1145 Repositories
Python video-pose-estimation Libraries
Identifying a Training-Set Attack’s Target Using Renormalized Influence Estimation
Identifying a Training-Set Attack’s Target Using Renormalized Influence Estimation By: Zayd Hammoudeh and Daniel Lowd Paper: Arxiv Preprint Coming soo
 2 Oct 8, 2022
2 Oct 8, 2022

Blind Video Temporal Consistency via Deep Video Prior
deep-video-prior (DVP) Code for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior PyTorch implementation | paper | project web
 272 Dec 21, 2022
272 Dec 21, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
 9.6k Jan 9, 2023
9.6k Jan 9, 2023

AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
AirPose AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation Check the teaser video This repository contains the code of A
 41 Dec 5, 2022
41 Dec 5, 2022

Human Dynamics from Monocular Video with Dynamic Camera Movements
Human Dynamics from Monocular Video with Dynamic Camera Movements Ri Yu, Hwangpil Park and Jehee Lee Seoul National University ACM Transactions on Gra
 215 Jan 1, 2023
215 Jan 1, 2023
Spotify playlist video generator
This program creates a video version of your Spotify playlist by using the Spotify API and YouTube-dl.
 0 Mar 3, 2022
0 Mar 3, 2022
Meme-videos - Scrapes memes and turn them into a video compilations
Meme Videos Scrapes memes from reddit using praw and request and then converts t
 12 Oct 28, 2022
12 Oct 28, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023

 431 Jan 3, 2023
431 Jan 3, 2023
Clockwork Convnets for Video Semantic Segmentation
Clockwork Convnets for Video Semantic Segmentation This is the reference implementation of arxiv:1608.03609: Clockwork Convnets for Video Semantic Seg
 141 Nov 21, 2022
141 Nov 21, 2022
Natural Posterior Network: Deep Bayesian Predictive Uncertainty for Exponential Family Distributions
Natural Posterior Network This repository provides the official implementation o
 54 Dec 6, 2022
54 Dec 6, 2022

PyTorch implemention of ICCV'21 paper SGPA: Structure-Guided Prior Adaptation for Category-Level 6D Object Pose Estimation
SGPA: Structure-Guided Prior Adaptation for Category-Level 6D Object Pose Estimation This is the PyTorch implemention of ICCV'21 paper SGPA: Structure
 24 Dec 5, 2022
24 Dec 5, 2022

Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
 1 Jan 23, 2022
1 Jan 23, 2022
Xbot-Music - Bot Play Music and Video in Voice Chat Group Telegram
XBOT-MUSIC A Telegram Music+video Bot written in Python using Pyrogram and Py-Tg
 2 Jan 20, 2022
2 Jan 20, 2022
Fixed waypoint(pose) navigation for turtlebot simulation.
Turtlebot-NavigationStack-Fixed-Waypoints fixed waypoint(pose) navigation for turtlebot simulation. Task Details Task Permformed using Navigation Stac
 1 Apr 8, 2022
1 Apr 8, 2022

Estimation of whether or not the persons given information will have diabetes.
Diabetes Business Problem : It is desired to develop a machine learning model that can predict whether people have diabetes when their characteristics
 0 Jan 20, 2022
0 Jan 20, 2022

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022
(ICONIP 2020) MobileHand: Real-time 3D Hand Shape and Pose Estimation from Color Image
MobileHand: Real-time 3D Hand Shape and Pose Estimation from Color Image This repo contains the source code for MobileHand, real-time estimation of 3D
 90 Dec 12, 2022
90 Dec 12, 2022

All exercises done during the Python 3 course in the Video Course (World 1, 2 and 3)
Python3-cursoemvideo-exercises - All exercises done during the Python 3 course in the Video Course (World 1, 2 and 3)
 3 Jan 17, 2022
3 Jan 17, 2022
TikTok - TikTok Bot to download video or audio from TikTok
TikTok - TikTok Bot to download video or audio from TikTok
 51 Mar 4, 2022
51 Mar 4, 2022

