231 Repositories
Python LARGE Libraries

Global Tracking Transformers, CVPR 2022
Global Tracking Transformers Global Tracking Transformers, Xingyi Zhou, Tianwei Yin, Vladlen Koltun, Philipp Krähenbühl, CVPR 2022 (arXiv 2203.13250)
 304 Dec 16, 2022
304 Dec 16, 2022
JF⚡can - Super fast port scanning & service discovery using Masscan and Nmap. Scan large networks with Masscan and use Nmap's scripting abilities to discover information about services. Generate report.
Description Killing features Perform a large-scale scans using Nmap! Allows you to use Masscan to scan targets and execute Nmap on detected ports with
 377 Jan 3, 2023
377 Jan 3, 2023

MAT: Mask-Aware Transformer for Large Hole Image Inpainting
MAT: Mask-Aware Transformer for Large Hole Image Inpainting (CVPR2022, Oral) Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, Jiaya Jia [Paper] News This
 254 Dec 29, 2022
254 Dec 29, 2022

BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training By Likun Cai, Zhi Zhang, Yi Zhu, Li Zhang, Mu Li, Xiangyang Xue. This
 290 Dec 29, 2022
290 Dec 29, 2022
Georeferencing large amounts of data for free.
Geolocate Georeferencing large amounts of data for free. Special thanks to @brunodepauloalmeida and the whole team for the contributions. How? It's us
 23 Dec 30, 2022
23 Dec 30, 2022

Use the state-of-the-art m2m100 to translate large data on CPU/GPU/TPU. Super Easy!
Easy-Translate is a script for translating large text files in your machine using the M2M100 models from Facebook/Meta AI. We also privide a script fo
 41 Dec 15, 2022
41 Dec 15, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022

SentimentArcs: a large ensemble of dozens of sentiment analysis models to analyze emotion in text over time
SentimentArcs - Emotion in Text An end-to-end pipeline based on Jupyter notebooks to detect, extract, process and anlayze emotion over time in text. E
 14 Dec 19, 2022
14 Dec 19, 2022
This is the course repository for the Spring 2022 iteration of MACS 30123 "Large-Scale Computing for the Social Sciences" at the University of Chicago.
Large-Scale Computing for the Social Sciences Spring 2022 - MACS 30123/MAPS 30123/PLSC 30123 Instructor Information TA Information TA Information Cour
 6 May 6, 2022
6 May 6, 2022

Guide to using pre-trained large language models of source code
Large Models of Source Code I occasionally train and publicly release large neural language models on programs, including PolyCoder. Here, I describe
 947 Dec 28, 2022
947 Dec 28, 2022

Large-scale language modeling tutorials with PyTorch
Large-scale language modeling tutorials with PyTorch 안녕하세요. 저는 TUNiB에서 머신러닝 엔지니어로 근무 중인 고현웅입니다. 이 자료는 대규모 언어모델 개발에 필요한 여러가지 기술들을 소개드리기 위해 마련하였으며 기본적으로
 172 Dec 29, 2022
172 Dec 29, 2022
![[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets](https://github.com/autonomousvision/stylegan_xl/raw/main/media/banner.png)
[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
[Project] [PDF] This repository contains code for our SIGGRAPH'22 paper "StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets" by Axel Sauer, Katja
 742 Jan 4, 2023
742 Jan 4, 2023
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022 [Project page | Video] Getting sta
 51 Nov 29, 2022
51 Nov 29, 2022

The official codes of our CVPR2022 paper: A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift
TwoStageAlign The official codes of our CVPR2022 paper: A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift Pa
 32 Dec 15, 2022
32 Dec 15, 2022
Large-Scale Pre-training for Person Re-identification with Noisy Labels (LUPerson-NL)
LUPerson-NL Large-Scale Pre-training for Person Re-identification with Noisy Labels (LUPerson-NL) The repository is for our CVPR2022 paper Large-Scale
 43 Dec 26, 2022
43 Dec 26, 2022
DeepGNN is a framework for training machine learning models on large scale graph data.
DeepGNN Overview DeepGNN is a framework for training machine learning models on large scale graph data. DeepGNN contains all the necessary features in
 45 Jan 1, 2023
45 Jan 1, 2023

