473 Repositories
Python Compositional-Attention Libraries

Implementation of Memorizing Transformers (ICLR 2022), attention net augmented with indexing and retrieval of memories using approximate nearest neighbors, in Pytorch
Memorizing Transformers - Pytorch Implementation of Memorizing Transformers (ICLR 2022), attention net augmented with indexing and retrieval of memori
 364 Jan 6, 2023
364 Jan 6, 2023
![[CVPR 2022 Oral] MixFormer: End-to-End Tracking with Iterative Mixed Attention](https://github.com/MCG-NJU/MixFormer/raw/main/tracking/mixformer_framework.png)
[CVPR 2022 Oral] MixFormer: End-to-End Tracking with Iterative Mixed Attention
MixFormer The official implementation of the CVPR 2022 paper MixFormer: End-to-End Tracking with Iterative Mixed Attention [Models and Raw results] (G
 235 Jan 3, 2023
235 Jan 3, 2023

Official implementation for "Style Transformer for Image Inversion and Editing" (CVPR 2022)
Style Transformer for Image Inversion and Editing (CVPR2022) https://arxiv.org/abs/2203.07932 Existing GAN inversion methods fail to provide latent co
 153 Dec 2, 2022
153 Dec 2, 2022

Implementation of Deformable Attention in Pytorch from the paper "Vision Transformer with Deformable Attention"
Deformable Attention Implementation of Deformable Attention from this paper in Pytorch, which appears to be an improvement to what was proposed in DET
128 Dec 24, 2022

PyTorch implementation of U-TAE and PaPs for satellite image time series panoptic segmentation.
Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks (ICCV 2021) This repository is the official implem
 71 Jan 4, 2023
71 Jan 4, 2023

This repo presents you the official code of "VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention"
VISTA VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention Shengheng Deng, Zhihao Liang, Lin Sun and Kui Jia* (*) Corresponding a
 104 Dec 29, 2022
104 Dec 29, 2022

Implementation of the Transformer variant proposed in "Transformer Quality in Linear Time"
FLASH - Pytorch Implementation of the Transformer variant proposed in the paper Transformer Quality in Linear Time Install $ pip install FLASH-pytorch
209 Dec 28, 2022

A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution (CVPR2022)
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution (CVPR2022) https://arxiv.org/abs/2203.09388 Jianqi Ma, Zheto
 104 Jan 5, 2023
104 Jan 5, 2023

Code release for "BoxeR: Box-Attention for 2D and 3D Transformers"
BoxeR By Duy-Kien Nguyen, Jihong Ju, Olaf Booij, Martin R. Oswald, Cees Snoek. This repository is an official implementation of the paper BoxeR: Box-A
 111 Dec 7, 2022
111 Dec 7, 2022
Curso práctico: NLP de cero a cien 🤗
Curso Práctico: NLP de cero a cien Comprende todos los conceptos y arquitecturas clave del estado del arte del NLP y aplícalos a casos prácticos utili
 147 Jan 6, 2023
147 Jan 6, 2023
[CVPR'22] COAP: Learning Compositional Occupancy of People
COAP: Compositional Articulated Occupancy of People Paper | Video | Project Page This is the official implementation of the CVPR 2022 paper COAP: Lear
 111 Dec 11, 2022
111 Dec 11, 2022

B-cos Networks: Attention is All we Need for Interpretability
Convolutional Dynamic Alignment Networks for Interpretable Classifications M. Böhle, M. Fritz, B. Schiele. B-cos Networks: Alignment is All we Need fo
 58 Dec 23, 2022
58 Dec 23, 2022
Multi-Scale Temporal Frequency Convolutional Network With Axial Attention for Speech Enhancement
MTFAA-Net Unofficial PyTorch implementation of Baidu's MTFAA-Net: "Multi-Scale Temporal Frequency Convolutional Network With Axial Attention for Speec
 87 Dec 19, 2022
87 Dec 19, 2022

Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
CoCa - Pytorch Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch. They were able to elegantly fit in contras
565 Dec 30, 2022
![[ICML 2022] The official implementation of Graph Stochastic Attention (GSAT).](https://github.com/Graph-COM/GSAT/raw/main/data/arch.png)
[ICML 2022] The official implementation of Graph Stochastic Attention (GSAT).
Graph Stochastic Attention (GSAT) The official implementation of GSAT for our paper: Interpretable and Generalizable Graph Learning via Stochastic Att
 85 Nov 27, 2022
85 Nov 27, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
 9 Jun 26, 2022
9 Jun 26, 2022
Codes for "Efficient Long-Range Attention Network for Image Super-resolution"
ELAN Codes for "Efficient Long-Range Attention Network for Image Super-resolution", arxiv link. Dependencies & Installation Please refer to the follow
 124 Dec 22, 2022
124 Dec 22, 2022
Official implementation of cosformer-attention in cosFormer: Rethinking Softmax in Attention
cosFormer Official implementation of cosformer-attention in cosFormer: Rethinking Softmax in Attention Update log 2022/2/28 Add core code License This
 120 Dec 15, 2022
120 Dec 15, 2022

QuadTree Attention for Vision Transformers (ICLR2022)
This repository contains codes for quadtree attention. This repo contains codes for feature matching, image classficiation, object detection and seman
 222 Dec 28, 2022
222 Dec 28, 2022

(CVPR 2022) Pytorch implementation of "Self-supervised transformers for unsupervised object discovery using normalized cut"
(CVPR 2022) TokenCut Pytorch implementation of Tokencut: Self-supervised Transformers for Unsupervised Object Discovery using Normalized Cut Yangtao W
 200 Jan 2, 2023
200 Jan 2, 2023
.png)
Contextual Attention Network: Transformer Meets U-Net
Contextual Attention Network: Transformer Meets U-Net Contexual attention network for medical image segmentation with state of the art results on skin
 67 Nov 28, 2022
67 Nov 28, 2022
SciFive: a text-text transformer model for biomedical literature
SciFive SciFive provided a Text-Text framework for biomedical language and natural language in NLP. Under the T5's framework and desrbibed in the pape
 54 Dec 24, 2022
54 Dec 24, 2022

Official implementation for "QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation" (CVPR 2022)
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation (CVPR2022) https://arxiv.org/abs/2203.08483 Unpaired image-to-image (I2I
50 Dec 16, 2022

Implementation of a protein autoregressive language model, but with autoregressive infilling objective (editing subsequences capability)
Protein GLM (wip) Implementation of a protein autoregressive language model, but with autoregressive infilling objective (editing subsequences capabil
17 May 6, 2022

Implementation of 🦩 Flamingo, state-of-the-art few-shot visual question answering attention net out of Deepmind, in Pytorch
🦩 Flamingo - Pytorch Implementation of Flamingo, state-of-the-art few-shot visual question answering attention net, in Pytorch. It will include the p
630 Dec 28, 2022

Implementation of the GVP-Transformer, which was used in the paper "Learning inverse folding from millions of predicted structures" for de novo protein design alongside Alphafold2
GVP Transformer (wip) Implementation of the GVP-Transformer, which was used in the paper Learning inverse folding from millions of predicted structure
19 May 6, 2022

Official Implementation of HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation by Lukas Hoyer, Dengxin Dai, and Luc Van Gool [Arxiv] [Paper] Overview Unsup
 149 Dec 28, 2022
149 Dec 28, 2022
![[CVPRW 2022] Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network](https://github.com/IIGROUP/AHIQ/raw/main/Figures/architecture.png)
[CVPRW 2022] Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Attention Helps CNN See Better: Hybrid Image Quality Assessment Network [CVPRW 2022] Code for Hybrid Image Quality Assessment Network [paper] [code] T
 49 Dec 11, 2022
49 Dec 11, 2022

code for paper"A High-precision Semantic Segmentation Method Combining Adversarial Learning and Attention Mechanism"
PyTorch implementation of UAGAN(U-net Attention Generative Adversarial Networks) This repository contains the source code for the paper "A High-precis
 8 Apr 25, 2022
8 Apr 25, 2022

The code is for the paper "A Self-Distillation Embedded Supervised Affinity Attention Model for Few-Shot Segmentation"
SD-AANet The code is for the paper "A Self-Distillation Embedded Supervised Affinity Attention Model for Few-Shot Segmentation" [arxiv] Overview confi
 9 Nov 7, 2022
9 Nov 7, 2022

Implementation of MeMOT - Multi-Object Tracking with Memory - in Pytorch
MeMOT - Pytorch (wip) Implementation of MeMOT - Multi-Object Tracking with Memory - in Pytorch. This paper is just one in a line of work, but importan
15 May 9, 2022

