1016 Repositories
Python visual-transformer Libraries

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax
Simple Transformer An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax. Note: The only ex
 29 Jun 16, 2022
29 Jun 16, 2022

DocEnTr: An end-to-end document image enhancement transformer
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
 19 Jan 29, 2022
19 Jan 29, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
Computer Vision Paper Reviews with Key Summary of paper, End to End Code Practice and Jupyter Notebook converted papers
Computer-Vision-Paper-Reviews Computer Vision Paper Reviews with Key Summary along Papers & Codes. Jonathan Choi 2021 The repository provides 100+ Pap
 2 Mar 17, 2022
2 Mar 17, 2022

Deep ViT Features as Dense Visual Descriptors
dino-vit-features [paper] [project page] Official implementation of the paper "Deep ViT Features as Dense Visual Descriptors". We demonstrate the effe
 113 Dec 24, 2022
113 Dec 24, 2022
Ensemble Visual-Inertial Odometry (EnVIO)
Ensemble Visual-Inertial Odometry (EnVIO) Authors : Jae Hyung Jung, Yeongkwon Choe, and Chan Gook Park 1. Overview This is a ROS package of Ensemble V
 95 Jan 3, 2023
95 Jan 3, 2023

PyTorch implementation of "VRT: A Video Restoration Transformer"
VRT: A Video Restoration Transformer Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, Luc Van Gool Computer
 837 Jan 9, 2023
837 Jan 9, 2023
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022

Decision Transformer: A brand new Offline RL Pattern
DecisionTransformer_StepbyStep Intro Decision Transformer: A brand new Offline RL Pattern. 这是关于NeurIPS 2021 热门论文Decision Transformer的复现。 👍 原文地址: Deci
 14 Nov 22, 2022
14 Nov 22, 2022

Geometric Interpretation of Matrix Square Root and Inverse Square Root
Fast Differentiable Matrix Sqrt Root Geometric Interpretation of Matrix Square Root and Inverse Square Root This repository constains the official Pyt
 5 Jan 24, 2022
5 Jan 24, 2022

This repository contains the code for TABS, a 3D CNN-Transformer hybrid automated brain tissue segmentation algorithm using T1w structural MRI scans
This repository contains the code for TABS, a 3D CNN-Transformer hybrid automated brain tissue segmentation algorithm using T1w structural MRI scans. TABS relies on a Res-Unet backbone, with a Vision Transformer embedded between the encoder and decoder layers.
 6 Nov 7, 2022
6 Nov 7, 2022

SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation
SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation This repo is the official implementation for SegTransVAE. Seg
 4 Aug 4, 2022
4 Aug 4, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022
Transformer based SAR image despeckling
Transformer based SAR image despeckling Using the code: The code is stable while using Python 3.6.13, CUDA =10.1 Clone this repository: git clone htt
 27 Nov 13, 2022
27 Nov 13, 2022
Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer.
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
74 Jan 7, 2023
Vpw analyzer - A visual J1850 VPW analyzer written in Python
VPW Analyzer A visual J1850 VPW analyzer written in Python Requires Tkinter, Pan
 7 May 1, 2022
7 May 1, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization,
FSRA This repository contains the dataset link and the code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV
 32 Dec 18, 2022
32 Dec 18, 2022

EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation
EdiBERT, a generative model for image editing EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation. The
 16 Dec 7, 2022
16 Dec 7, 2022
Revisiting Weakly Supervised Pre-Training of Visual Perception Models
SWAG: Supervised Weakly from hashtAGs This repository contains SWAG models from the paper Revisiting Weakly Supervised Pre-Training of Visual Percepti
 134 Jan 5, 2023
134 Jan 5, 2023

On the Adversarial Robustness of Visual Transformer
On the Adversarial Robustness of Visual Transformer Code for our paper "On the Adversarial Robustness of Visual Transformers"
 35 Dec 14, 2022
35 Dec 14, 2022
This repository contains the implementation of the following paper: Cross-Descriptor Visual Localization and Mapping
Cross-Descriptor Visual Localization and Mapping This repository contains the implementation of the following paper: "Cross-Descriptor Visual Localiza
 81 Oct 6, 2022
81 Oct 6, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
 68 Dec 16, 2022
68 Dec 16, 2022

Clustering is a popular approach to detect patterns in unlabeled data
Visual Clustering Clustering is a popular approach to detect patterns in unlabeled data. Existing clustering methods typically treat samples in a data
 24 Nov 11, 2022
24 Nov 11, 2022
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022

Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
 4 Jun 1, 2022
4 Jun 1, 2022

This is a small program that prints a user friendly, visual representation, of your current bsp tree
bspcq, q for query A bspc analyzer (utility for bspwm) This is a small program that prints a user friendly, visual representation, of your current bsp
 9 Apr 24, 2022
9 Apr 24, 2022
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022

RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting
RATCHET: RAdiological Text Captioning for Human Examined Thoraxes RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting. Based on t
 26 Nov 14, 2022
26 Nov 14, 2022
Generating Radiology Reports via Memory-driven Transformer
R2Gen This is the implementation of Generating Radiology Reports via Memory-driven Transformer at EMNLP-2020. Citations If you use or extend our work,
 101 Dec 13, 2022
101 Dec 13, 2022

This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
ICCV Workshop 2021 VTGAN This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
 25 Dec 8, 2022
25 Dec 8, 2022
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021)
T2Net Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021) [Paper][Code] Dependencies numpy==1.18.5 scikit_image==
 64 Nov 23, 2022
64 Nov 23, 2022
COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models
COVID-ViT COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models This code is to response to te MIA-COV19 compe
 17 Dec 30, 2022
17 Dec 30, 2022
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification [NeurIPS 2021] Abstract Multiple instance learn
 132 Dec 30, 2022
132 Dec 30, 2022
Mixed Transformer UNet for Medical Image Segmentation
MT-UNet Update 2022/01/05 By another round of training based on previous weights, our model also achieved a better performance on ACDC (91.61% DSC). W
 92 Dec 25, 2022
92 Dec 25, 2022
Official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation
SegPC-2021 This is the official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation by
 13 Dec 14, 2022
13 Dec 14, 2022

This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
 89 Jan 24, 2022
89 Jan 24, 2022
nnFormer: Interleaved Transformer for Volumetric Segmentation
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation ". Please
 610 Dec 28, 2022
610 Dec 28, 2022
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
ademxapp Visual applications by the University of Adelaide In designing our Model A, we did not over-optimize its structure for efficiency unless it w
 338 Dec 12, 2022
338 Dec 12, 2022

Pytorch implementation of ICASSP 2022 paper Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 6 Sep 21, 2022
6 Sep 21, 2022

Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 3 Oct 31, 2022
3 Oct 31, 2022
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features | paper | Official PyTorch implementation for Mul
 48 Dec 28, 2022
48 Dec 28, 2022
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow with breakpoints + real-time visualization of the data flowing through the computational graph
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow (Google's Deep Learning framework) with breakpoints + real-time visualization of the data flowing through the computational graph.
 1.4k Dec 15, 2022
1.4k Dec 15, 2022

OMNIVORE is a single vision model for many different visual modalities
Omnivore: A Single Model for Many Visual Modalities [paper][website] OMNIVORE is a single vision model for many different visual modalities. It learns
451 Dec 27, 2022
Fast Differentiable Matrix Sqrt Root
Official Pytorch implementation of ICLR 22 paper Fast Differentiable Matrix Square Root
42 Dec 30, 2022
This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector of the financial market.
GPlearn_finiance_stock_futures_extension This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector
 189 Dec 25, 2022
189 Dec 25, 2022
ServiceX Transformer that converts flat ROOT ntuples into columnwise data
ServiceX_Uproot_Transformer ServiceX Transformer that converts flat ROOT ntuples into columnwise data Usage You can invoke the transformer from the co
 0 Jan 20, 2022
0 Jan 20, 2022
Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
Awesome Visual-Transformer Collect some Transformer with Computer-Vision (CV) papers. If you find some overlooked papers, please open issues or pull r
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Transformer in Computer Vision
Transformer-in-Vision A paper list of some recent Transformer-based CV works. If you find some ignored papers, please open issues or pull requests. **
 506 Dec 26, 2022
506 Dec 26, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
 7 Jan 13, 2022
7 Jan 13, 2022
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022
Detail-Preserving Transformer for Light Field Image Super-Resolution
DPT Official Pytorch implementation of the paper "Detail-Preserving Transformer for Light Field Image Super-Resolution" accepted by AAAI 2022 . Update
 50 Jan 1, 2023
50 Jan 1, 2023

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction. arxiv This repository contains python scripts for tr
 12 Dec 12, 2022
12 Dec 12, 2022
TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning
TransZero++ This repository contains the testing code for the paper "TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning" submitted
 3 Jan 5, 2022
3 Jan 5, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022

MADT: Offline Pre-trained Multi-Agent Decision Transformer
MADT: Offline Pre-trained Multi-Agent Decision Transformer A link to our paper can be found on Arxiv. Overview Official codebase for Offline Pre-train
 51 Dec 21, 2022
51 Dec 21, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022

