424 Repositories
Python visual-question-answering Libraries
Generative Art Using Neural Visual Grammars and Dual Encoders
Generative Art Using Neural Visual Grammars and Dual Encoders Arnheim 1 The original algorithm from the paper Generative Art Using Neural Visual Gramm
 231 Jan 5, 2023
231 Jan 5, 2023

ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning This repository contains the code for our ICCV 202
 28 Nov 8, 2022
28 Nov 8, 2022
SAT: 2D Semantics Assisted Training for 3D Visual Grounding, ICCV 2021 (Oral)
SAT: 2D Semantics Assisted Training for 3D Visual Grounding SAT: 2D Semantics Assisted Training for 3D Visual Grounding by Zhengyuan Yang, Songyang Zh
 22 Nov 30, 2022
22 Nov 30, 2022
![[AAAI-2021] Visual Boundary Knowledge Translation for Foreground Segmentation](https://user-images.githubusercontent.com/6896182/141064192-3dad4369-7307-459a-8bb3-5e9d639239af.png)
[AAAI-2021] Visual Boundary Knowledge Translation for Foreground Segmentation
Trans-Net Code for (Visual Boundary Knowledge Translation for Foreground Segmentation, AAAI2021). [https://ojs.aaai.org/index.php/AAAI/article/view/16
 2 Mar 4, 2022
2 Mar 4, 2022

Python Indent - Correct python indentation in Visual Studio Code.
Python Indent Correct python indentation in Visual Studio Code. See the extension on the VSCode Marketplace and its source code on GitHub. Please cons
 57 Dec 15, 2022
57 Dec 15, 2022

C++ Environment InitiatorVisual Studio Code C / C++ Environment Initiator
Visual Studio Code C / C++ Environment Initiator Latest Version : v 1.0.1(2021/11/08) .exe link here About : Visual Studio Code에서 C/C++환경을 MinGW GCC/G
 2 Dec 19, 2021
2 Dec 19, 2021
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation This repository contains the source code of the paper A Differentiable
 2 May 5, 2022
2 May 5, 2022
Entity-Based Knowledge Conflicts in Question Answering.
Entity-Based Knowledge Conflicts in Question Answering Run Instructions | Paper | Citation | License This repository provides the Substitution Framewo
 35 Oct 19, 2022
35 Oct 19, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
A collection of differentiable SVD methods and also the official implementation of the ICCV21 paper "Why Approximate Matrix Square Root Outperforms Accurate SVD in Global Covariance Pooling?"
Differentiable SVD Introduction This repository contains: The official Pytorch implementation of ICCV21 paper Why Approximate Matrix Square Root Outpe
 32 Dec 25, 2022
32 Dec 25, 2022
Code for Greedy Gradient Ensemble for Visual Question Answering (ICCV 2021, Oral)
Greedy Gradient Ensemble for De-biased VQA Code release for "Greedy Gradient Ensemble for Robust Visual Question Answering" (ICCV 2021, Oral). GGE can
 21 Jun 29, 2022
21 Jun 29, 2022
This repo holds codes of the ICCV21 paper: Visual Alignment Constraint for Continuous Sign Language Recognition.
VAC_CSLR This repo holds codes of the paper: Visual Alignment Constraint for Continuous Sign Language Recognition.(ICCV 2021) [paper] Prerequisites Th
 64 Dec 19, 2022
64 Dec 19, 2022

Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation (CoRL 2021)
Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation [Project website] [Paper] This project is a PyTorch i
 6 Feb 28, 2022
6 Feb 28, 2022

SW components and demos for visual kinship recognition. An emphasis is put on the FIW dataset-- data loaders, benchmarks, results in summary.
FIW Data Development Kit Table of Contents Introduction Families In the Wild Database Publications Organization To Do License Getting Involved Introdu
 12 Jun 4, 2022
12 Jun 4, 2022
[NeurIPS 2021] Introspective Distillation for Robust Question Answering
Introspective Distillation (IntroD) This repository is the Pytorch implementation of our paper "Introspective Distillation for Robust Question Answeri
 13 Jul 26, 2022
13 Jul 26, 2022

