3321 Repositories
Python Iris-Data-Set-Classification Libraries

Goblyn is a Python tool focused to enumeration and capture of website files metadata.
Goblyn Metadata Enumeration What's Goblyn? Goblyn is a tool focused to enumeration and capture of website files metadata. How it works? Goblyn will se
 46 Nov 22, 2022
46 Nov 22, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022
Code and data for the EMNLP 2021 paper "Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts". Coming soon!
ToxiChat Code and data for the EMNLP 2021 paper "Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts". Install depen
 11 Jan 1, 2023
11 Jan 1, 2023
Framework for creating efficient data processing pipelines
Aqueduct Framework for creating efficient data processing pipelines. Contact Feel free to ask questions in telegram t.me/avito-ml Key Features Increas
 137 Dec 29, 2022
137 Dec 29, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022

machine learning model deployment project of Iris classification model in a minimal UI using flask web framework and deployed it in Azure cloud using Azure app service
This is a machine learning model deployment project of Iris classification model in a minimal UI using flask web framework and deployed it in Azure cloud using Azure app service. We initially made this project as a requirement for an internship at Indian Servers. We are now making it open to contribution.
 73 Dec 1, 2022
73 Dec 1, 2022
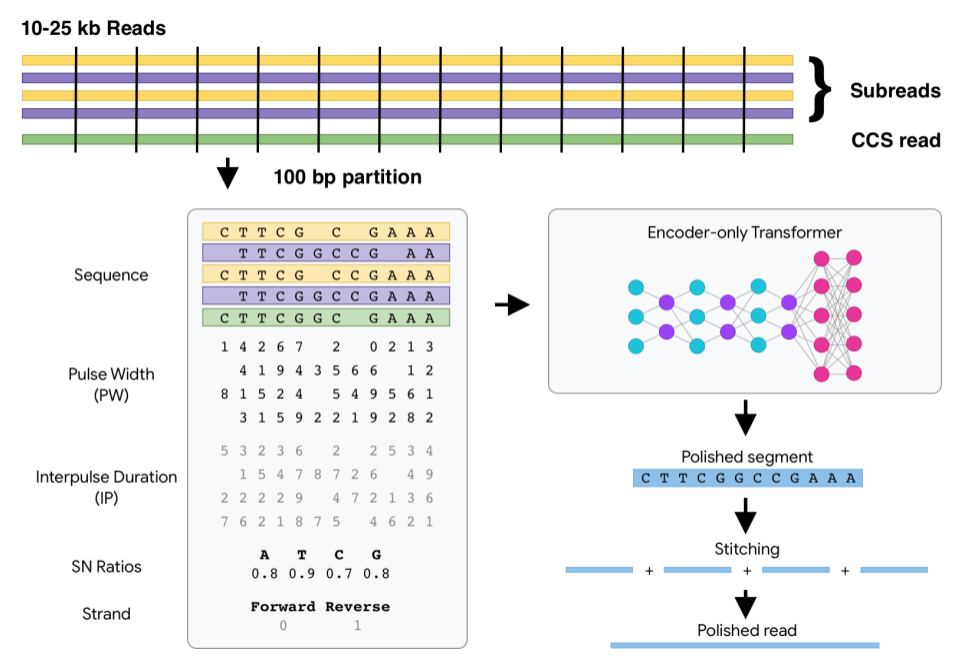
DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS) data.
DeepConsensus DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS)
 149 Dec 19, 2022
149 Dec 19, 2022
Mail classification with tensorflow and MS Exchange Server (ham or spam).
Mail classification with tensorflow and MS Exchange Server (ham or spam).
 1 Sep 11, 2021
1 Sep 11, 2021
Ranking Models in Unlabeled New Environments (iccv21)
Ranking Models in Unlabeled New Environments Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch 1.7.0 + torchivision 0.8.1
 14 Dec 17, 2021
14 Dec 17, 2021
Applicator Kit for Modo allow you to apply Apple ARKit Face Tracking data from your iPhone or iPad to your characters in Modo.
Applicator Kit for Modo Applicator Kit for Modo allow you to apply Apple ARKit Face Tracking data from your iPhone or iPad with a TrueDepth camera to
 3 Aug 24, 2021
3 Aug 24, 2021

