424 Repositories
Python visual-question-answering Libraries

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022
This is the code for CVPR 2021 oral paper: Jigsaw Clustering for Unsupervised Visual Representation Learning
JigsawClustering Jigsaw Clustering for Unsupervised Visual Representation Learning Pengguang Chen, Shu Liu, Jiaya Jia Introduction This project provid
 73 Sep 18, 2022
73 Sep 18, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs
PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs This code aims to reproduce results obtained in the paper "Visual F
 93 Aug 17, 2022
93 Aug 17, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

This is the official implementation of "One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval".
CORA This is the official implementation of the following paper: Akari Asai, Xinyan Yu, Jungo Kasai and Hannaneh Hajishirzi. One Question Answering Mo
 59 Dec 28, 2022
59 Dec 28, 2022

source code of “Visual Saliency Transformer” (ICCV2021)
Visual Saliency Transformer (VST) source code for our ICCV 2021 paper “Visual Saliency Transformer” by Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, an
 89 Dec 21, 2022
89 Dec 21, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

URIE: Universal Image Enhancementfor Visual Recognition in the Wild
URIE: Universal Image Enhancementfor Visual Recognition in the Wild This is the implementation of the paper "URIE: Universal Image Enhancement for Vis
 43 Sep 12, 2022
43 Sep 12, 2022
Pytorch implementation for the EMNLP 2020 (Findings) paper: Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering
Path-Generator-QA This is a Pytorch implementation for the EMNLP 2020 (Findings) paper: Connecting the Dots: A Knowledgeable Path Generator for Common
 33 Dec 5, 2022
33 Dec 5, 2022
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022
![[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts](https://github.com/gyhandy/Visual-Reasoning-eXplanation/raw/main/docs/Fig-1.png)
[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
Visual-Reasoning-eXplanation [CVPR 2021 A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts] Project Page | Vid
 54 Dec 21, 2022
54 Dec 21, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 286 Jan 2, 2023
286 Jan 2, 2023

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
 564 Jan 3, 2023
564 Jan 3, 2023

Code for "Learning Canonical Representations for Scene Graph to Image Generation", Herzig & Bar et al., ECCV2020
Learning Canonical Representations for Scene Graph to Image Generation (ECCV 2020) Roei Herzig*, Amir Bar*, Huijuan Xu, Gal Chechik, Trevor Darrell, A
 24 Jul 7, 2022
24 Jul 7, 2022
![[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.](https://github.com/svip-lab/LBYLNet/raw/main/imgs/landmarks.png)
[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.
LBYL-Net This repo implements paper Look Before You Leap: Learning Landmark Features For One-Stage Visual Grounding CVPR 2021. Getting Started Prerequ
 45 Dec 12, 2022
45 Dec 12, 2022

VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation
VID-Fusion VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation Authors: Ziming Ding , Tiankai Yang, Kunyi Zhan
 86 Nov 18, 2022
86 Nov 18, 2022
Localizing Visual Sounds the Hard Way
Localizing-Visual-Sounds-the-Hard-Way Code and Dataset for "Localizing Visual Sounds the Hard Way". The repo contains code and our pre-trained model.
 58 Dec 7, 2022
58 Dec 7, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022

Visual Weather api. Returns beautiful pictures with the current weather.
VWapi Visual Weather api. Returns beautiful pictures with the current weather. Installation: sudo apt update -y && sudo apt upgrade -y sudo apt instal
 33 Nov 13, 2022
33 Nov 13, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022
PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Representation
How to Reproduce our Results This repository contains PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Represen
 46 Dec 15, 2022
46 Dec 15, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022

Code for the RA-L (ICRA) 2021 paper "SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition"
SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition [ArXiv+Supplementary] [IEEE Xplore RA-L 2021] [ICRA 2021 YouTube Video]
 63 Dec 12, 2022
63 Dec 12, 2022

JittorVis - Visual understanding of deep learning model.
JittorVis is a deep neural network computational graph visualization library based on Jittor.
 182 Jan 6, 2023
182 Jan 6, 2023

