Filter By
1361 Repositories
Python Text Data & NLP
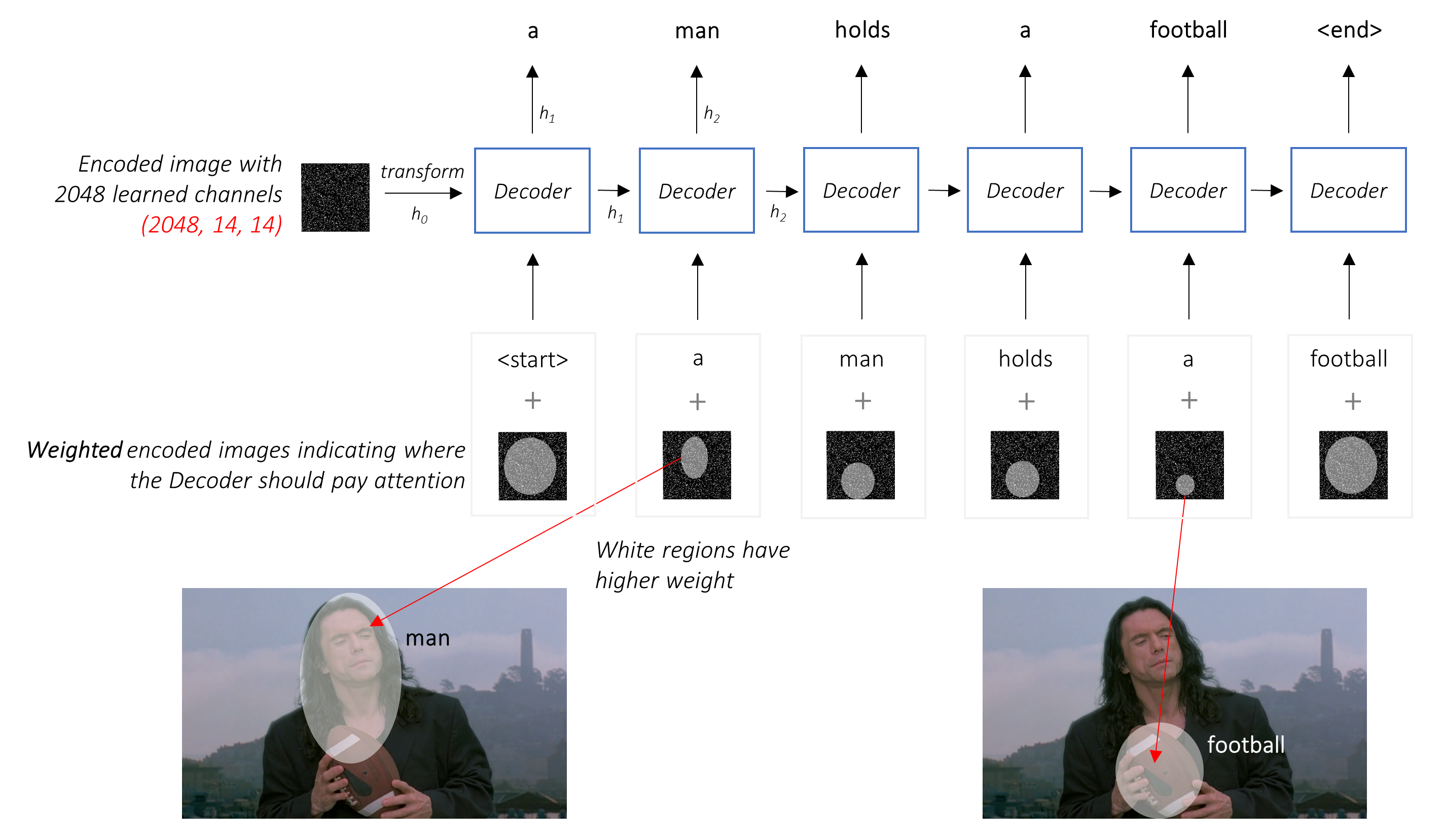
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022

