1678 Repositories
Python Drug-Rating-Prediction-Portal-from-Drug-Reviews-Dataset-NLP-ML Libraries

Quickly and easily create / train a custom DeepDream model
Dream-Creator This project aims to simplify the process of creating a custom DeepDream model by using pretrained GoogleNet models and custom image dat
 56 Jan 3, 2023
56 Jan 3, 2023
Semi Supervised Learning for Medical Image Segmentation, a collection of literature reviews and code implementations.
Semi-supervised-learning-for-medical-image-segmentation. Recently, semi-supervised image segmentation has become a hot topic in medical image computin
 1.3k Jan 3, 2023
1.3k Jan 3, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022
Universal Adversarial Triggers for Attacking and Analyzing NLP (EMNLP 2019)
Universal Adversarial Triggers for Attacking and Analyzing NLP This is the official code for the EMNLP 2019 paper, Universal Adversarial Triggers for
 248 Dec 17, 2022
248 Dec 17, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022

Wind Speed Prediction using LSTMs in PyTorch
Implementation of Deep-Forecast using PyTorch Deep Forecast: Deep Learning-based Spatio-Temporal Forecasting Adapted from original implementation Setu
 151 Dec 14, 2022
151 Dec 14, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

The PASS dataset: pretrained models and how to get the data - PASS: Pictures without humAns for Self-Supervised Pretraining
The PASS dataset: pretrained models and how to get the data - PASS: Pictures without humAns for Self-Supervised Pretraining
 249 Dec 22, 2022
249 Dec 22, 2022
A crowdsourced dataset of dialogues grounded in social contexts involving utilization of commonsense.
A crowdsourced dataset of dialogues grounded in social contexts involving utilization of commonsense.
 62 Dec 20, 2022
62 Dec 20, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset.
Med-VQA In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset. Two of these are made on top of Facebook AI Reasearch's Multi-Mo
 8 Apr 14, 2022
8 Apr 14, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 4, 2023
7.1k Jan 4, 2023

A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing.
AnimeGAN A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing. Randomly Generated Images The images are
 1.2k Jan 3, 2023
1.2k Jan 3, 2023

Pixel-wise segmentation on VOC2012 dataset using pytorch.
PiWiSe Pixel-wise segmentation on the VOC2012 dataset using pytorch. FCN SegNet PSPNet UNet RefineNet For a more complete implementation of segmentati
 378 Dec 30, 2022
378 Dec 30, 2022
Recurrent Variational Autoencoder that generates sequential data implemented with pytorch
Pytorch Recurrent Variational Autoencoder Model: This is the implementation of Samuel Bowman's Generating Sentences from a Continuous Space with Kim's
 347 Nov 14, 2022
347 Nov 14, 2022
A Domain Specific Language (DSL) for building language patterns. These can be later compiled into spaCy patterns, pure regex, or any other format
RITA DSL This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy co
 60 Sep 26, 2022
60 Sep 26, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
 15.2k Jan 1, 2023
15.2k Jan 1, 2023
Code and dataset for the EMNLP 2021 Finding paper "Can NLI Models Verify QA Systems’ Predictions?"
Code and dataset for the EMNLP 2021 Finding paper "Can NLI Models Verify QA Systems’ Predictions?"
 22 Oct 21, 2022
22 Oct 21, 2022
A2T: Towards Improving Adversarial Training of NLP Models (EMNLP 2021 Findings)
A2T: Towards Improving Adversarial Training of NLP Models This is the source code for the EMNLP 2021 (Findings) paper "Towards Improving Adversarial T
17 Oct 15, 2022

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 50 Dec 21, 2022
50 Dec 21, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023

grungegirl is the hacker's drug encyclopedia. programmed in python for maximum modularity and ease of configuration.
grungegirl. cli-based drug search for girls. welcome. grungegirl is aiming to be the premier drug culture application. it is the hacker's encyclopedia
 10 Oct 2, 2022
10 Oct 2, 2022
![[ICCV 2021] FaPN: Feature-aligned Pyramid Network for Dense Image Prediction](https://github.com/ShihuaHuang95/FaPN-full/raw/main/assert/fpn_vs_fapn.png)
[ICCV 2021] FaPN: Feature-aligned Pyramid Network for Dense Image Prediction
FaPN: Feature-aligned Pyramid Network for Dense Image Prediction [arXiv] [Project Page] @inproceedings{ huang2021fapn, title={{FaPN}: Feature-alig
 23 Jul 22, 2022
23 Jul 22, 2022
Code of paper "Compositionally Generalizable 3D Structure Prediction"
Compositionally Generalizable 3D Structure Prediction In this work, We bring in the concept of compositional generalizability and factorizes the 3D sh
 30 Dec 17, 2022
30 Dec 17, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022
Code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
This repository contains the code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
 28 Nov 10, 2022
28 Nov 10, 2022