Visual Python and C++ nanosecond profiler, logger, tests enabler
Look into Palanteer and get an omniscient view of your program Palanteer is a set of lean and efficient tools to improve the quality of software, for
 1.9k Dec 26, 2022
1.9k Dec 26, 2022
Flow-based visual scripting for Python
A simple visual node editor for Python Ryven combines flow-based visual scripting with Python. It gives you absolute freedom for your nodes and a simp
 3.1k Jan 6, 2023
3.1k Jan 6, 2023
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022
Official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
199 Jan 3, 2023
[ACM MM 2021] Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation) [arXiv] [paper] @inproceedings{hou2021multiview, title={Multiview
 27 Dec 13, 2022
27 Dec 13, 2022

Unifying Global-Local Representations in Salient Object Detection with Transformer
GLSTR (Global-Local Saliency Transformer) This is the official implementation of paper "Unifying Global-Local Representations in Salient Object Detect
 11 Aug 24, 2022
11 Aug 24, 2022
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
 27 Nov 7, 2022
27 Nov 7, 2022

This is a code repository for paper OODformer: Out-Of-Distribution Detection Transformer
OODformer: Out-Of-Distribution Detection Transformer This repo is the official the implementation of the OODformer: Out-Of-Distribution Detection Tran
 34 Dec 2, 2022
34 Dec 2, 2022
Image Fusion Transformer
Image-Fusion-Transformer Platform Python 3.7 Pytorch =1.0 Training Dataset MS-COCO 2014 (T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ram
 68 Dec 23, 2022
68 Dec 23, 2022
Official implementation of Sparse Transformer-based Action Recognition
STAR Official implementation of S parse T ransformer-based A ction R ecognition Dataset download NTU RGB+D 60 action recognition of 2D/3D skeleton fro
 15 Nov 2, 2022
15 Nov 2, 2022
MlTr: Multi-label Classification with Transformer
MlTr: Multi-label Classification with Transformer This is official implement of "MlTr: Multi-label Classification with Transformer". Abstract The task
 38 Nov 8, 2022
38 Nov 8, 2022
Pyramid Pooling Transformer for Scene Understanding
Pyramid Pooling Transformer for Scene Understanding Requirements: torch 1.6+ torchvision 0.7.0 timm==0.3.2 Validated on torch 1.6.0, torchvision 0.7.0
 119 Dec 29, 2022
119 Dec 29, 2022
PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluation of Visual Stories via Semantic Consistency"
Improving Generation and Evaluation of Visual Stories via Semantic Consistency PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluat
 28 Dec 8, 2022
28 Dec 8, 2022
Visual dialog agents with pre-trained vision-and-language encoders.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation Or READ-UP: Referring Expression Agent Dialog with Unified Pretr
 7 Oct 8, 2022
7 Oct 8, 2022

Implementations for the ICLR-2021 paper: SEED: Self-supervised Distillation For Visual Representation.
Implementations for the ICLR-2021 paper: SEED: Self-supervised Distillation For Visual Representation.
 27 Oct 23, 2022
27 Oct 23, 2022

Deep learning transformer model that generates unique music sequences.
music-ai Deep learning transformer model that generates unique music sequences. Abstract In 2017, a new state-of-the-art was published for natural lan
 6 Nov 19, 2022
6 Nov 19, 2022

PyFlow is a general purpose visual scripting framework for python
PyFlow is a general purpose visual scripting framework for python. State Base structure of program implemented, such things as packages disco
 1.8k Jan 7, 2023
1.8k Jan 7, 2023

PyTorch implementation of Higher Order Recurrent Space-Time Transformer
Higher Order Recurrent Space-Time Transformer (HORST) This is the official PyTorch implementation of Higher Order Recurrent Space-Time Transformer. Th
 13 Oct 18, 2022
13 Oct 18, 2022

Pytorch implementation of Decoupled Spatial-Temporal Transformer for Video Inpainting
Decoupled Spatial-Temporal Transformer for Video Inpainting By Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, J
 51 Dec 13, 2022
51 Dec 13, 2022
Official PyTorch Implementation of "AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting".
AgentFormer This repo contains the official implementation of our paper: AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecast
 161 Dec 23, 2022
161 Dec 23, 2022

Single-Shot Motion Completion with Transformer
Single-Shot Motion Completion with Transformer 👉 [Preprint] 👈 Abstract Motion completion is a challenging and long-discussed problem, which is of gr
 78 Dec 29, 2022
78 Dec 29, 2022
![[ICCV 2021] Relaxed Transformer Decoders for Direct Action Proposal Generation](https://github.com/MCG-NJU/RTD-Action/raw/main/rtd_overview.png)
[ICCV 2021] Relaxed Transformer Decoders for Direct Action Proposal Generation
RTD-Net (ICCV 2021) This repo holds the codes of paper: "Relaxed Transformer Decoders for Direct Action Proposal Generation", accepted in ICCV 2021. N
 80 Nov 30, 2022
80 Nov 30, 2022
IOT: Instance-wise Layer Reordering for Transformer Structures
Introduction This repository contains the code for Instance-wise Ordered Transformer (IOT), which is introduced in the ICLR2021 paper IOT: Instance-wi
 19 Nov 15, 2022
19 Nov 15, 2022