This is the 25 + 1 year anniversary version of the 1995 Rachford-Rice contest
Rachford-Rice Contest This is the 25 + 1 year anniversary version of the 1995 Rachford-Rice contest. Can you solve the Rachford-Rice problem for all t
 13 Sep 20, 2022
13 Sep 20, 2022
Modular and extensible speech recognition library leveraging pytorch-lightning and hydra.
Lightning ASR Modular and extensible speech recognition library leveraging pytorch-lightning and hydra What is Lightning ASR • Installation • Get Star
 40 Sep 19, 2022
40 Sep 19, 2022
多语言降噪预训练模型MBart的中文生成任务
mbart-chinese 基于mbart-large-cc25 的中文生成任务 Input source input: text + /s + lang_code target input: lang_code + text + /s Usage token_ids_mapping.jso
 11 Sep 19, 2022
11 Sep 19, 2022

BERT-based Financial Question Answering System
BERT-based Financial Question Answering System In this example, we use Jina, PyTorch, and Hugging Face transformers to build a production-ready BERT-b
 61 Sep 18, 2022
61 Sep 18, 2022
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022

Quick insights from Zoom meeting transcripts using Graph + NLP
Transcript Analysis - Graph + NLP This program extracts insights from Zoom Meeting Transcripts (.vtt) using TigerGraph and NLTK. In order to run this
 7 Sep 17, 2022
7 Sep 17, 2022

Dual languaged (rus+eng) tool for packing and unpacking archives of Silky Engine.
SilkyArcTool English Dual languaged (rus+eng) GUI tool for packing and unpacking archives of Silky Engine. It is not the same arc as used in Ai6WIN. I
 5 Sep 15, 2022
5 Sep 15, 2022
Script to generate VAD dataset used in Asteroid recipe
About the dataset LibriVAD is an open source dataset for voice activity detection in noisy environments. It is derived from LibriSpeech signals (clean
 11 Sep 15, 2022
11 Sep 15, 2022
Indonesia spellchecker with python
indonesia-spellchecker Ganti kata yang terdapat pada file teks.txt untuk diperiksa kebenaran kata. Run on local machine python3 main.py
 1 Sep 14, 2022
1 Sep 14, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
 65 Sep 13, 2022
65 Sep 13, 2022
Code for PED: DETR For (Crowd) Pedestrian Detection
Code for PED: DETR For (Crowd) Pedestrian Detection
 36 Sep 13, 2022
36 Sep 13, 2022

Use Tensorflow2.7.0 Build OpenAI'GPT-2
TF2_GPT-2 Use Tensorflow2.7.0 Build OpenAI'GPT-2 使用最新tensorflow2.7.0构建openai官方的GPT-2 NLP模型 优点 使用无监督技术 拥有大量词汇量 可实现续写(堪比“xx梦续写”) 实现对话后续将应用于FloatTech的Bot
 9 Sep 13, 2022
9 Sep 13, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
A python wrapper around the ZPar parser for English.
NOTE This project is no longer under active development since there are now really nice pure Python parsers such as Stanza and Spacy. The repository w
 49 Sep 12, 2022
49 Sep 12, 2022
Checking spelling of form elements
Checking spelling of form elements. You can check the source files of external workflows/reports and configuration files
 15 Sep 12, 2022
15 Sep 12, 2022

Train GPT-3 model on V100(16GB Mem) Using improved Transformer.
GPT-X using transformer pytorch
 24 Sep 11, 2022
24 Sep 11, 2022
Share constant definitions between programming languages and make your constants constant again
Introduction Reconstant lets you share constant and enum definitions between programming languages. Constants are defined in a yaml file and converted
 47 Sep 10, 2022
47 Sep 10, 2022
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources (NAACL-2021).
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources Description This is the repository for the paper Unifying Cross-
 16 Sep 9, 2022
16 Sep 9, 2022