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022

뉴스 도메인 질의응답 시스템 (21-1학기 졸업 프로젝트)
뉴스 도메인 질의응답 시스템 본 프로젝트는 뉴스기사에 대한 질의응답 서비스 를 제공하기 위해서 진행한 프로젝트입니다. 약 3개월간 ( 21. 03 ~ 21. 05 ) 진행하였으며 Transformer 아키텍쳐 기반의 Encoder를 사용하여 한국어 질의응답 데이터셋으로
 4 Jul 8, 2022
4 Jul 8, 2022
Code for papers "Generation-Augmented Retrieval for Open-Domain Question Answering" and "Reader-Guided Passage Reranking for Open-Domain Question Answering", ACL 2021
This repo provides the code of the following papers: (GAR) "Generation-Augmented Retrieval for Open-domain Question Answering", ACL 2021 (RIDER) "Read
 49 Dec 26, 2022
49 Dec 26, 2022
The official implementation for ACL 2021 "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval".
Code for "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval" (ACL 2021, Long) This is the repository for baseline m
25 Oct 30, 2022
![Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]](https://github.com/wvangansbeke/Revisiting-Contrastive-SSL/raw/main/images/teaser.jpg)
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations This repo contains the Pytorch implementation of our paper: Revisit
 80 Nov 20, 2022
80 Nov 20, 2022
Baseline code for Korean open domain question answering(ODQA)
Open-Domain Question Answering(ODQA)는 다양한 주제에 대한 문서 집합으로부터 자연어 질의에 대한 답변을 찾아오는 task입니다. 이때 사용자 질의에 답변하기 위해 주어지는 지문이 따로 존재하지 않습니다. 따라서 사전에 구축되어있는 Knowl
 69 Nov 4, 2022
69 Nov 4, 2022
FeTaQA: Free-form Table Question Answering
FeTaQA: Free-form Table Question Answering FeTaQA is a Free-form Table Question Answering dataset with 10K Wikipedia-based {table, question, free-form
 40 Dec 13, 2022
40 Dec 13, 2022

Keep CALM and Improve Visual Feature Attribution
Keep CALM and Improve Visual Feature Attribution Jae Myung Kim1*, Junsuk Choe1*, Zeynep Akata2, Seong Joon Oh1† * Equal contribution † Corresponding a
 90 Dec 7, 2022
90 Dec 7, 2022

Code for paper: Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
Group-CAM By Zhang, Qinglong and Rao, Lu and Yang, Yubin [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the o
 98 Nov 16, 2022
98 Nov 16, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
PyTorch implementation for ACL 2021 paper "Maria: A Visual Experience Powered Conversational Agent".
Maria: A Visual Experience Powered Conversational Agent This repository is the Pytorch implementation of our paper "Maria: A Visual Experience Powered
 22 Dec 12, 2022
22 Dec 12, 2022

Codes for ACL-IJCNLP 2021 Paper "Zero-shot Fact Verification by Claim Generation"
Zero-shot-Fact-Verification-by-Claim-Generation This repository contains code and models for the paper: Zero-shot Fact Verification by Claim Generatio
 47 Jan 1, 2023
47 Jan 1, 2023

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022
![A 2D Visual Localization Framework based on Essential Matrices [ICRA2020]](https://github.com/GrumpyZhou/visloc-relapose/raw/master/pipeline/pipeline.jpg)
A 2D Visual Localization Framework based on Essential Matrices [ICRA2020]
A 2D Visual Localization Framework based on Essential Matrices This repository provides implementation of our paper accepted at ICRA: To Learn or Not
 27 Nov 7, 2022
27 Nov 7, 2022
FLVIS: Feedback Loop Based Visual Initial SLAM
FLVIS Feedback Loop Based Visual Inertial SLAM 1-Video EuRoC DataSet MH_05 Handheld Test in Lab FlVIS on UAV Platform 2-Relevent Publication: Under Re
 182 Dec 4, 2022
182 Dec 4, 2022

Exploring Visual Engagement Signals for Representation Learning
Exploring Visual Engagement Signals for Representation Learning Menglin Jia, Zuxuan Wu, Austin Reiter, Claire Cardie, Serge Belongie and Ser-Nam Lim C
 9 Jul 23, 2022
9 Jul 23, 2022

A new kind of Progress Bar, with real time throughput, eta and very cool animations!
A new kind of Progress Bar, with real time throughput, eta and very cool animations!
 4.1k Jan 8, 2023
4.1k Jan 8, 2023
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022
This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
ResT By Qing-Long Zhang and Yu-Bin Yang [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the official implement
222 Dec 13, 2022