Learning to compose soft prompts for compositional zero-shot learning.
Compositional Soft Prompting (CSP) Compositional soft prompting (CSP), a parameter-efficient learning technique to improve the zero-shot compositional
 32 Jan 2, 2023
32 Jan 2, 2023
Attention-based CNN-LSTM and XGBoost hybrid model for stock prediction
Attention-based CNN-LSTM and XGBoost hybrid model for stock prediction Requirements The code has been tested running under Python 3.7.4, with the foll
 84 Jan 1, 2023
84 Jan 1, 2023

Implementation of the Hybrid Perception Block and Dual-Pruned Self-Attention block from the ITTR paper for Image to Image Translation using Transformers
ITTR - Pytorch Implementation of the Hybrid Perception Block (HPB) and Dual-Pruned Self-Attention (DPSA) block from the ITTR paper for Image to Image
17 Dec 23, 2022
Implementation of a memory efficient multi-head attention as proposed in the paper, "Self-attention Does Not Need O(n²) Memory"
Memory Efficient Attention Pytorch Implementation of a memory efficient multi-head attention as proposed in the paper, Self-attention Does Not Need O(
180 Jan 5, 2023
Using this repository you can send mails to multiple recipients.Was created in support of Ukraine, to turn society`s attention to war.
mails-in-support-of-UA Using this repository you can send mails to multiple recipients.Was created in support of Ukraine, to turn society`s attention
 2 Mar 4, 2022
2 Mar 4, 2022

Job-Recommend-Competition - Vectorwise Interpretable Attentions for Multimodal Tabular Data
SiD - Simple Deep Model Vectorwise Interpretable Attentions for Multimodal Tabul
 40 Dec 22, 2022
40 Dec 22, 2022
End-to-end image captioning with EfficientNet-b3 + LSTM with Attention
Image captioning End-to-end image captioning with EfficientNet-b3 + LSTM with Attention Model is seq2seq model. In the encoder pretrained EfficientNet
 2 Feb 10, 2022
2 Feb 10, 2022

HAIS_2GNN: 3D Visual Grounding with Graph and Attention
HAIS_2GNN: 3D Visual Grounding with Graph and Attention This repository is for the HAIS_2GNN research project. Tao Gu, Yue Chen Introduction The motiv
 1 Nov 26, 2022
1 Nov 26, 2022
DCSAU-Net: A Deeper and More Compact Split-Attention U-Net for Medical Image Segmentation
DCSAU-Net: A Deeper and More Compact Split-Attention U-Net for Medical Image Segmentation By Qing Xu, Wenting Duan and Na He Requirements pytorch==1.1
 20 Dec 9, 2022
20 Dec 9, 2022
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
 0 Feb 8, 2022
0 Feb 8, 2022
A pure PyTorch implementation of the loss described in "Online Segment to Segment Neural Transduction"
ssnt-loss ℹ️ This is a WIP project. the implementation is still being tested. A pure PyTorch implementation of the loss described in "Online Segment t
 1 Feb 9, 2022
1 Feb 9, 2022
An implementation of IMLE-Net: An Interpretable Multi-level Multi-channel Model for ECG Classification
IMLE-Net: An Interpretable Multi-level Multi-channel Model for ECG Classification The repostiory consists of the code, results and data set links for
 12 Dec 26, 2022
12 Dec 26, 2022
Pytorch implementation of the paper "Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization"
Pytorch implementation of the paper "Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization"
 4 Sep 18, 2022
4 Sep 18, 2022

An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax
Simple Transformer An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax. Note: The only ex
 29 Jun 16, 2022
29 Jun 16, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022
PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks
AttentionHTR PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks. Scene Text
 31 Dec 22, 2022
31 Dec 22, 2022
Framework for training options with different attention mechanism and using them to solve downstream tasks.
Using Attention in HRL Framework for training options with different attention mechanism and using them to solve downstream tasks. Requirements GPU re
 5 Nov 3, 2022
5 Nov 3, 2022