CDLA: A Chinese document layout analysis (CDLA) dataset
CDLA: A Chinese document layout analysis (CDLA) dataset 介绍 CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 正文 标题 图片 图片标题 表格 表格标题 页眉 页脚 注释 公式 Text Title
 84 Dec 28, 2022
84 Dec 28, 2022
A daily updated JSON dataset of all the Open House London venues, events, and metadata
Open House London listings data All of it. Automatically scraped hourly with updates committed to git, autogenerated per-day CSV's, and autogenerated
 4 Jan 1, 2022
4 Jan 1, 2022
A set of tools for converting a darknet dataset to COCO format working with YOLOX
darknet格式数据→COCO darknet训练数据目录结构(详情参见dataset/darknet): darknet ├── class.names ├── gen_config.data ├── gen_train.txt ├── gen_valid.txt └── images
 148 Jan 3, 2023
148 Jan 3, 2023
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022
MVGCN: a novel multi-view graph convolutional network (MVGCN) framework for link prediction in biomedical bipartite networks.
MVGCN MVGCN: a novel multi-view graph convolutional network (MVGCN) framework for link prediction in biomedical bipartite networks. Developer: Fu Hait
 13 Dec 1, 2022
13 Dec 1, 2022
A multilingual version of MS MARCO passage ranking dataset
mMARCO A multilingual version of MS MARCO passage ranking dataset This repository presents a neural machine translation-based method for translating t
 75 Dec 27, 2022
75 Dec 27, 2022
A script to generate the m3u playlist containing direct streamable file (.mpd or MPEG-DASH or DASH) based on the channels that the user has subscribed on the Tata Sky portal. You just have to login using your password or otp that's it .
Tata Sky IPTV Script generator A script to generate the m3u playlist containing direct streamable file (.mpd or MPEG-DASH or DASH) based on the channe
 19 Dec 3, 2021
19 Dec 3, 2021

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
 7.6k Jan 1, 2023
7.6k Jan 1, 2023
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022
The FinQA dataset from paper: FinQA: A Dataset of Numerical Reasoning over Financial Data
Data and code for EMNLP 2021 paper "FinQA: A Dataset of Numerical Reasoning over Financial Data"
 114 Dec 29, 2022
114 Dec 29, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
 81 Dec 9, 2022
81 Dec 9, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022
A script to generate the m3u playlist containing direct streamable file (.mpd or MPEG-DASH or DASH) based on the channels that the user has subscribed on the Tata Sky portal. You just have to login using your password or otp that's it .
Tata Sky IPTV Script generator A script to generate the m3u playlist containing direct streamable file (.mpd or MPEG-DASH or DASH) based on the channe
17 Nov 23, 2021
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
297 Dec 29, 2022

Python scripts for performing stereo depth estimation using the HITNET Tensorflow model.
HITNET-Stereo-Depth-estimation Python scripts for performing stereo depth estimation using the HITNET Tensorflow model from Google Research. Stereo de
 76 Jan 2, 2023
76 Jan 2, 2023

