3466 Repositories
Python data-pre-processing Libraries
An assignment from my grad-level data mining course demonstrating some experience with NLP/neural networks/Pytorch
NLP-Pytorch-Assignment An assignment from my grad-level data mining course (before I started personal projects) demonstrating some experience with NLP
 0 Feb 6, 2022
0 Feb 6, 2022
Demonstrate a Dataflow pipeline that saves data from an API into BigQuery table
Overview dataflow-mvp provides a basic example pipeline that pulls data from an API and writes it to a BigQuery table using GCP's Dataflow (i.e., Apac
 1 Dec 3, 2021
1 Dec 3, 2021
A Python library for loading data from a SpaceX Starlink satellite.
Starlink Python A Python library for loading data from a SpaceX Starlink satellite. The goal is to be a simple interface for Starlink. It builds upon
 2 Jan 16, 2022
2 Jan 16, 2022
Visualize large time-series data in plotly
plotly_resampler enables visualizing large sequential data by adding resampling functionality to Plotly figures. In this Plotly-Resampler demo over 11
 604 Dec 28, 2022
604 Dec 28, 2022
Rainbow DQN implementation accompanying the paper "Fast and Data-Efficient Training of Rainbow" which reaches 205.7 median HNS after 10M frames. 🌈
Rainbow 🌈 An implementation of Rainbow DQN which reaches a median HNS of 205.7 after only 10M frames (the original Rainbow from Hessel et al. 2017 re
 15 Dec 3, 2021
15 Dec 3, 2021

Code for EMNLP 2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training"
SCAPT-ABSA Code for EMNLP2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training" Overvie
 66 Dec 4, 2022
66 Dec 4, 2022
Randomisation-based inference in Python based on data resampling and permutation.
Randomisation-based inference in Python based on data resampling and permutation.
 67 Dec 27, 2022
67 Dec 27, 2022
Python code for working with NFL play by play data.
nfl_data_py nfl_data_py is a Python library for interacting with NFL data sourced from nflfastR, nfldata, dynastyprocess, and Draft Scout. Includes im
 82 Jan 5, 2023
82 Jan 5, 2023
voice assistant made with python that search for covid19 data(like total cases, deaths and etc) in a specific country
covid19-voice-assistant voice assistant made with python that search for covid19 data(like total cases, deaths and etc) in a specific country installi
 2 Dec 5, 2021
2 Dec 5, 2021

