50 Repositories
Python tpu-acceleration Libraries
Sionna: An Open-Source Library for Next-Generation Physical Layer Research
Sionna: An Open-Source Library for Next-Generation Physical Layer Research Sionna™ is an open-source Python library for link-level simulations of digi
 313 Dec 22, 2022
313 Dec 22, 2022

Use the state-of-the-art m2m100 to translate large data on CPU/GPU/TPU. Super Easy!
Easy-Translate is a script for translating large text files in your machine using the M2M100 models from Facebook/Meta AI. We also privide a script fo
 41 Dec 15, 2022
41 Dec 15, 2022
GenGNN: A Generic FPGA Framework for Graph Neural Network Acceleration
GenGNN: A Generic FPGA Framework for Graph Neural Network Acceleration Stefan Abi-Karam*, Yuqi He*, Rishov Sarkar*, Lakshmi Sathidevi, Zihang Qiao, Co
 19 Dec 15, 2022
19 Dec 15, 2022

Orchestrating Distributed Materials Acceleration Platform Tutorial
Orchestrating Distributed Materials Acceleration Platform Tutorial This tutorial for orchestrating distributed materials acceleration platform was pre
 1 Jan 25, 2022
1 Jan 25, 2022
PyTorch implementation of federated learning framework based on the acceleration of global momentum
Federated Learning with Acceleration of Global Momentum PyTorch implementation of federated learning framework based on the acceleration of global mom
 0 Dec 23, 2021
0 Dec 23, 2021
Collection of machine learning related notebooks to share.
ML_Notebooks Collection of machine learning related notebooks to share. Notebooks GAN_distributed_training.ipynb In this Notebook, TensorFlow's tutori
 14 Dec 22, 2022
14 Dec 22, 2022
Reference models and tools for Cloud TPUs.
Cloud TPUs This repository is a collection of reference models and tools used with Cloud TPUs. The fastest way to get started training a model on a Cl
 5k Jan 5, 2023
5k Jan 5, 2023
The full training script for Enformer (Tensorflow Sonnet) on TPU clusters
Enformer TPU training script (wip) The full training script for Enformer (Tensorflow Sonnet) on TPU clusters, in an effort to migrate the model to pyt
 10 Oct 19, 2022
10 Oct 19, 2022

EfficientNetV2-with-TPU - Cifar-10 case study
EfficientNetV2-with-TPU EfficientNet EfficientNetV2 adalah jenis jaringan saraf convolutional yang memiliki kecepatan pelatihan lebih cepat dan efisie
 1 Dec 28, 2021
1 Dec 28, 2021
A minimal TPU compatible Jax implementation of NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF Minimal Jax implementation of NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. Result of Tiny-NeRF RGB Depth
 11 Jul 24, 2022
11 Jul 24, 2022
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
ONNX Runtime is a cross-platform inference and training machine-learning accelerator. ONNX Runtime inference can enable faster customer experiences an
 8k Jan 4, 2023
8k Jan 4, 2023
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
12.9k Jan 7, 2023

Efficient and Scalable Physics-Informed Deep Learning and Scientific Machine Learning on top of Tensorflow for multi-worker distributed computing
Notice: Support for Python 3.6 will be dropped in v.0.2.1, please plan accordingly! Efficient and Scalable Physics-Informed Deep Learning Collocation-
 74 Dec 9, 2022
74 Dec 9, 2022
A python package simulating the quasi-2D pseudospin-1/2 Gross-Pitaevskii equation with NVIDIA GPU acceleration.
A python package simulating the quasi-2D pseudospin-1/2 Gross-Pitaevskii equation with NVIDIA GPU acceleration. Introduction spinor-gpe is high-level,
 2 Sep 20, 2022
2 Sep 20, 2022