Official code of Team Yao at Multi-Modal-Fact-Verification-2022
Official code of Team Yao at Multi-Modal-Fact-Verification-2022 A Multi-Modal Fact Verification dataset released as part of the De-Factify workshop in
 11 Nov 15, 2022
11 Nov 15, 2022
This repository is for Contrastive Embedding Distribution Refinement and Entropy-Aware Attention Network (CEDR)
CEDR This repository is for Contrastive Embedding Distribution Refinement and Entropy-Aware Attention Network (CEDR) introduced in the following paper
 3 Feb 27, 2022
3 Feb 27, 2022
Sinkformers: Transformers with Doubly Stochastic Attention
Code for the paper : "Sinkformers: Transformers with Doubly Stochastic Attention" Paper You will find our paper here. Compat This package has been dev
 31 Dec 29, 2022
31 Dec 29, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
 68 Dec 16, 2022
68 Dec 16, 2022

ComPhy: Compositional Physical Reasoning ofObjects and Events from Videos
ComPhy This repository holds the code for the paper. ComPhy: Compositional Physical Reasoning ofObjects and Events from Videos, (Under review) PDF Pro
 29 Dec 29, 2022
29 Dec 29, 2022

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022
Static Features Classifier - A static features classifier for Point-Could clusters using an Attention-RNN model
Static Features Classifier This is a static features classifier for Point-Could
 1 Jan 25, 2022
1 Jan 25, 2022
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline. The pipeline accepts english text as input and returns the French translation.
 1 Jan 24, 2022
1 Jan 24, 2022

Pytorch implementation of ICASSP 2022 paper Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
6 Sep 21, 2022

Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 3 Oct 31, 2022
3 Oct 31, 2022
HistoSeg : Quick attention with multi-loss function for multi-structure segmentation in digital histology images
HistoSeg : Quick attention with multi-loss function for multi-structure segmentation in digital histology images Histological Image Segmentation This
 11 Dec 16, 2022
11 Dec 16, 2022
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022
GalaXC: Graph Neural Networks with Labelwise Attention for Extreme Classification
GalaXC GalaXC: Graph Neural Networks with Labelwise Attention for Extreme Classification @InProceedings{Saini21, author = {Saini, D. and Jain,
 28 Dec 5, 2022
28 Dec 5, 2022
Seq2seq attn - Use the Seq2Seq method to implement machine translation and introduce Attention mechanism to improve the results
Seq2seq_attn Use the Seq2Seq method to implement machine translation and use the
 1 Jun 28, 2022
1 Jun 28, 2022
Unofficial PyTorch Implementation of "Augmenting Convolutional networks with attention-based aggregation"
Pytorch Implementation of Augmenting Convolutional networks with attention-based aggregation This is the unofficial PyTorch Implementation of "Augment
 20 Sep 9, 2022
20 Sep 9, 2022
Escaping the Gradient Vanishing: Periodic Alternatives of Softmax in Attention Mechanism
Period-alternatives-of-Softmax Experimental Demo for our paper 'Escaping the Gradient Vanishing: Periodic Alternatives of Softmax in Attention Mechani
 0 Sep 6, 2021
0 Sep 6, 2021

Official implementation of "Refiner: Refining Self-attention for Vision Transformers".
RefinerViT This repo is the official implementation of "Refiner: Refining Self-attention for Vision Transformers". The repo is build on top of timm an
 101 Dec 29, 2022
101 Dec 29, 2022

RETRO-pytorch - Implementation of RETRO, Deepmind's Retrieval based Attention net, in Pytorch
RETRO - Pytorch (wip) Implementation of RETRO, Deepmind's Retrieval based Attent
556 Jan 4, 2023

Implementation of Memory-Compressed Attention, from the paper "Generating Wikipedia By Summarizing Long Sequences"
Memory Compressed Attention Implementation of the Self-Attention layer of the proposed Memory-Compressed Attention, in Pytorch. This repository offers
47 Dec 23, 2022
Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2018)" and "CBAM: Convolutional Block Attention Module (ECCV2018)"
BAM and CBAM Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2018)" and "CBAM: Convolutional Block Attention Module (ECCV2018)" Updat
 1.7k Jan 1, 2023
1.7k Jan 1, 2023

An implementation of the efficient attention module.
Efficient Attention An implementation of the efficient attention module. Description Efficient attention is an attention mechanism that substantially
 194 Dec 15, 2022
194 Dec 15, 2022
This repository contains an implementation of the Permutohedral Attention Module in Pytorch
Permutohedral_attention_module This repository contains an implementation of the Permutohedral Attention Module
 26 Nov 27, 2022
26 Nov 27, 2022
The code for Expectation-Maximization Attention Networks for Semantic Segmentation (ICCV'2019 Oral)
EMANet News The bug in loading the pretrained model is now fixed. I have updated the .pth. To use it, download it again. EMANet-101 gets 80.99 on the
 663 Nov 30, 2022
663 Nov 30, 2022