DeepFaceLive - Live Deep Fake in python, Real-time face swap for PC streaming or video calls
DeepFaceLive - Live Deep Fake in python, Real-time face swap for PC streaming or video calls
 8.3k Dec 31, 2022
8.3k Dec 31, 2022
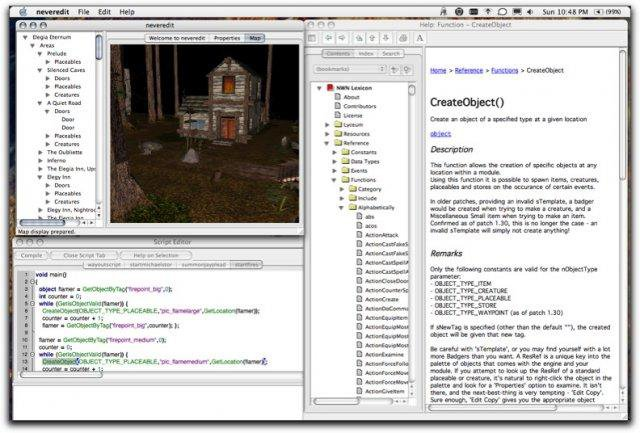
Editor for Bioware's Original Neverwinter Nights Game
neveredit This is an import of an old sourceforge project. Neveredit is an editor for Bioware's Neverwinter Nights game. It also includes all the low
 2 Apr 12, 2022
2 Apr 12, 2022

Code for paper: Towards Tokenized Human Dynamics Representation
Video Tokneization Codebase for video tokenization, based on our paper Towards Tokenized Human Dynamics Representation. Prerequisites (tested under Py
 20 May 31, 2022
20 May 31, 2022

A PyTorch implementation of VIOLET
VIOLET: End-to-End Video-Language Transformers with Masked Visual-token Modeling A PyTorch implementation of VIOLET Overview VIOLET is an implementati
 119 Dec 30, 2022
119 Dec 30, 2022

Official repository for the ICCV 2021 paper: UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model Official repository for the ICCV 2021 paper: UltraPose: Syn
 92 Dec 21, 2022
92 Dec 21, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022

Pose Transformers: Human Motion Prediction with Non-Autoregressive Transformers
Pose Transformers: Human Motion Prediction with Non-Autoregressive Transformers This is the repo used for human motion prediction with non-autoregress
 26 Dec 14, 2022
26 Dec 14, 2022
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss This is official implement of "
 87 Dec 24, 2022
87 Dec 24, 2022

