1678 Repositories
Python Drug-Rating-Prediction-Portal-from-Drug-Reviews-Dataset-NLP-ML Libraries
Official PyTorch implementation of MAAD: A Model and Dataset for Attended Awareness
MAAD: A Model for Attended Awareness in Driving Install // Datasets // Training // Experiments // Analysis // License Official PyTorch implementation
 7 Oct 16, 2022
7 Oct 16, 2022
This repository contains the code for the paper in EMNLP 2021: "HRKD: Hierarchical Relational Knowledge Distillation for Cross-domain Language Model Compression".
HRKD: Hierarchical Relational Knowledge Distillation for Cross-domain Language Model Compression This repository contains the code for the paper in EM
 2 Mar 24, 2022
2 Mar 24, 2022

PyTorch implementation of "Dataset Knowledge Transfer for Class-Incremental Learning Without Memory" (WACV2022)
Dataset Knowledge Transfer for Class-Incremental Learning Without Memory [Paper] [Slides] Summary Introduction Installation Reproducing results Citati
 5 Dec 5, 2022
5 Dec 5, 2022
Link prediction using Multiple Order Local Information (MOLI)
Understanding the network formation pattern for better link prediction Authors: yujiating@amss.ac.cn lywu@amss.ac.cn Overview: Link prediction using M
 0 Oct 18, 2021
0 Oct 18, 2021
Using Clinical Drug Representations for Improving Mortality and Length of Stay Predictions
Using Clinical Drug Representations for Improving Mortality and Length of Stay Predictions Usage Clone the code to local. https://github.com/tanlab/MI
 3 Oct 18, 2022
3 Oct 18, 2022
Simultaneous Demand Prediction and Planning
Simultaneous Demand Prediction and Planning Dependencies Python packages: Pytorch, scikit-learn, Pandas, Numpy, PyYAML Data POI: data/poi Road network
 1 Sep 1, 2022
1 Sep 1, 2022

Official implementation of the paper: "LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech"
LDNet Author: Wen-Chin Huang (Nagoya University) Email: wen.chinhuang@g.sp.m.is.nagoya-u.ac.jp This is the official implementation of the paper "LDNet
 40 Nov 20, 2022
40 Nov 20, 2022
The description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts.
FMFCC-A This project is the description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts. The FMFCC-A dataset is shared through BaiduCl
 18 Dec 24, 2022
18 Dec 24, 2022
A graph-to-sequence model for one-step retrosynthesis and reaction outcome prediction.
Graph2SMILES A graph-to-sequence model for one-step retrosynthesis and reaction outcome prediction. 1. Environmental setup System requirements Ubuntu:
 29 Nov 18, 2022
29 Nov 18, 2022

Offcial implementation of "A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Prediction, ICCV-2021".
HF2-VAD Offcial implementation of "A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Predictio
 76 Dec 21, 2022
76 Dec 21, 2022

Wafer Fault Detection using MlOps Integration
Wafer Fault Detection using MlOps Integration This is an end to end machine learning project with MlOps integration for predicting the quality of wafe
 0 Mar 11, 2022
0 Mar 11, 2022
Diabetes Prediction with Logistic Regression
Diabetes Prediction with Logistic Regression Exploratory Data Analysis Data Preprocessing Model & Prediction Model Evaluation Model Validation: Holdou
 2 Oct 23, 2021
2 Oct 23, 2021
TensorFlow2 Classification Model Zoo playing with TensorFlow2 on the CIFAR-10 dataset.
Training CIFAR-10 with TensorFlow2(TF2) TensorFlow2 Classification Model Zoo. I'm playing with TensorFlow2 on the CIFAR-10 dataset. Architectures LeNe
 16 Sep 27, 2022
16 Sep 27, 2022

