780 Repositories
Python Transformer-Captioning Libraries
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022

Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
 4 Jun 1, 2022
4 Jun 1, 2022
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022

RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting
RATCHET: RAdiological Text Captioning for Human Examined Thoraxes RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting. Based on t
 26 Nov 14, 2022
26 Nov 14, 2022
Generating Radiology Reports via Memory-driven Transformer
R2Gen This is the implementation of Generating Radiology Reports via Memory-driven Transformer at EMNLP-2020. Citations If you use or extend our work,
 101 Dec 13, 2022
101 Dec 13, 2022

This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
ICCV Workshop 2021 VTGAN This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
 25 Dec 8, 2022
25 Dec 8, 2022
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021)
T2Net Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021) [Paper][Code] Dependencies numpy==1.18.5 scikit_image==
 64 Nov 23, 2022
64 Nov 23, 2022
COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models
COVID-ViT COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models This code is to response to te MIA-COV19 compe
 17 Dec 30, 2022
17 Dec 30, 2022
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification [NeurIPS 2021] Abstract Multiple instance learn
 132 Dec 30, 2022
132 Dec 30, 2022
Mixed Transformer UNet for Medical Image Segmentation
MT-UNet Update 2022/01/05 By another round of training based on previous weights, our model also achieved a better performance on ACDC (91.61% DSC). W
 92 Dec 25, 2022
92 Dec 25, 2022
Official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation
SegPC-2021 This is the official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation by
 13 Dec 14, 2022
13 Dec 14, 2022

This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
 89 Jan 24, 2022
89 Jan 24, 2022
nnFormer: Interleaved Transformer for Volumetric Segmentation
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation ". Please
 610 Dec 28, 2022
610 Dec 28, 2022

Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
 1 Jan 23, 2022
1 Jan 23, 2022

Pytorch implementation of ICASSP 2022 paper Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 6 Sep 21, 2022
6 Sep 21, 2022

Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 3 Oct 31, 2022
3 Oct 31, 2022

Fast Differentiable Matrix Sqrt Root
Official Pytorch implementation of ICLR 22 paper Fast Differentiable Matrix Square Root
 42 Dec 30, 2022
42 Dec 30, 2022
This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector of the financial market.
GPlearn_finiance_stock_futures_extension This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector
 189 Dec 25, 2022
189 Dec 25, 2022

Image Captioning on google cloud platform based on iot
Image-Captioning-on-google-cloud-platform-based-on-iot - Image Captioning on google cloud platform based on iot
 1 Jan 20, 2022
1 Jan 20, 2022
ServiceX Transformer that converts flat ROOT ntuples into columnwise data
ServiceX_Uproot_Transformer ServiceX Transformer that converts flat ROOT ntuples into columnwise data Usage You can invoke the transformer from the co
 0 Jan 20, 2022
0 Jan 20, 2022
Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
Awesome Visual-Transformer Collect some Transformer with Computer-Vision (CV) papers. If you find some overlooked papers, please open issues or pull r
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Transformer in Computer Vision
Transformer-in-Vision A paper list of some recent Transformer-based CV works. If you find some ignored papers, please open issues or pull requests. **
 506 Dec 26, 2022
506 Dec 26, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
 7 Jan 13, 2022
7 Jan 13, 2022
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022
Detail-Preserving Transformer for Light Field Image Super-Resolution
DPT Official Pytorch implementation of the paper "Detail-Preserving Transformer for Light Field Image Super-Resolution" accepted by AAAI 2022 . Update
 50 Jan 1, 2023
50 Jan 1, 2023

Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction. arxiv This repository contains python scripts for tr
 12 Dec 12, 2022
12 Dec 12, 2022
TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning
TransZero++ This repository contains the testing code for the paper "TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning" submitted
 3 Jan 5, 2022
3 Jan 5, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022

MADT: Offline Pre-trained Multi-Agent Decision Transformer
MADT: Offline Pre-trained Multi-Agent Decision Transformer A link to our paper can be found on Arxiv. Overview Official codebase for Offline Pre-train
 51 Dec 21, 2022
51 Dec 21, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022
Official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
199 Jan 3, 2023
[ACM MM 2021] Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation) [arXiv] [paper] @inproceedings{hou2021multiview, title={Multiview
 27 Dec 13, 2022
27 Dec 13, 2022