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
 223 Dec 5, 2022
223 Dec 5, 2022
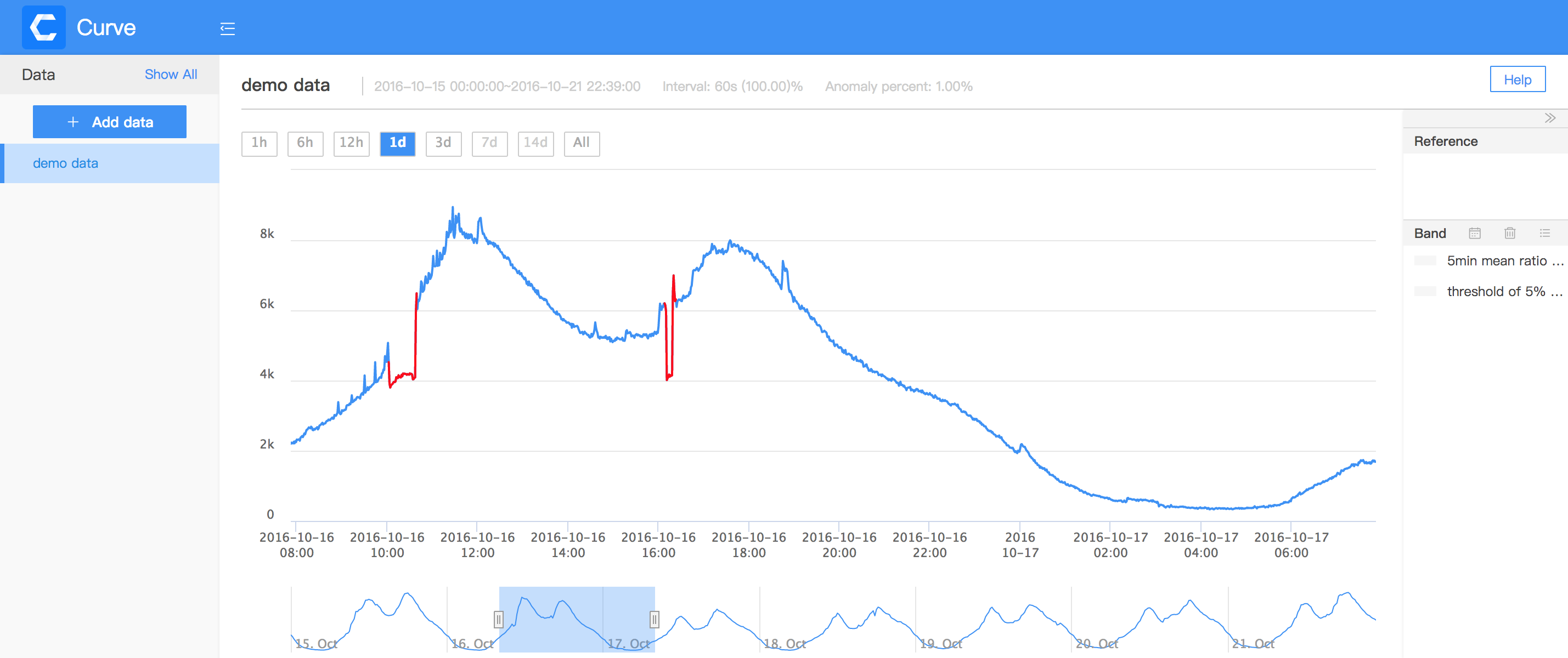
An Integrated Experimental Platform for time series data anomaly detection.
Curve Sorry to tell contributors and users. We decided to archive the project temporarily due to the employee work plan of collaborators. There are no
 486 Dec 21, 2022
486 Dec 21, 2022
Natural Language Processing Tasks and Examples.
Natural Language Processing Tasks and Examples With the advancement of A.I. technology in recent years, natural language processing technology has bee
 53 Dec 20, 2022
53 Dec 20, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Python script to tabulate data formats like json, csv, html, etc
pyT PyT is a a command line tool and as well a library for visualising various data formats like: JSON HTML Table CSV XML, etc. Features Print table o
 1 Dec 30, 2021
1 Dec 30, 2021

MS in Data Science capstone project. Studying attacks on autonomous vehicles.
Surveying Attack Models for CAVs Guide to Installing CARLA and Collecting Data Our project focuses on surveying attack models for Connveced Autonomous
 1 Dec 9, 2021
1 Dec 9, 2021
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
 9 Mar 24, 2022
9 Mar 24, 2022

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
 228 Nov 21, 2022
228 Nov 21, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022

