1191 Repositories
Python video-transformers Libraries

Python package to display video in GUI using OpenCV-Python and PySide6
Python package to display video in GUI using OpenCV-Python and PySide6. Introduction cv2PySide6 is a package which provides utility classes and functi
 3 Jun 6, 2022
3 Jun 6, 2022
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
 6 Jun 20, 2022
6 Jun 20, 2022
Telegram music & video bot direct play music
Telegram music & video bot direct play music
 1 Dec 28, 2021
1 Dec 28, 2021
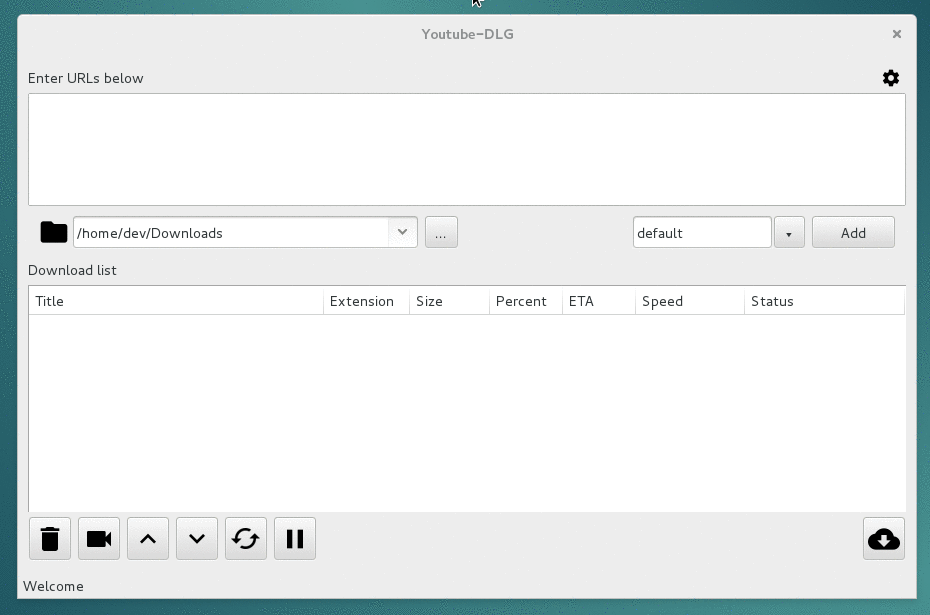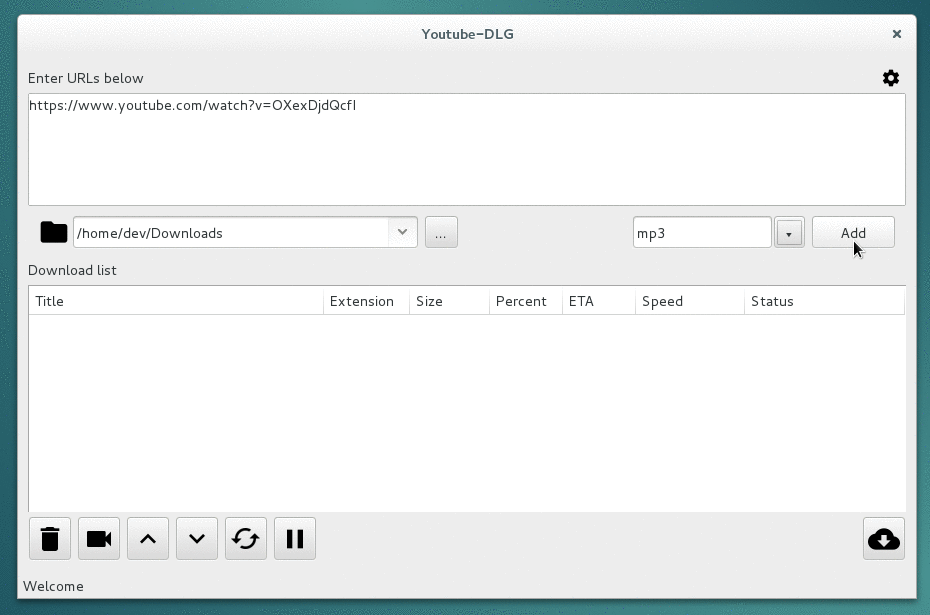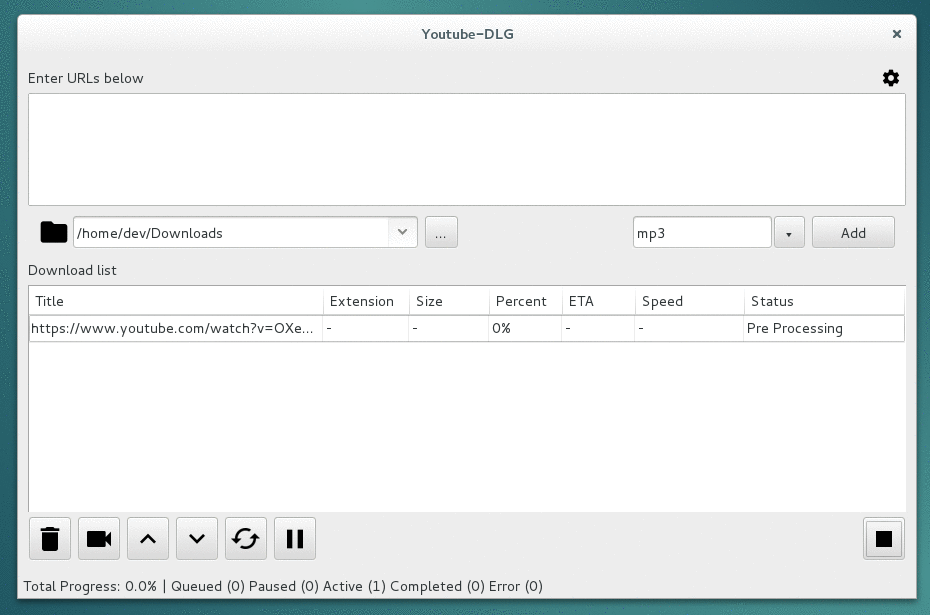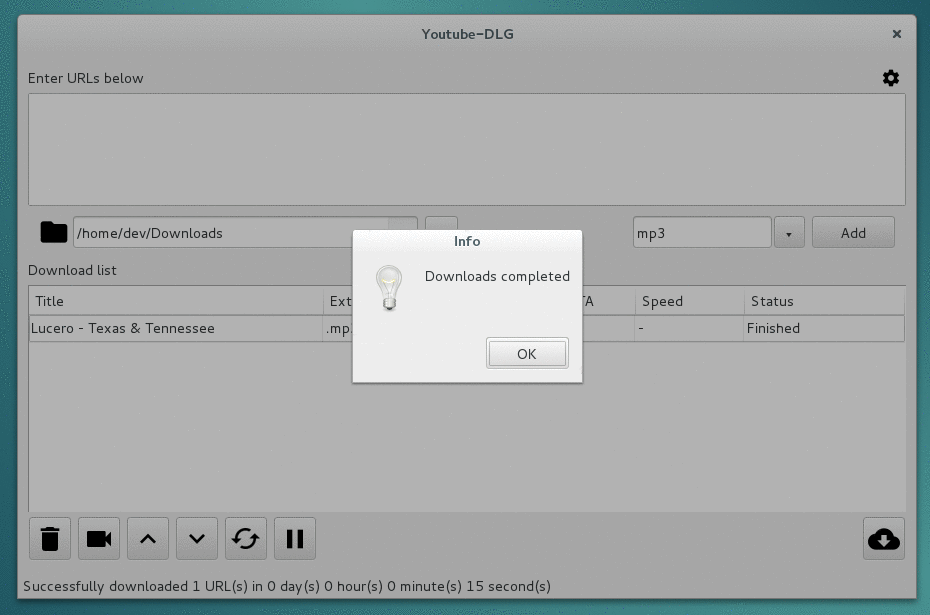
A cross platform front-end GUI of the popular youtube-dl written in wxPython.
youtube-dlG A cross platform front-end GUI of the popular youtube-dl media downloader written in wxPython. Supported sites Screenshots Requirements Py
 8.7k Dec 31, 2022
8.7k Dec 31, 2022