Unifying Global-Local Representations in Salient Object Detection with Transformer
GLSTR (Global-Local Saliency Transformer) This is the official implementation of paper "Unifying Global-Local Representations in Salient Object Detect
 11 Aug 24, 2022
11 Aug 24, 2022
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
 27 Nov 7, 2022
27 Nov 7, 2022

This is a code repository for paper OODformer: Out-Of-Distribution Detection Transformer
OODformer: Out-Of-Distribution Detection Transformer This repo is the official the implementation of the OODformer: Out-Of-Distribution Detection Tran
 34 Dec 2, 2022
34 Dec 2, 2022
Image Fusion Transformer
Image-Fusion-Transformer Platform Python 3.7 Pytorch =1.0 Training Dataset MS-COCO 2014 (T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ram
 68 Dec 23, 2022
68 Dec 23, 2022
Official implementation of Sparse Transformer-based Action Recognition
STAR Official implementation of S parse T ransformer-based A ction R ecognition Dataset download NTU RGB+D 60 action recognition of 2D/3D skeleton fro
 15 Nov 2, 2022
15 Nov 2, 2022
MlTr: Multi-label Classification with Transformer
MlTr: Multi-label Classification with Transformer This is official implement of "MlTr: Multi-label Classification with Transformer". Abstract The task
 38 Nov 8, 2022
38 Nov 8, 2022
Pyramid Pooling Transformer for Scene Understanding
Pyramid Pooling Transformer for Scene Understanding Requirements: torch 1.6+ torchvision 0.7.0 timm==0.3.2 Validated on torch 1.6.0, torchvision 0.7.0
 119 Dec 29, 2022
119 Dec 29, 2022

Deep learning transformer model that generates unique music sequences.
music-ai Deep learning transformer model that generates unique music sequences. Abstract In 2017, a new state-of-the-art was published for natural lan
 6 Nov 19, 2022
6 Nov 19, 2022

PyTorch implementation of Higher Order Recurrent Space-Time Transformer
Higher Order Recurrent Space-Time Transformer (HORST) This is the official PyTorch implementation of Higher Order Recurrent Space-Time Transformer. Th
 13 Oct 18, 2022
13 Oct 18, 2022

Pytorch implementation of Decoupled Spatial-Temporal Transformer for Video Inpainting
Decoupled Spatial-Temporal Transformer for Video Inpainting By Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, J
 51 Dec 13, 2022
51 Dec 13, 2022
Official PyTorch Implementation of "AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting".
AgentFormer This repo contains the official implementation of our paper: AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecast
 161 Dec 23, 2022
161 Dec 23, 2022

Single-Shot Motion Completion with Transformer
Single-Shot Motion Completion with Transformer 👉 [Preprint] 👈 Abstract Motion completion is a challenging and long-discussed problem, which is of gr
 78 Dec 29, 2022
78 Dec 29, 2022
![[ICCV 2021] Relaxed Transformer Decoders for Direct Action Proposal Generation](https://github.com/MCG-NJU/RTD-Action/raw/main/rtd_overview.png)
[ICCV 2021] Relaxed Transformer Decoders for Direct Action Proposal Generation
RTD-Net (ICCV 2021) This repo holds the codes of paper: "Relaxed Transformer Decoders for Direct Action Proposal Generation", accepted in ICCV 2021. N
 80 Nov 30, 2022
80 Nov 30, 2022
IOT: Instance-wise Layer Reordering for Transformer Structures
Introduction This repository contains the code for Instance-wise Ordered Transformer (IOT), which is introduced in the ICLR2021 paper IOT: Instance-wi
 19 Nov 15, 2022
19 Nov 15, 2022

Code and Resources for the Transformer Encoder Reasoning Network (TERN)
Transformer Encoder Reasoning Network Code for the cross-modal visual-linguistic retrieval method from "Transformer Reasoning Network for Image-Text M
 53 Dec 30, 2022
53 Dec 30, 2022
Effective Use of Transformer Networks for Entity Tracking
Effective Use of Transformer Networks for Entity Tracking (EMNLP19) This is a PyTorch implementation of our EMNLP paper on the effectiveness of pre-tr
 5 Nov 6, 2021
5 Nov 6, 2021
Pytorch implementation of set transformer
set_transformer Official PyTorch implementation of the paper Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks .
 410 Jan 6, 2023
410 Jan 6, 2023