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022
🥈78th place in Riiid Answer Correctness Prediction competition
Riiid Answer Correctness Prediction Introduction This repository is the code that placed 78th in Riiid Answer Correctness Prediction competition. Requ
 10 Jul 14, 2022
10 Jul 14, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
ONNX Runtime Web demo is an interactive demo portal showing real use cases running ONNX Runtime Web in VueJS.
ONNX Runtime Web demo is an interactive demo portal showing real use cases running ONNX Runtime Web in VueJS. It currently supports four examples for you to quickly experience the power of ONNX Runtime Web.
58 Dec 18, 2022
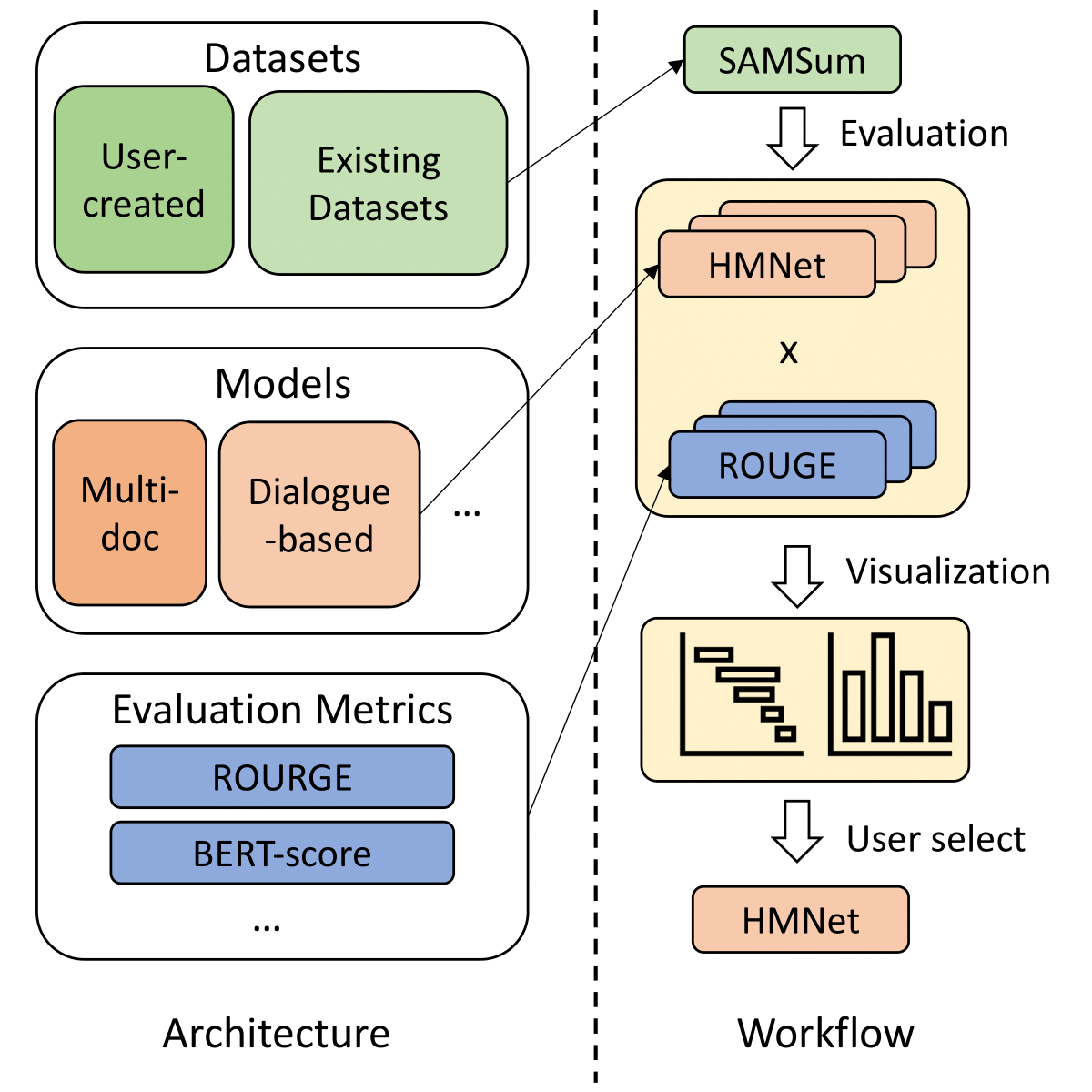
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection (ICCV 2021)
Preparation Please see dataset/README.md to get more details about our datasets-VIL100 Please see INSTALL.md to install environment and evaluation too
 82 Dec 15, 2022
82 Dec 15, 2022

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022
Ask for weather information like a human
weather-nlp About Ask for weather information like a human. Goals Understand typical questions like: Hourly temperatures in Potsdam on 2020-09-15. Rai
 5 Oct 29, 2022
5 Oct 29, 2022

Official implementation of particle-based models (GNS and DPI-Net) on the Physion dataset.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines [paper] Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, Hsiao-Y
 18 Dec 19, 2022
18 Dec 19, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
EMNLP 2021 Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections Ruiqi Zhong, Kristy Lee*, Zheng Zhang*, Dan Klein EMN
 42 Nov 3, 2022
42 Nov 3, 2022
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
 230 Nov 22, 2022
230 Nov 22, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022

LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision Project | Arxiv | Abstract It is very challenging for various visual tasks such as image
 377 Jan 7, 2023
377 Jan 7, 2023

NUANCED is a user-centric conversational recommendation dataset that contains 5.1k annotated dialogues and 26k high-quality user turns.
NUANCED: Natural Utterance Annotation for Nuanced Conversation with Estimated Distributions Overview NUANCED is a user-centric conversational recommen
 18 Dec 28, 2021
18 Dec 28, 2021
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
7.1k Jan 5, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
176 Dec 28, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023

This repository is based on Ultralytics/yolov5, with adjustments to enable rotate prediction boxes.
Rotate-Yolov5 This repository is based on Ultralytics/yolov5, with adjustments to enable rotate prediction boxes. Section I. Description The codes are
 90 Dec 13, 2022
90 Dec 13, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022

PyTorch DepthNet Training on Still Box dataset
DepthNet training on Still Box Project page This code can replicate the results of our paper that was published in UAVg-17. If you use this repo in yo
 115 Nov 21, 2022
115 Nov 21, 2022
PyTorch experiments with the Zalando fashion-mnist dataset
zalando-pytorch PyTorch experiments with the Zalando fashion-mnist dataset Project Organization ├── LICENSE ├── Makefile - Makefile with co
 31 Sep 25, 2021
31 Sep 25, 2021

YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset
YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research int
 73 Dec 16, 2022
73 Dec 16, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

A PyTorch implementation of the Relational Graph Convolutional Network (RGCN).
Torch-RGCN Torch-RGCN is a PyTorch implementation of the RGCN, originally proposed by Schlichtkrull et al. in Modeling Relational Data with Graph Conv
 66 Nov 30, 2022
66 Nov 30, 2022

Progressive Coordinate Transforms for Monocular 3D Object Detection
Progressive Coordinate Transforms for Monocular 3D Object Detection This repository is the official implementation of PCT. Introduction In this paper,
58 Nov 6, 2022