XViT - Space-time Mixing Attention for Video Transformer
XViT - Space-time Mixing Attention for Video Transformer This is the official implementation of the XViT paper: @inproceedings{bulat2021space, title
 33 Dec 23, 2022
33 Dec 23, 2022
A curated list of the latest breakthroughs in AI (in 2021) by release date with a clear video explanation, link to a more in-depth article, and code.
2021: A Year Full of Amazing AI papers- A Review 📌 A curated list of the latest breakthroughs in AI by release date with a clear video explanation, l
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio.
YouTube-Downloader Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio. G
 2 Dec 27, 2021
2 Dec 27, 2021

FingerPy is a algorithm to measure, analyse and monitor heart-beat using only a video of the user's finger on a mobile cellphone camera.
FingerPy is a algorithm using python, scipy and fft to measure, analyse and monitor heart-beat using only a video of the user's finger on a m
 37 Oct 21, 2022
37 Oct 21, 2022
Utilize Korean BERT model in sentence-transformers library
ko-sentence-transformers 이 프로젝트는 KoBERT 모델을 sentence-transformers 에서 보다 쉽게 사용하기 위해 만들어졌습니다. Ko-Sentence-BERT-SKTBERT 프로젝트에서는 KoBERT 모델을 sentence-trans
 40 Dec 20, 2022
40 Dec 20, 2022
python based bot Sends notification to your telegram whenever a new video is released on a youtube channel!
YTnotifier python based bot Sends notification to your telegram whenever a new video is released on a youtube channel! REQUIREMENTS telethon python-de
 6 Jul 23, 2022
6 Jul 23, 2022
Breaking Shortcut: Exploring Fully Convolutional Cycle-Consistency for Video Correspondence Learning
Breaking Shortcut: Exploring Fully Convolutional Cycle-Consistency for Video Correspondence Learning Yansong Tang *, Zhenyu Jiang *, Zhenda Xie *, Yue
 12 Nov 16, 2022
12 Nov 16, 2022
PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.
ALiBi PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. Quickstart Clone this reposit
 4 Jul 27, 2022
4 Jul 27, 2022
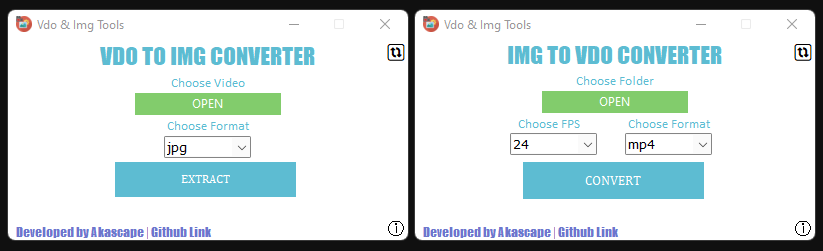
An easy to use GUI based video to image sequence converter (and vice versa).
Vdo & Img Conversion Tools This is a quick conversion tool made with python that can save you a lot of time. With this tool you can extract image sequ
 3 Sep 18, 2022
3 Sep 18, 2022

Traditional deepdream with VQGAN+CLIP and optical flow. Ready to use in Google Colab
VQGAN-CLIP-Video cat.mp4 policeman.mp4 schoolboy.mp4 forsenBOG.mp4
 23 Oct 26, 2022
23 Oct 26, 2022
jiant is an NLP toolkit
🚨 Update 🚨 : As of 2021/10/17, the jiant project is no longer being actively maintained. This means there will be no plans to add new models, tasks,
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
Telegram bot for stream music or video on telegram
KYURA MUSIC Telegram bot for stream music or video on telegram, powered by PyTgCalls and Pyrogram Help Need Help me to translate this repo, click the
 0 Dec 8, 2022
0 Dec 8, 2022
SeMask: Semantically Masked Transformers for Semantic Segmentation.
SeMask: Semantically Masked Transformers Jitesh Jain, Anukriti Singh, Nikita Orlov, Zilong Huang, Jiachen Li, Steven Walton, Humphrey Shi This repo co
 186 Dec 30, 2022
186 Dec 30, 2022