PyTorch reimplementation of the Smooth ReLU activation function proposed in the paper "Real World Large Scale Recommendation Systems Reproducibility and Smooth Activations" [arXiv 2022].
Smooth ReLU in PyTorch Unofficial PyTorch reimplementation of the Smooth ReLU (SmeLU) activation function proposed in the paper Real World Large Scale
 10 Jan 2, 2023
10 Jan 2, 2023
Repository for DNN training, theory to practice, part of the Large Scale Machine Learning class at Mines Paritech
DNN Training, from theory to practice This repository is complementary to the deep learning training lesson given to les Mines ParisTech on the 11th o
 6 Nov 14, 2022
6 Nov 14, 2022

IPscan - This Script is Framework To automate IP process large scope For Bug Hunting
IPscan This Script is Framework To automate IP process large scope For Bug Hunti
 8 Mar 12, 2022
8 Mar 12, 2022

Large-Scale Unsupervised Object Discovery
Large-Scale Unsupervised Object Discovery Huy V. Vo, Elena Sizikova, Cordelia Schmid, Patrick Pérez, Jean Ponce [PDF] We propose a novel ranking-based
 17 Sep 19, 2022
17 Sep 19, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022
Large-scale Knowledge Graph Construction with Prompting
Large-scale Knowledge Graph Construction with Prompting across tasks (predictive and generative), and modalities (language, image, vision + language, etc.)
 161 Dec 28, 2022
161 Dec 28, 2022
FewBit — a library for memory efficient training of large neural networks
FewBit FewBit — a library for memory efficient training of large neural networks. Its efficiency originates from storage optimizations applied to back
 24 Oct 22, 2022
24 Oct 22, 2022
Kartothek - a Python library to manage large amounts of tabular data in a blob store
Kartothek - a Python library to manage (create, read, update, delete) large amounts of tabular data in a blob store
 15 Dec 25, 2022
15 Dec 25, 2022

YOLTv5 rapidly detects objects in arbitrarily large aerial or satellite images that far exceed the ~600×600 pixel size typically ingested by deep learning object detection frameworks
YOLTv5 rapidly detects objects in arbitrarily large aerial or satellite images that far exceed the ~600×600 pixel size typically ingested by deep learning object detection frameworks.
 145 Jan 1, 2023
145 Jan 1, 2023

Opencontactbook - Bulk-manage large numbers of vCard contacts with built-in geolocation
Open Contact Book Open Contact Book is a buiness-oriented, cross-platform, Pytho
 2 Aug 8, 2022
2 Aug 8, 2022
Split large XML files into smaller ones for easy upload
Split large XML files into smaller ones for easy upload. Works for WordPress Posts Import and other XML files.
 1 Jan 30, 2022
1 Jan 30, 2022
A large-scale benchmark for co-optimizing the design and control of soft robots, as seen in NeurIPS 2021.
Evolution Gym A large-scale benchmark for co-optimizing the design and control of soft robots. As seen in Evolution Gym: A Large-Scale Benchmark for E
 121 Dec 14, 2022
121 Dec 14, 2022
Very large and sparse networks appear often in the wild and present unique algorithmic opportunities and challenges for the practitioner
Sparse network learning with snlpy Very large and sparse networks appear often in the wild and present unique algorithmic opportunities and challenges
 1 Apr 30, 2021
1 Apr 30, 2021
Storing, versioning, and downloading files from S3 made as easy as using open() in Python. Caching included.
open(LARGE) Storing, versioning, and downloading files from S3 made as easy as using open() in Python. Caching included. Motivation Oftentimes, especi
 2 Jan 30, 2022
2 Jan 30, 2022
Raster Vision is an open source Python framework for building computer vision models on satellite, aerial, and other large imagery sets
Raster Vision is an open source Python framework for building computer vision models on satellite, aerial, and other large imagery sets (including obl
 1.7k Dec 22, 2022
1.7k Dec 22, 2022

