1028 Repositories
Python WORDLE-VISION Libraries
This repository builds a basic vision transformer from scratch so that one beginner can understand the theory of vision transformer.
vision-transformer-from-scratch This repository includes several kinds of vision transformers from scratch so that one beginner can understand the the
 1 Dec 24, 2021
1 Dec 24, 2021
Collection of common code that's shared among different research projects in FAIR computer vision team.
fvcore fvcore is a light-weight core library that provides the most common and essential functionality shared in various computer vision frameworks de
 1.5k Jan 7, 2023
1.5k Jan 7, 2023

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
 217 Dec 5, 2022
217 Dec 5, 2022
Code for the paper "VisualBERT: A Simple and Performant Baseline for Vision and Language"
This repository contains code for the following two papers: VisualBERT: A Simple and Performant Baseline for Vision and Language (arxiv) with a short
 464 Jan 4, 2023
464 Jan 4, 2023
Multi Task Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning Please cite the following if you use this code. Code and pre-trained models for 12-in-
711 Jan 8, 2023

Pytorch implementation of the paper "Class-Balanced Loss Based on Effective Number of Samples"
Class-balanced-loss-pytorch Pytorch implementation of the paper Class-Balanced Loss Based on Effective Number of Samples presented at CVPR'19. Yin Cui
 697 Dec 29, 2022
697 Dec 29, 2022
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning. CVPR 2018
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning Tensorflow code and models for the paper: Large Scale Fine-Grained Categ
 187 Oct 1, 2022
187 Oct 1, 2022

Learn the Deep Learning for Computer Vision in three steps: theory from base to SotA, code in PyTorch, and space-repetition with Anki
DeepCourse: Deep Learning for Computer Vision arthurdouillard.com/deepcourse/ This is a course I'm giving to the French engineering school EPITA each
 113 Nov 29, 2022
113 Nov 29, 2022
💃 VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
💃 VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena.
 17 Nov 7, 2022
17 Nov 7, 2022

MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity Introduction The 3D LiDAR place recognition aim
 16 Dec 8, 2022
16 Dec 8, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022

Code basis for the paper "Camera Condition Monitoring and Readjustment by means of Noise and Blur" (2021)
Camera Condition Monitoring and Readjustment by means of Noise and Blur This repository contains the source code of the paper: Wischow, M., Gallego, G
 7 Dec 22, 2022
7 Dec 22, 2022

Get 2D point positions (e.g., facial landmarks) projected on 3D mesh
points2d_projection_mesh Input 2D points (e.g. facial landmarks) on an image Camera parameters (extrinsic and intrinsic) of the image Aligned 3D mesh
 5 Dec 8, 2022
5 Dec 8, 2022

(Preprint) Official PyTorch implementation of "How Do Vision Transformers Work?"
(Preprint) Official PyTorch implementation of "How Do Vision Transformers Work?"
 656 Dec 30, 2022
656 Dec 30, 2022

SRA's seminar on Introduction to Computer Vision Fundamentals
Introduction to Computer Vision This repository includes basics to : Python Numpy: A python library Git Computer Vision. The aim of this repository is
 147 Dec 4, 2022
147 Dec 4, 2022
A Vision Transformer approach that uses concatenated query and reference images to learn the relationship between query and reference images directly.
A Vision Transformer approach that uses concatenated query and reference images to learn the relationship between query and reference images directly.
 24 Dec 13, 2022
24 Dec 13, 2022

Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX.
Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX. The repository combines a class agnostic object localizer to first detect the objects in the image, and next a ResNet50 model trained on ImageNet is used to label each box.
 24 Nov 14, 2022
24 Nov 14, 2022

Computer Vision Script to recognize first person motion, developed as final project for the course "Machine Learning and Deep Learning"
Overview of The Code BaseColab/MLDL_FPAR.pdf: it contains the full explanation of our work Base Colab: it contains the base colab used to perform all
 4 Jul 16, 2022
4 Jul 16, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022