Mixed Neural Likelihood Estimation for models of decision-making
Mixed neural likelihood estimation for models of decision-making Mixed neural likelihood estimation (MNLE) enables Bayesian parameter inference for mo
 9 Dec 22, 2022
9 Dec 22, 2022
[SIGGRAPH Asia 2021] Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN [Paper] [Project Website] [Output resutls] Official Pytorch i
 215 Dec 17, 2022
215 Dec 17, 2022
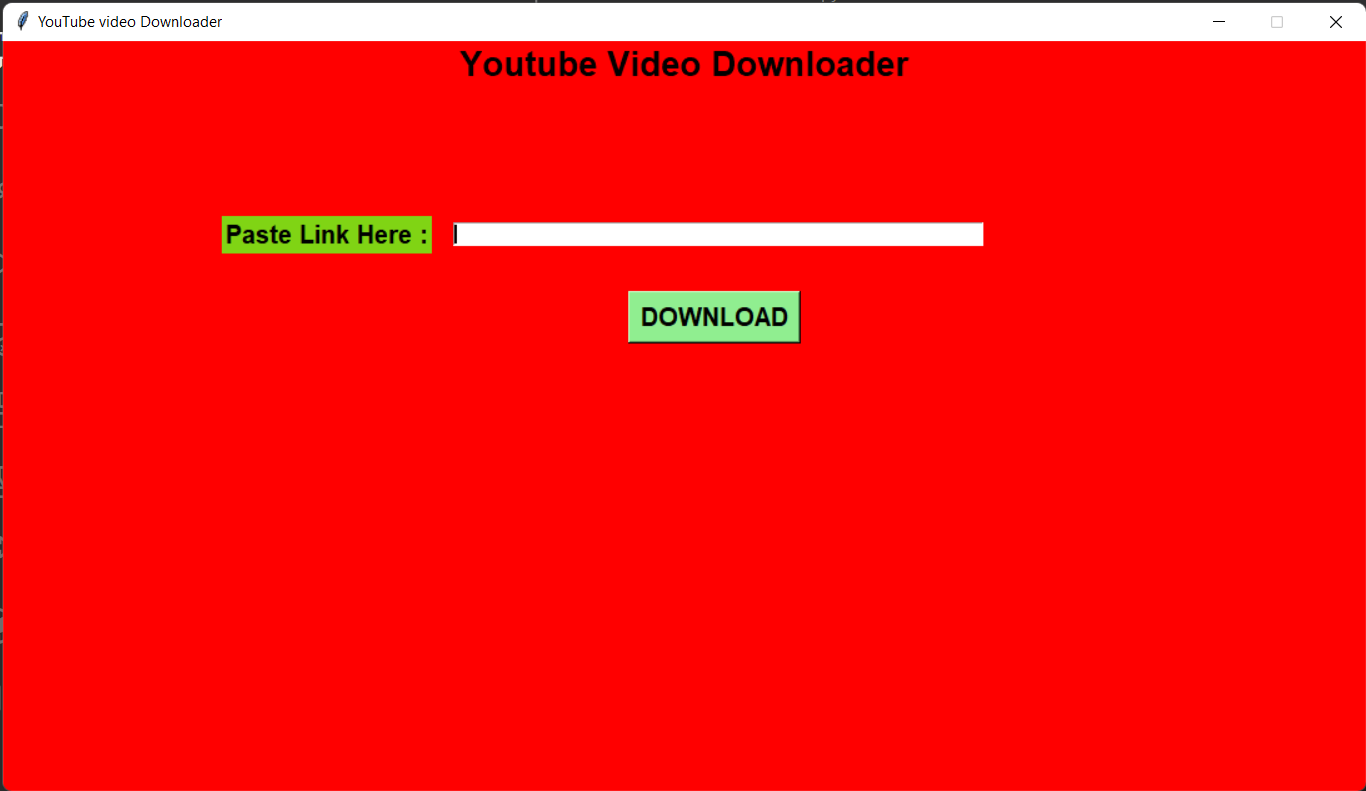
YouTube-Downloader - YouTube Video Downloader made using python
YouTube-Downloader YouTube Videos Downloder made using python.
 1 Jan 16, 2022
1 Jan 16, 2022

CLIP2Video: Mastering Video-Text Retrieval via Image CLIP
CLIP2Video: Mastering Video-Text Retrieval via Image CLIP The implementation of paper CLIP2Video: Mastering Video-Text Retrieval via Image CLIP. CLIP2
 168 Dec 29, 2022
168 Dec 29, 2022

An official PyTorch Implementation of Boundary-aware Self-supervised Learning for Video Scene Segmentation (BaSSL)
An official PyTorch Implementation of Boundary-aware Self-supervised Learning for Video Scene Segmentation (BaSSL)
 72 Dec 28, 2022
72 Dec 28, 2022
Human pose estimation from video plays a critical role in various applications such as quantifying physical exercises, sign language recognition, and full-body gesture control.
Pose Detection Project Description: Human pose estimation from video plays a critical role in various applications such as quantifying physical exerci
 2 Jan 17, 2022
2 Jan 17, 2022
Energy consumption estimation utilities for Jetson-based platforms
This repository contains a utility for measuring energy consumption when running various programs in NVIDIA Jetson-based platforms. Currently TX-2, NX, and AGX are supported.
 10 Jun 17, 2022
10 Jun 17, 2022