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023

NeurIPS workshop paper 'Counter-Strike Deathmatch with Large-Scale Behavioural Cloning'
Counter-Strike Deathmatch with Large-Scale Behavioural Cloning Tim Pearce, Jun Zhu Offline RL workshop, NeurIPS 2021 Paper: https://arxiv.org/abs/2104
 169 Dec 26, 2022
169 Dec 26, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
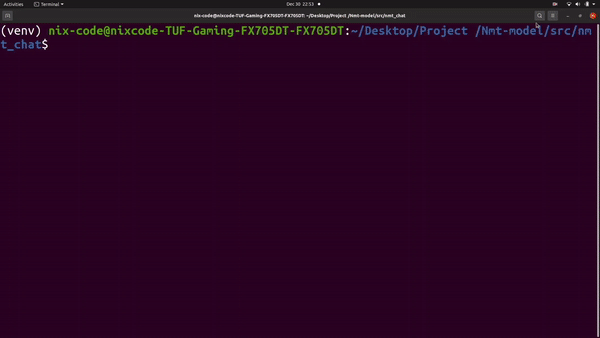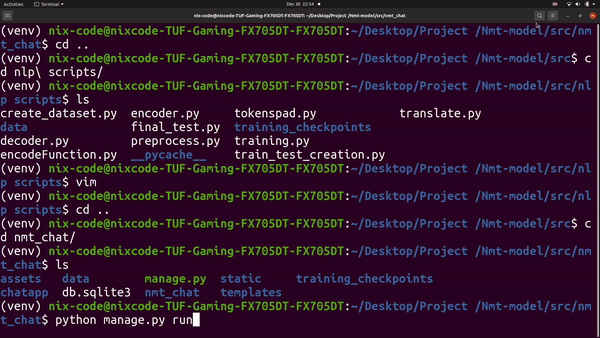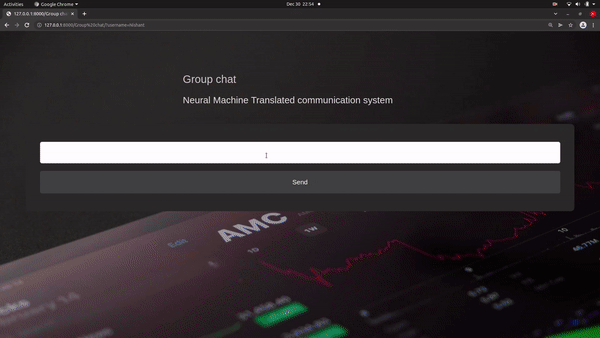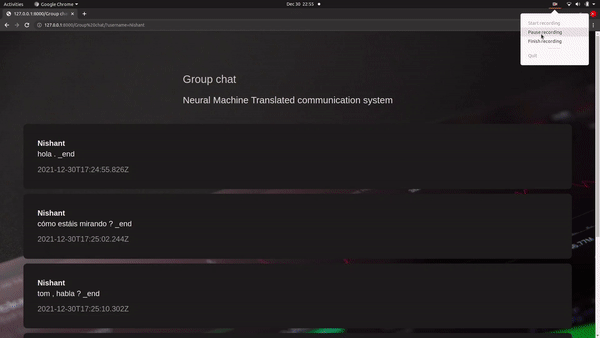
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
 7 Sep 22, 2022
7 Sep 22, 2022

Official PyTorch implementation of Time-aware Large Kernel (TaLK) Convolutions (ICML 2020)
Time-aware Large Kernel (TaLK) Convolutions (Lioutas et al., 2020) This repository contains the source code, pre-trained models, as well as instructio
 28 Dec 7, 2022
28 Dec 7, 2022
this repo store a Awoesome telegram bot for protect from your large group from bot attack.
this repo store a Awoesome telegram bot for protect from your large group from bot attack.
 2 Jul 22, 2022
2 Jul 22, 2022

(3DV 2021 Oral) Filtering by Cluster Consistency for Large-Scale Multi-Image Matching
Scalable Cluster-Consistency Statistics for Robust Multi-Object Matching (3DV 2021 Oral Presentation) Filtering by Cluster Consistency (FCC) is a very
 11 Sep 28, 2022
11 Sep 28, 2022

