery with Cyclical Pseudo Labeling and Noisy Student Training
Flood Detection Challenge This repository contains code for our submission to the ETCI 2021 Competition on Flood Detection (Winning Solution #2). Acco
 108 Dec 28, 2022
108 Dec 28, 2022
ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
ST++ This is the official PyTorch implementation of our paper: ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation. Lihe Ya
 147 Jan 3, 2023
147 Jan 3, 2023
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
42 Dec 9, 2022

PyTorch DepthNet Training on Still Box dataset
DepthNet training on Still Box Project page This code can replicate the results of our paper that was published in UAVg-17. If you use this repo in yo
 115 Nov 21, 2022
115 Nov 21, 2022

Official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.
 281 Dec 30, 2022
281 Dec 30, 2022

Dynamic Divide-and-Conquer Adversarial Training for Robust Semantic Segmentation (ICCV2021)
Dynamic Divide-and-Conquer Adversarial Training for Robust Semantic Segmentation This is a pytorch project for the paper Dynamic Divide-and-Conquer Ad
 29 Nov 21, 2022
29 Nov 21, 2022
Unofficial pytorch implementation for Self-critical Sequence Training for Image Captioning. and others.
An Image Captioning codebase This is a codebase for image captioning research. It supports: Self critical training from Self-critical Sequence Trainin
 906 Jan 3, 2023
906 Jan 3, 2023

IAST: Instance Adaptive Self-training for Unsupervised Domain Adaptation (ECCV 2020)
This repo is the official implementation of our paper "Instance Adaptive Self-training for Unsupervised Domain Adaptation". The purpose of this repo is to better communicate with you and respond to your questions. This repo is almost the same with Another-Version, and you can also refer to that version.
 84 Dec 12, 2022
84 Dec 12, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training.
Updates (2020/06/21) Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training. Pyr
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023