Lumen provides a framework for visual analytics, which allows users to build data-driven dashboards from a simple yaml specification
Lumen project provides a framework for visual analytics, which allows users to build data-driven dashboards from a simple yaml specification
 120 Jan 4, 2023
120 Jan 4, 2023
Conformer: Local Features Coupling Global Representations for Visual Recognition
Conformer: Local Features Coupling Global Representations for Visual Recognition (arxiv) This repository is built upon DeiT and timm Usage First, inst
 378 Jan 8, 2023
378 Jan 8, 2023

TrTr: Visual Tracking with Transformer
TrTr: Visual Tracking with Transformer We propose a novel tracker network based on a powerful attention mechanism called Transformer encoder-decoder a
 66 Dec 27, 2022
66 Dec 27, 2022
covid question answering datasets and fine tuned models
Covid-QA Fine tuned models for question answering on Covid-19 data. Hosted Inference This model has been contributed to huggingface.Click here to see
 19 Sep 9, 2021
19 Sep 9, 2021
Binary Passage Retriever (BPR) - an efficient passage retriever for open-domain question answering
BPR Binary Passage Retriever (BPR) is an efficient neural retrieval model for open-domain question answering. BPR integrates a learning-to-hash techni
 147 Dec 7, 2022
147 Dec 7, 2022

Code release for paper: The Boombox: Visual Reconstruction from Acoustic Vibrations
The Boombox: Visual Reconstruction from Acoustic Vibrations Boyuan Chen, Mia Chiquier, Hod Lipson, Carl Vondrick Columbia University Project Website |
 12 Nov 30, 2022
12 Nov 30, 2022
Python codes for Lite Audio-Visual Speech Enhancement.
Lite Audio-Visual Speech Enhancement (Interspeech 2020) Introduction This is the PyTorch implementation of Lite Audio-Visual Speech Enhancement (LAVSE
 85 Dec 1, 2022
85 Dec 1, 2022
Continuous Query Decomposition for Complex Query Answering in Incomplete Knowledge Graphs
Continuous Query Decomposition This repository contains the official implementation for our ICLR 2021 (Oral) paper, Complex Query Answering with Neura
 71 Dec 29, 2022
71 Dec 29, 2022
Visual DSL framework for django
Preface Processes change more often than technic. Domain Rules are situational and may differ from customer to customer. With diverse code and frequen
 165 Jan 8, 2023
165 Jan 8, 2023

Visual Tracking by TridenAlign and Context Embedding
Visual Tracking by TridentAlign and Context Embedding (TACT) Test code for "Visual Tracking by TridentAlign and Context Embedding" Janghoon Choi, Juns
 32 Aug 25, 2021
32 Aug 25, 2021

Location-Sensitive Visual Recognition with Cross-IOU Loss
The trained models are temporarily unavailable, but you can train the code using reasonable computational resource. Location-Sensitive Visual Recognit
 146 Dec 25, 2022
146 Dec 25, 2022
A simple visual front end to the Maya UE4 RBF plugin delivered with MetaHumans
poseWrangler Overview PoseWrangler is a simple UI to create and edit pose-driven relationships in Maya using the MayaUE4RBF plugin. This plugin is dis
 105 Dec 18, 2022
105 Dec 18, 2022
So-ViT: Mind Visual Tokens for Vision Transformer
So-ViT: Mind Visual Tokens for Vision Transformer Introduction This repository contains the source code under PyTorch framework and models trai
 44 Nov 24, 2022
44 Nov 24, 2022

ManipulaTHOR, a framework that facilitates visual manipulation of objects using a robotic arm
ManipulaTHOR: A Framework for Visual Object Manipulation Kiana Ehsani, Winson Han, Alvaro Herrasti, Eli VanderBilt, Luca Weihs, Eric Kolve, Aniruddha
 65 Dec 30, 2022
65 Dec 30, 2022

LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
LVI-SAM This repository contains code for a lidar-visual-inertial odometry and mapping system, which combines the advantages of LIO-SAM and Vins-Mono
 1.1k Dec 27, 2022
1.1k Dec 27, 2022

GrailQA: Strongly Generalizable Question Answering
GrailQA is a new large-scale, high-quality KBQA dataset with 64,331 questions annotated with both answers and corresponding logical forms in different syntax (i.e., SPARQL, S-expression, etc.). It can be used to test three levels of generalization in KBQA: i.i.d., compositional, and zero-shot.
 76 Dec 21, 2022
76 Dec 21, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023

Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
 105 Nov 7, 2022
105 Nov 7, 2022

Knowledge Graph,Question Answering System,基于知识图谱和向量检索的医疗诊断问答系统
Knowledge Graph,Question Answering System,基于知识图谱和向量检索的医疗诊断问答系统
 823 Dec 28, 2022
823 Dec 28, 2022