A treasure chest for visual recognition powered by PaddlePaddle
简体中文 | English PaddleClas 简介 飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。 近期更新 2021.11.1 发布PP-ShiTu技术报告,新增饮料识别demo 2021.10.23 发
 4.6k Dec 31, 2022
4.6k Dec 31, 2022
Data and Code for paper Outlining and Filling: Hierarchical Query Graph Generation for Answering Complex Questions over Knowledge Graph is available for research purposes.
Data and Code for paper Outlining and Filling: Hierarchical Query Graph Generation for Answering Complex Questions over Knowledge Graph is available f
 5 Nov 10, 2022
5 Nov 10, 2022
The code for MM2021 paper "Multi-Level Counterfactual Contrast for Visual Commonsense Reasoning"
The Code for MM2021 paper "Multi-Level Counterfactual Contrast for Visual Commonsense Reasoning" Setting up and using the repo Get the dataset. Follow
 4 Apr 20, 2022
4 Apr 20, 2022
[IROS2021] NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
NYU-VPR This repository provides the experiment code for the paper Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymiza
 22 Sep 28, 2022
22 Sep 28, 2022

Dynamic Visual Reasoning by Learning Differentiable Physics Models from Video and Language (NeurIPS 2021)
VRDP (NeurIPS 2021) Dynamic Visual Reasoning by Learning Differentiable Physics Models from Video and Language Mingyu Ding, Zhenfang Chen, Tao Du, Pin
 36 Sep 20, 2022
36 Sep 20, 2022

A new benchmark for Icon Question Answering (IconQA) and a large-scale icon dataset Icon645.
IconQA About IconQA is a new diverse abstract visual question answering dataset that highlights the importance of abstract diagram understanding and c
 24 Dec 30, 2022
24 Dec 30, 2022
Code Release for the paper "TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation"
TriBERT This repository contains the code for the NeurIPS 2021 paper titled "TriBERT: Full-body Human-centric Audio-visual Representation Learning for
 8 Aug 31, 2022
8 Aug 31, 2022
Audio Visual Emotion Recognition using TDA
Audio Visual Emotion Recognition using TDA RAVDESS database with two datasets analyzed: Video and Audio dataset: Audio-Dataset: https://www.kaggle.com
 3 May 11, 2022
3 May 11, 2022

Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
 19 Oct 21, 2022
19 Oct 21, 2022
jel - Japanese Entity Linker - is Bi-encoder based entity linker for japanese.
jel: Japanese Entity Linker jel - Japanese Entity Linker - is Bi-encoder based entity linker for japanese. Usage Currently, link and question methods
 10 Jan 6, 2023
10 Jan 6, 2023
This repository contains code and data for "On the Multimodal Person Verification Using Audio-Visual-Thermal Data"
trimodal_person_verification This repository contains the code, and preprocessed dataset featured in "A Study of Multimodal Person Verification Using
 7 Aug 31, 2022
7 Aug 31, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023
A novel pipeline framework for multi-hop complex KGQA task. About the paper title: Improving Multi-hop Embedded Knowledge Graph Question Answering by Introducing Relational Chain Reasoning
Rce-KGQA A novel pipeline framework for multi-hop complex KGQA task. This framework mainly contains two modules, answering_filtering_module and relati
 16 Nov 18, 2022
16 Nov 18, 2022

Efficient Training of Visual Transformers with Small Datasets
Official codes for "Efficient Training of Visual Transformers with Small Datasets", NerIPS 2021.
 112 Dec 25, 2022
112 Dec 25, 2022

Question answering app is used to answer for a user given question from user given text.
Question answering app is used to answer for a user given question from user given text.It is created using HuggingFace's transformer pipeline and streamlit python packages.
 3 Apr 5, 2022
3 Apr 5, 2022
Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
19 Oct 21, 2022

This repository is the official implementation of Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning (NeurIPS21).
Core-tuning This repository is the official implementation of ``Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regular
 18 Dec 17, 2022
18 Dec 17, 2022
中文問句產生器;使用台達電閱讀理解資料集(DRCD)
Transformer QG on DRCD The inputs of the model refers to we integrate C and A into a new C' in the following form. C' = [c1, c2, ..., [HL], a1, ..., a
 1 Oct 22, 2021
1 Oct 22, 2021
DEEPAGÉ: Answering Questions in Portuguese about the Brazilian Environment
DEEPAGÉ: Answering Questions in Portuguese about the Brazilian Environment This repository is related to the paper DEEPAGÉ: Answering Questions in Por
 0 Dec 10, 2021
0 Dec 10, 2021
VOneNet: CNNs with a Primary Visual Cortex Front-End
VOneNet: CNNs with a Primary Visual Cortex Front-End A family of biologically-inspired Convolutional Neural Networks (CNNs). VOneNets have the followi
 99 Dec 22, 2022
99 Dec 22, 2022
The official PyTorch implementation of paper BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition Boyan Zhou, Quan Cui, Xiu-Shen Wei*, Zhao-Min Chen This repo
 616 Dec 21, 2022
616 Dec 21, 2022