Official code of IterMVS
IterMVS official source code of paper 'IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo' Introduction IterMVS is a novel lear
 30 Dec 12, 2021
30 Dec 12, 2021
Re-implememtation of MAE (Masked Autoencoders Are Scalable Vision Learners) using PyTorch.
mae-repo PyTorch re-implememtation of "masked autoencoders are scalable vision learners". In this repo, it heavily borrows codes from codebase https:/
 1 Dec 14, 2021
1 Dec 14, 2021

Official Implementation for the paper DeepFace-EMD: Re-ranking Using Patch-wise Earth Mover’s Distance Improves Out-Of-Distribution Face Identification
DeepFace-EMD: Re-ranking Using Patch-wise Earth Mover’s Distance Improves Out-Of-Distribution Face Identification Official Implementation for the pape
 36 Dec 28, 2022
36 Dec 28, 2022
This is the official code for the paper "Learning with Nested Scene Modeling and Cooperative Architecture Search for Low-Light Vision"
RUAS This is the official code for the paper "Learning with Nested Scene Modeling and Cooperative Architecture Search for Low-Light Vision" A prelimin
 2 May 5, 2022
2 May 5, 2022
Official source code of paper 'IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo'
IterMVS official source code of paper 'IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo' Introduction IterMVS is a novel lear
127 Jan 4, 2023

Supplemental learning materials for "Fourier Feature Networks and Neural Volume Rendering"
Fourier Feature Networks and Neural Volume Rendering This repository is a companion to a lecture given at the University of Cambridge Engineering Depa
 133 Dec 26, 2022
133 Dec 26, 2022

Class-Balanced Loss Based on Effective Number of Samples. CVPR 2019
Class-Balanced Loss Based on Effective Number of Samples Tensorflow code for the paper: Class-Balanced Loss Based on Effective Number of Samples Yin C
546 Jan 8, 2023

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Python library for computer vision labeling tasks. The core functionality is to translate bounding box annotations between different formats-for example, from coco to yolo.
PyLabel pip install pylabel PyLabel is a Python package to help you prepare image datasets for computer vision models including PyTorch and YOLOv5. I
 176 Jan 1, 2023
176 Jan 1, 2023

A simple rest api that classifies pneumonia infection weather it is Normal, Pneumonia Virus or Pneumonia Bacteria from a chest-x-ray image.
This is a simple rest api that classifies pneumonia infection weather it is Normal, Pneumonia Virus or Pneumonia Bacteria from a chest-x-ray image.
 3 Jan 8, 2022
3 Jan 8, 2022

Localized representation learning from Vision and Text (LoVT)
Localized Vision-Text Pre-Training Contrastive learning has proven effective for pre- training image models on unlabeled data and achieved great resul
 10 Dec 7, 2022
10 Dec 7, 2022

CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks
CALVIN CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks Oier Mees, Lukas Hermann, Erick Rosete,
 107 Dec 26, 2022
107 Dec 26, 2022

Implementation of paper "Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal"
Patch-wise Adversarial Removal Implementation of paper "Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal
 4 Oct 12, 2022
4 Oct 12, 2022
Repository aimed at compiling code, papers, demos etc.. related to my PhD on 3D vision and machine learning for fruit detection and shape estimation at the university of Lincoln
PhD_3DPerception Repository aimed at compiling code, papers, demos etc.. related to my PhD on 3D vision and machine learning for fruit detection and s
 2 Oct 6, 2022
2 Oct 6, 2022
MLPs for Vision and Langauge Modeling (Coming Soon)
MLP Architectures for Vision-and-Language Modeling: An Empirical Study MLP Architectures for Vision-and-Language Modeling: An Empirical Study (Code wi
 27 May 9, 2022
27 May 9, 2022
Post-Training Quantization for Vision transformers.
PTQ4ViT Post-Training Quantization Framework for Vision Transformers. We use the twin uniform quantization method to reduce the quantization error on
 61 Dec 28, 2022
61 Dec 28, 2022