Pytorch implementation of Decoupled Spatial-Temporal Transformer for Video Inpainting
Decoupled Spatial-Temporal Transformer for Video Inpainting By Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, J
 51 Dec 13, 2022
51 Dec 13, 2022
Use CLIP to represent video for Retrieval Task
A Straightforward Framework For Video Retrieval Using CLIP This repository contains the basic code for feature extraction and replication of results.
 54 Dec 22, 2022
54 Dec 22, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
An anime themed telegram bot that can convert telegram media.
ShoukoKomiRobot • 𝕎𝕣𝕚𝕥𝕥𝕖𝕟 𝕀𝕟 Python3 • 𝕃𝕚𝕓𝕣𝕒𝕣𝕪 𝕌𝕤𝕖𝕕 Pyrogram • 𝕊𝕠𝕗𝕥𝕨𝕒𝕣𝕖 𝕌𝕤𝕖𝕕 Ebook-convert Deploy 𝔽𝕠𝕣𝕜 𝕥𝕙𝕚𝕤 𝕣
 25 Aug 14, 2022
25 Aug 14, 2022
Play Video & Music on Telegram Group Video Chat
Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat 🧪 Get SESSION_NAME from below: Pyrogram
 1 Jan 17, 2022
1 Jan 17, 2022
This repo is about implementing different approaches of pose estimation and also is a sub-task of the smart hospital bed project :smile:
Pose-Estimation This repo is a sub-task of the smart hospital bed project which is about implementing the task of pose estimation 😄 Many thanks to th
 11 Oct 17, 2022
11 Oct 17, 2022