The implementation of the submitted paper "Deep Multi-Behaviors Graph Network for Voucher Redemption Rate Prediction" in SIGKDD 2021 Applied Data Science Track.
DMBGN: Deep Multi-Behaviors Graph Networks for Voucher Redemption Rate Prediction The implementation of the accepted paper "Deep Multi-Behaviors Graph
 10 Jul 12, 2022
10 Jul 12, 2022
[ICDMW 2020] Code and dataset for "DGTN: Dual-channel Graph Transition Network for Session-based Recommendation"
DGTN: Dual-channel Graph Transition Network for Session-based Recommendation This repository contains PyTorch Implementation of ICDMW 2020 (NeuRec @ I
 25 Nov 17, 2022
25 Nov 17, 2022
Beyond Clicks: Modeling Multi-Relational Item Graph for Session-Based Target Behavior Prediction
MGNN-SPred This is our Tensorflow implementation for the paper: WenWang,Wei Zhang, Shukai Liu, Qi Liu, Bo Zhang, Leyu Lin, and Hongyuan Zha. 2020. Bey
 18 Jan 2, 2023
18 Jan 2, 2023

CaFM-pytorch ICCV ACCEPT Introduction of dataset VSD4K
CaFM-pytorch ICCV ACCEPT Introduction of dataset VSD4K Our dataset VSD4K includes 6 popular categories: game, sport, dance, vlog, interview and city.
 96 Jul 5, 2022
96 Jul 5, 2022

Officially unofficial re-implementation of paper: Paint Transformer: Feed Forward Neural Painting with Stroke Prediction, ICCV 2021.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction [Paper] [Official Paddle Implementation] [Huggingface Gradio Demo] [Unofficial
 361 Oct 19, 2021
361 Oct 19, 2021

Web Scraping, Document Deduplication & GPT-2 Fine-tuning with a newly created scam dataset.
Web Scraping, Document Deduplication & GPT-2 Fine-tuning with a newly created scam dataset.
 18 Nov 28, 2022
18 Nov 28, 2022
PyTorch implementation of TSception V2 using DEAP dataset
TSception This is the PyTorch implementation of TSception V2 using DEAP dataset in our paper: Yi Ding, Neethu Robinson, Su Zhang, Qiuhao Zeng, Cuntai
 27 Dec 15, 2022
27 Dec 15, 2022
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
 18 Nov 18, 2022
18 Nov 18, 2022
A Dataset for Direct Quotation Extraction and Attribution in News Articles.
DirectQuote - A Dataset for Direct Quotation Extraction and Attribution in News Articles DirectQuote is a corpus containing 19,760 paragraphs and 10,3
 9 Sep 23, 2022
9 Sep 23, 2022

ViSD4SA, a Vietnamese Span Detection for Aspect-based sentiment analysis dataset
UIT-ViSD4SA PACLIC 35 General Introduction This repository contains the data of the paper: Span Detection for Vietnamese Aspect-Based Sentiment Analys
 5 Nov 13, 2022
5 Nov 13, 2022
Repository for MuSiQue: Multi-hop Questions via Single-hop Question Composition
🎵 MuSiQue: Multi-hop Questions via Single-hop Question Composition This is the repository for our paper "MuSiQue: Multi-hop Questions via Single-hop
 21 Jan 2, 2023
21 Jan 2, 2023
SciBERT is a BERT model trained on scientific text.
SciBERT is a BERT model trained on scientific text.
 1.2k Dec 24, 2022
1.2k Dec 24, 2022
Coarse implement of the paper "A Simultaneous Denoising and Dereverberation Framework with Target Decoupling", On DNS-2020 dataset, the DNSMOS of first stage is 3.42 and second stage is 3.47.
SDDNet Coarse implement of the paper "A Simultaneous Denoising and Dereverberation Framework with Target Decoupling", On DNS-2020 dataset, the DNSMOS
 43 Nov 21, 2022
43 Nov 21, 2022

We have a dataset of user performances. The project is to develop a machine learning model that will predict the salaries of baseball players.
Salary-Prediction-with-Machine-Learning 1. Business Problem Can a machine learning project be implemented to estimate the salaries of baseball players
 9 Oct 14, 2022
9 Oct 14, 2022
The first online catalogue for Arabic NLP datasets.
Masader The first online catalogue for Arabic NLP datasets. This catalogue contains 200 datasets with more than 25 metadata annotations for each datas
 94 Dec 26, 2022
94 Dec 26, 2022