Codes for the paper Contrast and Mix: Temporal Contrastive Video Domain Adaptation with Background Mixing
Contrast and Mix (CoMix) The repository contains the codes for the paper Contrast and Mix: Temporal Contrastive Video Domain Adaptation with Backgroun
 13 Dec 10, 2022
13 Dec 10, 2022
Code implementation from my Medium blog post: [Transformers from Scratch in PyTorch]
transformer-from-scratch Code for my Medium blog post: Transformers from Scratch in PyTorch Note: This Transformer code does not include masked attent
 27 Dec 21, 2022
27 Dec 21, 2022
Automatically segment in-video YouTube sponsorships.
SponsorBlock Auto Segment [Model Download] Automatically segment in-video YouTube sponsorships. Trained on a large dataset of YouTube sponsor transcri
 7 Aug 22, 2022
7 Aug 22, 2022
🐥Flappy Birds🐤 Video game. With your help I can go through🚀 the pipes. All UI is made with 🐍Pygame🐍
🐠 Flappy Fish 🐢 I am Flappy Fish 🐟 . With your help I can jump through the pipes and experience an interesting and exciting flight deep into the fi
 2 Jan 14, 2022
2 Jan 14, 2022
Create a Video Membership app using FastAPI & NoSQL
Video Membership Create a Video Membership app using FastAPI & NoSQL. In this series, we're going to explore building a membership application using F
 69 Dec 25, 2022
69 Dec 25, 2022

Turn any live video stream or locally stored video into a dataset of interesting samples for ML training, or any other type of analysis.
Sieve Video Data Collection Example Find samples that are interesting within hours of raw video, for free and completely automatically using Sieve API
 72 Aug 1, 2022
72 Aug 1, 2022

A Simple YouTube Video Downloader With Python
Simple YouTube Video Downloader Simple YouTube Video Downloader is an open source project with a very simple UI that tries to speed up the process of
 2 Jan 3, 2022
2 Jan 3, 2022

PyTorch implementation of Super SloMo by Jiang et al.
Super-SloMo PyTorch implementation of "Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation" by Jiang H., Sun
 2.9k Jan 3, 2023
2.9k Jan 3, 2023

Official repository for "Deep Recurrent Neural Network with Multi-scale Bi-directional Propagation for Video Deblurring".
RNN-MBP Deep Recurrent Neural Network with Multi-scale Bi-directional Propagation for Video Deblurring (AAAI-2022) by Chao Zhu, Hang Dong, Jinshan Pan
 22 Aug 31, 2022
22 Aug 31, 2022

⛵️The official PyTorch implementation for "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing" (EMNLP 2020).
BERT-of-Theseus Code for paper "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing". BERT-of-Theseus is a new compressed BERT by progre
 284 Nov 25, 2022
284 Nov 25, 2022
The code for paper "Contrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation" which is accepted by AAAI 2022
Contrastive Spatio Temporal Pretext Learning for Self-supervised Video Representation (AAAI 2022) The code for paper "Contrastive Spatio-Temporal Pret
 8 Jun 30, 2022
8 Jun 30, 2022
Video Stream: an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat
Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat 🧪 Get SESSION_NAME from below: Pyrogram
 6 Feb 8, 2022
6 Feb 8, 2022
Скрипт который выводит видео в консоль. Ничего лишнего)
video-to-ascii Скрипт который выводит видео в консоль. Ничего лишнего) Требования Минимальное разрешение экрана: 1280x720 Видео в качестве 360p 10-45f
 155 Nov 28, 2022
155 Nov 28, 2022