Action Recognition for Self-Driving Cars
Action Recognition for Self-Driving Cars This repo contains the codes for the 2021 Fall semester project "Action Recognition for Self-Driving Cars" at
 3 Apr 7, 2022
3 Apr 7, 2022
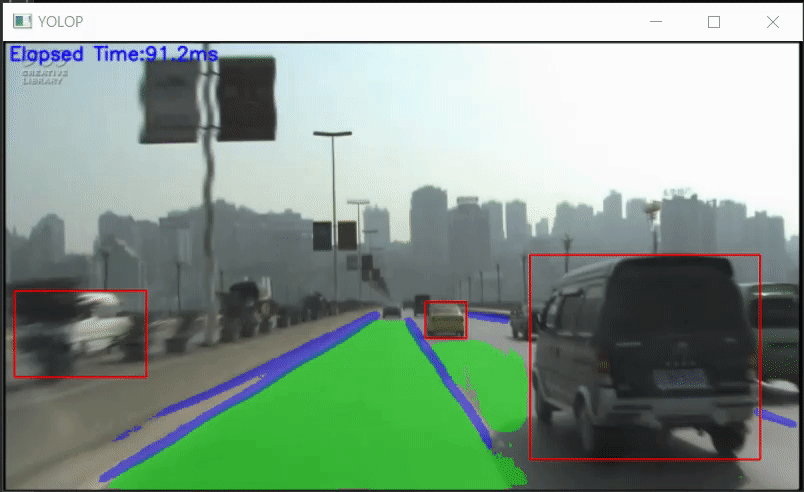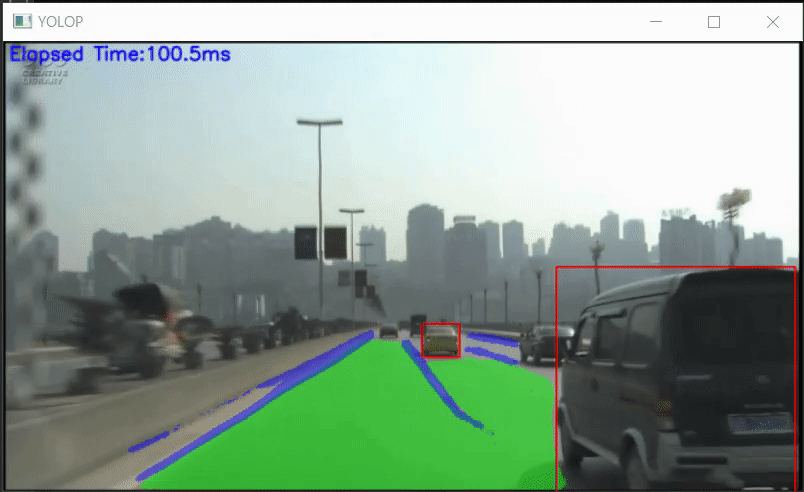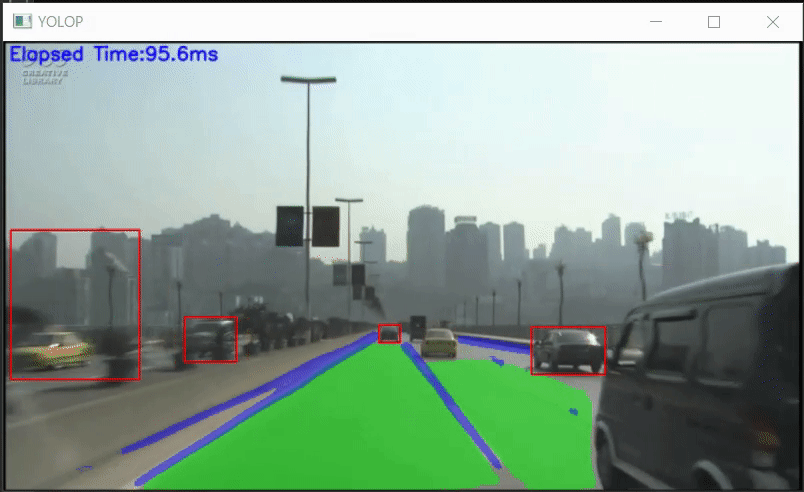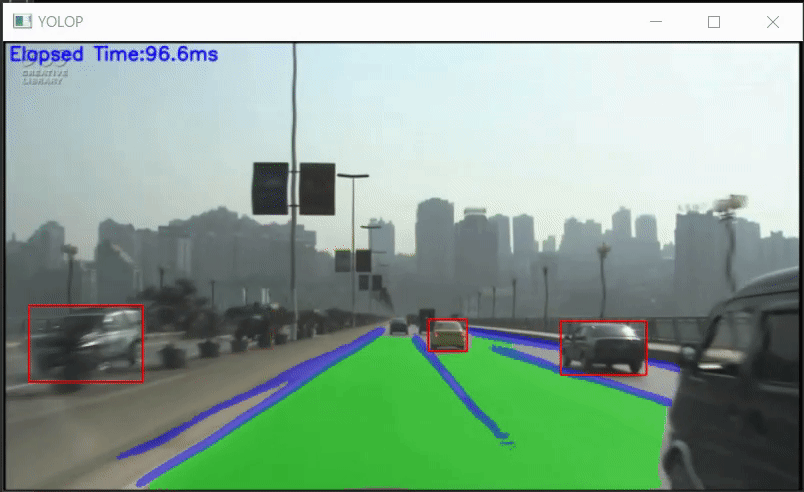
YOLOPのPythonでのONNX推論サンプル
YOLOP-ONNX-Video-Inference-Sample YOLOPのPythonでのONNX推論サンプルです。 ONNXモデルは、hustvl/YOLOP/weights を使用しています。 Requirement OpenCV 3.4.2 or later onnxruntime 1.
 8 Sep 5, 2022
8 Sep 5, 2022
A Blender addon for VSE that auto-adjusts video strip's length, if speed effect is applied.
Blender VSE Speed Adjust Addon When using Video Sequence Editor in Blender, the speed effect strip doesn't auto-adjusts clip length when changing its
 2 Jan 18, 2022
2 Jan 18, 2022
Multi-query Video Retreival
Multi-query Video Retreival
 17 Nov 22, 2022
17 Nov 22, 2022

VR Viewport Pose Model for Quantifying and Exploiting Frame Correlations
This repository contains the introduction to the collected VRViewportPose dataset and the code for the IEEE INFOCOM 2022 paper: "VR Viewport Pose Model for Quantifying and Exploiting Frame Correlations"
 0 Aug 10, 2022
0 Aug 10, 2022
Spectrum Surveying: Active Radio Map Estimation with Autonomous UAVs
Spectrum Surveying: The Python code in this repository implements the simulations and plots the figures described in the paper “Spectrum Surveying: Ac
 2 Dec 6, 2022
2 Dec 6, 2022
PEPit is a package enabling computer-assisted worst-case analyses of first-order optimization methods.
PEPit: Performance Estimation in Python This open source Python library provides a generic way to use PEP framework in Python. Performance estimation
 53 Nov 16, 2022
53 Nov 16, 2022