A curated list of awesome open source libraries to deploy, monitor, version and scale your machine learning
Awesome production machine learning This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, versi
 12.9k Jan 4, 2023
12.9k Jan 4, 2023

Helper to organize your windows on your desktop.
The script of positionsing windows on the screen. How does it work? Select your window to move/res
 1 Jul 9, 2021
1 Jul 9, 2021
Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis
Introduction This is an implementation of our paper Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis.
 24 Dec 6, 2022
24 Dec 6, 2022

Large scale PTM - PPI relation extraction
Large-scale protein-protein post-translational modification extraction with distant supervision and confidence calibrated BioBERT The silver standard
 1 Feb 25, 2022
1 Feb 25, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022

A Simulation Environment to train Robots in Large Realistic Interactive Scenes
iGibson: A Simulation Environment to train Robots in Large Realistic Interactive Scenes iGibson is a simulation environment providing fast visual rend
 493 Jan 4, 2023
493 Jan 4, 2023

Vis2Mesh: Efficient Mesh Reconstruction from Unstructured Point Clouds of Large Scenes with Learned Virtual View Visibility ICCV2021
Vis2Mesh This is the offical repository of the paper: Vis2Mesh: Efficient Mesh Reconstruction from Unstructured Point Clouds of Large Scenes with Lear
 71 Dec 25, 2022
71 Dec 25, 2022
This is a DemoCode for parsing through large log files and triggering an email whenever there's an error.
LogFileParserDemoCode This is a DemoCode for parsing through large log files and triggering an email whenever there's an error. There are a total of f
 2 Jan 6, 2022
2 Jan 6, 2022

Interactive dimensionality reduction for large datasets
BlosSOM 🌼 BlosSOM is a graphical environment for running semi-supervised dimensionality reduction with EmbedSOM. You can use it to explore multidimen
 19 Dec 14, 2022
19 Dec 14, 2022
NFT-Image-Generator - Utility to generate a large collection of unique images
NFT-Image-Generator Utility for creating a generative art collection from suppli
 60 Dec 15, 2022
60 Dec 15, 2022
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
7 Sep 22, 2022
A simple python discord bot which give you a yogurt brand name, basing on a large database often updated.
YaourtBot A discord simple bot by Lopinosaurus Before using this code : ・Move env file to .env ・Change the channel ID on line 38 of bot.py to your #pi
 0 May 9, 2022
0 May 9, 2022
An distributed automation framework.
Automation Kit Repository Welcome to the Automation Kit repository! Note: This package is progressing quickly but is not yet ready for full production
 3 Nov 3, 2022
3 Nov 3, 2022

N-Omniglot is a large neuromorphic few-shot learning dataset
N-Omniglot [Paper] || [Dataset] N-Omniglot is a large neuromorphic few-shot learning dataset. It reconstructs strokes of Omniglot as videos and uses D
 11 Dec 5, 2022
11 Dec 5, 2022

Manage large and heterogeneous data spaces on the file system.
signac - simple data management The signac framework helps users manage and scale file-based workflows, facilitating data reuse, sharing, and reproduc
 109 Dec 14, 2022
109 Dec 14, 2022
LynxKite: a complete graph data science platform for very large graphs and other datasets.
LynxKite is a complete graph data science platform for very large graphs and other datasets. It seamlessly combines the benefits of a friendly graphical interface and a powerful Python API.
 124 Dec 14, 2022
124 Dec 14, 2022

A set of tests for evaluating large-scale algorithms for Wasserstein-2 transport maps computation.
Continuous Wasserstein-2 Benchmark This is the official Python implementation of the NeurIPS 2021 paper Do Neural Optimal Transport Solvers Work? A Co
 22 Dec 12, 2022
22 Dec 12, 2022

CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
CurriculumNet Introduction This repo contains related code and models from the ECCV 2018 CurriculumNet paper. CurriculumNet is a new training strategy
 156 Jul 4, 2022
156 Jul 4, 2022