Pytorch implementation of Compressive Transformers, from Deepmind
Compressive Transformer in Pytorch Pytorch implementation of Compressive Transformers, a variant of Transformer-XL with compressed memory for long-ran
 118 Dec 1, 2022
118 Dec 1, 2022
Code repo for "Transformer on a Diet" paper
Transformer on a Diet Reference: C Wang, Z Ye, A Zhang, Z Zhang, A Smola. "Transformer on a Diet". arXiv preprint arXiv (2020). Installation pip insta
 31 Sep 26, 2021
31 Sep 26, 2021
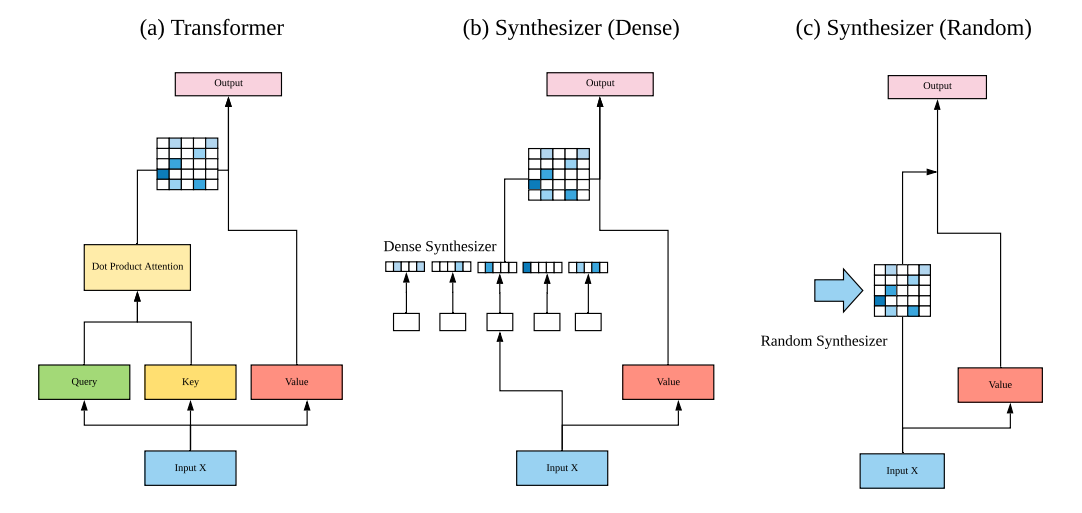
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch Reference Paper URL Author: Yi Tay, Dara Bahri, Donald Metzler
 66 Nov 30, 2022
66 Nov 30, 2022

Implementation of Memformer, a Memory-augmented Transformer, in Pytorch
Memformer - Pytorch Implementation of Memformer, a Memory-augmented Transformer, in Pytorch. It includes memory slots, which are updated with attentio
60 Nov 6, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022

This is the official implementation of our proposed SwinMR
SwinMR This is the official implementation of our proposed SwinMR: Swin Transformer for Fast MRI Please cite: @article{huang2022swin, title={Swi
 27 Nov 17, 2022
27 Nov 17, 2022
Accurate identification of bacteriophages from metagenomic data using Transformer
PhaMer is a python library for identifying bacteriophages from metagenomic data. PhaMer is based on a Transorfer model and rely on protein-based vocab
 9 Nov 30, 2022
9 Nov 30, 2022
The official implementation of ELSA: Enhanced Local Self-Attention for Vision Transformer
ELSA: Enhanced Local Self-Attention for Vision Transformer By Jingkai Zhou, Pich
 87 Dec 19, 2022
87 Dec 19, 2022
MPViT:Multi-Path Vision Transformer for Dense Prediction
MPViT : Multi-Path Vision Transformer for Dense Prediction This repository inlcu
 272 Dec 20, 2022
272 Dec 20, 2022