Deep Learning for 3D Point Clouds: A Survey (IEEE TPAMI, 2020)
🔥Deep Learning for 3D Point Clouds (IEEE TPAMI, 2020)
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

A Red Team tool for exfiltrating sensitive data from Jira tickets.
Jir-thief This Module will connect to Jira's API using an access token, export to a word .doc, and download the Jira issues that the target has access
 82 Dec 12, 2022
82 Dec 12, 2022

An original implementation of "Noisy Channel Language Model Prompting for Few-Shot Text Classification"
Channel LM Prompting (and beyond) This includes an original implementation of Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer. "Noisy Cha
 92 Jan 7, 2023
92 Jan 7, 2023

(ICCV'21) Official PyTorch implementation of Relational Embedding for Few-Shot Classification
Relational Embedding for Few-Shot Classification (ICCV 2021) Dahyun Kang, Heeseung Kwon, Juhong Min, Minsu Cho [paper], [project hompage] We propose t
 82 Dec 24, 2022
82 Dec 24, 2022

【ACMMM 2021】DSANet: Dynamic Segment Aggregation Network for Video-Level Representation Learning
DSANet: Dynamic Segment Aggregation Network for Video-Level Representation Learning (ACMMM 2021) Overview We release the code of the DSANet (Dynamic S
 46 Dec 27, 2022
46 Dec 27, 2022
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task。涵盖68个领域、共计916万词的专业词典知识库,可用于文本分类、知识增强、领域词汇库扩充等自然语言处理应用。
 357 Dec 24, 2022
357 Dec 24, 2022
pywinauto is a set of python modules to automate the Microsoft Windows GUI
pywinauto is a set of python modules to automate the Microsoft Windows GUI. At its simplest it allows you to send mouse and keyboard actions to windows dialogs and controls, but it has support for more complex actions like getting text data.
 3.8k Jan 6, 2023
3.8k Jan 6, 2023

Implement Decoupled Neural Interfaces using Synthetic Gradients in Pytorch
disclaimer: this code is modified from pytorch-tutorial Image classification with synthetic gradient in Pytorch I implement the Decoupled Neural Inter
 114 Dec 22, 2022
114 Dec 22, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Official Python wrapper for the Quantel Finance API
Quantel is a powerful financial data and insights API. It provides easy access to world-class financial information. Quantel goes beyond just financial statements, giving users valuable information like insider transactions, major shareholder transactions, share ownership, peers, and so much more.
 47 Oct 16, 2022
47 Oct 16, 2022

Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown.
Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown
 915 Dec 26, 2022
915 Dec 26, 2022

prettymaps - A minimal Python library to draw customized maps from OpenStreetMap data.
A small set of Python functions to draw pretty maps from OpenStreetMap data. Based on osmnx, matplotlib and shapely libraries.
 9k Jan 8, 2023
9k Jan 8, 2023
Auto-updating data to assist in investment to NEPSE
Symbol Ratios Summary Sector LTP Undervalued Bonus % MEGA Strong Commercial Banks 368 5 10 JBBL Strong Development Banks 568 5 10 SIFC Strong Finance
 16 Nov 1, 2022
16 Nov 1, 2022
🔍 IRIS: An open-source intelligence framework
IRIS is an open-source OSINT framework, consisting of modules to find information about a target by scraping sites and fetching data from APIs.
 79 Dec 20, 2022
79 Dec 20, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
Public API client for GETTR, a "non-bias [sic] social network," designed for data archival and analysis.
GoGettr GoGettr is an API client for GETTR, a "non-bias [sic] social network." (We will not reward their domain with a hyperlink.) GoGettr is built an
 72 Dec 14, 2022
72 Dec 14, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022
Code for the KDD 2021 paper 'Filtration Curves for Graph Representation'
Filtration Curves for Graph Representation This repository provides the code from the KDD'21 paper Filtration Curves for Graph Representation. Depende
 16 Oct 16, 2022
16 Oct 16, 2022