Code for Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021)
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021) Hang Zhou, Yasheng Sun, Wayne Wu, Chen Cha
 628 Dec 28, 2022
628 Dec 28, 2022
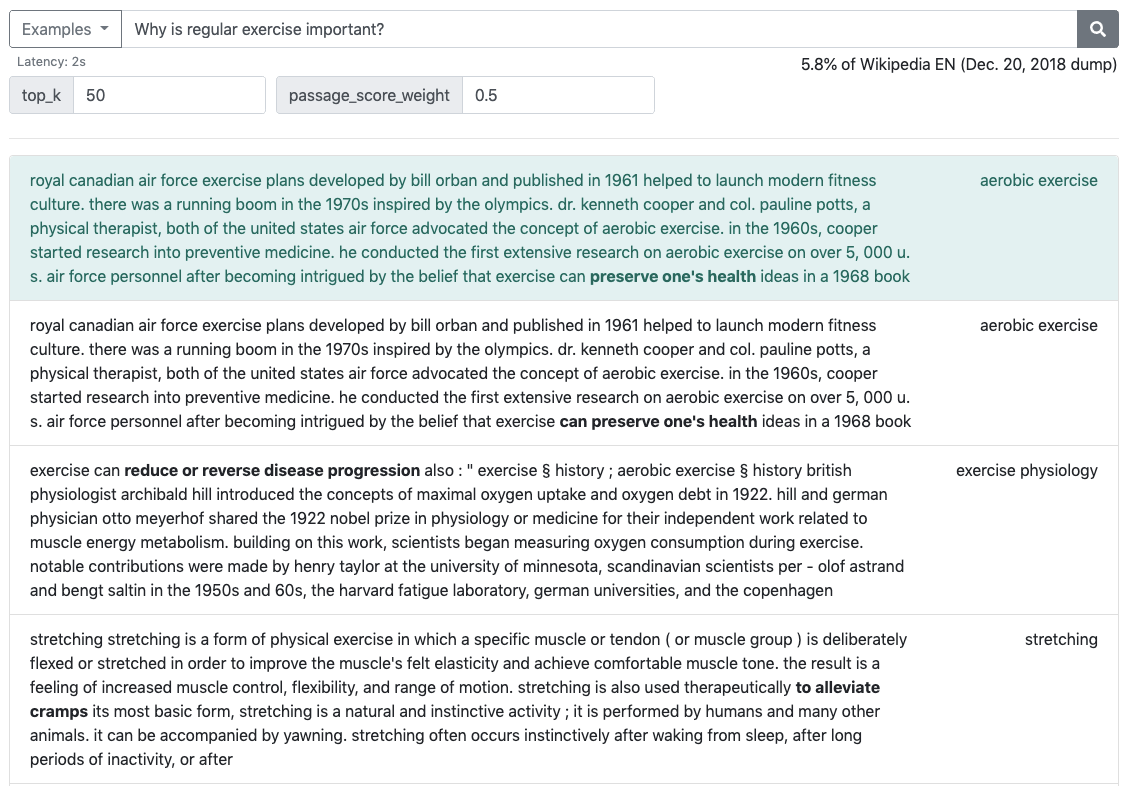
Designing a Minimal Retrieve-and-Read System for Open-Domain Question Answering (NAACL 2021)
Designing a Minimal Retrieve-and-Read System for Open-Domain Question Answering Abstract In open-domain question answering (QA), retrieve-and-read mec
 34 Apr 13, 2022
34 Apr 13, 2022

QA-GNN: Question Answering using Language Models and Knowledge Graphs
QA-GNN: Question Answering using Language Models and Knowledge Graphs This repo provides the source code & data of our paper: QA-GNN: Reasoning with L
 434 Jan 4, 2023
434 Jan 4, 2023
PyTorch reimplementation of the paper Involution: Inverting the Inherence of Convolution for Visual Recognition [CVPR 2021].
Involution: Inverting the Inherence of Convolution for Visual Recognition Unofficial PyTorch reimplementation of the paper Involution: Inverting the I
 100 Dec 1, 2022
100 Dec 1, 2022

Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation This is the official repository for our paper Neural Reprojection Error
 78 Dec 1, 2022
78 Dec 1, 2022

A Collection of Conference & School Notes in Machine Learning 🦄📝🎉
Machine Learning Conference & Summer School Notes. 🦄📝🎉
 558 Dec 28, 2022
558 Dec 28, 2022