Repository of Vision Transformer with Deformable Attention
Vision Transformer with Deformable Attention This repository contains the code for the paper Vision Transformer with Deformable Attention [arXiv]. Int
 410 Jan 3, 2023
410 Jan 3, 2023
A Transformer Implementation that is easy to understand and customizable.
Simple Transformer I've written a series of articles on the transformer architecture and language models on Medium. This repository contains an implem
 4 Jan 20, 2022
4 Jan 20, 2022
Unofficial PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution
PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution [arXiv 2021].
 122 Dec 12, 2022
122 Dec 12, 2022
The official TensorFlow implementation of the paper Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition
Action Transformer A Self-Attention Model for Short-Time Human Action Recognition This repository contains the official TensorFlow implementation of t
 20 Jan 3, 2023
20 Jan 3, 2023
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
19 Dec 12, 2022
Generating new names based on trends in data using GPT2 (Transformer network)
MLOpsNameGenerator Overall Goal The goal of the project is to develop a model that is capable of creating Pokémon names based on its description, usin
 2 Jan 10, 2022
2 Jan 10, 2022

Implementation of a Transformer using ReLA (Rectified Linear Attention)
ReLA (Rectified Linear Attention) Transformer Implementation of a Transformer using ReLA (Rectified Linear Attention). It will also contain an attempt
49 Oct 14, 2022
Trax — Deep Learning with Clear Code and Speed
Trax — Deep Learning with Clear Code and Speed Trax is an end-to-end library for deep learning that focuses on clear code and speed. It is actively us
 7.3k Dec 26, 2022
7.3k Dec 26, 2022

RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Tr
 230 Dec 31, 2022
230 Dec 31, 2022

A Transformer-Based Siamese Network for Change Detection
ChangeFormer: A Transformer-Based Siamese Network for Change Detection (Under review at IGARSS-2022) Wele Gedara Chaminda Bandara, Vishal M. Patel Her
 32 Jan 9, 2022
32 Jan 9, 2022
![End-to-end Temporal Action Detection with Transformer. [Under review]](https://github.com/xlliu7/TadTR/raw/master/arch.png)
End-to-end Temporal Action Detection with Transformer. [Under review]
TadTR: End-to-end Temporal Action Detection with Transformer By Xiaolong Liu, Qimeng Wang, Yao Hu, Xu Tang, Song Bai, Xiang Bai. This repo holds the c
 105 Dec 25, 2022
105 Dec 25, 2022

This is a super simple visualization toolbox (script) for transformer attention visualization ✌
Trans_attention_vis This is a super simple visualization toolbox (script) for transformer attention visualization ✌ 1. How to prepare your attention m
 3 Jul 9, 2022
3 Jul 9, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
Adversarial Robustness Comparison of Vision Transformer and MLP-Mixer to CNNs
Adversarial Robustness Comparison of Vision Transformer and MLP-Mixer to CNNs ArXiv Abstract Convolutional Neural Networks (CNNs) have become the de f
 12 Oct 24, 2022
12 Oct 24, 2022
Deep learning PyTorch library for time series forecasting, classification, and anomaly detection
Deep learning for time series forecasting Flow forecast is an open-source deep learning for time series forecasting framework. It provides all the lat
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
PASSL包含 SimCLR,MoCo,BYOL,CLIP等基于对比学习的图像自监督算法以及 Vision-Transformer,Swin-Transformer,BEiT,CVT,T2T,MLP_Mixer等视觉Transformer算法
PASSL Introduction PASSL is a Paddle based vision library for state-of-the-art Self-Supervised Learning research with PaddlePaddle. PASSL aims to acce
 186 Dec 29, 2022
186 Dec 29, 2022

Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch
Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch. Topics: Face detection with Detectron 2, Time Series anomaly detection with LSTM Autoencoders, Object Detection with YOLO v5, Build your first Neural Network, Time Series forecasting for Coronavirus daily cases, Sentiment Analysis with BERT.
 1.8k Dec 31, 2022
1.8k Dec 31, 2022

End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021)
PDVC Official implementation for End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021) [paper] [valse论文速递(Chinese)] This repo supports:
 118 Dec 16, 2022
118 Dec 16, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023
Code for the paper "Jukebox: A Generative Model for Music"
Status: Archive (code is provided as-is, no updates expected) Jukebox Code for "Jukebox: A Generative Model for Music" Paper Blog Explorer Colab Insta
 6k Jan 2, 2023
6k Jan 2, 2023