Pytorch implementation of Compressive Transformers, from Deepmind
Compressive Transformer in Pytorch Pytorch implementation of Compressive Transformers, a variant of Transformer-XL with compressed memory for long-ran
118 Dec 1, 2022
Implementation of Axial attention - attending to multi-dimensional data efficiently
Axial Attention Implementation of Axial attention in Pytorch. A simple but powerful technique to attend to multi-dimensional data efficiently. It has
250 Dec 25, 2022
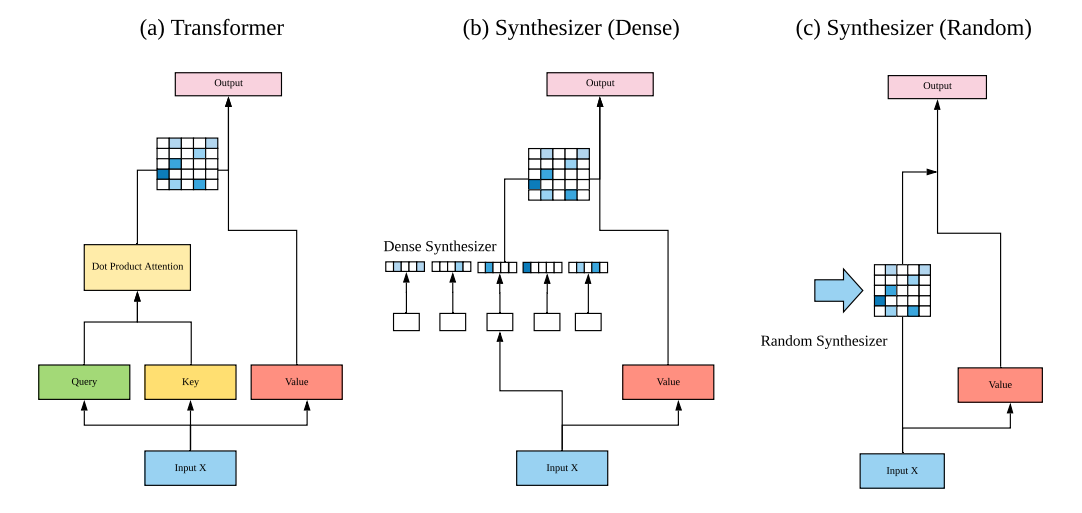
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch Reference Paper URL Author: Yi Tay, Dara Bahri, Donald Metzler
 66 Nov 30, 2022
66 Nov 30, 2022

My take on a practical implementation of Linformer for Pytorch.
Linformer Pytorch Implementation A practical implementation of the Linformer paper. This is attention with only linear complexity in n, allowing for v
 349 Dec 25, 2022
349 Dec 25, 2022

Implementation of Kronecker Attention in Pytorch
Kronecker Attention Pytorch Implementation of Kronecker Attention in Pytorch. Results look less than stellar, but if someone found some context where
16 May 6, 2022

Implementation of Memformer, a Memory-augmented Transformer, in Pytorch
Memformer - Pytorch Implementation of Memformer, a Memory-augmented Transformer, in Pytorch. It includes memory slots, which are updated with attentio
60 Nov 6, 2022
![[NeurIPS 2020] Official Implementation:](https://github.com/giannisdaras/smyrf/raw/master/visuals/quality_degradation.png)
[NeurIPS 2020] Official Implementation: "SMYRF: Efficient Attention using Asymmetric Clustering".
SMYRF: Efficient attention using asymmetric clustering Get started: Abstract We propose a novel type of balanced clustering algorithm to approximate a
 46 Dec 22, 2022
46 Dec 22, 2022
![[ACM MM 2021] TSA-Net: Tube Self-Attention Network for Action Quality Assessment](https://github.com/Shunli-Wang/TSA-Net/raw/main/fig/TSA-Net.jpg)
[ACM MM 2021] TSA-Net: Tube Self-Attention Network for Action Quality Assessment
Tube Self-Attention Network (TSA-Net) This repository contains the PyTorch implementation for paper TSA-Net: Tube Self-Attention Network for Action Qu
 18 Dec 23, 2022
18 Dec 23, 2022