A quick recipe to learn all about Transformers
Transformers have accelerated the development of new techniques and models for natural language processing (NLP) tasks.
 772 Dec 31, 2022
772 Dec 31, 2022
A Telegram bot to transcribe audio, video and image into text.
Transcriber Bot A Telegram bot to transcribe audio, video and image into text. Deploy to Heroku Local Deploying Install the FFmpeg. Make sure you have
 10 Dec 19, 2022
10 Dec 19, 2022
An Telegram Bot By @ZauteKm To Stream Videos In Telegram Voice Chat Of Both Groups & Channels. Supports Live Streams, YouTube Videos & Telegram Media !!
Telegram Video Stream Bot (Py-TgCalls) An Telegram Bot By @ZauteKm To Stream Videos In Telegram Voice Chat Of Both Groups & Channels. Supports Live St
 14 Oct 21, 2022
14 Oct 21, 2022
Convert human motion from video to .bvh
video_to_bvh Convert human motion from video to .bvh with Google Colab Usage 1. Open video_to_bvh.ipynb in Google Colab Go to https://colab.research.g
 306 Dec 10, 2022
306 Dec 10, 2022

Efficient 3D human pose estimation in video using 2D keypoint trajectories
3D human pose estimation in video with temporal convolutions and semi-supervised training This is the implementation of the approach described in the
 3.1k Dec 29, 2022
3.1k Dec 29, 2022

Yuno is context based search engine for anime.
Yuno yuno.mp4 Table of Contents Introduction Power Of Yuno Try Yuno How Yuno was created? References Introduction Yuno is a context based search engin
 354 Dec 19, 2022
354 Dec 19, 2022
A python program to download one or multiple videos from YouTube.
YouTube-Video-Downloader A python program to download one or multiple videos from YouTube. Quick Start guide First Clone The Project git clone https:/
 1 Sep 11, 2022
1 Sep 11, 2022
Spatio-Temporal Entropy Model (STEM) for end-to-end leaned video compression.
Spatio-Temporal Entropy Model A Pytorch Reproduction of Spatio-Temporal Entropy Model (STEM) for end-to-end leaned video compression. More details can
 16 Nov 28, 2022
16 Nov 28, 2022
Automatically remove the mosaics in images and videos, or add mosaics to them.
Automatically remove the mosaics in images and videos, or add mosaics to them.
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
![[ICCV 2021] Target Adaptive Context Aggregation for Video Scene Graph Generation](https://github.com/MCG-NJU/TRACE/raw/main/gt_vidvrd.png)
[ICCV 2021] Target Adaptive Context Aggregation for Video Scene Graph Generation
Target Adaptive Context Aggregation for Video Scene Graph Generation This is a PyTorch implementation for Target Adaptive Context Aggregation for Vide
 44 Dec 14, 2022
44 Dec 14, 2022

Code for the ICCV'21 paper "Context-aware Scene Graph Generation with Seq2Seq Transformers"
ICCV'21 Context-aware Scene Graph Generation with Seq2Seq Transformers Authors: Yichao Lu*, Himanshu Rai*, Cheng Chang*, Boris Knyazev†, Guangwei Yu,
 37 Dec 18, 2022
37 Dec 18, 2022
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding Official Pytorch implementation of Negative Sample Matter
69 Dec 26, 2022

Code for "Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose"
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose We provide PyTorch implementations for our arxiv paper "Audio-dr
 497 Jan 9, 2023
497 Jan 9, 2023
AudioDVP:Photorealistic Audio-driven Video Portraits
AudioDVP This is the official implementation of Photorealistic Audio-driven Video Portraits. Major Requirements Ubuntu = 18.04 PyTorch = 1.2 GCC =
 232 Jan 3, 2023
232 Jan 3, 2023
This is the official PyTorch implementation of the CVPR 2020 paper "TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting".
TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting Project Page | YouTube | Paper This is the official PyTorch implementation of the C
 330 Dec 11, 2022
330 Dec 11, 2022
pyYotubemanager is full web automated bot capable of General tasks like:- Uploading a Video , Downloading , adding Title , Description , Listing types , adding Thumbnail
PyYoutubemanager Explore the docs » View Demo · Report Bug · Request Feature About The Project PyYotubemanager is full web automated bot capable of Ge
 4 Jun 29, 2022
4 Jun 29, 2022

