1191 Repositories
Python video-transformers Libraries

Official Pytorch Implementation of Relational Self-Attention: What's Missing in Attention for Video Understanding
Relational Self-Attention: What's Missing in Attention for Video Understanding This repository is the official implementation of "Relational Self-Atte
 43 Dec 7, 2022
43 Dec 7, 2022
SLAMP: Stochastic Latent Appearance and Motion Prediction
SLAMP: Stochastic Latent Appearance and Motion Prediction Official implementation of the paper SLAMP: Stochastic Latent Appearance and Motion Predicti
 34 Dec 8, 2022
34 Dec 8, 2022
A Python library that simplifies working with video from soccer matches.
Match Video This is a Python library that simplifies working with video from soccer matches. It allows match video to be selected intuitively by perio
 2 Jul 21, 2022
2 Jul 21, 2022

Python based YouTube video Downloader GUI Application.
Youtube video Downloader Python based Youtube video Downloader GUI Application. Installation Python Dependencies Import pytube pip install pytube Im
 1 Jan 3, 2022
1 Jan 3, 2022

PolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation
PolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation Winner method of the ICCV-2021 SemKITTI-DVPS Challenge. [arxiv] [
 38 Jan 3, 2023
38 Jan 3, 2023
![[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation](https://user-images.githubusercontent.com/65257938/145016835-3c4be820-c55d-4eb4-b7f5-b8a012ee0f8c.png)
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
 70 Dec 4, 2022
70 Dec 4, 2022

Implementation of N-Grammer, augmenting Transformers with latent n-grams, in Pytorch
N-Grammer - Pytorch Implementation of N-Grammer, augmenting Transformers with latent n-grams, in Pytorch Install $ pip install n-grammer-pytorch Usage
 66 Dec 29, 2022
66 Dec 29, 2022
Train and use generative text models in a few lines of code.
blather Train and use generative text models in a few lines of code. To see blather in action check out the colab notebook! Installation Use the packa
 16 Nov 7, 2022
16 Nov 7, 2022