Exploring Classification Equilibrium in Long-Tailed Object Detection, ICCV2021
Exploring Classification Equilibrium in Long-Tailed Object Detection (LOCE, ICCV 2021) Paper Introduction The conventional detectors tend to make imba
 52 Nov 21, 2022
52 Nov 21, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Generative Models as a Data Source for Multiview Representation Learning
GenRep Project Page | Paper Generative Models as a Data Source for Multiview Representation Learning Ali Jahanian, Xavier Puig, Yonglong Tian, Phillip
 81 Dec 3, 2022
81 Dec 3, 2022

Import, visualize, and analyze SpiderFoot OSINT data in Neo4j, a graph database
SpiderFoot Neo4j Tools Import, visualize, and analyze SpiderFoot OSINT data in Neo4j, a graph database Step 1: Installation NOTE: This installs the sf
 42 Dec 26, 2022
42 Dec 26, 2022
Low code JSON to extract data in one line
JSON Inline Low code JSON to extract data in one line ENG RU Installation pip install json-inline Usage Rules Modificator Description ?key:value Searc
 12 Mar 9, 2022
12 Mar 9, 2022

An implementation of paper `Real-time Convolutional Neural Networks for Emotion and Gender Classification` with PaddlePaddle.
简介 通过PaddlePaddle框架复现了论文 Real-time Convolutional Neural Networks for Emotion and Gender Classification 中提出的两个模型,分别是SimpleCNN和MiniXception。利用 imdb_crop
 8 Mar 11, 2022
8 Mar 11, 2022
A Pythonic Data Catalog powered by Ray that brings exabyte-level scalability and fast, ACID-compliant, change-data-capture to your big data workloads.
DeltaCAT DeltaCAT is a Pythonic Data Catalog powered by Ray. Its data storage model allows you to define and manage fast, scalable, ACID-compliant dat
 45 Oct 15, 2022
45 Oct 15, 2022
The official implementation of the IEEE S&P`22 paper "SoK: How Robust is Deep Neural Network Image Classification Watermarking".
Watermark-Robustness-Toolbox - Official PyTorch Implementation This repository contains the official PyTorch implementation of the following paper to
 49 Dec 19, 2022
49 Dec 19, 2022
Doing set operations on files considered as sets of lines
CLI tool that can be used to do set operations like union on files considering them as a set of lines. Notes It ignores all empty lines with whitespac
 11 Sep 6, 2022
11 Sep 6, 2022

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
 15 Dec 22, 2022
15 Dec 22, 2022

Guesslang detects the programming language of a given source code
Detect the programming language of a source code
 618 Dec 29, 2022
618 Dec 29, 2022

Data Preparation, Processing, and Visualization for MoVi Data
MoVi-Toolbox Data Preparation, Processing, and Visualization for MoVi Data, https://www.biomotionlab.ca/movi/ MoVi is a large multipurpose dataset of
 51 Nov 27, 2022
51 Nov 27, 2022

Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud This repository contains a reference implementation of our Part-Aware Data Augment
 62 Jan 3, 2023
62 Jan 3, 2023

Library for implementing reservoir computing models (echo state networks) for multivariate time series classification and clustering.
Framework overview This library allows to quickly implement different architectures based on Reservoir Computing (the family of approaches popularized
 249 Dec 21, 2022
249 Dec 21, 2022

A PyTorch implementation of the Relational Graph Convolutional Network (RGCN).
Torch-RGCN Torch-RGCN is a PyTorch implementation of the RGCN, originally proposed by Schlichtkrull et al. in Modeling Relational Data with Graph Conv
 66 Nov 30, 2022
66 Nov 30, 2022
Official repository with code and data accompanying the NAACL 2021 paper "Hurdles to Progress in Long-form Question Answering" (https://arxiv.org/abs/2103.06332).
Hurdles to Progress in Long-form Question Answering This repository contains the official scripts and datasets accompanying our NAACL 2021 paper, "Hur
 41 Nov 8, 2022
41 Nov 8, 2022
Parametric Contrastive Learning (ICCV2021)
Parametric-Contrastive-Learning This repository contains the implementation code for ICCV2021 paper: Parametric Contrastive Learning (https://arxiv.or
 156 Dec 21, 2022
156 Dec 21, 2022