Code and Resources for the Transformer Encoder Reasoning Network (TERN)
Transformer Encoder Reasoning Network Code for the cross-modal visual-linguistic retrieval method from "Transformer Reasoning Network for Image-Text M
 53 Dec 30, 2022
53 Dec 30, 2022
Effective Use of Transformer Networks for Entity Tracking
Effective Use of Transformer Networks for Entity Tracking (EMNLP19) This is a PyTorch implementation of our EMNLP paper on the effectiveness of pre-tr
 5 Nov 6, 2021
5 Nov 6, 2021
Pytorch implementation of set transformer
set_transformer Official PyTorch implementation of the paper Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks .
 410 Jan 6, 2023
410 Jan 6, 2023

Pytorch implementation of Compressive Transformers, from Deepmind
Compressive Transformer in Pytorch Pytorch implementation of Compressive Transformers, a variant of Transformer-XL with compressed memory for long-ran
 118 Dec 1, 2022
118 Dec 1, 2022
Code repo for "Transformer on a Diet" paper
Transformer on a Diet Reference: C Wang, Z Ye, A Zhang, Z Zhang, A Smola. "Transformer on a Diet". arXiv preprint arXiv (2020). Installation pip insta
 31 Sep 26, 2021
31 Sep 26, 2021
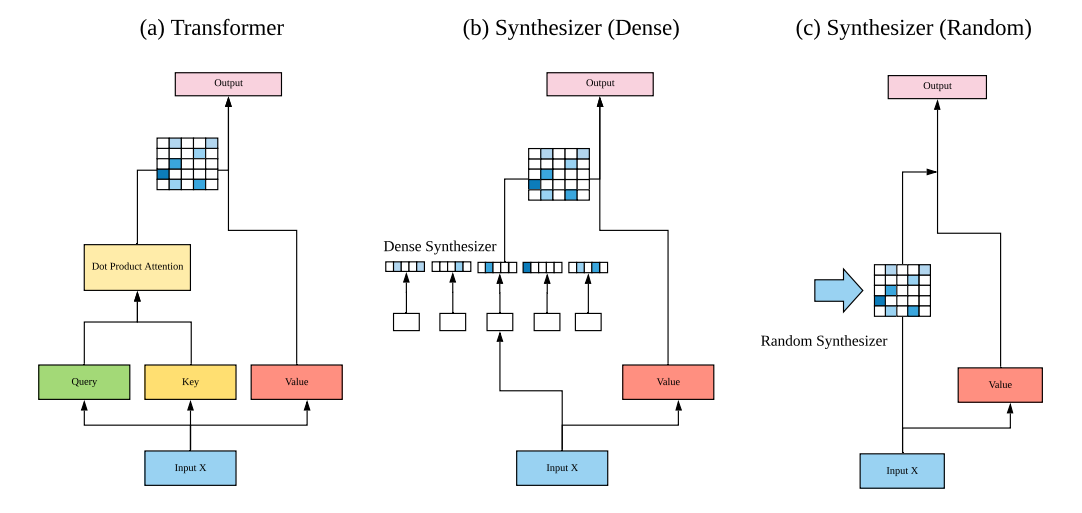
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch Reference Paper URL Author: Yi Tay, Dara Bahri, Donald Metzler
 66 Nov 30, 2022
66 Nov 30, 2022

Implementation of Memformer, a Memory-augmented Transformer, in Pytorch
Memformer - Pytorch Implementation of Memformer, a Memory-augmented Transformer, in Pytorch. It includes memory slots, which are updated with attentio
60 Nov 6, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
Reproducing-BowNet: Learning Representations by Predicting Bags of Visual Words
Reproducing-BowNet Our reproducibility effort based on the 2020 ML Reproducibility Challenge. We are reproducing the results of this CVPR 2020 paper:
 6 Mar 16, 2022
6 Mar 16, 2022

This is the official implementation of our proposed SwinMR
SwinMR This is the official implementation of our proposed SwinMR: Swin Transformer for Fast MRI Please cite: @article{huang2022swin, title={Swi
 27 Nov 17, 2022
27 Nov 17, 2022
Accurate identification of bacteriophages from metagenomic data using Transformer
PhaMer is a python library for identifying bacteriophages from metagenomic data. PhaMer is based on a Transorfer model and rely on protein-based vocab
 9 Nov 30, 2022
9 Nov 30, 2022