Deeply Supervised, Layer-wise Prediction-aware (DSLP) Transformer for Non-autoregressive Neural Machine Translation
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision Training Efficiency We show the training efficiency of our DSLP model b
 36 Oct 31, 2022
36 Oct 31, 2022
Official code for Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Official code for our Interspeech 2021 - Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset [1]*. Visually-grounded spoken language datasets c
 3 Jan 26, 2022
3 Jan 26, 2022
novel deep learning research works with PaddlePaddle
Research 发布基于飞桨的前沿研究工作,包括CV、NLP、KG、STDM等领域的顶会论文和比赛冠军模型。 目录 计算机视觉(Computer Vision) 自然语言处理(Natrual Language Processing) 知识图谱(Knowledge Graph) 时空数据挖掘(Spa
 1.5k Dec 29, 2022
1.5k Dec 29, 2022

Food Drinks and groceries Images Multi Lingual (FooDI-ML) dataset.
Food Drinks and groceries Images Multi Lingual (FooDI-ML) dataset.
 41 Jan 4, 2023
41 Jan 4, 2023

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 51 Jan 6, 2023
51 Jan 6, 2023

Code and Data for NeurIPS2021 Paper "A Dataset for Answering Time-Sensitive Questions"
Time-Sensitive-QA The repo contains the dataset and code for NeurIPS2021 (dataset track) paper Time-Sensitive Question Answering dataset. The dataset
 35 Nov 14, 2022
35 Nov 14, 2022
NLP, Machine learning
Netflix-recommendation-system NLP, Machine learning About Recommendation algorithms are at the core of the Netflix product. It provides their members
 6 Jan 12, 2022
6 Jan 12, 2022
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
18 Nov 18, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-quality pre-trained models from torchvision, MMLabs, and soon Pytorch Image Models. It orchestrates the end-to-end deep learning workflow allowing to train networks with easy-to-use robust high-performance libraries such as Pytorch-Lightning and Fastai
 789 Dec 29, 2022
789 Dec 29, 2022

Multiview 3D object detection on MultiviewC dataset through moft3d.
Multiview Orthographic Feature Transformation for 3D Object Detection Multiview 3D object detection on MultiviewC dataset through moft3d. Introduction
 20 Dec 21, 2022
20 Dec 21, 2022
Rethinking Transformer-based Set Prediction for Object Detection
Rethinking Transformer-based Set Prediction for Object Detection Here are the code for the ICCV paper. The code is adapted from Detectron2 and AdelaiD
 62 Dec 3, 2022
62 Dec 3, 2022
Official code for Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Official code for our Interspeech 2021 - Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset [1]*. Visually-grounded spoken language datasets c
3 Jan 26, 2022

Human4D Dataset tools for processing and visualization
HUMAN4D: A Human-Centric Multimodal Dataset for Motions & Immersive Media HUMAN4D constitutes a large and multimodal 4D dataset that contains a variet
 15 Nov 9, 2022
15 Nov 9, 2022
novel deep learning research works with PaddlePaddle
Research 发布基于飞桨的前沿研究工作,包括CV、NLP、KG、STDM等领域的顶会论文和比赛冠军模型。 目录 计算机视觉(Computer Vision) 自然语言处理(Natrual Language Processing) 知识图谱(Knowledge Graph) 时空数据挖掘(Spa
1.5k Jan 3, 2023
Deeply Supervised, Layer-wise Prediction-aware (DSLP) Transformer for Non-autoregressive Neural Machine Translation
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision Training Efficiency We show the training efficiency of our DSLP model b
37 Jan 4, 2023
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset (CVPR'19)
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset (CVPR'19) Tianyu Wang*, Xin Yang*, Ke Xu, Shaozhe Chen, Qiang Zhang, Ry
 177 Dec 1, 2022
177 Dec 1, 2022
Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers.
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
 2 Oct 14, 2021
2 Oct 14, 2021
PSML: A Multi-scale Time-series Dataset for Machine Learning in Decarbonized Energy Grids
PSML: A Multi-scale Time-series Dataset for Machine Learning in Decarbonized Energy Grids The electric grid is a key enabling infrastructure for the a
 19 Jan 7, 2023
19 Jan 7, 2023
Companion code for "Bayesian logistic regression for online recalibration and revision of risk prediction models with performance guarantees"
Companion code for "Bayesian logistic regression for online recalibration and revision of risk prediction models with performance guarantees" Installa
 0 Oct 13, 2021
0 Oct 13, 2021
This repository implements variational graph auto encoder by Thomas Kipf.
Variational Graph Auto-encoder in Pytorch This repository implements variational graph auto-encoder by Thomas Kipf. For details of the model, refer to
 215 Jan 2, 2023
215 Jan 2, 2023
Release of the ConditionalQA dataset
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
14 Oct 17, 2022
A cross-lingual COVID-19 fake news dataset
CrossFake An English-Chinese COVID-19 fake&real news dataset from the ICDMW 2021 paper below: Cross-lingual COVID-19 Fake News Detection. Jiangshu Du,
 11 Dec 1, 2022
11 Dec 1, 2022
Smart discord chatbot integrated with Dialogflow
academic-NLP-chatbot Smart discord chatbot integrated with Dialogflow to interact with students naturally and manage different classes in a school. De
 5 Oct 24, 2022
5 Oct 24, 2022