This is an official implementation of the High-Resolution Transformer for Dense Prediction.
High-Resolution Transformer for Dense Prediction Introduction This is the official implementation of High-Resolution Transformer (HRT). We present a H
 403 Dec 13, 2022
403 Dec 13, 2022
Nasdaq Cloud Data Service (NCDS) provides a modern and efficient method of delivery for realtime exchange data and other financial information. This repository provides an SDK for developing applications to access the NCDS.
Nasdaq Cloud Data Service (NCDS) Nasdaq Cloud Data Service (NCDS) provides a modern and efficient method of delivery for realtime exchange data and ot
 8 Dec 1, 2022
8 Dec 1, 2022
Using python-binance to provide websocket data to freqtrade
The goal of this project is to provide an alternative way to get realtime data from Binance and use it in freqtrade despite the exchange used. It also uses talipp for computing
 58 Jan 1, 2023
58 Jan 1, 2023
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

Script de monitoramento de telemetria para missões espaciais, cansat e foguetemodelismo.
Aeroespace_GroundStation Script de monitoramento de telemetria para missões espaciais, cansat e foguetemodelismo. Imagem 1 - Dashboard realizando moni
 5 Nov 27, 2022
5 Nov 27, 2022
Home Assistant integration for spanish electrical data providers (e.g., datadis)
homeassistant-edata Esta integración para Home Assistant te permite seguir de un vistazo tus consumos y máximas potencias alcanzadas. Para ello, se ap
 163 Jan 5, 2023
163 Jan 5, 2023

CredData is a set of files including credentials in open source projects
CredData is a set of files including credentials in open source projects. CredData includes suspicious lines with manual review results and more information such as credential types for each suspicious line. CredData can be used to develop new tools or improve existing tools. Furthermore, using the benchmark result of the CredData, users can choose a proper tool among open source credential scanning tools according to their use case.
 19 Sep 7, 2022
19 Sep 7, 2022
This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, reading data from PubSub.
Sample streaming Dataflow pipeline written in Python This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, readin
 9 Mar 18, 2022
9 Mar 18, 2022

Danfeng Hong, Lianru Gao, Jing Yao, Bing Zhang, Antonio Plaza, Jocelyn Chanussot. Graph Convolutional Networks for Hyperspectral Image Classification, IEEE TGRS, 2021.
Graph Convolutional Networks for Hyperspectral Image Classification Danfeng Hong, Lianru Gao, Jing Yao, Bing Zhang, Antonio Plaza, Jocelyn Chanussot T
 154 Dec 13, 2022
154 Dec 13, 2022

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
 65 Sep 13, 2022
65 Sep 13, 2022

Python ELT Studio, an application for building ELT (and ETL) data flows.
The Python Extract, Load, Transform Studio is an application for performing ELT (and ETL) tasks. Under the hood the application consists of a two parts.
 55 Nov 18, 2022
55 Nov 18, 2022

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022
Vanilla and Prototypical Networks with Random Weights for image classification on Omniglot and mini-ImageNet. Made with Python3.
vanilla-rw-protonets-project Vanilla Prototypical Networks and PNs with Random Weights for image classification on Omniglot and mini-ImageNet. Made wi
 8 Aug 31, 2022
8 Aug 31, 2022
Test django schema and data migrations, including migrations' order and best practices.
django-test-migrations Features Allows to test django schema and data migrations Allows to test both forward and rollback migrations Allows to test th
 382 Dec 27, 2022
382 Dec 27, 2022
A configurable set of panels that display various debug information about the current request/response.
Django Debug Toolbar The Django Debug Toolbar is a configurable set of panels that display various debug information about the current request/respons
 7.3k Jan 2, 2023
7.3k Jan 2, 2023
Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app.
django-permissions-policy Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app. Requirements Python 3.
 76 Nov 30, 2022
76 Nov 30, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022

A light-weight image labelling tool for Python designed for creating segmentation data sets.
An image labelling tool for creating segmentation data sets, for Django and Flask.
 117 Nov 21, 2022
117 Nov 21, 2022
Download history data from binance and save to dataframe or csv file
Binance history data downloader Download history data from binance and save to dataframe or csv file
 10 Dec 2, 2022
10 Dec 2, 2022