PyTorch implementation of Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Simple PyTorch Implementation of "Grokking" Implementation of Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets Usage Running
 15 Sep 29, 2022
15 Sep 29, 2022
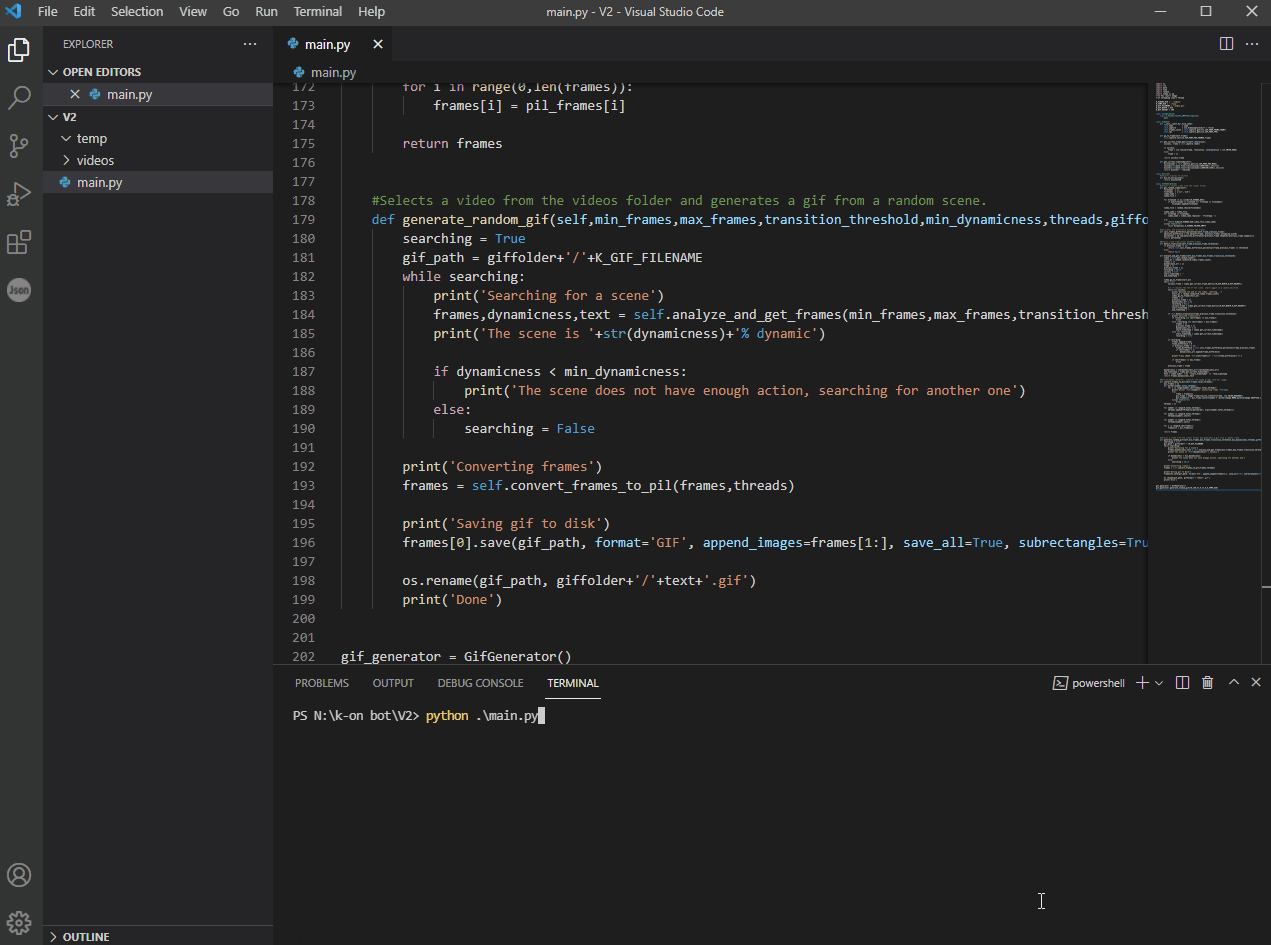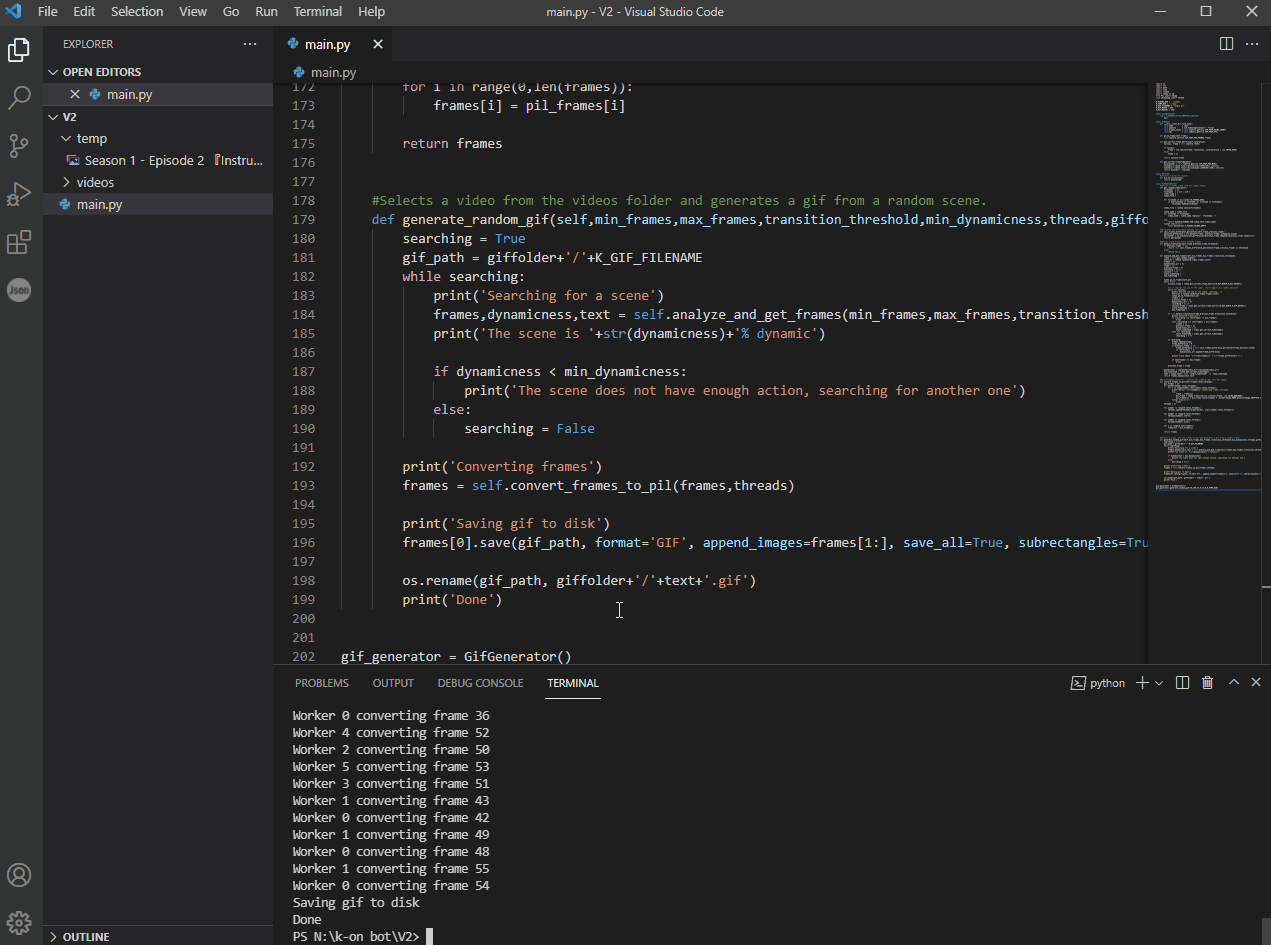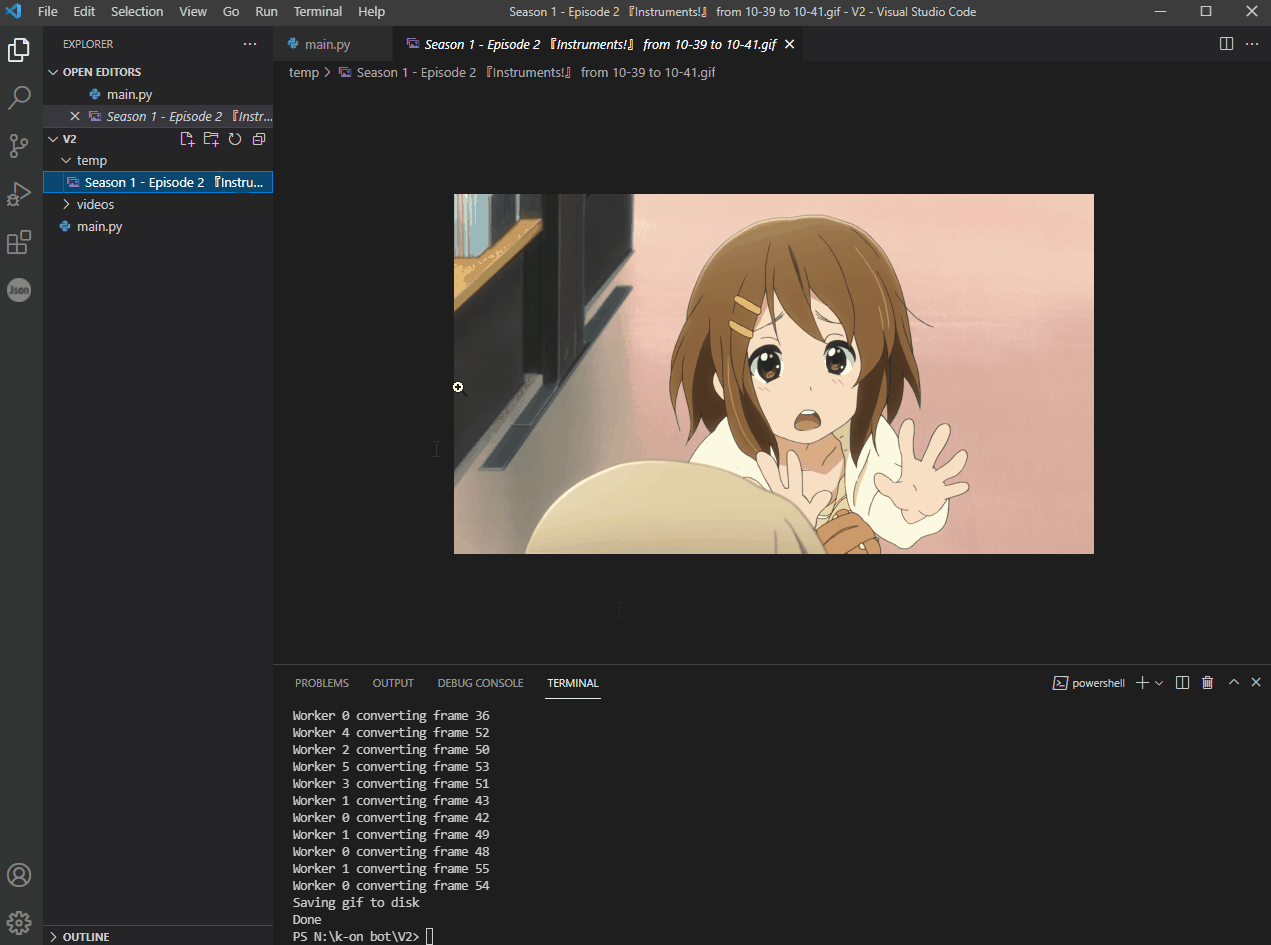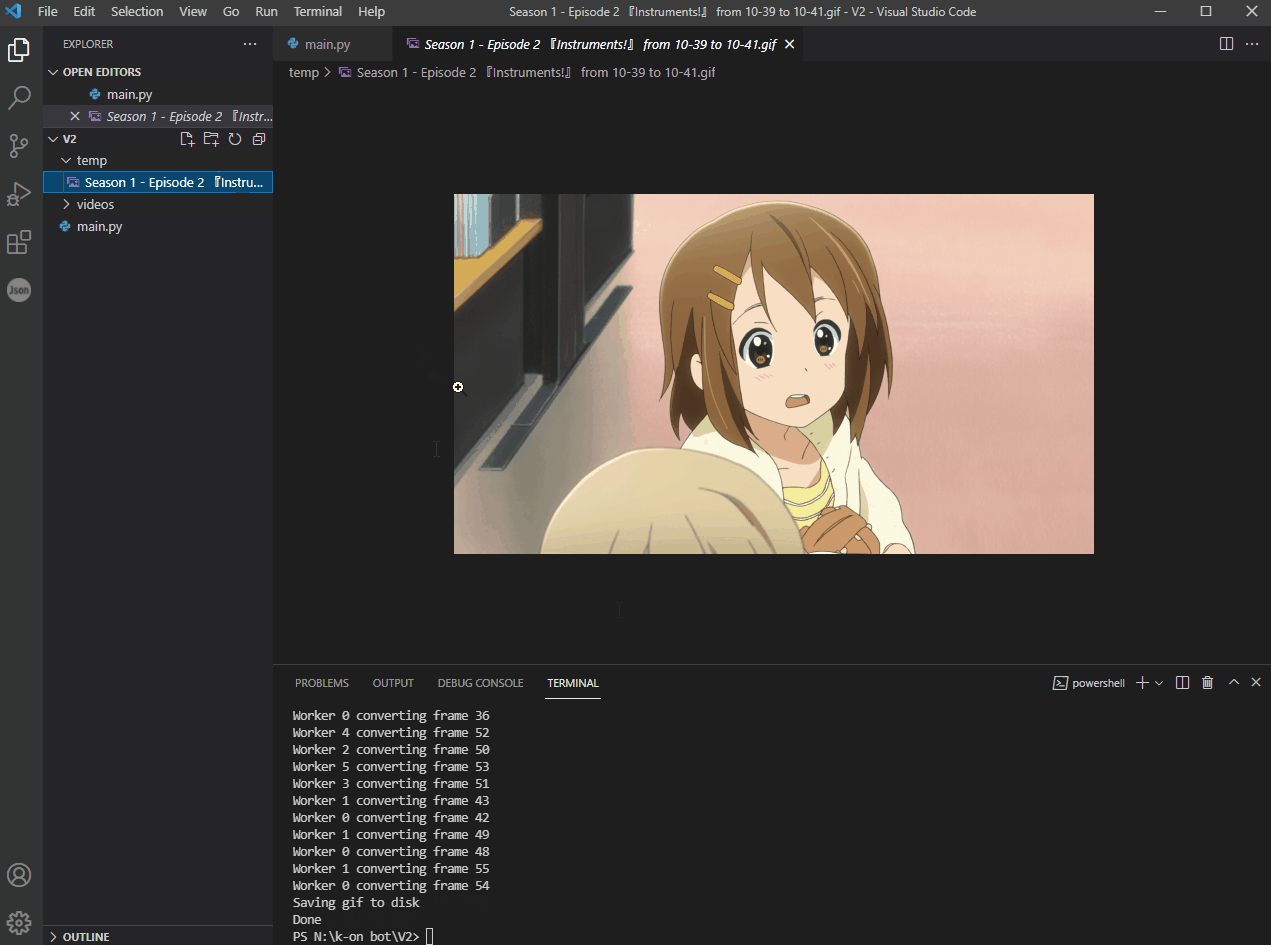
Anime2Gif - an algorithm that detects scenes in a video and generates gifs from it
Anime2Gif Anime2Gif is an algorithm that detects scenes in a video and generates gifs from it. How to use To use it, first, you'll need to install it'
 1 Dec 9, 2021
1 Dec 9, 2021