SentAugment is a data augmentation technique for semi-supervised learning in NLP.
SentAugment SentAugment is a data augmentation technique for semi-supervised learning in NLP. It uses state-of-the-art sentence embeddings to structur
 363 Dec 30, 2022
363 Dec 30, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022
Creating predictive checklists from data using integer programming.
Learning Optimal Predictive Checklists A Python package to learn simple predictive checklists from data subject to customizable constraints. For more
 5 Apr 19, 2022
5 Apr 19, 2022
![Code and Data for the paper: Molecular Contrastive Learning with Chemical Element Knowledge Graph [AAAI 2022]](https://github.com/Fangyin1994/KCL/raw/main/fig/overview.png)
Code and Data for the paper: Molecular Contrastive Learning with Chemical Element Knowledge Graph [AAAI 2022]
Knowledge-enhanced Contrastive Learning (KCL) Molecular Contrastive Learning with Chemical Element Knowledge Graph [ AAAI 2022 ]. We construct a Chemi
 58 Dec 26, 2022
58 Dec 26, 2022
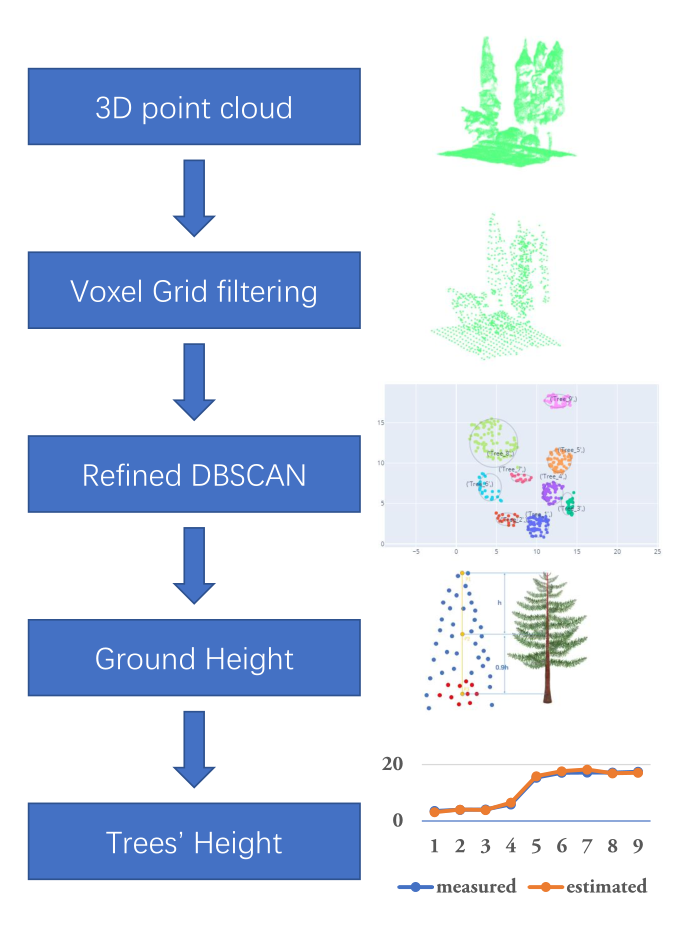
A simple algorithm for extracting tree height in sparse scene from point cloud data.
TREE HEIGHT EXTRACTION IN SPARSE SCENES BASED ON UAV REMOTE SENSING This is the offical python implementation of the paper "Tree Height Extraction in
 6 Oct 28, 2022
6 Oct 28, 2022

My notes on Data structure and Algos in golang implementation and python
My notes on DS and Algo Table of Contents Arrays LinkedList Trees Types of trees: Tree/Graph Traversal Algorithms Heap Priorty Queue Trie Graphs Graph
 0 Feb 13, 2022
0 Feb 13, 2022
Minimal pure Python library for working with little-endian list representation of bit strings.
bitlist Minimal Python library for working with bit vectors natively. Purpose This library allows programmers to work with a native representation of
 0 Jul 25, 2022
0 Jul 25, 2022