MapReader: A computer vision pipeline for the semantic exploration of maps at scale
MapReader A computer vision pipeline for the semantic exploration of maps at scale MapReader is an end-to-end computer vision (CV) pipeline designed b
 25 Dec 26, 2022
25 Dec 26, 2022
The implementation code for "DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction"
DAGAN This is the official implementation code for DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruct
 159 Nov 22, 2022
159 Nov 22, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022

A Tensorfflow implementation of Attend, Infer, Repeat
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models This is an unofficial Tensorflow implementation of Attend, Infear, Repeat (AIR)
 82 May 27, 2022
82 May 27, 2022
![[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation](https://user-images.githubusercontent.com/65257938/145016835-3c4be820-c55d-4eb4-b7f5-b8a012ee0f8c.png)
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
 2 Dec 7, 2021
2 Dec 7, 2021

PyTorch implementation of the paper Dynamic Token Normalization Improves Vision Transfromers.
Dynamic Token Normalization Improves Vision Transformers This is the PyTorch implementation of the paper Dynamic Token Normalization Improves Vision T
 20 Oct 9, 2022
20 Oct 9, 2022
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
70 Dec 4, 2022
Reproduction of Vision Transformer in Tensorflow2. Train from scratch and Finetune.
Vision Transformer(ViT) in Tensorflow2 Tensorflow2 implementation of the Vision Transformer(ViT). This repository is for An image is worth 16x16 words
 42 Dec 27, 2022
42 Dec 27, 2022
Spiking Neural Network for Computer Vision using SpikingJelly framework and Pytorch-Lightning
Spiking Neural Network for Computer Vision using SpikingJelly framework and Pytorch-Lightning
 2 Oct 20, 2022
2 Oct 20, 2022
Code repository for "Reducing Underflow in Mixed Precision Training by Gradient Scaling" presented at IJCAI '20
Reducing Underflow in Mixed Precision Training by Gradient Scaling This project implements the gradient scaling method to improve the performance of m
 5 Apr 14, 2022
5 Apr 14, 2022

Official Pytorch implementation for 2021 ICCV paper "Learning Motion Priors for 4D Human Body Capture in 3D Scenes" and trained models / data
Learning Motion Priors for 4D Human Body Capture in 3D Scenes (LEMO) Official Pytorch implementation for 2021 ICCV (oral) paper "Learning Motion Prior
 165 Dec 19, 2022
165 Dec 19, 2022
Single-Stage Instance Shadow Detection with Bidirectional Relation Learning (CVPR 2021 Oral)
Single-Stage Instance Shadow Detection with Bidirectional Relation Learning (CVPR 2021 Oral) Tianyu Wang*, Xiaowei Hu*, Chi-Wing Fu, and Pheng-Ann Hen
 51 Oct 20, 2022
51 Oct 20, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
 938 Dec 26, 2022
938 Dec 26, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss
UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss This repository contains the TensorFlow implementation of the paper UnF
 270 Nov 6, 2022
270 Nov 6, 2022

This is the official code repository for A Simple Long-Tailed Rocognition Baseline via Vision-Language Model.
BALLAD This is the official code repository for A Simple Long-Tailed Rocognition Baseline via Vision-Language Model. Requirements Python3 Pytorch(1.7.
 11 Dec 1, 2021
11 Dec 1, 2021
MapReader: A computer vision pipeline for the semantic exploration of maps at scale
MapReader A computer vision pipeline for the semantic exploration of maps at scale MapReader is an end-to-end computer vision (CV) pipeline designed b
25 Dec 26, 2022