JittorVis - Visual understanding of deep learning models
JittorVis: Visual understanding of deep learning model JittorVis is an open-source library for understanding the inner workings of Jittor models by vi
 182 Jan 6, 2023
182 Jan 6, 2023

A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
CLEVR Dataset Generation This is the code used to generate the CLEVR dataset as described in the paper: CLEVR: A Diagnostic Dataset for Compositional
 503 Jan 4, 2023
503 Jan 4, 2023
pytorch implementation of "Contrastive Multiview Coding", "Momentum Contrast for Unsupervised Visual Representation Learning", and "Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination"
Unofficial implementation: MoCo: Momentum Contrast for Unsupervised Visual Representation Learning (Paper) InsDis: Unsupervised Feature Learning via N
 16 Nov 4, 2020
16 Nov 4, 2020
Multi-angle c(q)uestion answering
Macaw Introduction Macaw (Multi-angle c(q)uestion answering) is a ready-to-use model capable of general question answering, showing robustness outside
 430 Jan 4, 2023
430 Jan 4, 2023

Official implementation of deep-multi-trajectory-based single object tracking (IEEE T-CSVT 2021).
DeepMTA_PyTorch Officical PyTorch Implementation of "Dynamic Attention-guided Multi-TrajectoryAnalysis for Single Object Tracking", Xiao Wang, Zhe Che
 7 Dec 3, 2022
7 Dec 3, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
 12 Oct 22, 2022
12 Oct 22, 2022
Repository for MuSiQue: Multi-hop Questions via Single-hop Question Composition
🎵 MuSiQue: Multi-hop Questions via Single-hop Question Composition This is the repository for our paper "MuSiQue: Multi-hop Questions via Single-hop
 21 Jan 2, 2023
21 Jan 2, 2023
Open-Domain Question-Answering for COVID-19 and Other Emergent Domains
Open-Domain Question-Answering for COVID-19 and Other Emergent Domains This repository contains the source code for an end-to-end open-domain question
 7 Sep 27, 2022
7 Sep 27, 2022

Code and Data for NeurIPS2021 Paper "A Dataset for Answering Time-Sensitive Questions"
Time-Sensitive-QA The repo contains the dataset and code for NeurIPS2021 (dataset track) paper Time-Sensitive Question Answering dataset. The dataset
 35 Nov 14, 2022
35 Nov 14, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
12 Oct 22, 2022
The official implementation of CVPR 2021 Paper: Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation.
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation This repository is the official implementation of CVPR 2021 paper:
 9 Nov 14, 2022
9 Nov 14, 2022
Open-Domain Question-Answering for COVID-19 and Other Emergent Domains
Open-Domain Question-Answering for COVID-19 and Other Emergent Domains This repository contains the source code for an end-to-end open-domain question
7 Sep 27, 2022

The code is an implementation of Feedback Convolutional Neural Network for Visual Localization and Segmentation.
Feedback Convolutional Neural Network for Visual Localization and Segmentation The code is an implementation of Feedback Convolutional Neural Network
 19 Dec 4, 2022
19 Dec 4, 2022
Code for Efficient Visual Pretraining with Contrastive Detection
Code for DetCon This repository contains code for the ICCV 2021 paper "Efficient Visual Pretraining with Contrastive Detection" by Olivier J. Hénaff,
56 Nov 13, 2022

Implementation of ICCV21 paper: PnP-DETR: Towards Efficient Visual Analysis with Transformers
Implementation of ICCV 2021 paper: PnP-DETR: Towards Efficient Visual Analysis with Transformers arxiv This repository is based on detr Recently, DETR
 113 Dec 27, 2022
113 Dec 27, 2022

question‘s area recognition using image processing and regular expression
======================================== Paper-Question-recognition ======================================== question‘s area recognition using image p
 7 Dec 27, 2021
7 Dec 27, 2021
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022

Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning This repository is the official implementation of CARE.
 18 Oct 13, 2021
18 Oct 13, 2021
Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021)
Pano-AVQA Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021) [Paper] [Poster] [Video] Getting Starte
 9 Dec 23, 2022
9 Dec 23, 2022
Repo for EchoVPR: Echo State Networks for Visual Place Recognition
EchoVPR Repo for EchoVPR: Echo State Networks for Visual Place Recognition Currently under development Dirs: data: pre-collected hidden representation
 4 Oct 4, 2022
4 Oct 4, 2022
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
89 Dec 2, 2022

This is an example of building a video Question-Answer system using Jina.
example-video-search This is an example of building a video Question-Answer system using Jina. The index data is subtitle files of YouTube videos. Aft
 9 Oct 18, 2022
9 Oct 18, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022
COVINS -- A Framework for Collaborative Visual-Inertial SLAM and Multi-Agent 3D Mapping
COVINS -- A Framework for Collaborative Visual-Inertial SLAM and Multi-Agent 3D Mapping Version 1.0 COVINS is an accurate, scalable, and versatile vis
 183 Dec 27, 2022
183 Dec 27, 2022

This is the official pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering" on VQA Task
🌈 ERASOR (RA-L'21 with ICRA Option) Official page of "ERASOR: Egocentric Ratio of Pseudo Occupancy-based Dynamic Object Removal for Static 3D Point C
 225 Dec 29, 2022
225 Dec 29, 2022

Pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering".
TRAnsformer Routing Networks (TRAR) This is an official implementation for ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visu
 49 Nov 10, 2022
49 Nov 10, 2022

A PyTorch implementation of "From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network" (ICCV2021)
From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network The official code of VisionLAN (ICCV2021). VisionLAN successfully a
 81 Dec 12, 2022
81 Dec 12, 2022
Official implementation of Influence-balanced Loss for Imbalanced Visual Classification in PyTorch.
Official implementation of Influence-balanced Loss for Imbalanced Visual Classification in PyTorch.
 70 Jan 3, 2023
70 Jan 3, 2023
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
 39 Oct 5, 2021
39 Oct 5, 2021

We utilize deep reinforcement learning to obtain favorable trajectories for visual-inertial system calibration.
Unified Data Collection for Visual-Inertial Calibration via Deep Reinforcement Learning Update: The lastest code will be updated in this branch. Pleas
 27 Dec 29, 2022
27 Dec 29, 2022
AryaBota: An app to teach Python coding via gradual programming and visual output
AryaBota An app to teach Python coding, that gradually allows students to transition from using commands similar to natural language, to more Pythonic
 5 Feb 8, 2022
5 Feb 8, 2022
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
68 Jul 18, 2022

RNG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering
RNG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering Authors: Xi Ye, Semih Yavuz, Kazuma Hashimoto, Yingbo Zhou and
 72 Dec 5, 2022
72 Dec 5, 2022
A Fast and Accurate One-Stage Approach to Visual Grounding, ICCV 2019 (Oral)
One-Stage Visual Grounding ***** New: Our recent work on One-stage VG is available at ReSC.***** A Fast and Accurate One-Stage Approach to Visual Grou
118 Dec 5, 2022

Benchmark for Answering Existential First Order Queries with Single Free Variable
EFO-1-QA Benchmark for First Order Query Estimation on Knowledge Graphs This repository contains an entire pipeline for the EFO-1-QA benchmark. EFO-1
 14 Oct 24, 2022
14 Oct 24, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022
Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models.
Tevatron Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models. The toolkit has a modularized
 193 Jan 4, 2023
193 Jan 4, 2023
This repo in the implementation of EMNLP'21 paper "SPARQLing Database Queries from Intermediate Question Decompositions" by Irina Saparina, Anton Osokin
SPARQLing Database Queries from Intermediate Question Decompositions This repo is the implementation of the following paper: SPARQLing Database Querie
 20 Dec 19, 2022
20 Dec 19, 2022