NLP topic mdel LDA - Gathered from New York Times website
NLP topic mdel LDA - Gathered from New York Times website
 1 Oct 14, 2021
1 Oct 14, 2021
Official implementation of "Motif-based Graph Self-Supervised Learning forMolecular Property Prediction"
Motif-based Graph Self-Supervised Learning for Molecular Property Prediction Official Pytorch implementation of NeurIPS'21 paper "Motif-based Graph Se
 71 Dec 20, 2022
71 Dec 20, 2022
Scraping news from Ucsal portal with Scrapy.
NewsScraping Esse é um projeto de raspagem das últimas noticias, de 2021, do portal da universidade Ucsal http://noosfero.ucsal.br/institucional Tecno
 0 Sep 30, 2021
0 Sep 30, 2021
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022

An end-to-end regression problem of predicting the price of properties in Bangalore.
Bangalore-House-Price-Prediction An end-to-end regression problem of predicting the price of properties in Bangalore. Deployed in Heroku using Flask.
 1 Nov 25, 2022
1 Nov 25, 2022

A synthetic texture-invariant dataset for object detection of UAVs
A synthetic dataset for object detection of UAVs This repository contains a synthetic datasets accompanying the paper Sim2Air - Synthetic aerial datas
 10 Aug 13, 2022
10 Aug 13, 2022

Acute ischemic stroke dataset
AISD Acute ischemic stroke dataset contains 397 Non-Contrast-enhanced CT (NCCT) scans of acute ischemic stroke with the interval from symptom onset to
 21 Sep 6, 2022
21 Sep 6, 2022
TEACh is a dataset of human-human interactive dialogues to complete tasks in a simulated household environment.
TEACh is a dataset of human-human interactive dialogues to complete tasks in a simulated household environment.
 32 Oct 13, 2021
32 Oct 13, 2021
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation (NeurIPS2021 Benchmark and Dataset Track)
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 174 Dec 22, 2022
174 Dec 22, 2022

This repository contains the files for running the Patchify GUI.
Repository Name Train-Test-Validation-Dataset-Generation App Name Patchify Description This app is designed for crop images and creating smal
 9 Feb 15, 2022
9 Feb 15, 2022
LIVECell - A large-scale dataset for label-free live cell segmentation
LIVECell dataset This document contains instructions of how to access the data associated with the submitted manuscript "LIVECell - A large-scale data
 112 Jan 7, 2023
112 Jan 7, 2023

Face Synthetics dataset is a collection of diverse synthetic face images with ground truth labels.
The Face Synthetics dataset Face Synthetics dataset is a collection of diverse synthetic face images with ground truth labels. It was introduced in ou
 608 Jan 2, 2023
608 Jan 2, 2023