A Simple Long-Tailed Rocognition Baseline via Vision-Language Model
BALLAD This is the official code repository for A Simple Long-Tailed Rocognition Baseline via Vision-Language Model. Requirements Python3 Pytorch(1.7.
 4 Jan 20, 2022
4 Jan 20, 2022
Official code repository for A Simple Long-Tailed Rocognition Baseline via Vision-Language Model.
This is the official code repository for A Simple Long-Tailed Rocognition Baseline via Vision-Language Model.
42 Nov 26, 2022
Datasets, Transforms and Models specific to Computer Vision
vision Datasets, Transforms and Models specific to Computer Vision Installation First install the nightly version of OneFlow python3 -m pip install on
 68 Dec 7, 2022
68 Dec 7, 2022

This is a collection of our NAS and Vision Transformer work.
This is a collection of our NAS and Vision Transformer work.
367 Nov 30, 2021
2021 National Underwater Robotics Vision Optics
2021-National-Underwater-Robotics-Vision-Optics 2021年全国水下机器人算法大赛-光学赛道-B榜精度第18名 (Kilian_Di的团队:A榜map@50:95 56.36 B榜map@50:95 56.7) 2021年全国水下机器人算法大赛-声学赛道
 9 Nov 4, 2022
9 Nov 4, 2022

The official implementation for "FQ-ViT: Fully Quantized Vision Transformer without Retraining".
FQ-ViT [arXiv] This repo contains the official implementation of "FQ-ViT: Fully Quantized Vision Transformer without Retraining". Table of Contents In
 132 Jan 8, 2023
132 Jan 8, 2023
This is a collection of our NAS and Vision Transformer work.
AutoML - Neural Architecture Search This is a collection of our AutoML-NAS work iRPE (NEW): Rethinking and Improving Relative Position Encoding for Vi
828 Dec 28, 2022

This repository contains the source code of our work on designing efficient CNNs for computer vision
Efficient networks for Computer Vision This repo contains source code of our work on designing efficient networks for different computer vision tasks:
 386 Nov 26, 2022
386 Nov 26, 2022
Code repository for the paper Computer Vision User Entity Behavior Analytics
Computer Vision User Entity Behavior Analytics Code repository for "Computer Vision User Entity Behavior Analytics" Code Description dataset.csv As di
 2 Aug 20, 2022
2 Aug 20, 2022

Official Pytorch Code for the paper TransWeather
TransWeather Official Code for the paper TransWeather, Arxiv Tech Report 2021 Paper | Website About this repo: This repo hosts the implentation code,
 81 Dec 30, 2022
81 Dec 30, 2022
Experimenting with computer vision techniques to generate annotated image datasets from gameplay recordings automatically.
Experimenting with computer vision techniques to generate annotated image datasets from gameplay recordings automatically. The collected data will then be used to train a deep neural network that can detect enemy player models in real time, during gameplay. Finally, a virtual input device will adjust the player's crosshair based on live detections for greater accuracy.
 3 Apr 24, 2022
3 Apr 24, 2022

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 5, 2023
2.4k Jan 5, 2023

Monk is a low code Deep Learning tool and a unified wrapper for Computer Vision.
Monk - A computer vision toolkit for everyone Why use Monk Issue: Want to begin learning computer vision Solution: Start with Monk's hands-on study ro
 507 Dec 4, 2022
507 Dec 4, 2022

We are building an open database of COVID-19 cases with chest X-ray or CT images.
🛑 Note: please do not claim diagnostic performance of a model without a clinical study! This is not a kaggle competition dataset. Please read this pa
 2.9k Dec 30, 2022
2.9k Dec 30, 2022
HybVIO visual-inertial odometry and SLAM system
HybVIO A visual-inertial odometry system with an optional SLAM module. This is a research-oriented codebase, which has been published for the purposes
 320 Jan 3, 2023
320 Jan 3, 2023
labelpix is a graphical image labeling interface for drawing bounding boxes
Welcome to labelpix 👋 labelpix is a graphical image labeling interface for drawing bounding boxes. 🏠 Homepage Install pip install -r requirements.tx
 26 May 24, 2022
26 May 24, 2022
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
105 Jan 8, 2022