A C-like hardware description language (HDL) adding high level synthesis(HLS)-like automatic pipelining as a language construct/compiler feature.
██████╗ ██╗██████╗ ███████╗██╗ ██╗███╗ ██╗███████╗ ██████╗ ██╔══██╗██║██╔══██╗██╔════╝██║ ██║████╗ ██║██╔════╝██╔════╝ ██████╔╝██║██████╔╝█
 391 Jan 1, 2023
391 Jan 1, 2023
A library for researching neural networks compression and acceleration methods.
A library for researching neural networks compression and acceleration methods.
 100 Dec 29, 2022
100 Dec 29, 2022

Class-Balanced Loss Based on Effective Number of Samples. CVPR 2019
Class-Balanced Loss Based on Effective Number of Samples Tensorflow code for the paper: Class-Balanced Loss Based on Effective Number of Samples Yin C
 546 Jan 8, 2023
546 Jan 8, 2023
SAMO: Streaming Architecture Mapping Optimisation
SAMO: Streaming Architecture Mapping Optimiser The SAMO framework provides a method of optimising the mapping of a Convolutional Neural Network model
 20 Dec 10, 2022
20 Dec 10, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022
⚡️Optimizing einsum functions in NumPy, Tensorflow, Dask, and more with contraction order optimization.
Optimized Einsum Optimized Einsum: A tensor contraction order optimizer Optimized einsum can significantly reduce the overall execution time of einsum
 653 Dec 30, 2022
653 Dec 30, 2022

GNNAdvisor: An Efficient Runtime System for GNN Acceleration on GPUs
GNNAdvisor: An Efficient Runtime System for GNN Acceleration on GPUs [Paper, Slides, Video Talk] at USENIX OSDI'21 @inproceedings{GNNAdvisor, title=
 47 Jan 3, 2023
47 Jan 3, 2023
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet buil
3.4k Jan 7, 2023

Calculates JMA (Japan Meteorological Agency) seismic intensity (shindo) scale from acceleration data recorded in NumPy array
shindo.py Calculates JMA (Japan Meteorological Agency) seismic intensity (shindo) scale from acceleration data stored in NumPy array Introduction Japa
 3 Sep 23, 2022
3 Sep 23, 2022
Anderson Acceleration for Deep Learning
Anderson Accelerated Deep Learning (AADL) AADL is a Python package that implements the Anderson acceleration to speed-up the training of deep learning
 7 Nov 24, 2022
7 Nov 24, 2022
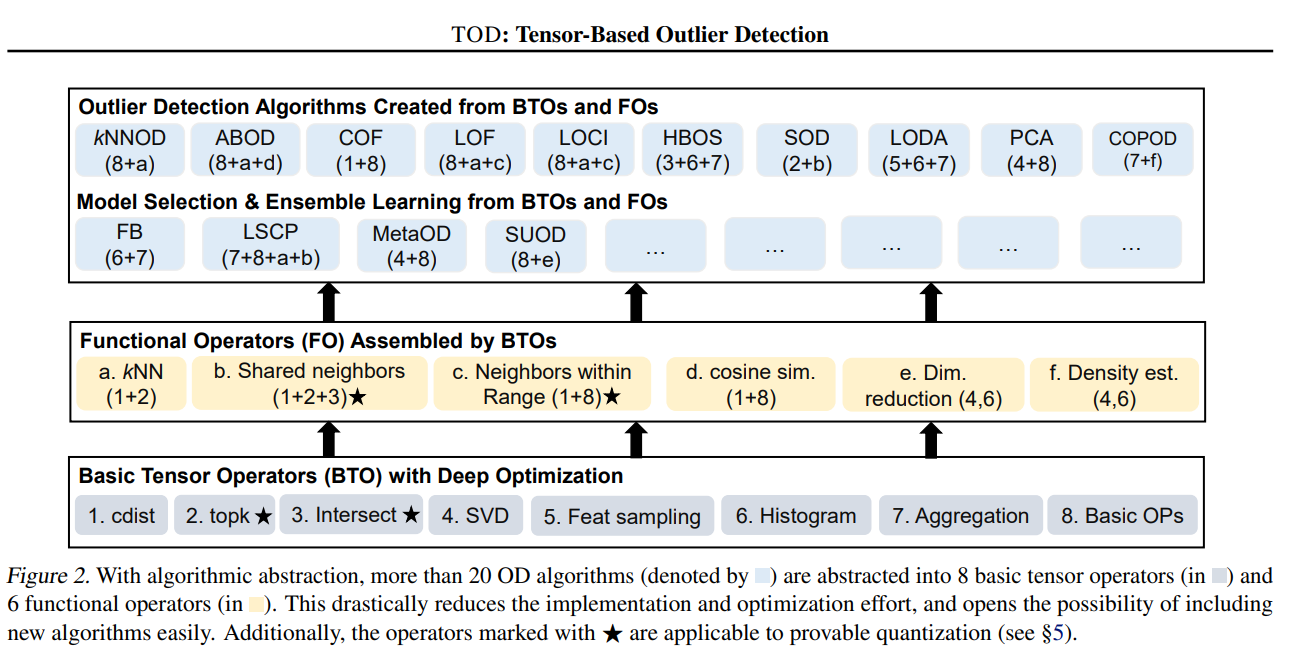
(Py)TOD: Tensor-based Outlier Detection, A General GPU-Accelerated Framework
(Py)TOD: Tensor-based Outlier Detection, A General GPU-Accelerated Framework Background: Outlier detection (OD) is a key data mining task for identify
 127 Jan 5, 2023
127 Jan 5, 2023