Public Models considered for emotion estimation from EEG
Emotion-EEG Set of models for emotion estimation from EEG. Composed by the combination of two deep-learing models learning together (RNN and CNN) with
 21 Dec 23, 2022
21 Dec 23, 2022

This is the code for the paper "Motion-Focused Contrastive Learning of Video Representations" (ICCV'21).
Motion-Focused Contrastive Learning of Video Representations Introduction This is the code for the paper "Motion-Focused Contrastive Learning of Video
 11 Sep 23, 2022
11 Sep 23, 2022

This is a demo app to be used in the video streaming applications
MoViDNN: A Mobile Platform for Evaluating Video Quality Enhancement with Deep Neural Networks MoViDNN is an Android application that can be used to ev
 7 Jul 21, 2022
7 Jul 21, 2022

Proposal, Tracking and Segmentation (PTS): A Cascaded Network for Video Object Segmentation
Proposal, Tracking and Segmentation (PTS): A Cascaded Network for Video Object Segmentation By Qiang Zhou*, Zilong Huang*, Lichao Huang, Han Shen, Yon
 117 Apr 1, 2022
117 Apr 1, 2022

MaskTrackRCNN for video instance segmentation based on mmdetection
MaskTrackRCNN for video instance segmentation Introduction This repo serves as the official code release of the MaskTrackRCNN model for video instance
 411 Jan 5, 2023
411 Jan 5, 2023

The final project of "Applying AI to 3D Medical Imaging Data" from "AI for Healthcare" nanodegree - Udacity.
Quantifying Hippocampus Volume for Alzheimer's Progression Background Alzheimer's disease (AD) is a progressive neurodegenerative disorder that result
 1 Jan 14, 2022
1 Jan 14, 2022

UDP++ (ECCVW 2020 Oral), (Winner of COCO 2020 Keypoint Challenge).
UDP-Pose This is the pytorch implementation for UDP++, which won the Fisrt place in COCO Keypoint Challenge at ECCV 2020 Workshop. Top-Down Results on
 20 Jul 29, 2022
20 Jul 29, 2022
Vigia-youtube - The YouTube Watch bot is able to monitor channels on Google's video platform
Vigia do YouTube O bot Vigia do YouTube é capaz de monitorar canais na plataform
 10 Oct 3, 2022
10 Oct 3, 2022
GEGVL: Google Earth Based Geoscience Video Library
Google Earth Based Geoscience Video Library is transforming to Server Based. The
 3 Feb 11, 2022
3 Feb 11, 2022
Video stream recording dockerized server using python/ffmpeg.
Stream Recording Server Video stream recording dockerized server using python/ffmpeg. Usage Configuration Prepare .env file, check .env.example for th
 2 Jan 14, 2022
2 Jan 14, 2022
Eff video representation - Efficient video representation through neural fields
Neural Residual Flow Fields for Efficient Video Representations 1. Download MPI
 41 Jan 6, 2023
41 Jan 6, 2023

YouTube Video publisher using youtube-dl & ROS2🐢
YouTube-publisher-ROS2 Publish sensor_msgs/Image by "YouTube" 🤗 🤗 🤗 ! You don't have to use webcamera or your video to check demos. Purpose Quick d
 5 Dec 4, 2022
5 Dec 4, 2022

Training a Resilient Q-Network against Observational Interference, Causal Inference Q-Networks
Obs-Causal-Q-Network AAAI 2022 - Training a Resilient Q-Network against Observational Interference Preprint | Slides | Colab Demo | Environment Setup
 23 Nov 21, 2022
23 Nov 21, 2022
Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages.
Video Games Web Scraper Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages. This
 1 Jan 12, 2022
1 Jan 12, 2022
Face uncertainty quantification or estimation using PyTorch.
Face-uncertainty-pytorch This is a demo code of face uncertainty quantification or estimation using PyTorch. The uncertainty of face recognition is af
 3 Sep 16, 2022
3 Sep 16, 2022
Depth-Aware Video Frame Interpolation (CVPR 2019)
DAIN (Depth-Aware Video Frame Interpolation) Project | Paper Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang, Zhiyong Gao, and Ming-Hsuan Yang IEEE C
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