OceanScript is an Esoteric language used to encode and decode text into a formulation of characters
OceanScript is an Esoteric language used to encode and decode text into a formulation of characters - where the final result looks like waves in the ocean.
 2 Sep 9, 2022
2 Sep 9, 2022
scikit-learn wrappers for Python fastText.
skift scikit-learn wrappers for Python fastText. from skift import FirstColFtClassifier df = pandas.DataFrame([['woof', 0], ['meow', 1]], colu
 233 Sep 9, 2022
233 Sep 9, 2022
A framework for evaluating Knowledge Graph Embedding Models in a fine-grained manner.
A framework for evaluating Knowledge Graph Embedding Models in a fine-grained manner.
 13 Sep 8, 2022
13 Sep 8, 2022
Athena is an open-source implementation of end-to-end speech processing engine.
Athena is an open-source implementation of end-to-end speech processing engine. Our vision is to empower both industrial application and academic research on end-to-end models for speech processing. To make speech processing available to everyone, we're also releasing example implementation and recipe on some opensource dataset for various tasks (Automatic Speech Recognition, Speech Synthesis, Voice Conversion, Speaker Recognition, etc).
 34 Sep 8, 2022
34 Sep 8, 2022
Python wrapper for Stanford CoreNLP tools v3.4.1
Python interface to Stanford Core NLP tools v3.4.1 This is a Python wrapper for Stanford University's NLP group's Java-based CoreNLP tools. It can eit
 610 Sep 7, 2022
610 Sep 7, 2022

CredData is a set of files including credentials in open source projects
CredData is a set of files including credentials in open source projects. CredData includes suspicious lines with manual review results and more information such as credential types for each suspicious line. CredData can be used to develop new tools or improve existing tools. Furthermore, using the benchmark result of the CredData, users can choose a proper tool among open source credential scanning tools according to their use case.
 19 Sep 7, 2022
19 Sep 7, 2022

Predict an emoji that is associated with a text
Sentiment Analysis Sentiment analysis in computational linguistics is a general term for techniques that quantify sentiment or mood in a text. Can you
 30 Sep 7, 2022
30 Sep 7, 2022

Application for shadowing Chinese.
chinese-shadowing Simple APP for shadowing chinese. With this application, it is very easy to record yourself, play the sound recorded and listen to s
 5 Sep 6, 2022
5 Sep 6, 2022
2021搜狐校园文本匹配算法大赛baseline
sohu2021-baseline 2021搜狐校园文本匹配算法大赛baseline 简介 分享了一个搜狐文本匹配的baseline,主要是通过条件LayerNorm来增加模型的多样性,以实现同一模型处理不同类型的数据、形成不同输出的目的。 线下验证集F1约0.74,线上测试集F1约0.73。
 45 Sep 6, 2022
45 Sep 6, 2022
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
What is MUSE? MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (16 languages) of Universal Sentence Encoder (USE). MUS
 47 Sep 5, 2022
47 Sep 5, 2022
Code for Findings at EMNLP 2021 paper: "Learn Continually, Generalize Rapidly: Lifelong Knowledge Accumulation for Few-shot Learning"
Learn Continually, Generalize Rapidly: Lifelong Knowledge Accumulation for Few-shot Learning This repo is for Findings at EMNLP 2021 paper: Learn Cont
 6 Sep 2, 2022
6 Sep 2, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022

Neural network models for joint POS tagging and dependency parsing (CoNLL 2017-2018)
Neural Network Models for Joint POS Tagging and Dependency Parsing Implementations of joint models for POS tagging and dependency parsing, as describe
 152 Sep 2, 2022
152 Sep 2, 2022
An evaluation toolkit for voice conversion models.
Voice-conversion-evaluation An evaluation toolkit for voice conversion models. Sample test pair Generate the metadata for evaluating models. The direc
 30 Aug 29, 2022
30 Aug 29, 2022

Takes a string and puts it through different languages in Google Translate a requested amount of times, returning nonsense.
PythonTextObfuscator Takes a string and puts it through different languages in Google Translate a requested amount of times, returning nonsense. Requi
 2 Aug 29, 2022
2 Aug 29, 2022
German Text-To-Speech Engine using Tacotron and Griffin-Lim
jotts JoTTS is a German text-to-speech engine using tacotron and griffin-lim. The synthesizer model has been trained on my voice using Tacotron1. Due
 6 Aug 28, 2022
6 Aug 28, 2022
Indobenchmark are collections of Natural Language Understanding (IndoNLU) and Natural Language Generation (IndoNLG)
Indobenchmark Toolkit Indobenchmark are collections of Natural Language Understanding (IndoNLU) and Natural Language Generation (IndoNLG) resources fo
 11 Aug 26, 2022
11 Aug 26, 2022
Implementation of TF-IDF algorithm to find documents similarity with cosine similarity
NLP learning Trying to learn NLP to use in my projects! Table of Contents About The Project Built With Getting Started Requirements Run Usage License
 3 Aug 25, 2022
3 Aug 25, 2022
Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech
epub2audiobook Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech Input examples qual a pasta do seu
 7 Aug 25, 2022
7 Aug 25, 2022