OSLO: Open Source framework for Large-scale transformer Optimization
O S L O Open Source framework for Large-scale transformer Optimization What's New: December 21, 2021 Released OSLO 1.0. What is OSLO about? OSLO is a
280 Nov 24, 2022
Django models and endpoints for working with large images -- tile serving
Django Large Image Models and endpoints for working with large images in Django -- specifically geared towards geospatial tile serving. DISCLAIMER: th
 42 Dec 17, 2022
42 Dec 17, 2022
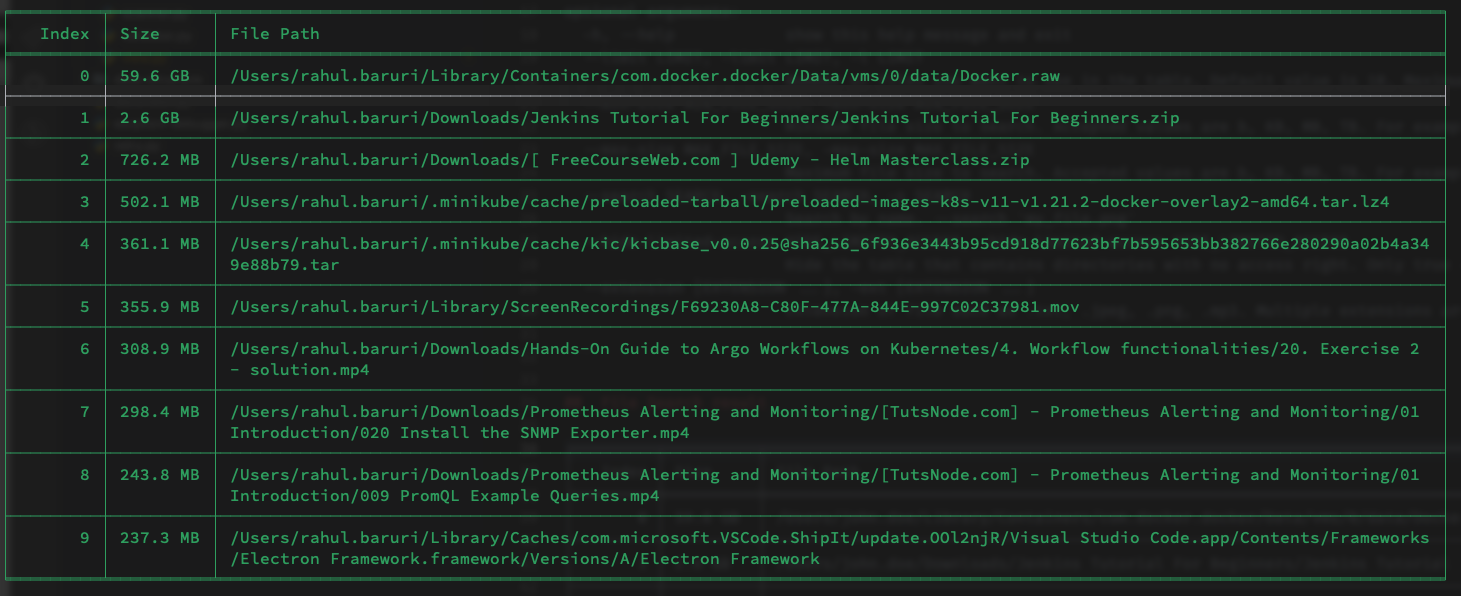
A simple CLI application helps you to find giant files that are eating up your system storage
Large file finder Sometimes it's very hard to find if some giant files are eating up your system storage. We might need to hunt those down. This simpl
 5 Nov 18, 2022
5 Nov 18, 2022
![MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]](https://github.com/uniBruce/Mead/raw/master/Figures/mead.png)
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020] by Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wa
 112 Dec 28, 2022
112 Dec 28, 2022