Simple cross-platform application for DaVinci surgical video frame annotation
About DaVid is a simple cross-platform GUI for annotating robotic and endoscopic surgical actions for use in deep-learning research. Features Simple a
 4 Oct 9, 2021
4 Oct 9, 2021
Telegram bot for stream music or video on telegram
Anonymous VC Bot + Stream Bot Telegram bot for stream music or video on telegram, powered by PyTgCalls and Pyrogram Features Playlist features Multi L
 111 Oct 4, 2022
111 Oct 4, 2022
Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat
WAR MUSIC / VIDEO PLAYER Bot Bot Link: 🧪 Get SESSION_NAME from below: Pyrogram 🎭 Preview ✨ Features Music & Video stream support MultiChat support P
 11 Dec 25, 2022
11 Dec 25, 2022
Takes a video as an input and creates a video which is suitable to upload on Youtube Shorts and Tik Tok (1080x1920 resolution).
Shorts-Tik-Tok-Creator Takes a video as an input and creates a video which is suitable to upload on Youtube Shorts and Tik Tok (1080x1920 resolution).
 5 Nov 9, 2022
5 Nov 9, 2022
Latest Open Source Code for Playing Music in Telegram Video Chat. Made with Pyrogram and Pytgcalls 💖
MusicPlayer_TG Latest Open Source Code for Playing Music in Telegram Video Chat. Made with Pyrogram and Pytgcalls 💖 Requirements 📝 FFmpeg NodeJS nod
 2 Feb 4, 2022
2 Feb 4, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 0 Mar 20, 2022
0 Mar 20, 2022