Large Scale Multi-Illuminant (LSMI) Dataset for Developing White Balance Algorithm under Mixed Illumination
Large Scale Multi-Illuminant (LSMI) Dataset for Developing White Balance Algorithm under Mixed Illumination (ICCV 2021) Dataset License This work is l
 33 Jan 4, 2023
33 Jan 4, 2023
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

classification task on dataset-CIFAR10,by using Tensorflow/keras
CIFAR10-Tensorflow classification task on dataset-CIFAR10,by using Tensorflow/keras 在这一个库中,我使用Tensorflow与keras框架搭建了几个卷积神经网络模型,针对CIFAR10数据集进行了训练与测试。分别使
 3 Oct 17, 2021
3 Oct 17, 2021
Tribuo - A Java machine learning library
Tribuo - A Java prediction library (v4.1) Tribuo is a machine learning library in Java that provides multi-class classification, regression, clusterin
 1.1k Dec 28, 2022
1.1k Dec 28, 2022

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023

 200 Dec 27, 2022
200 Dec 27, 2022

Code for the paper Relation Prediction as an Auxiliary Training Objective for Improving Multi-Relational Graph Representations (AKBC 2021).
Relation Prediction as an Auxiliary Training Objective for Knowledge Base Completion This repo provides the code for the paper Relation Prediction as
 85 Jan 2, 2023
85 Jan 2, 2023
TEACh is a dataset of human-human interactive dialogues to complete tasks in a simulated household environment.
TEACh Task-driven Embodied Agents that Chat Aishwarya Padmakumar*, Jesse Thomason*, Ayush Shrivastava, Patrick Lange, Anjali Narayan-Chen, Spandana Ge
98 Dec 9, 2022
Exploratory Data Analysis for Employee Retention Dataset
Exploratory Data Analysis for Employee Retention Dataset Employee turn-over is a very costly problem for companies. The cost of replacing an employee
 2 Oct 1, 2021
2 Oct 1, 2021
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022
Train 🤗-transformers model with Poutyne.
poutyne-transformers Train 🤗 -transformers models with Poutyne. Installation pip install poutyne-transformers Example import torch from transformers
 2 Dec 18, 2022
2 Dec 18, 2022

Google's Meena transformer chatbot implementation
Here's my attempt at recreating Meena, a state of the art chatbot developed by Google Research and described in the paper Towards a Human-like Open-Domain Chatbot.
 94 Dec 25, 2022
94 Dec 25, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
A Python library for choreographing your machine learning research.
A Python library for choreographing your machine learning research.
270 Jan 6, 2023
Definition of a business problem according to Wilson Lower Bound Score and Time Based Average Rating
Wilson Lower Bound Score, Time Based Rating Average In this study I tried to calculate the product rating and sorting reviews more accurately. I have
 3 Sep 30, 2021
3 Sep 30, 2021
Signature remover is a NLP based solution which removes email signatures from the rest of the text.
Signature Remover Signature remover is a NLP based solution which removes email signatures from the rest of the text. It helps to enchance data conten
 8 Jan 6, 2023
8 Jan 6, 2023
customer churn prediction prevention in telecom industry using machine learning and survival analysis
Telco Customer Churn Prediction - Plotly Dash Application Description This dash application allows you to predict telco customer churn using machine l
 3 Nov 20, 2021
3 Nov 20, 2021
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
 39 Oct 5, 2021
39 Oct 5, 2021