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
281 Dec 15, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
7.8k Jan 9, 2023
Large-scale pretraining for dialogue
A State-of-the-Art Large-scale Pretrained Response Generation Model (DialoGPT) This repository contains the source code and trained model for a large-
1.8k Jan 7, 2023
Large-scale open domain KNOwledge grounded conVERsation system based on PaddlePaddle
Knover Knover is a toolkit for knowledge grounded dialogue generation based on PaddlePaddle. Knover allows researchers and developers to carry out eff
 606 Dec 28, 2022
606 Dec 28, 2022

Forest R-CNN: Large-Vocabulary Long-Tailed Object Detection and Instance Segmentation (ACM MM 2020)
Forest R-CNN: Large-Vocabulary Long-Tailed Object Detection and Instance Segmentation (ACM MM 2020) Official implementation of: Forest R-CNN: Large-Vo
 54 Jan 6, 2023
54 Jan 6, 2023
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning. CVPR 2018
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning Tensorflow code and models for the paper: Large Scale Fine-Grained Categ
 187 Oct 1, 2022
187 Oct 1, 2022

A high-performance distributed deep learning system targeting large-scale and automated distributed training.
HETU Documentation | Examples Hetu is a high-performance distributed deep learning system targeting trillions of parameters DL model training, develop
 150 Dec 21, 2022
150 Dec 21, 2022
SimpleITK is an image analysis toolkit with a large number of components supporting general filtering operations, image segmentation and registration
SimpleITK is an image analysis toolkit with a large number of components supporting general filtering operations, image segmentation and registration
 672 Jan 5, 2023
672 Jan 5, 2023
Python modules to work with large multiresolution images.
Large Image Python modules to work with large, multiresolution images. Large Image is developed and maintained by the Data & Analytics group at Kitwar
 136 Jan 2, 2023
136 Jan 2, 2023

CleanX is an open source python library for exploring, cleaning and augmenting large datasets of X-rays, or certain other types of radiological images.
cleanX CleanX is an open source python library for exploring, cleaning and augmenting large datasets of X-rays, or certain other types of radiological
 20 Jan 5, 2023
20 Jan 5, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022
A GUI-based audio player with support for a large variety of formats
Miza-Player A GUI-based audio player with support for a large variety of formats, able to play from web-hosted media platforms such as YouTube, includ
 3 Dec 14, 2022
3 Dec 14, 2022
Utils for streaming large files (S3, HDFS, gzip, bz2...)
smart_open — utils for streaming large files in Python What? smart_open is a Python 3 library for efficient streaming of very large files from/to stor
 2.7k Jan 6, 2023
2.7k Jan 6, 2023

Download a large file from Google Drive (curl/wget fails because of the security notice).
gdown Download a large file from Google Drive. Description Download a large file from Google Drive. If you use curl/wget, it fails with a large file b
 2.7k Jan 9, 2023
2.7k Jan 9, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
WSDM2022 Challenge - Large scale temporal graph link prediction
WSDM 2022 Large-scale Temporal Graph Link Prediction - Baseline and Initial Test Set WSDM Cup Website link Link to this challenge This branch offers A
 34 Dec 29, 2022
34 Dec 29, 2022

This is the paddle code for SeBoW(Self-Born wiring for neural trees), a kind of neural tree born form a large search space
SeBoW: Self-Born Wiring for neural trees(PaddlePaddle version) This is the paddle code for SeBoW(Self-Born wiring for neural trees), a kind of neural
 13 Dec 8, 2022
13 Dec 8, 2022
Implementation of "Large Steps in Inverse Rendering of Geometry"
Large Steps in Inverse Rendering of Geometry ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia), December 2021. Baptiste Nicolet · Alec Jacob
 274 Jan 6, 2023
274 Jan 6, 2023

Official Code for VideoLT: Large-scale Long-tailed Video Recognition (ICCV 2021)
Pytorch Code for VideoLT [Website][Paper] Updates [10/29/2021] Features uploaded to Google Drive, for access please send us an e-mail: zhangxing18 at
 26 Sep 18, 2022
26 Sep 18, 2022
A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch.
WebDataset WebDataset is a PyTorch Dataset (IterableDataset) implementation providing efficient access to datasets stored in POSIX tar archives and us
 1.1k Jan 8, 2023
1.1k Jan 8, 2023