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023

Repository for Project Insight: NLP as a Service
Project Insight NLP as a Service Contents Introduction Features Installation Setup and Documentation Project Details Demonstration Directory Details H
 286 Dec 6, 2022
286 Dec 6, 2022
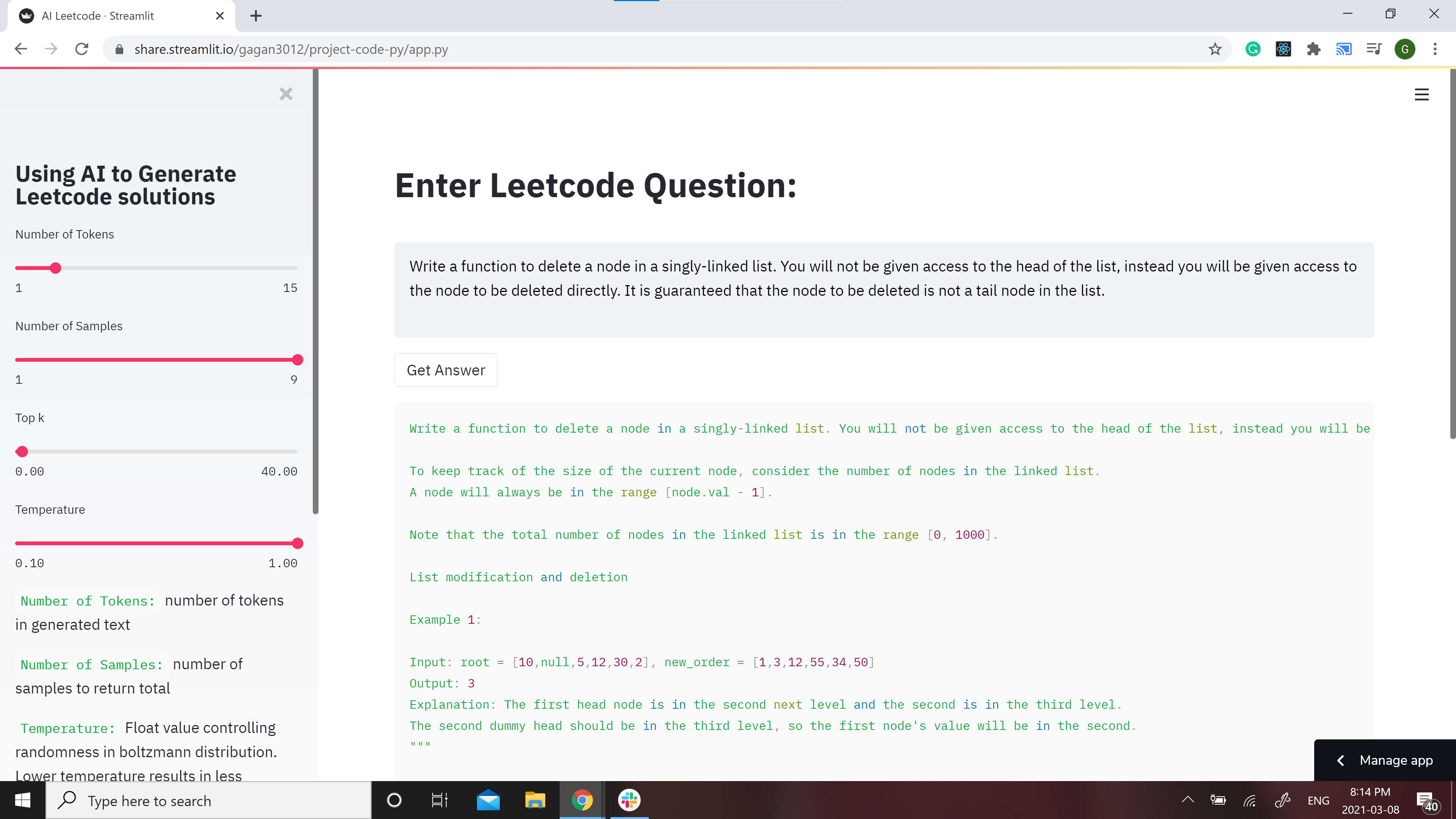
GPT-2 Model for Leetcode Questions in python
Leetcode using AI 🤖 GPT-2 Model for Leetcode Questions in python New demo here: https://huggingface.co/spaces/gagan3012/project-code-py Note: the Ans
 100 Dec 12, 2022
100 Dec 12, 2022
CV backbones including GhostNet, TinyNet and TNT, developed by Huawei Noah's Ark Lab.
CV Backbones including GhostNet, TinyNet, TNT (Transformer in Transformer) developed by Huawei Noah's Ark Lab. GhostNet Code TinyNet Code TNT Code Pyr
 3k Jan 8, 2023
3k Jan 8, 2023
A Transformer-Based Siamese Network for Change Detection
ChangeFormer: A Transformer-Based Siamese Network for Change Detection (Under review at IGARSS-2022) Wele Gedara Chaminda Bandara, Vishal M. Patel Her
214 Dec 29, 2022
Repository accompanying the "Sign Pose-based Transformer for Word-level Sign Language Recognition" paper
by Matyáš Boháček and Marek Hrúz, University of West Bohemia Should you have any questions or inquiries, feel free to contact us here. Repository acco
 30 Dec 30, 2022
30 Dec 30, 2022