TensorFlow implementation of "Variational Inference with Normalizing Flows"
[TensorFlow 2] Variational Inference with Normalizing Flows TensorFlow implementation of "Variational Inference with Normalizing Flows" [1] Concept Co
 7 Jun 8, 2022
7 Jun 8, 2022
Script to generate VAD dataset used in Asteroid recipe
About the dataset LibriVAD is an open source dataset for voice activity detection in noisy environments. It is derived from LibriSpeech signals (clean
 11 Sep 15, 2022
11 Sep 15, 2022
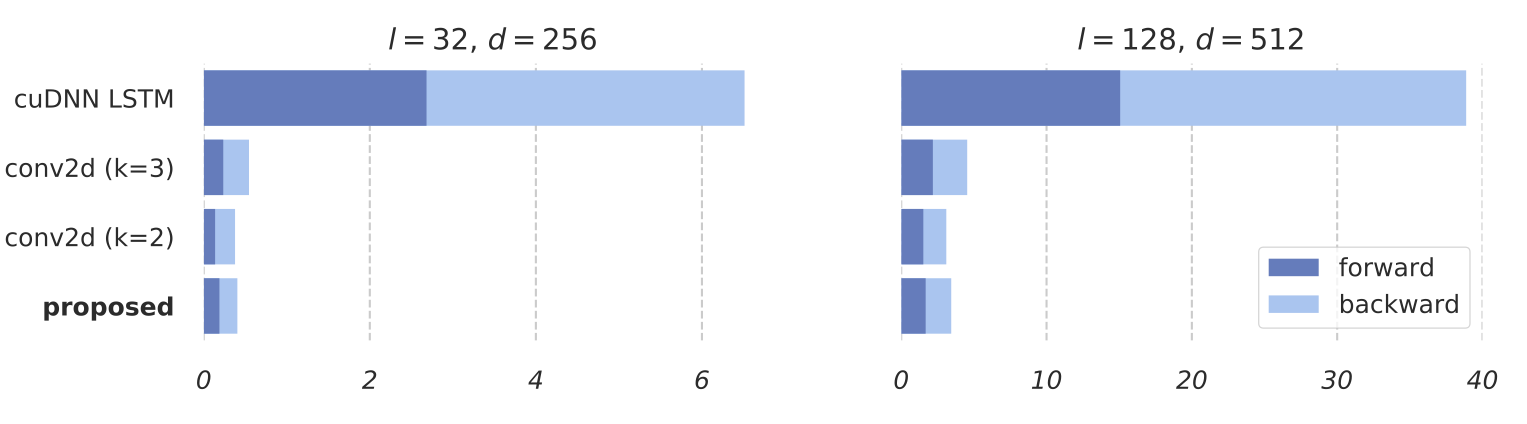
Training RNNs as Fast as CNNs
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
Beyond Paragraphs: NLP for Long Sequences
Beyond Paragraphs: NLP for Long Sequences
338 Dec 2, 2022
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
68 Jul 18, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023
Paradigm Shift in NLP - "Paradigm Shift in Natural Language Processing".
Paradigm Shift in NLP Welcome to the webpage for "Paradigm Shift in Natural Language Processing". Some resources of the paper are constantly maintaine
 41 Dec 30, 2022
41 Dec 30, 2022
![Exploring Relational Context for Multi-Task Dense Prediction [ICCV 2021]](https://github.com/brdav/atrc/raw/main/docs/teaser.png)
Exploring Relational Context for Multi-Task Dense Prediction [ICCV 2021]
Adaptive Task-Relational Context (ATRC) This repository provides source code for the ICCV 2021 paper Exploring Relational Context for Multi-Task Dense
 35 Dec 5, 2022
35 Dec 5, 2022

Pytorch implementation of CVPR2020 paper “VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation”
VectorNet Re-implementation This is the unofficial pytorch implementation of CVPR2020 paper "VectorNet: Encoding HD Maps and Agent Dynamics from Vecto
 120 Jan 6, 2023
120 Jan 6, 2023

A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones.
Imbalanced Dataset Sampler Introduction In many machine learning applications, we often come across datasets where some types of data may be seen more
 2k Jan 8, 2023
2k Jan 8, 2023
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022

Sign Language is detected in realtime using video sequences. Our approach involves MediaPipe Holistic for keypoints extraction and LSTM Model for prediction.
RealTime Sign Language Detection using Action Recognition Approach Real-Time Sign Language is commonly predicted using models whose architecture consi
 15 Aug 20, 2022
15 Aug 20, 2022
Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ)
DeepNLP-models-Pytorch Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ: NLP with Deep Learning) This is not for Pytorch be
 2.9k Dec 24, 2022
2.9k Dec 24, 2022
An IPython Notebook tutorial on deep learning for natural language processing, including structure prediction.
Table of Contents: Introduction to Torch's Tensor Library Computation Graphs and Automatic Differentiation Deep Learning Building Blocks: Affine maps,
 1.8k Jan 4, 2023
1.8k Jan 4, 2023