Slack bot for monitoring your Metaflow flows!
Metaflowbot - Slack Bot for your Metaflow flows! Metaflowbot makes it fun and easy to monitor your Metaflow runs, past and present. Imagine starting a
 21 Dec 7, 2022
21 Dec 7, 2022
Creates a C array from a hex-string or a stream of binary data.
hex2array-c Creates a C array from a hex-string. Usage Usage: python3 hex2array_c.py HEX_STRING [-h|--help] Use '-' to read the hex string from STDIN.
 3 Nov 24, 2022
3 Nov 24, 2022
Implementation of "Selection via Proxy: Efficient Data Selection for Deep Learning" from ICLR 2020.
Selection via Proxy: Efficient Data Selection for Deep Learning This repository contains a refactored implementation of "Selection via Proxy: Efficien
 70 Nov 16, 2022
70 Nov 16, 2022
Data from "HateCheck: Functional Tests for Hate Speech Detection Models" (Röttger et al., ACL 2021)
In this repo, you can find the data from our ACL 2021 paper "HateCheck: Functional Tests for Hate Speech Detection Models". "test_suite_cases.csv" con
 43 Nov 11, 2022
43 Nov 11, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

Amazon Scraper: A command-line tool for scraping Amazon product data
Amazon Product Scraper: 2021 Description A command-line tool for scraping Amazon product data to CSV or JSON format(s). Requirements Python 3 pip3 Ins
 49 Nov 15, 2021
49 Nov 15, 2021

This is official implementaion of paper "Token Shift Transformer for Video Classification".
This is official implementaion of paper "Token Shift Transformer for Video Classification". We achieve SOTA performance 80.40% on Kinetics-400 val. Paper link
 60 Dec 30, 2022
60 Dec 30, 2022

A Data Annotation Tool for Semantic Segmentation, Object Detection and Lane Line Detection.(In Development Stage)
Data-Annotation-Tool How to Run this Tool? To run this software, follow the steps: git clone https://github.com/Autonomous-Car-Project/Data-Annotation
 13 Aug 18, 2022
13 Aug 18, 2022
Scraping Thailand COVID-19 data from the DDC's tableau dashboard
Scraping COVID-19 data from DDC Dashboard Scraping Thailand COVID-19 data from the DDC's tableau dashboard. Data is updated at 07:30 and 08:00 daily.
 5 Jan 4, 2022
5 Jan 4, 2022
DenseClus is a Python module for clustering mixed type data using UMAP and HDBSCAN
DenseClus is a Python module for clustering mixed type data using UMAP and HDBSCAN. Allowing for both categorical and numerical data, DenseClus makes it possible to incorporate all features in clustering.
 53 Dec 8, 2022
53 Dec 8, 2022
ml4h is a toolkit for machine learning on clinical data of all kinds including genetics, labs, imaging, clinical notes, and more
ml4h is a toolkit for machine learning on clinical data of all kinds including genetics, labs, imaging, clinical notes, and more
 65 Dec 20, 2022
65 Dec 20, 2022

Official implementation of paper "Query2Label: A Simple Transformer Way to Multi-Label Classification".
Introdunction This is the official implementation of the paper "Query2Label: A Simple Transformer Way to Multi-Label Classification". Abstract This pa
 274 Dec 28, 2022
274 Dec 28, 2022
This repository is home to the Optimus data transformation plugins for various data processing needs.
Transformers Optimus's transformation plugins are implementations of Task and Hook interfaces that allows execution of arbitrary jobs in optimus. To i
 37 Dec 14, 2022
37 Dec 14, 2022

Minimal Ethereum fee data viewer for the terminal, contained in a single python script.
Minimal Ethereum fee data viewer for the terminal, contained in a single python script. Connects to your node and displays some metrics in real-time.
 48 Dec 5, 2022
48 Dec 5, 2022