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022

Wonkey - an open source programming language for the creation of cross-platform video games
Wonkey Programming Language Wonkey is an open source programming language for the creation of cross-platform video games, highly inspired by the “Blit
 110 Nov 9, 2022
110 Nov 9, 2022
Model parallel transformers in JAX and Haiku
Table of contents Mesh Transformer JAX Updates Pretrained Models GPT-J-6B Links Acknowledgments License Model Details Zero-Shot Evaluations Architectu
 4.9k Jan 4, 2023
4.9k Jan 4, 2023
GANformer: Generative Adversarial Transformers
GANformer: Generative Adversarial Transformers Drew A. Hudson* & C. Lawrence Zitnick Update: We released the new GANformer2 paper! *I wish to thank Ch
 1k Dec 16, 2021
1k Dec 16, 2021
The code for the Subformer, from the EMNLP 2021 Findings paper: "Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers", by Machel Reid, Edison Marrese-Taylor, and Yutaka Matsuo
Subformer This repository contains the code for the Subformer. To help overcome this we propose the Subformer, allowing us to retain performance while
 10 Dec 27, 2022
10 Dec 27, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022

Sinkhorn Transformer - Practical implementation of Sparse Sinkhorn Attention
Sinkhorn Transformer This is a reproduction of the work outlined in Sparse Sinkhorn Attention, with additional enhancements. It includes a parameteriz
 217 Nov 25, 2022
217 Nov 25, 2022

DeLighT: Very Deep and Light-Weight Transformers
DeLighT: Very Deep and Light-weight Transformers This repository contains the source code of our work on building efficient sequence models: DeFINE (I
 440 Dec 18, 2022
440 Dec 18, 2022
This repository contains the code for running the character-level Sandwich Transformers from our ACL 2020 paper on Improving Transformer Models by Reordering their Sublayers.
Improving Transformer Models by Reordering their Sublayers This repository contains the code for running the character-level Sandwich Transformers fro
 53 Sep 26, 2022
53 Sep 26, 2022
Examples of using sparse attention, as in "Generating Long Sequences with Sparse Transformers"
Status: Archive (code is provided as-is, no updates expected) Update August 2020: For an example repository that achieves state-of-the-art modeling pe
 1.3k Dec 28, 2022
1.3k Dec 28, 2022
An implementation of model parallel GPT-2 and GPT-3-style models using the mesh-tensorflow library.
GPT Neo 🎉 1T or bust my dudes 🎉 An implementation of model & data parallel GPT3-like models using the mesh-tensorflow library. If you're just here t
 6.7k Dec 28, 2022
6.7k Dec 28, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Jul 30, 2022
4 Jul 30, 2022
A self-hosted streaming platform with Discord authentication, auto-recording and more!
A self-hosted streaming platform with Discord authentication, auto-recording and more!
 331 Dec 27, 2022
331 Dec 27, 2022

SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation
SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation SeqFormer SeqFormer: a Frustratingly Simple Model for Video Instance Segmentat
 298 Dec 22, 2022
298 Dec 22, 2022

👻🟡 Download all Snapchat video & photo memories from a data export.
Snapchat "Memories" Fetcher In compliance with the California Consumer Privacy Act of 2018 (“CCPA”), businesses which collect and store user data must
 18 Dec 26, 2022
18 Dec 26, 2022

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

Powerful unsupervised domain adaptation method for dense retrieval.
Powerful unsupervised domain adaptation method for dense retrieval
 191 Dec 28, 2022
191 Dec 28, 2022
Dynamic View Synthesis from Dynamic Monocular Video
Dynamic View Synthesis from Dynamic Monocular Video Project Website | Video | Paper Dynamic View Synthesis from Dynamic Monocular Video Chen Gao, Ayus
 139 Dec 28, 2022
139 Dec 28, 2022
Official Pytorch implementation for Deep Contextual Video Compression, NeurIPS 2021
Introduction Official Pytorch implementation for Deep Contextual Video Compression, NeurIPS 2021 Prerequisites Python 3.8 and conda, get Conda CUDA 11
 51 Dec 3, 2022
51 Dec 3, 2022