A platform which give you info about the newest video on a channel
youtube A platform which give you info about the newest video on a channel. This uses web scraping, a better implementation will be to use the API. BR
 36 Sep 29, 2022
36 Sep 29, 2022
The official TensorFlow implementation of the paper Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition
Action Transformer A Self-Attention Model for Short-Time Human Action Recognition This repository contains the official TensorFlow implementation of t
 20 Jan 3, 2023
20 Jan 3, 2023
Weight estimation in CT by multi atlas techniques
maweight A Python package for multi-atlas based weight estimation for CT images, including segmentation by registration, feature extraction and model
 0 Dec 24, 2021
0 Dec 24, 2021

Official Implementation of ReferFormer
The official implementation of the paper: Language as Queries for Referring Video Object Segmentation Language as Queries for Referring Video Object S
 51 Jan 11, 2022
51 Jan 11, 2022
R-package accompanying the paper "Dynamic Factor Model for Functional Time Series: Identification, Estimation, and Prediction"
dffm The goal of dffm is to provide functionality to apply the methods developed in the paper “Dynamic Factor Model for Functional Time Series: Identi
 3 Dec 9, 2022
3 Dec 9, 2022
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data. Flexible EM-Inspired Discriminant Analysis is a robust supervised classification algorithm that performs well in noisy and contaminated datasets.
 0 Sep 6, 2022
0 Sep 6, 2022

Optimal Camera Position for a Practical Application of Gaze Estimation on Edge Devices,
Optimal Camera Position for a Practical Application of Gaze Estimation on Edge Devices, Linh Van Ma, Tin Trung Tran, Moongu Jeon, ICAIIC 2022 (The 4th
 11 Oct 10, 2022
11 Oct 10, 2022
Video lie detector using xgboost - A video lie detector using OpenFace and xgboost
video_lie_detector_using_xgboost a video lie detector using OpenFace and xgboost
 2 Jan 11, 2022
2 Jan 11, 2022
A simple python script and it's used for mp4 type video downloading from youtube.
This is a simple python script and it's used for mp4 type video downloading from youtube. also, it's used inbuilt python module pytube. Furthermore, I know we have so many apps and online websites to do the same thing so it's just an experiment to study how to do those things in python.
 1 Jan 10, 2022
1 Jan 10, 2022
In this project, we will be blurring the background in a live video feed
In this project, we will be blurring the background in a live video feed. This can be further integrated into online meetings, streamings etc.
2 Jan 6, 2022

A vanilla 3D face modeling on pose-invariant and multi-lightning image data
3D-Face-Modeling A vanilla 3D face modeling on pose-invariant and multi-lightning image data Table of Contents Background Install Usage Contributing B
 1 Mar 12, 2022
1 Mar 12, 2022
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023

Course materials and handouts for #100DaysOfCode in Python course
#100DaysOfCode with Python course Course details page: talkpython.fm/100days Course Summary #100DaysOfCode in Python is your perfect companion to take
 1.9k Dec 31, 2022
1.9k Dec 31, 2022
Python package for Near Duplicate Video Detection (Perceptual Video Hashing) - Get a 64-bit comparable hash-value for any video.
The Python package for near duplicate video detection ⭐️ Introduction Videohash is a Python package for detecting near-duplicate videos (Perceptual Vi
 144 Dec 19, 2022
144 Dec 19, 2022

A High-Quality Real Time Upscaler for Anime Video
Anime4K Anime4K is a set of open-source, high-quality real-time anime upscaling/denoising algorithms that can be implemented in any programming langua
 15.7k Jan 6, 2023
15.7k Jan 6, 2023

Official PyTorch implementation of "The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation" (ICCV 21).
CenterGroup This the official implementation of our ICCV 2021 paper The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person P
 43 Dec 25, 2022
43 Dec 25, 2022