LightNet++: Boosted Light-weighted Networks for Real-time Semantic Segmentation
LightNet++ !!!New Repo.!!! ⇒ EfficientNet.PyTorch: Concise, Modular, Human-friendly PyTorch implementation of EfficientNet with Pre-trained Weights !!
 237 Jan 5, 2023
237 Jan 5, 2023
The official implementation of ELSA: Enhanced Local Self-Attention for Vision Transformer
ELSA: Enhanced Local Self-Attention for Vision Transformer By Jingkai Zhou, Pich
 87 Dec 19, 2022
87 Dec 19, 2022

Repository of Vision Transformer with Deformable Attention
Vision Transformer with Deformable Attention This repository contains the code for the paper Vision Transformer with Deformable Attention [arXiv]. Int
 410 Jan 3, 2023
410 Jan 3, 2023
This repository provides the official implementation of 'Learning to ignore: rethinking attention in CNNs' accepted in BMVC 2021.
inverse_attention This repository provides the official implementation of 'Learning to ignore: rethinking attention in CNNs' accepted in BMVC 2021. Le
 5 Jul 8, 2022
5 Jul 8, 2022
Unofficial PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution
PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution [arXiv 2021].
 122 Dec 12, 2022
122 Dec 12, 2022
The official TensorFlow implementation of the paper Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition
Action Transformer A Self-Attention Model for Short-Time Human Action Recognition This repository contains the official TensorFlow implementation of t
 20 Jan 3, 2023
20 Jan 3, 2023
Alignment Attention Fusion framework for Few-Shot Object Detection
AAF framework Framework generalities This repository contains the code of the AAF framework proposed in this paper. The main idea behind this work is
 20 Dec 16, 2022
20 Dec 16, 2022

Implementation of a Transformer using ReLA (Rectified Linear Attention)
ReLA (Rectified Linear Attention) Transformer Implementation of a Transformer using ReLA (Rectified Linear Attention). It will also contain an attempt
49 Oct 14, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions Project Page | Paper If you find our work useful for your research, please con
 96 Jan 4, 2023
96 Jan 4, 2023

Official PyTorch implementation of "The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation" (ICCV 21).
CenterGroup This the official implementation of our ICCV 2021 paper The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person P
 43 Dec 25, 2022
43 Dec 25, 2022

Code for "Multi-Time Attention Networks for Irregularly Sampled Time Series", ICLR 2021.
Multi-Time Attention Networks (mTANs) This repository contains the PyTorch implementation for the paper Multi-Time Attention Networks for Irregularly
 68 Dec 17, 2022
68 Dec 17, 2022

This is a super simple visualization toolbox (script) for transformer attention visualization ✌
Trans_attention_vis This is a super simple visualization toolbox (script) for transformer attention visualization ✌ 1. How to prepare your attention m
 3 Jul 9, 2022
3 Jul 9, 2022
RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality?
RaftMLP RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality? By Yuki Tatsunami and Masato Taki (Rikkyo University) [arxiv]
 20 Aug 31, 2022
20 Aug 31, 2022

In this project we use both Resnet and Self-attention layer for cat, dog and flower classification.
cdf_att_classification classes = {0: 'cat', 1: 'dog', 2: 'flower'} In this project we use both Resnet and Self-attention layer for cdf-Classification.
 3 Nov 23, 2022
3 Nov 23, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

GAT - Graph Attention Network (PyTorch) 💻 + graphs + 📣 = ❤️
GAT - Graph Attention Network (PyTorch) 💻 + graphs + 📣 = ❤️ This repo contains a PyTorch implementation of the original GAT paper ( 🔗 Veličković et
 1.9k Jan 9, 2023
1.9k Jan 9, 2023
Fast convergence of detr with spatially modulated co-attention
Fast convergence of detr with spatially modulated co-attention Usage There are no extra compiled components in SMCA DETR and package dependencies are
 135 Dec 7, 2022
135 Dec 7, 2022

SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition PDF Abstract Explainable artificial intelligence has been gaining attention
 87 Dec 26, 2022
87 Dec 26, 2022
Custom studies about block sparse attention.
Block Sparse Attention 研究总结 本人近半年来对Block Sparse Attention(块稀疏注意力)的研究总结(持续更新中)。按时间顺序,主要分为如下三部分: PyTorch 自定义 CUDA 算子——以矩阵乘法为例 基于 Triton 的 Block Sparse A
 2 Jan 9, 2022
2 Jan 9, 2022