YouTube Video Search Engine For Python
YouTube-Video-Search-Engine Introduction With the increasing demand for electronic devices, it is hard for people to choose the best products from mul
 1 Dec 21, 2021
1 Dec 21, 2021

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
keytotext Idea is to build a model which will take keywords as inputs and generate sentences as outputs. Potential use case can include: Marketing Sea
 364 Jan 3, 2023
364 Jan 3, 2023
Video Matting Refinement For Python
Video-matting refinement Library (use pip to install) scikit-image numpy av matplotlib Run Static background python path_to_video.mp4 Moving backgroun
 3 Jan 11, 2022
3 Jan 11, 2022
Dynamic View Synthesis from Dynamic Monocular Video
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer This repository contains code to compute depth from a
 2.3k Jan 1, 2023
2.3k Jan 1, 2023
A repository with exploration into using transformers to predict DNA ↔ transcription factor binding
Transcription Factor binding predictions with Attention and Transformers A repository with exploration into using transformers to predict DNA ↔ transc
62 Dec 20, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022
nextdl - download videos from youtube.com or other video platforms
nextdl - download videos from youtube.com or other video platforms
 3 Feb 2, 2022
3 Feb 2, 2022
Rune - a video miniplayer made with Python.
Rune - a video miniplayer made with Python.
 1 Dec 13, 2021
1 Dec 13, 2021

(Preprint) Official PyTorch implementation of "How Do Vision Transformers Work?"
(Preprint) Official PyTorch implementation of "How Do Vision Transformers Work?"
 656 Dec 30, 2022
656 Dec 30, 2022
PyTorch implementation of a collections of scalable Video Transformer Benchmarks.
PyTorch implementation of Video Transformer Benchmarks This repository is mainly built upon Pytorch and Pytorch-Lightning. We wish to maintain a colle
 156 Jan 8, 2023
156 Jan 8, 2023
Easy Language Model Pretraining leveraging Huggingface's Transformers and Datasets
Easy Language Model Pretraining leveraging Huggingface's Transformers and Datasets What is LASSL • How to Use What is LASSL LASSL은 LAnguage Semi-Super
 116 Dec 27, 2022
116 Dec 27, 2022
Pangu-Alpha for Transformers
Pangu-Alpha for Transformers Usage Download MindSpore FP32 weights for GPU from here to data/Pangu-alpha_2.6B.ckpt Activate MindSpore environment and
 5 Oct 1, 2022
5 Oct 1, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021
![[NeurIPS 2021]: Are Transformers More Robust Than CNNs? (Pytorch implementation & checkpoints)](https://github.com/ytongbai/ViTs-vs-CNNs/raw/main/resources/teaser.png)
[NeurIPS 2021]: Are Transformers More Robust Than CNNs? (Pytorch implementation & checkpoints)
Are Transformers More Robust Than CNNs? Pytorch implementation for NeurIPS 2021 Paper: Are Transformers More Robust Than CNNs? Our implementation is b
 145 Dec 1, 2022
145 Dec 1, 2022
Simple VLC-based media player that can play multiple videos at the same time
Screenshots About Simple VLC-based media player that can play multiple videos at the same time. You can play as many videos as you like, the only limi
 161 Jan 5, 2023
161 Jan 5, 2023

2D Human Pose estimation using transformers. Implementation in Pytorch
PE-former: Pose Estimation Transformer Vision transformer architectures perform very well for image classification tasks. Efforts to solve more challe
 23 Oct 17, 2022
23 Oct 17, 2022