Auto translate textbox from Japanese to English or Indonesia
priconne-auto-translate Auto translate textbox from Japanese to English or Indonesia How to use Install python first, Anaconda is recommended Install
 5 Aug 25, 2022
5 Aug 25, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
 14 Aug 24, 2022
14 Aug 24, 2022
A sentence aligner for comparable corpora
About Yalign is a tool for extracting parallel sentences from comparable corpora. Statistical Machine Translation relies on parallel corpora (eg.. eur
 128 Aug 24, 2022
128 Aug 24, 2022
基于Transformer的单模型、多尺度的VAE模型
UniVAE 基于Transformer的单模型、多尺度的VAE模型 介绍 https://kexue.fm/archives/8475 依赖 需要大于0.10.6版本的bert4keras(当前还没有推到pypi上,可以直接从GitHub上clone最新版)。 引用 @misc{univae,
49 Aug 24, 2022
Mednlp - Medical natural language parsing and utility library
Medical natural language parsing and utility library A natural language medical
 3 Aug 24, 2022
3 Aug 24, 2022
This repository describes our reproducible framework for assessing self-supervised representation learning from speech
LeBenchmark: a reproducible framework for assessing SSL from speech Self-Supervised Learning (SSL) using huge unlabeled data has been successfully exp
 49 Aug 24, 2022
49 Aug 24, 2022
GVT is a generic translation tool for parts of text on the PC screen with Text to Speak functionality.
GVT is a generic translation tool for parts of text on the PC screen with Text to Speech functionality. I wanted to create it because the existing tools that I experimented with did not satisfy me in ease-to-use experience and configuration. Personally I used it with Lost Ark (example included generated by 2k monitor) to translate simple dialogues of quests in Italian.
 1 Aug 21, 2022
1 Aug 21, 2022
A tool helps build a talk preview image by combining the given background image and talk event description
talk-preview-img-builder A tool helps build a talk preview image by combining the given background image and talk event description Installation and U
 4 Aug 20, 2022
4 Aug 20, 2022
The Sudachi synonym dictionary in Solar format.
solr-sudachi-synonyms The Sudachi synonym dictionary in Solar format. Summary Run a script that checks for updates to the Sudachi dictionary every hou
 3 Aug 19, 2022
3 Aug 19, 2022

2021 2학기 데이터크롤링 기말프로젝트
공지 주제 웹 크롤링을 이용한 취업 공고 스케줄러 스케줄 주제 정하기 코딩하기 핵심 코드 설명 + 피피티 구조 구상 // 12/4 토 피피티 + 스크립트(대본) 제작 + 녹화 // ~ 12/10 ~ 12/11 금~토 영상 편집 // ~12/11 토 웹크롤러 사람인_평균
 2 Aug 16, 2022
2 Aug 16, 2022
Tokenizer - Module python d'analyse syntaxique et de grammaire, tokenization
Tokenizer Le Tokenizer est un analyseur lexicale, il permet, comme Flex and Yacc par exemple, de tokenizer du code, c'est à dire transformer du code e
 1 Aug 15, 2022
1 Aug 15, 2022
Collection of useful (to me) python scripts for interacting with napari
Napari scripts A collection of napari related tools in various state of disrepair/functionality. Browse_LIF_widget.py This module can be imported, for
 5 Aug 15, 2022
5 Aug 15, 2022

TLA - Twitter Linguistic Analysis
TLA - Twitter Linguistic Analysis Tool for linguistic analysis of communities TLA is built using PyTorch, Transformers and several other State-of-the-
 47 Aug 14, 2022
47 Aug 14, 2022

Built for cleaning purposes in military institutions
Ferramenta do AL Construído para fins de limpeza em instituições militares. Instalação Requer python = 3.2 pip install -r requirements.txt Usagem Exe
 0 Aug 13, 2022
0 Aug 13, 2022
🗣️ NALP is a library that covers Natural Adversarial Language Processing.
NALP: Natural Adversarial Language Processing Welcome to NALP. Have you ever wanted to create natural text from raw sources? If yes, NALP is for you!
 21 Aug 12, 2022
21 Aug 12, 2022