Code for the TPAMI paper: "Syntax Customized Video Captioning by Imitating Exemplar Sentences"
Syntax-Customized-Video-Captioning Code for the TPAMI paper: "Syntax Customized Video Captioning by Imitating Exemplar Sentences". This is my second w
 3 Dec 5, 2022
3 Dec 5, 2022

Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022

Official PyTorch implementation for paper "Efficient Two-Stage Detection of Human–Object Interactions with a Novel Unary–Pairwise Transformer"
UPT: Unary–Pairwise Transformers This repository contains the official PyTorch implementation for the paper Frederic Z. Zhang, Dylan Campbell and Step
 109 Dec 20, 2022
109 Dec 20, 2022
Userscript qutebrowser for downloading audio / video from youtube using aria2
Yt-Downloader Userscript qutebrowser for downloading video / audio from youtube using aria2 by hint links. Requirements Rofi youtube-dl aria2 dunst In
 0 Dec 11, 2021
0 Dec 11, 2021
Streams video from raspberry pi to desktop T1 - Recognizes Faces on client T2
VideoStreamingServer Completed: Streams video from raspberry pi to desktop T1 - Recognizes Faces on client T2 In progress: Change the transmission Pro
 1 Dec 6, 2021
1 Dec 6, 2021
Royal Music You can play music and video at a time in vc
Royals-Music Royal Music You can play music and video at a time in vc Commands SOON String STRING_SESSION Deployment 🎖 Credits • 🇸ᴏᴍʏᴀ⃝🇯ᴇᴇᴛ • 🇴ғғɪ
 2 Nov 23, 2021
2 Nov 23, 2021
Telegram Video Stream
Video Stream An Advanced VC Video Player created for playing video in the voice chats of Telegram Groups And Channel Configs TOKEN - Get bot token fro
 46 Dec 25, 2022
46 Dec 25, 2022

Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch
NÜWA - Pytorch (wip) Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch. This repository will be popul
463 Dec 28, 2022

Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat
Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat 📊 Stats 🧪 Get SESSION_NAME from below:
 12 May 8, 2022
12 May 8, 2022

Mastering Transformers, published by Packt
Mastering Transformers This is the code repository for Mastering Transformers, published by Packt. Build state-of-the-art models from scratch with adv
 195 Jan 1, 2023
195 Jan 1, 2023

MoViNets PyTorch implementation: Mobile Video Networks for Efficient Video Recognition;
MoViNet-pytorch Pytorch unofficial implementation of MoViNets: Mobile Video Networks for Efficient Video Recognition. Authors: Dan Kondratyuk, Liangzh
 189 Dec 20, 2022
189 Dec 20, 2022

Panoptic SegFormer: Delving Deeper into Panoptic Segmentation with Transformers
Panoptic SegFormer: Delving Deeper into Panoptic Segmentation with Transformers Results results on COCO val Backbone Method Lr Schd PQ Config Download
 155 Dec 20, 2022
155 Dec 20, 2022
4D Human Body Capture from Egocentric Video via 3D Scene Grounding
4D Human Body Capture from Egocentric Video via 3D Scene Grounding [Project] [Paper] Installation: Our method requires the same dependencies as SMPLif
 37 Nov 8, 2022
37 Nov 8, 2022

A Python script that creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editing software such as FinalCut Pro for further adjustments.
Text to Subtitles - Python This python file creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editin
 9 Dec 24, 2022
9 Dec 24, 2022

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
 463 Dec 30, 2022
463 Dec 30, 2022
Code for ACL 2019 Paper: "COMET: Commonsense Transformers for Automatic Knowledge Graph Construction"
To run a generation experiment (either conceptnet or atomic), follow these instructions: First Steps First clone, the repo: git clone https://github.c
 575 Jan 1, 2023
575 Jan 1, 2023
Code for the ACL 2021 paper "Structural Guidance for Transformer Language Models"
Structural Guidance for Transformer Language Models This repository accompanies the paper, Structural Guidance for Transformer Language Models, publis
 10 Dec 14, 2022
10 Dec 14, 2022
PyTorch code for EMNLP 2019 paper "LXMERT: Learning Cross-Modality Encoder Representations from Transformers".
LXMERT: Learning Cross-Modality Encoder Representations from Transformers Our servers break again :(. I have updated the links so that they should wor
 838 Dec 19, 2022
838 Dec 19, 2022
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Video Frame Interpolation without Temporal Priors (a general method for blurry video interpolation)
Video Frame Interpolation without Temporal Priors (NeurIPS2020) [Paper] [video] How to run Prerequisites NVIDIA GPU + CUDA 9.0 + CuDNN 7.6.5 Pytorch 1
 31 Sep 4, 2022
31 Sep 4, 2022
Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022
A PyTorch Implementation of PGL-SUM from "Combining Global and Local Attention with Positional Encoding for Video Summarization", Proc. IEEE ISM 2021
PGL-SUM: Combining Global and Local Attention with Positional Encoding for Video Summarization PyTorch Implementation of PGL-SUM From "PGL-SUM: Combin
 35 Dec 22, 2022
35 Dec 22, 2022
A Telegram Video Watermark Adder Bot
Watermark-Bot A Telegram Video Watermark Adder Bot by @VideosWaterMarkRobot Features: Save Custom Watermark Image. Auto Resize Watermark According to
 5 Jun 17, 2022
5 Jun 17, 2022
Code & Models for Temporal Segment Networks (TSN) in ECCV 2016
Temporal Segment Networks (TSN) We have released MMAction, a full-fledged action understanding toolbox based on PyTorch. It includes implementation fo
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Code for Editing Factual Knowledge in Language Models
KnowledgeEditor Code for Editing Factual Knowledge in Language Models (https://arxiv.org/abs/2104.08164). @inproceedings{decao2021editing, title={Ed
 86 Nov 28, 2022
86 Nov 28, 2022

OOD Generalization and Detection (ACL 2020)
Pretrained Transformers Improve Out-of-Distribution Robustness How does pretraining affect out-of-distribution robustness? We create an OOD benchmark
 57 Jan 9, 2023
57 Jan 9, 2023
EMNLP 2021 paper The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022

Understanding the Difficulty of Training Transformers
Admin Understanding the Difficulty of Training Transformers Guided by our analyses, we propose Adaptive Model Initialization (Admin), which successful
 300 Dec 29, 2022
300 Dec 29, 2022
Optimizing Deeper Transformers on Small Datasets
DT-Fixup Optimizing Deeper Transformers on Small Datasets Paper published in ACL 2021: arXiv Detailed instructions to replicate our results in the pap
 16 Nov 14, 2022
16 Nov 14, 2022
Official Pytorch Implementation of Length-Adaptive Transformer (ACL 2021)
Length-Adaptive Transformer This is the official Pytorch implementation of Length-Adaptive Transformer. For detailed information about the method, ple
 93 Dec 28, 2022
93 Dec 28, 2022
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022
PyTorch implementation of the ACL, 2021 paper Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks.
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks This repo contains the PyTorch implementation of the ACL, 2021 pa
 98 Dec 28, 2022
98 Dec 28, 2022
Media Replay Engine (MRE) is a framework to build automated video clipping and replay (highlight) generation pipelines for live and video-on-demand content.
Media Replay Engine (MRE) is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live
 30 Nov 29, 2022
30 Nov 29, 2022
Revisiting Temporal Alignment for Video Restoration
Revisiting Temporal Alignment for Video Restoration [arXiv] Kun Zhou, Wenbo Li, Liying Lu, Xiaoguang Han, Jiangbo Lu We provide our results at Google
 52 Dec 25, 2022
52 Dec 25, 2022
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning This is the official repository of "Camera Distortion-
 12 Oct 6, 2022
12 Oct 6, 2022