Official repository for the paper F, B, Alpha Matting
FBA Matting Official repository for the paper F, B, Alpha Matting. This paper and project is under heavy revision for peer reviewed publication, and s
 404 Jan 5, 2023
404 Jan 5, 2023

The code for the NeurIPS 2021 paper "A Unified View of cGANs with and without Classifiers".
Energy-based Conditional Generative Adversarial Network (ECGAN) This is the code for the NeurIPS 2021 paper "A Unified View of cGANs with and without
 11 Nov 25, 2021
11 Nov 25, 2021
Code of TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
TVT Code of TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation Datasets: Digit: MNIST, SVHN, USPS Object: Office, Office-Home, Vi
 37 Dec 15, 2022
37 Dec 15, 2022

Source code for CVPR 2020 paper "Learning to Forget for Meta-Learning"
L2F - Learning to Forget for Meta-Learning Sungyong Baik, Seokil Hong, Kyoung Mu Lee Source code for CVPR 2020 paper "Learning to Forget for Meta-Lear
 29 May 22, 2022
29 May 22, 2022
🔥RandLA-Net in Tensorflow (CVPR 2020, Oral & IEEE TPAMI 2021)
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020) This is the official implementation of RandLA-Net (CVPR2020, Oral
 1k Dec 30, 2022
1k Dec 30, 2022
OpenMMLab Computer Vision Foundation
English | 简体中文 Introduction MMCV is a foundational library for computer vision research and supports many research projects as below: MMCV: OpenMMLab
 4.6k Jan 9, 2023
4.6k Jan 9, 2023

A minimal solution to hand motion capture from a single color camera at over 100fps. Easy to use, plug to run.
Minimal Hand A minimal solution to hand motion capture from a single color camera at over 100fps. Easy to use, plug to run. This project provides the
 824 Jan 7, 2023
824 Jan 7, 2023
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
Yolo v4, v3 and v2 for Windows and Linux (neural networks for object detection) Paper YOLO v4: https://arxiv.org/abs/2004.10934 Paper Scaled YOLO v4:
 20.2k Jan 9, 2023
20.2k Jan 9, 2023

A hybrid SOTA solution of LiDAR panoptic segmentation with C++ implementations of point cloud clustering algorithms. ICCV21, Workshop on Traditional Computer Vision in the Age of Deep Learning
ICCVW21-TradiCV-Survey-of-LiDAR-Cluster Motivation In contrast to popular end-to-end deep learning LiDAR panoptic segmentation solutions, we propose a
 103 Nov 22, 2022
103 Nov 22, 2022

A TensorFlow 2.x implementation of Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders Are Scalable Vision Learners A TensorFlow implementation of Masked Autoencoders Are Scalable Vision Learners [1]. Our implementati
 59 Dec 10, 2022
59 Dec 10, 2022

Official PyTorch implementation of "Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning" (ICCV2021 Oral)
MeTAL - Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning (ICCV2021 Oral) Sungyong Baik, Janghoon Choi, Heewon Kim, Dohee Cho, Jaes
44 Dec 29, 2022