Official Pytorch Implementation for Splicing ViT Features for Semantic Appearance Transfer presenting Splice
Splicing ViT Features for Semantic Appearance Transfer [Project Page] Splice is a method for semantic appearance transfer, as described in Splicing Vi
 253 Jan 6, 2023
253 Jan 6, 2023
Understanding and Overcoming the Challenges of Efficient Transformer Quantization
Transformer Quantization This repository contains the implementation and experiments for the paper presented in Yelysei Bondarenko1, Markus Nagel1, Ti
 83 Dec 30, 2022
83 Dec 30, 2022
Transformer - Transformer in PyTorch
Transformer 完成进度 Embeddings and PositionalEncoding with example. MultiHeadAttent
 1 Jan 6, 2022
1 Jan 6, 2022
Code for the paper: Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution
Fusformer Code for the paper: "Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution" Plateform Python 3.8.5 + Pytor
 11 Dec 12, 2022
11 Dec 12, 2022
![[CVPR 2021] Scan2Cap: Context-aware Dense Captioning in RGB-D Scans](https://github.com/daveredrum/Scan2Cap/raw/main/demo/Scan2Cap.gif)
[CVPR 2021] Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
Scan2Cap: Context-aware Dense Captioning in RGB-D Scans Introduction We introduce the task of dense captioning in 3D scans from commodity RGB-D sensor
 79 Nov 7, 2022
79 Nov 7, 2022
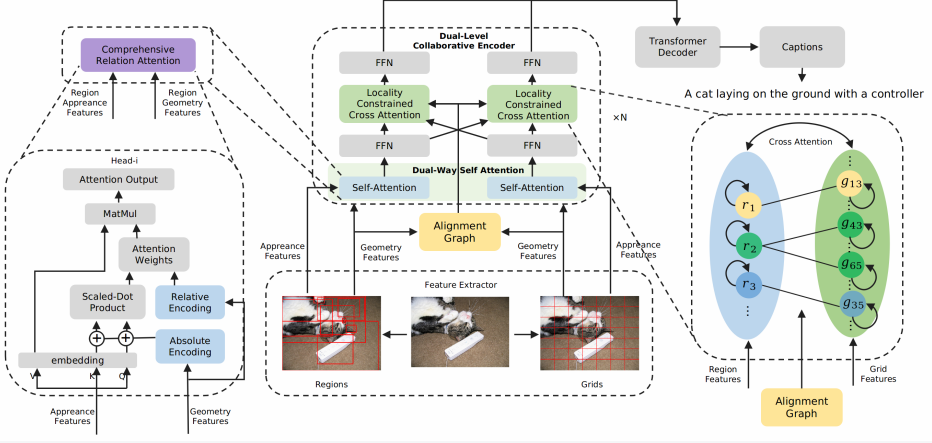
Official pytorch implementation of paper Dual-Level Collaborative Transformer for Image Captioning (AAAI 2021).
Dual-Level Collaborative Transformer for Image Captioning This repository contains the reference code for the paper Dual-Level Collaborative Transform
 160 Dec 11, 2022
160 Dec 11, 2022
Official pytorch implementation of the AAAI 2021 paper Semantic Grouping Network for Video Captioning
Semantic Grouping Network for Video Captioning Hobin Ryu, Sunghun Kang, Haeyong Kang, and Chang D. Yoo. AAAI 2021. [arxiv] Environment Ubuntu 16.04 CU
 43 Nov 25, 2022
43 Nov 25, 2022
LaBERT - A length-controllable and non-autoregressive image captioning model.
Length-Controllable Image Captioning (ECCV2020) This repo provides the implemetation of the paper Length-Controllable Image Captioning. Install conda
 53 Nov 13, 2022
53 Nov 13, 2022