Joint Channel and Weight Pruning for Model Acceleration on Mobile Devices
Joint Channel and Weight Pruning for Model Acceleration on Mobile Devices Abstract For practical deep neural network design on mobile devices, it is e
 11 Dec 30, 2022
11 Dec 30, 2022
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
12.9k Jan 9, 2023
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
 1k Jan 3, 2023
1k Jan 3, 2023
Tutorial to pretrain & fine-tune a 🤗 Flax T5 model on a TPUv3-8 with GCP
Pretrain and Fine-tune a T5 model with Flax on GCP This tutorial details how pretrain and fine-tune a FlaxT5 model from HuggingFace using a TPU VM ava
 41 Nov 18, 2022
41 Nov 18, 2022
Refactoring dalle-pytorch and taming-transformers for TPU VM
Text-to-Image Translation (DALL-E) for TPU in Pytorch Refactoring Taming Transformers and DALLE-pytorch for TPU VM with Pytorch Lightning Requirements
 61 Nov 7, 2022
61 Nov 7, 2022
TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A good teacher is patient and consistent by Beyer et al.
FunMatch-Distillation TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A g
 67 Dec 20, 2022
67 Dec 20, 2022
Neural Fixed-Point Acceleration for Convex Optimization
Licensing The majority of neural-scs is licensed under the CC BY-NC 4.0 License, however, portions of the project are available under separate license
 27 Oct 6, 2022
27 Oct 6, 2022
Convert Python 3 code to CUDA code.
Py2CUDA Convert python code to CUDA. Usage To convert a python file say named py_file.py to CUDA, run python generate_cuda.py --file py_file.py --arch
 3 Jul 14, 2021
3 Jul 14, 2021