PySlowFast: video understanding codebase from FAIR for reproducing state-of-the-art video models.
PySlowFast PySlowFast is an open source video understanding codebase from FAIR that provides state-of-the-art video classification models with efficie
 5.3k Jan 3, 2023
5.3k Jan 3, 2023

Official implementation of Pixel-Level Bijective Matching for Video Object Segmentation
BMVOS This is the official implementation of Pixel-Level Bijective Matching for Video Object Segmentation, to appear in WACV 2022. @article{cho2021pix
 13 Dec 14, 2022
13 Dec 14, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Dec 14, 2022
4 Dec 14, 2022
This repository contains the implementation of the paper: Federated Distillation of Natural Language Understanding with Confident Sinkhorns
Federated Distillation of Natural Language Understanding with Confident Sinkhorns This repository provides an alternative method for ensembled distill
 11 Nov 16, 2022
11 Nov 16, 2022
Official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution"
RealBasicVSR [Paper] This is the official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution, arXiv". This repository contain
 566 Dec 28, 2022
566 Dec 28, 2022

Real-time VIBE: Frame by Frame Inference of VIBE (Video Inference for Human Body Pose and Shape Estimation)
Real-time VIBE Inference VIBE frame-by-frame. Overview This is a frame-by-frame inference fork of VIBE at [https://github.com/mkocabas/VIBE]. Usage: i
 23 Jul 2, 2022
23 Jul 2, 2022

Code for "ATISS: Autoregressive Transformers for Indoor Scene Synthesis", NeurIPS 2021
ATISS: Autoregressive Transformers for Indoor Scene Synthesis This repository contains the code that accompanies our paper ATISS: Autoregressive Trans
 138 Dec 22, 2022
138 Dec 22, 2022
Code from the 2021 Signal Video Superclass
Twilio Video Demo This is the code written during the live Twilio Video demo during Twilio's Signal 2021 Superclass. It creates a simple Video applica
 2 Oct 21, 2021
2 Oct 21, 2021
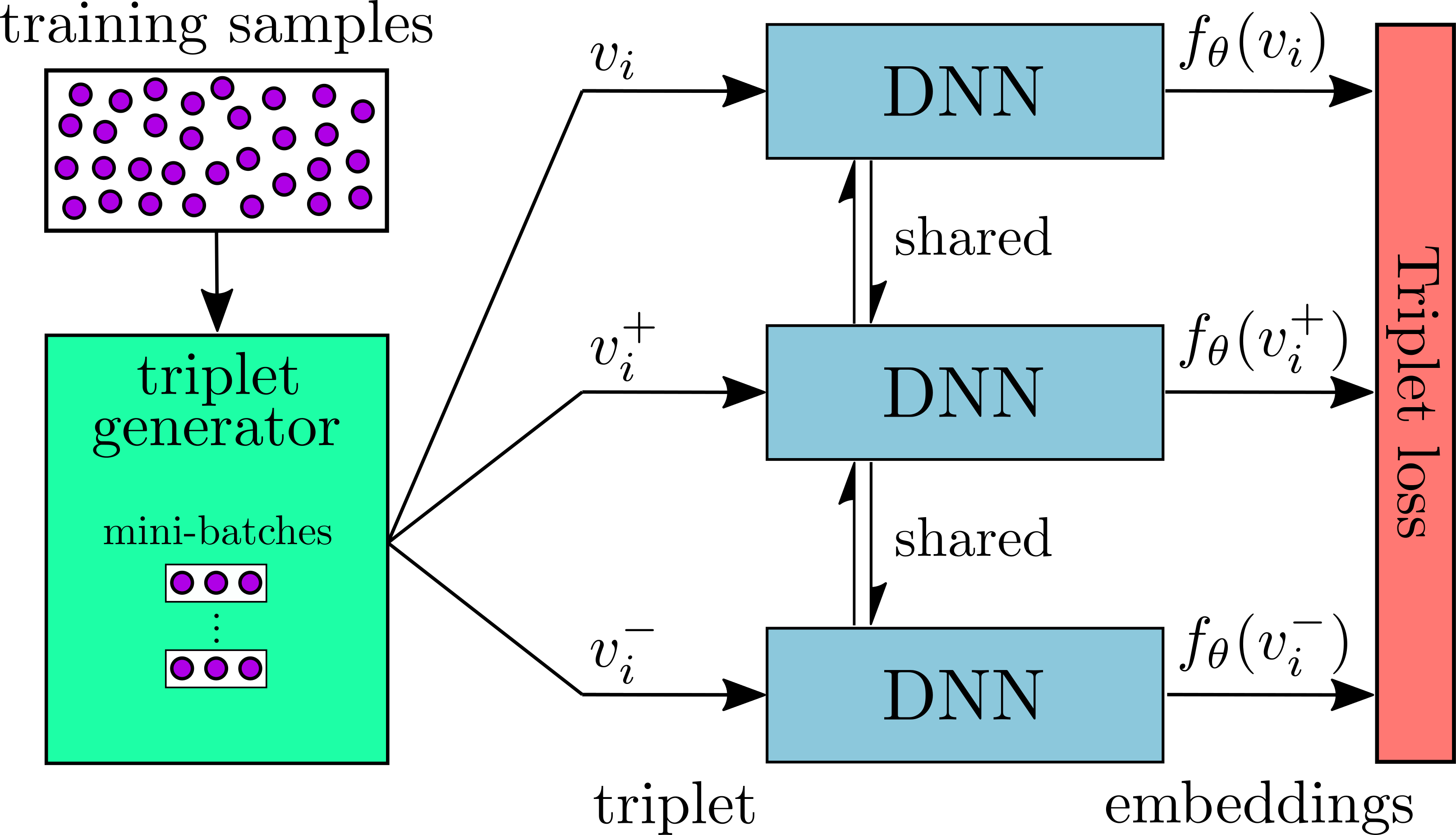
Near-Duplicate Video Retrieval with Deep Metric Learning
Near-Duplicate Video Retrieval with Deep Metric Learning This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retr
 2 Jan 24, 2022
2 Jan 24, 2022
This plugin generates json files used by deovr allowing you to play 2d and 3d video's using the player
deovr-plugin This plugin generates json files used by deovr allowing you to play 2d and 3d video's using the player. Deovr looks for an index file /de
 10 Sep 29, 2022
10 Sep 29, 2022
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
End-to-End Referring Video Object Segmentation with Multimodal Transformers
End-to-End Referring Video Object Segmentation with Multimodal Transformers This repo contains the official implementation of the paper: End-to-End Re
 608 Dec 30, 2022
608 Dec 30, 2022