R interface to fast.ai
R interface to fastai The fastai package provides R wrappers to fastai. The fastai library simplifies training fast and accurate neural nets using mod
 113 Dec 20, 2022
113 Dec 20, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023
Official Implementation of "Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras"
Multi Camera Pig Tracking Official Implementation of Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras CVPR2021 CV4Animals Workshop P
 44 Jan 6, 2023
44 Jan 6, 2023
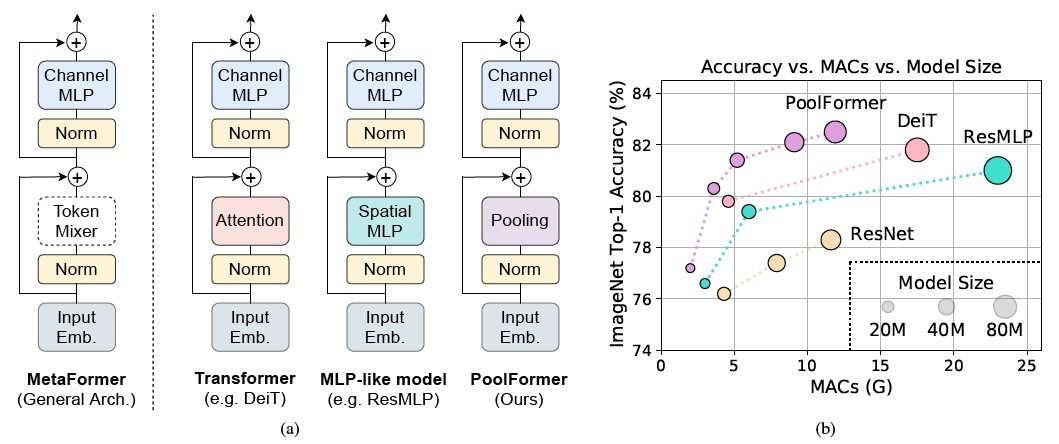
PoolFormer: MetaFormer is Actually What You Need for Vision
PoolFormer: MetaFormer is Actually What You Need for Vision (arXiv) This is a PyTorch implementation of PoolFormer proposed by our paper "MetaFormer i
 1k Dec 30, 2022
1k Dec 30, 2022
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks Image Classification Dataset: Google Landmark, COCO, ImageNet Model: Efficient
 62 Dec 10, 2022
62 Dec 10, 2022
Unofficial keras(tensorflow) implementation of MAE model from Masked Autoencoders Are Scalable Vision Learners
MAE-keras Unofficial keras(tensorflow) implementation of MAE model described in 'Masked Autoencoders Are Scalable Vision Learners'. This work has been
 11 Jun 12, 2022
11 Jun 12, 2022

Tensorflow 2.x implementation of Vision-Transformer model
Vision Transformer Unofficial Tensorflow 2.x implementation of the Transformer based Image Classification model proposed by the paper AN IMAGE IS WORT
 16 Jul 20, 2022
16 Jul 20, 2022

PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition, CVPR 2018
PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place
 294 Dec 12, 2022
294 Dec 12, 2022
COLMAP - Structure-from-Motion and Multi-View Stereo
COLMAP About COLMAP is a general-purpose Structure-from-Motion (SfM) and Multi-View Stereo (MVS) pipeline with a graphical and command-line interface.
 4.7k Jan 7, 2023
4.7k Jan 7, 2023

Current state of supervised and unsupervised depth completion methods
Awesome Depth Completion Table of Contents About Sparse-to-Dense Depth Completion Current State of Depth Completion Unsupervised VOID Benchmark Superv
 224 Dec 28, 2022
224 Dec 28, 2022

Multi-modal Vision Transformers Excel at Class-agnostic Object Detection
Multi-modal Vision Transformers Excel at Class-agnostic Object Detection
 206 Jan 4, 2023
206 Jan 4, 2023

Detectron2 for Document Layout Analysis
Detectron2 trained on PubLayNet dataset This repo contains the training configurations, code and trained models trained on PubLayNet dataset using Det
 163 Nov 21, 2022
163 Nov 21, 2022

Open source simulator for autonomous vehicles built on Unreal Engine / Unity, from Microsoft AI & Research
Welcome to AirSim AirSim is a simulator for drones, cars and more, built on Unreal Engine (we now also have an experimental Unity release). It is open
13.8k Jan 5, 2023

TransMorph: Transformer for Medical Image Registration
TransMorph: Transformer for Medical Image Registration keywords: Vision Transformer, Swin Transformer, convolutional neural networks, image registrati
 180 Jan 7, 2023
180 Jan 7, 2023
Deep Learning with PyTorch made easy 🚀 !
Deep Learning with PyTorch made easy 🚀 ! Carefree? carefree-learn aims to provide CAREFREE usages for both users and developers. It also provides a c
 381 Dec 22, 2022
381 Dec 22, 2022