Pytorch Implementations of large number classical backbone CNNs, data enhancement, torch loss, attention, visualization and some common algorithms.
Torch-template-for-deep-learning Pytorch implementations of some **classical backbone CNNs, data enhancement, torch loss, attention, visualization and
 270 Dec 31, 2022
270 Dec 31, 2022
Perturbed Self-Distillation: Weakly Supervised Large-Scale Point Cloud Semantic Segmentation (ICCV2021)
Perturbed Self-Distillation: Weakly Supervised Large-Scale Point Cloud Semantic Segmentation (ICCV2021) This is the implementation of PSD (ICCV 2021),
 12 Dec 12, 2022
12 Dec 12, 2022

Official repository for Automated Learning Rate Scheduler for Large-Batch Training (8th ICML Workshop on AutoML)
Automated Learning Rate Scheduler for Large-Batch Training The official repository for Automated Learning Rate Scheduler for Large-Batch Training (8th
 35 Jan 4, 2023
35 Jan 4, 2023
Scripts for BGC analysis in large MAGs and results of their application to soil metagenomes within Chernevaya Taiga RSF-funded project
Scripts for BGC analysis in large MAGs and results of their application to soil metagenomes within Chernevaya Taiga RSF-funded project
 1 Dec 6, 2021
1 Dec 6, 2021
A High-Performance Distributed Library for Large-Scale Bundle Adjustment
MegBA: A High-Performance and Distributed Library for Large-Scale Bundle Adjustment This repo contains an official implementation of MegBA. MegBA is a
 336 Dec 27, 2022
336 Dec 27, 2022
Visualize large time-series data in plotly
plotly_resampler enables visualizing large sequential data by adding resampling functionality to Plotly figures. In this Plotly-Resampler demo over 11
 604 Dec 28, 2022
604 Dec 28, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022

PartImageNet is a large, high-quality dataset with part segmentation annotations
PartImageNet: A Large, High-Quality Dataset of Parts We will release our dataset and scripts soon after cleaning and approval. Introduction PartImageN
 77 Nov 30, 2022
77 Nov 30, 2022
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022
A collection of simple tools that proved to be needed for hadling large periodic calculations with the VASP software package.
VESTA-tools A collection of simple tools that proved to be needed for handling large periodic calculations with the VASP software package. distTotCalc
 2 Dec 14, 2021
2 Dec 14, 2021
Public Code for NIPS submission SimiGrad: Fine-Grained Adaptive Batching for Large ScaleTraining using Gradient Similarity Measurement
Public code for NIPS submission "SimiGrad: Fine-Grained Adaptive Batching for Large Scale Training using Gradient Similarity Measurement" This repo co
 0 Oct 13, 2021
0 Oct 13, 2021
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models This repository is the official implementation of the fol
 41 Dec 6, 2022
41 Dec 6, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022
Large scale and asynchronous Hyperparameter Optimization at your fingertip.
Syne Tune This package provides state-of-the-art distributed hyperparameter optimizers (HPO) where trials can be evaluated with several backend option
 236 Jan 1, 2023
236 Jan 1, 2023
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and Python functions.
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and many other libraries. Documenta
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

A large-scale face dataset for face parsing, recognition, generation and editing.
CelebAMask-HQ [Paper] [Demo] CelebAMask-HQ is a large-scale face image dataset that has 30,000 high-resolution face images selected from the CelebA da
 1.7k Dec 26, 2022
1.7k Dec 26, 2022
Revisiting Video Saliency: A Large-scale Benchmark and a New Model (CVPR18, PAMI19)
DHF1K =========================================================================== Wenguan Wang, J. Shen, M.-M Cheng and A. Borji, Revisiting Video Sal
 126 Dec 3, 2022
126 Dec 3, 2022
Code for text augmentation method leveraging large-scale language models
HyperMix Code for our paper GPT3Mix and conducting classification experiments using GPT-3 prompt-based data augmentation. Getting Started Installing P
 47 Dec 20, 2022
47 Dec 20, 2022