Pre-Training 3D Point Cloud Transformers with Masked Point Modeling
Point-BERT: Pre-Training 3D Point Cloud Transformers with Masked Point Modeling Created by Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zho
 306 Jan 6, 2023
306 Jan 6, 2023

PyTorch code of paper "LiVLR: A Lightweight Visual-Linguistic Reasoning Framework for Video Question Answering"
LiVLR-VideoQA We propose a Lightweight Visual-Linguistic Reasoning framework (LiVLR) for VideoQA. The overview of LiVLR: Evaluation on MSRVTT-QA Datas
 7 Dec 30, 2022
7 Dec 30, 2022
🤖 Telegram UserBot Untuk Memutar Lagu Dan Video Di Obrolan Suara Telegram.
🤖 Telegram UserBot Untuk Memutar Lagu Dan Video Di Obrolan Suara Telegram.
 2 Nov 13, 2021
2 Nov 13, 2021
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats.
VC UserBot A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Python
 1 Nov 29, 2021
1 Nov 29, 2021
Code for our ICCV 2021 Paper "OadTR: Online Action Detection with Transformers".
Code for our ICCV 2021 Paper "OadTR: Online Action Detection with Transformers".
 66 Dec 15, 2022
66 Dec 15, 2022

Official Pytorch Code for the paper TransWeather
TransWeather Official Code for the paper TransWeather, Arxiv Tech Report 2021 Paper | Website About this repo: This repo hosts the implentation code,
 81 Dec 30, 2022
81 Dec 30, 2022

Fake videos detection by tracing the source using video hashing retrieval.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos 🎉️ 📜 Directory Introduction VTL Trace Samples and Acc of Hash
 56 Dec 22, 2022
56 Dec 22, 2022

✂️ EyeLipCropper is a Python tool to crop eyes and mouth ROIs of the given video.
EyeLipCropper EyeLipCropper is a Python tool to crop eyes and mouth ROIs of the given video. The whole process consists of three parts: frame extracti
 9 Oct 25, 2022
9 Oct 25, 2022
Telegram bot to stream videos in telegram voicechat for both groups and channels.
Telegram bot to stream videos in telegram voicechat for both groups and channels. Supports live streams, YouTube videos and telegram media. With record stream support, Schedule streams, and many more.
 4 Nov 13, 2022
4 Nov 13, 2022
Making a music video with Wav2CLIP and VQGAN-CLIP
music2video Overview A repo for making a music video with Wav2CLIP and VQGAN-CLIP. The base code was derived from VQGAN-CLIP The CLIP embedding for au
 163 Dec 26, 2022
163 Dec 26, 2022
Play Video & Music on Telegram Group Video Chat
🖤 DEMONGIRL 🖤 ʜᴇʟʟᴏ ❤️ 🇱🇰 Join us ᴠɪᴅᴇᴏ sᴛʀᴇᴀᴍ ɪs ᴀɴ ᴀᴅᴠᴀɴᴄᴇᴅ ᴛᴇʟᴇʀᴀᴍ ʙᴏᴛ ᴛʜᴀᴛ's ᴀʟʟᴏᴡ ʏᴏᴜ ᴛᴏ ᴘʟᴀʏ ᴠɪᴅᴇᴏ & ᴍᴜsɪᴄ ᴏɴ ᴛᴇʟᴇɢʀᴀᴍ ɢʀᴏᴜᴘ ᴠɪᴅᴇᴏ ᴄʜᴀᴛ 🧪 ɢ
 5 Dec 31, 2021
5 Dec 31, 2021
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
 799 Dec 28, 2022
799 Dec 28, 2022