A new video text spotting framework with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
67 Jan 3, 2023
Experiments and examples converting Transformers to ONNX
Experiments and examples converting Transformers to ONNX This repository containes experiments and examples on converting different Transformers to ON
 4 Dec 24, 2022
4 Dec 24, 2022
Contrastive Learning of Image Representations with Cross-Video Cycle-Consistency
Contrastive Learning of Image Representations with Cross-Video Cycle-Consistency This is a official implementation of the CycleContrast introduced in
 13 Nov 14, 2022
13 Nov 14, 2022

Official Code for VideoLT: Large-scale Long-tailed Video Recognition (ICCV 2021)
Pytorch Code for VideoLT [Website][Paper] Updates [10/29/2021] Features uploaded to Google Drive, for access please send us an e-mail: zhangxing18 at
 26 Sep 18, 2022
26 Sep 18, 2022

State-of-the-art NLP through transformer models in a modular design and consistent APIs.
Trapper (Transformers wRAPPER) Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps h
 42 Sep 21, 2022
42 Sep 21, 2022
An API that allows you to get full information about TikTok videos
TikTok-API An API that allows you to get full information about TikTok videos without using any third party sources and only the TikTok API. ##API onl
 13 Dec 20, 2021
13 Dec 20, 2021

Video Translation Into Text
2021/12/9 The project has been updated Added a home screen Just drag it onto the screen The final results \ 2021/12/9 项目已更新 添加了主界面 拖到即可 最后结果 \ Using t
 10 Mar 12, 2022
10 Mar 12, 2022

ViSER: Video-Specific Surface Embeddings for Articulated 3D Shape Reconstruction
ViSER: Video-Specific Surface Embeddings for Articulated 3D Shape Reconstruction. NeurIPS 2021.
 59 Nov 25, 2022
59 Nov 25, 2022
Fast and Context-Aware Framework for Space-Time Video Super-Resolution (VCIP 2021)
Fast and Context-Aware Framework for Space-Time Video Super-Resolution Preparation Dependencies PyTorch 1.2.0 CUDA 10.0 DCNv2 cd model/DCNv2 bash make
 1 Mar 29, 2022
1 Mar 29, 2022

Hashformers is a framework for hashtag segmentation with transformers.
Hashtag segmentation is the task of automatically inserting the missing spaces between the words in a hashtag. Hashformers applies Transformer models
 41 Nov 9, 2022
41 Nov 9, 2022

Implementation of paper "Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal"
Patch-wise Adversarial Removal Implementation of paper "Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal
 4 Oct 12, 2022
4 Oct 12, 2022
Godot RL Agents is a fully Open Source packages that allows video game creators
Godot RL Agents The Godot RL Agents is a fully Open Source packages that allows video game creators, AI researchers and hobbiest the opportunity to le
 326 Dec 30, 2022
326 Dec 30, 2022
![[AAAI2022] Source code for our paper《Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning》](https://github.com/mettyz/SSVC/raw/main/asset/sample.gif)
[AAAI2022] Source code for our paper《Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning》
SSVC The source code for paper [Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning] samples of the
 7 Oct 26, 2022
7 Oct 26, 2022
Post-Training Quantization for Vision transformers.
PTQ4ViT Post-Training Quantization Framework for Vision Transformers. We use the twin uniform quantization method to reduce the quantization error on
 61 Dec 28, 2022
61 Dec 28, 2022
![[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining](https://github.com/microsoft/COCO-LM/raw/main/coco-lm.png)
[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
COCO-LM This repository contains the scripts for fine-tuning COCO-LM pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: COCO-LM: Correcting an
 106 Dec 12, 2022
106 Dec 12, 2022

This is a re-implementation of TransGAN: Two Pure Transformers Can Make One Strong GAN (CVPR 2021) in PyTorch.
TransGAN: Two Transformers Can Make One Strong GAN [YouTube Video] Paper Authors: Yifan Jiang, Shiyu Chang, Zhangyang Wang CVPR 2021 This is re-implem
 79 Jan 5, 2023
79 Jan 5, 2023
![[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation](https://user-images.githubusercontent.com/65257938/145016835-3c4be820-c55d-4eb4-b7f5-b8a012ee0f8c.png)
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
 2 Dec 7, 2021
2 Dec 7, 2021