Codes for NAACL 2021 Paper "Unsupervised Multi-hop Question Answering by Question Generation"
Unsupervised-Multi-hop-QA This repository contains code and models for the paper: Unsupervised Multi-hop Question Answering by Question Generation (NA
70 Nov 27, 2022

UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning This is the official PyTorch implementation for UniMoCo pape
 49 Jan 2, 2023
49 Jan 2, 2023

Learning Spatio-Temporal Transformer for Visual Tracking
STARK The official implementation of the paper Learning Spatio-Temporal Transformer for Visual Tracking Hiring research interns for visual transformer
 484 Dec 29, 2022
484 Dec 29, 2022
Learning Spatio-Temporal Transformer for Visual Tracking
STARK The official implementation of the paper Learning Spatio-Temporal Transformer for Visual Tracking Highlights The strongest performances Tracker
485 Jan 4, 2023

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 5, 2023
399 Jan 5, 2023
git git《Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking》(CVPR 2021) GitHub:git2] 《Masksembles for Uncertainty Estimation》(CVPR 2021) GitHub:git3]
Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking Ning Wang, Wengang Zhou, Jie Wang, and Houqiang Li Accepted by CVPR
 236 Dec 22, 2022
236 Dec 22, 2022

Implementation of the 😇 Attention layer from the paper, Scaling Local Self-Attention For Parameter Efficient Visual Backbones
HaloNet - Pytorch Implementation of the Attention layer from the paper, Scaling Local Self-Attention For Parameter Efficient Visual Backbones. This re
 189 Nov 22, 2022
189 Nov 22, 2022

Visual Automata is a Python 3 library built as a wrapper for Caleb Evans' Automata library to add more visualization features.
Visual Automata Copyright 2021 Lewi Lie Uberg Released under the MIT license Visual Automata is a Python 3 library built as a wrapper for Caleb Evans'
 55 Nov 17, 2022
55 Nov 17, 2022
Simple app for visual editing of Page XML files
Name nw-page-editor - Simple app for visual editing of Page XML files. Version: 2021.02.22 Description nw-page-editor is an application for viewing/ed
 27 Jun 20, 2022
27 Jun 20, 2022
Visual Attention based OCR
Attention-OCR Authours: Qi Guo and Yuntian Deng Visual Attention based OCR. The model first runs a sliding CNN on the image (images are resized to hei
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
A Tensorflow model for text recognition (CNN + seq2seq with visual attention) available as a Python package and compatible with Google Cloud ML Engine.
Attention-based OCR Visual attention-based OCR model for image recognition with additional tools for creating TFRecords datasets and exporting the tra
 933 Dec 29, 2022
933 Dec 29, 2022
![[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator](https://github.com/d-li14/involution/raw/main/fig/involution.png)
[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator
involution Official implementation of a neural operator as described in Involution: Inverting the Inherence of Convolution for Visual Recognition (CVP
 1.3k Dec 28, 2022
1.3k Dec 28, 2022

Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning, CVPR 2021
Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning By Zhenda Xie*, Yutong Lin*, Zheng Zhang, Yue Ca
 293 Dec 20, 2022
293 Dec 20, 2022

Visual analysis and diagnostic tools to facilitate machine learning model selection.
Yellowbrick Visual analysis and diagnostic tools to facilitate machine learning model selection. What is Yellowbrick? Yellowbrick is a suite of visual
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
![[CVPR 2021] Released code for Counterfactual Zero-Shot and Open-Set Visual Recognition](https://github.com/Wangt-CN/gcm-cf/raw/main/osr/images/GCM_CF.png)
[CVPR 2021] Released code for Counterfactual Zero-Shot and Open-Set Visual Recognition
Counterfactual Zero-Shot and Open-Set Visual Recognition This project provides implementations for our CVPR 2021 paper Counterfactual Zero-S
 144 Dec 24, 2022
144 Dec 24, 2022

🍊 :bar_chart: :bulb: Orange: Interactive data analysis
Orange Data Mining Orange is a data mining and visualization toolbox for novice and expert alike. To explore data with Orange, one requires no program
 3.9k Jan 5, 2023
3.9k Jan 5, 2023

artisan: visual scope for coffee roasters
Artisan Visual scope for coffee roasters WARNING: pre-release builds may not work. Use at your own risk. Summary Artisan is a software that helps coff
 705 Jan 5, 2023
705 Jan 5, 2023