Conversational text Analysis using various NLP techniques
PyConverse Let me try first Installation pip install pyconverse Usage Please try this notebook that demos the core functionalities: basic usage noteb
 158 Dec 25, 2022
158 Dec 25, 2022
alfred-py: A deep learning utility library for **human**
Alfred Alfred is command line tool for deep-learning usage. if you want split an video into image frames or combine frames into a single video, then a
 800 Jan 3, 2023
800 Jan 3, 2023

Deep Sketch-guided Cartoon Video Inbetweening
Cartoon Video Inbetweening Paper | DOI | Video The source code of Deep Sketch-guided Cartoon Video Inbetweening by Xiaoyu Li, Bo Zhang, Jing Liao, Ped
 37 Dec 22, 2022
37 Dec 22, 2022
Package to compute Mauve, a similarity score between neural text and human text. Install with `pip install mauve-text`.
MAUVE MAUVE is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the eponymous MAUVE
 182 Jan 2, 2023
182 Jan 2, 2023

Make differentially private training of transformers easy for everyone
private-transformers This codebase facilitates fast experimentation of differentially private training of Hugging Face transformers. What is this? Why
 73 Dec 28, 2022
73 Dec 28, 2022
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
 105 Jan 8, 2022
105 Jan 8, 2022
![Deep Video Matting via Spatio-Temporal Alignment and Aggregation [CVPR2021]](https://github.com/nowsyn/DVM/raw/master/figures/framework.png)
Deep Video Matting via Spatio-Temporal Alignment and Aggregation [CVPR2021]
Deep Video Matting via Spatio-Temporal Alignment and Aggregation [CVPR2021] Paper: https://arxiv.org/abs/2104.11208 Introduction Despite the significa
 76 Dec 7, 2022
76 Dec 7, 2022
Simple nightcore song+video maker
nighty nighty is a simple nightcore song maker (+ video) Installation clone the repo wherever you want git clone https://www.github.com/DanyB0/nighty
 2 Oct 2, 2022
2 Oct 2, 2022
Convert Video Files To Text And Audio
Video-To-Text Convert Video Files To Text And Audio Convert To Audio 1: open dvtt folder in cmd 2: run this command in cmd = main.py Audio Convert To
 2 Dec 5, 2021
2 Dec 5, 2021

720p FPGA Media Player (RISC-V + Motion JPEG + SD + HDMI on an Artix 7)
FPGA Media Player This project is a FPGA based media player which is capable of playing Motion JPEG encoded video over HDMI or VGA on commonly availab
 179 Dec 2, 2022
179 Dec 2, 2022
Revisiting Video Saliency: A Large-scale Benchmark and a New Model (CVPR18, PAMI19)
DHF1K =========================================================================== Wenguan Wang, J. Shen, M.-M Cheng and A. Borji, Revisiting Video Sal
 126 Dec 3, 2022
126 Dec 3, 2022

Spectralformer: Rethinking hyperspectral image classification with transformers
Spectralformer: Rethinking hyperspectral image classification with transformers Danfeng Hong, Zhu Han, Jing Yao, Lianru Gao, Bing Zhang, Antonio Plaza
 102 Dec 29, 2022
102 Dec 29, 2022

Source files for the data lake demo video using the AWS TICKIT database
Data Lake Demo Source code for video demonstration detailed in the post, Building a Simple Data Lake on AWS . Build a simple data lake on AWS using a
 97 Dec 23, 2022
97 Dec 23, 2022

Automated question generation and question answering from Turkish texts using text-to-text transformers
Turkish Question Generation Offical source code for "Automated question generation & question answering from Turkish texts using text-to-text transfor
 29 Dec 14, 2022
29 Dec 14, 2022

Tandem Mass Spectrum Prediction with Graph Transformers
MassFormer This is the original implementation of MassFormer, a graph transformer for small molecule MS/MS prediction. Check out the preprint on arxiv
 13 Oct 27, 2022
13 Oct 27, 2022
Self-Regulated Learning for Egocentric Video Activity Anticipation
Self-Regulated Learning for Egocentric Video Activity Anticipation Introduction This is a Pytorch implementation of the model described in our paper:
 13 Sep 23, 2022
13 Sep 23, 2022
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis This is a PyTorch implementation of the model described in our pape
6 Jul 8, 2021

Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes
Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized C
 139 Jan 4, 2023
139 Jan 4, 2023
Official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution"
RealBasicVSR [Paper] This is the official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution, arXiv". This repository contain
566 Dec 28, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 1 Mar 8, 2022
1 Mar 8, 2022
CLIPImageClassifier wraps clip image model from transformers
CLIPImageClassifier CLIPImageClassifier wraps clip image model from transformers. CLIPImageClassifier is initialized with the argument classes, these
 6 Sep 12, 2022
6 Sep 12, 2022
OpenMMLab Video Perception Toolbox. It supports Video Object Detection (VID), Multiple Object Tracking (MOT), Single Object Tracking (SOT), Video Instance Segmentation (VIS) with a unified framework.
English | 简体中文 Documentation: https://mmtracking.readthedocs.io/ Introduction MMTracking is an open source video perception toolbox based on PyTorch.
 2.7k Jan 8, 2023
2.7k Jan 8, 2023
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
Use fastai-v2 with HuggingFace's pretrained transformers
FastHugs Use fastai v2 with HuggingFace's pretrained transformers, see the notebooks below depending on your task: Text classification: fasthugs_seq_c
 111 Nov 16, 2022
111 Nov 16, 2022