DSAC* for Visual Camera Re-Localization (RGB or RGB-D)
DSAC* for Visual Camera Re-Localization (RGB or RGB-D) Introduction Installation Data Structure Supported Datasets 7Scenes 12Scenes Cambridge Landmark
 143 Dec 22, 2022
143 Dec 22, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
 18 Dec 9, 2022
18 Dec 9, 2022
![[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification](https://github.com/raoyongming/CAL/raw/master/figs/intro.png)
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
 90 Dec 31, 2022
90 Dec 31, 2022

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Official Implementation of Few-shot Visual Relationship Co-localization
VRC Official implementation of the Few-shot Visual Relationship Co-localization (ICCV 2021) paper project page | paper Requirements Use python = 3.8.
 22 Oct 13, 2022
22 Oct 13, 2022
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
89 Dec 18, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
s-pass is a program that creates strong passwords and then encrypts the password and saves it to a file. To see the encrypted password, execute the decrypt.py file and paste the password in the txt file into the incoming question.
s-pass v1.1 s-pass is a program that creates strong passwords and then encrypts the password and saves it to a file. To see the encrypted password, ex
 9 Sep 9, 2022
9 Sep 9, 2022
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
 1.7k Dec 28, 2022
1.7k Dec 28, 2022

Cockpit is a visual and statistical debugger specifically designed for deep learning.
Cockpit: A Practical Debugging Tool for Training Deep Neural Networks
 421 Dec 29, 2022
421 Dec 29, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
PointNav-VO The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation Project Page | Paper Table of Contents Setup
 41 Dec 15, 2022
41 Dec 15, 2022
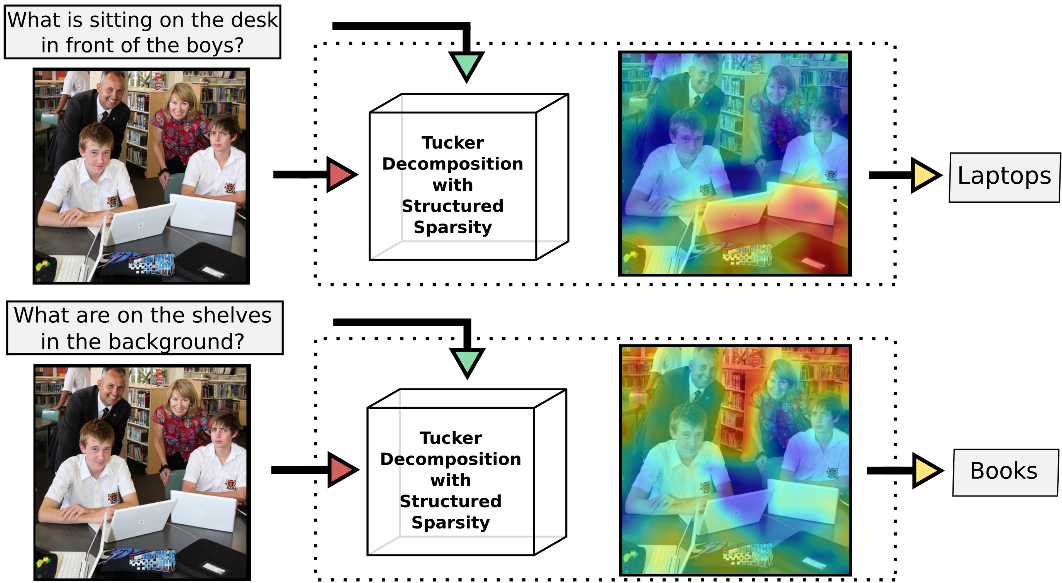
Visual Question Answering in Pytorch
Visual Question Answering in pytorch /!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch This repo wa
 672 Jan 1, 2023
672 Jan 1, 2023
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
166 Dec 11, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
A management system designed for the employees of MIRAS (Art Gallery). It is used to sell/cancel tickets, book/cancel events and keeps track of all upcoming events.
Art-Galleria-Management-System Its a management system designed for the employees of MIRAS (Art Gallery). Backend : Python Frontend : Django Database
 8 Nov 30, 2022
8 Nov 30, 2022
Official repository with code and data accompanying the NAACL 2021 paper "Hurdles to Progress in Long-form Question Answering" (https://arxiv.org/abs/2103.06332).
Hurdles to Progress in Long-form Question Answering This repository contains the official scripts and datasets accompanying our NAACL 2021 paper, "Hur
 41 Nov 8, 2022
41 Nov 8, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023