This solution helps you deploy Data Lake Infrastructure on AWS using CDK Pipelines.
CDK Pipelines for Data Lake Infrastructure Deployment This solution helps you deploy data lake infrastructure on AWS using CDK Pipelines. This is base
 66 Nov 23, 2022
66 Nov 23, 2022

Google Project: Search and auto-complete sentences within given input text files, manipulating data with complex data-structures.
Auto-Complete Google Project In this project there is an implementation for one feature of Google's search engines - AutoComplete. Autocomplete, or wo
 10 Jun 20, 2022
10 Jun 20, 2022
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (WSDM'21)
Hierarchical Metadata-Aware Document Categorization under Weak Supervision This project provides a weakly supervised framework for hierarchical metada
 53 Sep 17, 2022
53 Sep 17, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
 37 Dec 4, 2022
37 Dec 4, 2022

FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
FPGA & FreeNet Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification by Zhuo Zheng, Yanfei Zhong, Ailong M
 92 Jan 3, 2023
92 Jan 3, 2023
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Data and Code for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning"
Introduction Code and data for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning". We cons
 81 Dec 27, 2022
81 Dec 27, 2022
OpenGAN: Open-Set Recognition via Open Data Generation
OpenGAN: Open-Set Recognition via Open Data Generation ICCV 2021 (oral) Real-world machine learning systems need to analyze novel testing data that di
 90 Jan 6, 2023
90 Jan 6, 2023
Code release for our paper, "SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo"
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo Thomas Kollar, Michael Laskey, Kevin Stone, Brijen Thananjeyan
 68 Dec 14, 2022
68 Dec 14, 2022
MODALS: Modality-agnostic Automated Data Augmentation in the Latent Space
Update (20 Jan 2020): MODALS on text data is avialable MODALS MODALS: Modality-agnostic Automated Data Augmentation in the Latent Space Table of Conte
 38 Dec 15, 2022
38 Dec 15, 2022
TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A good teacher is patient and consistent by Beyer et al.
FunMatch-Distillation TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A g
 67 Dec 20, 2022
67 Dec 20, 2022
Extract Thailand COVID-19 Cluster data from daily briefing pdf.
Thailand COVID-19 Cluster Data Extraction About Extract Clusters from Thailand Daily COVID-19 briefing PDF Download latest data Here. Data will be upd
5 Sep 27, 2021
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022

The code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention.
CrossFormer This repository is the code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. Introduction Existin
 238 Jan 6, 2023
238 Jan 6, 2023
Universal End2End Training Platform, including pre-training, classification tasks, machine translation, and etc.
背景 安装教程 快速上手 (一)预训练模型 (二)机器翻译 (三)文本分类 TenTrans 进阶 1. 多语言机器翻译 2. 跨语言预训练 背景 TrenTrans是一个统一的端到端的多语言多任务预训练平台,支持多种预训练方式,以及序列生成和自然语言理解任务。 安装教程 git clone git
 42 Dec 20, 2022
42 Dec 20, 2022

Evidently helps analyze machine learning models during validation or production monitoring
Evidently helps analyze machine learning models during validation or production monitoring. The tool generates interactive visual reports and JSON profiles from pandas DataFrame or csv files. Currently 6 reports are available.
 3.1k Jan 7, 2023
3.1k Jan 7, 2023
Collect super-resolution related papers, data, repositories
Collect super-resolution related papers, data, repositories
 1.7k Jan 3, 2023
1.7k Jan 3, 2023
Active learning for text classification in Python
Active Learning allows you to efficiently label training data in a small-data scenario.
 375 Dec 28, 2022
375 Dec 28, 2022
Use this script to track the gains of cryptocurrencies using historical data and display it on a super-imposed chart in order to find the highest performing cryptocurrencies historically
crypto-performance-tracker Use this script to track the gains of cryptocurrencies using historical data and display it on a super-imposed chart in ord
 25 Aug 31, 2022
25 Aug 31, 2022
Automated data scraper for Thailand COVID-19 data
The Researcher COVID data Automated data scraper for Thailand COVID-19 data Accessing the Data 1st Dose Provincial Vaccination Data 2nd Dose Provincia
 31 Apr 17, 2022
31 Apr 17, 2022