This is the unofficial code of Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes. which achieve state-of-the-art trade-off between accuracy and speed on cityscapes and camvid, without using inference acceleration and extra data
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes Introduction This is the unofficial code of Deep Dual-re
 113 Dec 23, 2022
113 Dec 23, 2022
DI-HPC is an acceleration operator component for general algorithm modules in reinforcement learning algorithms
DI-HPC: Decision Intelligence - High Performance Computation DI-HPC is an acceleration operator component for general algorithm modules in reinforceme
 185 Dec 29, 2022
185 Dec 29, 2022
Complete U-net Implementation with keras
U Net Lowered with Keras Complete U-net Implementation with keras Original Paper Link : https://arxiv.org/abs/1505.04597 Special Implementations : The
 14 Oct 10, 2022
14 Oct 10, 2022
Sharpness-Aware Minimization for Efficiently Improving Generalization
Sharpness-Aware-Minimization-TensorFlow This repository provides a minimal implementation of sharpness-aware minimization (SAM) (Sharpness-Aware Minim
54 Dec 8, 2022
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution (CVPR2021)
MASA-SR Official PyTorch implementation of our CVPR2021 paper MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Re
 126 Dec 20, 2022
126 Dec 20, 2022
A simple way to train and use PyTorch models with multi-GPU, TPU, mixed-precision
🤗 Accelerate was created for PyTorch users who like to write the training loop of PyTorch models but are reluctant to write and maintain the boilerplate code needed to use multi-GPUs/TPU/fp16.
 3.5k Jan 8, 2023
3.5k Jan 8, 2023
SLIDE : In Defense of Smart Algorithms over Hardware Acceleration for Large-Scale Deep Learning Systems
The SLIDE package contains the source code for reproducing the main experiments in this paper. Dataset The Datasets can be downloaded in Amazon-
72 Dec 16, 2022
A highly efficient and modular implementation of Gaussian Processes in PyTorch
GPyTorch GPyTorch is a Gaussian process library implemented using PyTorch. GPyTorch is designed for creating scalable, flexible, and modular Gaussian
 3k Jan 2, 2023
3k Jan 2, 2023
BlazingSQL is a lightweight, GPU accelerated, SQL engine for Python. Built on RAPIDS cuDF.
A lightweight, GPU accelerated, SQL engine built on the RAPIDS.ai ecosystem. Get Started on app.blazingsql.com Getting Started | Documentation | Examp
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
A curated list of neural network pruning resources.
A curated list of neural network pruning and related resources. Inspired by awesome-deep-vision, awesome-adversarial-machine-learning, awesome-deep-learning-papers and Awesome-NAS.
 1.7k Jan 9, 2023
1.7k Jan 9, 2023
A highly efficient and modular implementation of Gaussian Processes in PyTorch
GPyTorch GPyTorch is a Gaussian process library implemented using PyTorch. GPyTorch is designed for creating scalable, flexible, and modular Gaussian
3k Jan 2, 2023
QKeras: a quantization deep learning library for Tensorflow Keras
QKeras github.com/google/qkeras QKeras 0.8 highlights: Automatic quantization using QKeras; Stochastic behavior (including stochastic rouding) is disa
 437 Jan 3, 2023
437 Jan 3, 2023

Social Distancing Detector using deep learning and capable to run on edge AI devices such as NVIDIA Jetson, Google Coral, and more.
Smart Social Distancing Smart Social Distancing Introduction Getting Started Prerequisites Usage Processor Optional Parameters Configuring AWS credent
 129 Dec 12, 2022
129 Dec 12, 2022
Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
JAX: Autograd and XLA Quickstart | Transformations | Install guide | Neural net libraries | Change logs | Reference docs | Code search News: JAX tops
11.4k Feb 13, 2021
Tensors and Dynamic neural networks in Python with strong GPU acceleration
PyTorch is a Python package that provides two high-level features: Tensor computation (like NumPy) with strong GPU acceleration Deep neural networks b
 46.1k Feb 13, 2021
46.1k Feb 13, 2021
Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
JAX: Autograd and XLA Quickstart | Transformations | Install guide | Neural net libraries | Change logs | Reference docs | Code search News: JAX tops
21.3k Jan 1, 2023
Tensors and Dynamic neural networks in Python with strong GPU acceleration
PyTorch is a Python package that provides two high-level features: Tensor computation (like NumPy) with strong GPU acceleration Deep neural networks b
61.4k Jan 4, 2023