Transfer Learning for Pose Estimation of Illustrated Characters
bizarre-pose-estimator Transfer Learning for Pose Estimation of Illustrated Characters Shuhong Chen *, Matthias Zwicker * WACV2022 [arxiv] [video] [po
 142 Dec 28, 2022
142 Dec 28, 2022

The VarCNN is an Convolution Neural Network based approach to automate Video Assistant Referee in football.
VarCnn: The Deep Learning Powered VAR
 1 Jan 9, 2022
1 Jan 9, 2022
Python package for dynamic system estimation of time series
PyDSE Toolset for Dynamic System Estimation for time series inspired by DSE. It is in a beta state and only includes ARMA models right now. Documentat
 40 Oct 7, 2022
40 Oct 7, 2022
FADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
FADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
 6 Nov 18, 2022
6 Nov 18, 2022
deepstream python rtsp video h264 or gstreamer python rtsp h264 | h264
deepstream python rtsp video h264 or gstreamer python rtsp h264 | h264 deepstrea
 6 Dec 14, 2022
6 Dec 14, 2022
VCPlayerBot - Telegram bot to stream videos in telegram voicechat for both groups and channels. Supports live steams, YouTube videos and telegram media
VCPlayerBot Telegram bot to stream videos in telegram voicechat for both groups
 3 Feb 22, 2022
3 Feb 22, 2022

Measures input lag without dedicated hardware, performing motion detection on recorded or live video
What is InputLagTimer? This tool can measure input lag by analyzing a video where both the game controller and the game screen can be seen on a webcam
 4 Aug 18, 2022
4 Aug 18, 2022
A curated list of the top 10 computer vision papers in 2021 with video demos, articles, code and paper reference.
The Top 10 Computer Vision Papers of 2021 The top 10 computer vision papers in 2021 with video demos, articles, code, and paper reference. While the w
 118 Dec 21, 2022
118 Dec 21, 2022
Automatic Video Library Manager for TV Shows
Automatic Video Library Manager for TV Shows. It watches for new episodes of your favorite shows, and when they are posted it does its magic. Dependen
 1.5k Dec 22, 2022
1.5k Dec 22, 2022
Social Fabric: Tubelet Compositions for Video Relation Detection
Social-Fabric Social Fabric: Tubelet Compositions for Video Relation Detection This repository contains the code and results for the following paper:
 7 Aug 9, 2022
7 Aug 9, 2022

Code for Domain Adaptive Video Segmentation via Temporal Consistency Regularization in ICCV 2021
Domain Adaptive Video Segmentation via Temporal Consistency Regularization Updates 08/2021: check out our domain adaptation for sematic segmentation p
 36 Dec 12, 2022
36 Dec 12, 2022

Official code for the ICCV 2021 paper "DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders"
DECA Official code for the ICCV 2021 paper "DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders". All the code is writte
 23 Dec 1, 2022
23 Dec 1, 2022

Code for "Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation" ICCV'21
Skeletal-GNN Code for "Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation" ICCV'21 Various deep learning techniques have been propose
 37 Oct 23, 2022
37 Oct 23, 2022
HandFoldingNet ✌️ : A 3D Hand Pose Estimation Network Using Multiscale-Feature Guided Folding of a 2D Hand Skeleton
HandFoldingNet ✌️ : A 3D Hand Pose Estimation Network Using Multiscale-Feature Guided Folding of a 2D Hand Skeleton Wencan Cheng, Jae Hyun Park, Jong
 23 Oct 21, 2022
23 Oct 21, 2022

Python3 / PyTorch implementation of the following paper: Fine-grained Semantics-aware Representation Enhancement for Self-supervisedMonocular Depth Estimation. ICCV 2021 (oral)
FSRE-Depth This is a Python3 / PyTorch implementation of FSRE-Depth, as described in the following paper: Fine-grained Semantics-aware Representation
 77 Dec 28, 2022
77 Dec 28, 2022

Implementation of Cross-category Video Highlight Detection via Set-based Learning (ICCV 2021).
Cross-category Video Highlight Detection via Set-based Learning Introduction This project is an implementation of ``Cross-category Video Highlight Det
 49 Dec 17, 2022
49 Dec 17, 2022