Google, Facebook, Amazon, Microsoft, Netflix tech interview questions
Algorithm and Data Structures Interview Questions HackerRank | Practice, Tutorials & Interview Preparation Solutions This repository consists of solut
 8 Oct 4, 2022
8 Oct 4, 2022
Learn to code in any language. If
Learn to Code It is an intiiative undertaken by Student Ambassadors Club, Jamshoro for students who are absolute begineers in programming and want to
 15 Oct 19, 2022
15 Oct 19, 2022
Multiple Imputation with Random Forests in Python
miceforest: Fast, Memory Efficient Imputation with lightgbm Fast, memory efficient Multiple Imputation by Chained Equations (MICE) with lightgbm. The
 202 Dec 31, 2022
202 Dec 31, 2022
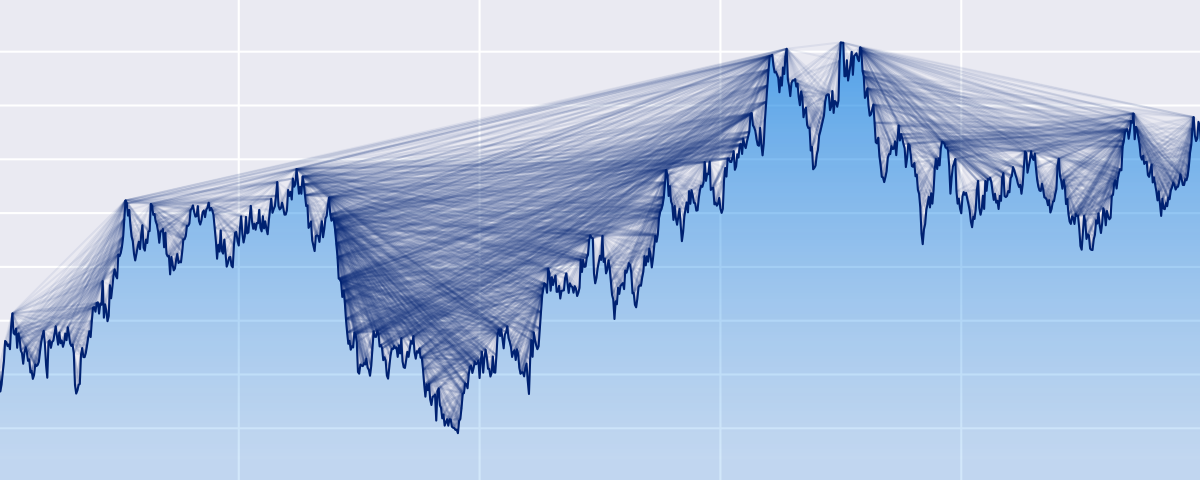
Python ts2vg package provides high-performance algorithm implementations to build visibility graphs from time series data.
ts2vg: Time series to visibility graphs The Python ts2vg package provides high-performance algorithm implementations to build visibility graphs from t
 26 Dec 17, 2022
26 Dec 17, 2022

Very useful and necessary functions that simplify working with data
Additional-function-for-pandas Very useful and necessary functions that simplify working with data random_fill_nan(module_name, nan) - Replaces all sp
 2 Dec 2, 2021
2 Dec 2, 2021
Makes google's political ad database actually useful
Making Google's political ad transparency library suck less This is a series of scripts that takes Google's political ad transparency data and makes t
 7 Apr 28, 2022
7 Apr 28, 2022
A tool to nowcast quarterly data with monthly indicators: US consumption example
MIDAS_Nowcaster A tool to nowcast quarterly data with monthly indicators: US consumption example Pulls data directly from FRED from a list of codes -
 3 Oct 6, 2022
3 Oct 6, 2022
Data Exfiltration without ever making a connection. Using TCP header space.
TCPwned PoC toy code to exfiltrate data without ever making a TCP connection. This will never show up in firewall logs, much less, actually be monitor
 2 Nov 21, 2022
2 Nov 21, 2022
Upgini : data search library for your machine learning pipelines
Automated data search library for your machine learning pipelines → find & deliver relevant external data & features to boost ML accuracy :chart_with_upwards_trend:
 175 Jan 8, 2023
175 Jan 8, 2023
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022
Code and pre-trained models for "ReasonBert: Pre-trained to Reason with Distant Supervision", EMNLP'2021
ReasonBERT Code and pre-trained models for ReasonBert: Pre-trained to Reason with Distant Supervision, EMNLP'2021 Pretrained Models The pretrained mod
 29 Dec 19, 2022
29 Dec 19, 2022
Code for Editing Factual Knowledge in Language Models
KnowledgeEditor Code for Editing Factual Knowledge in Language Models (https://arxiv.org/abs/2104.08164). @inproceedings{decao2021editing, title={Ed
 86 Nov 28, 2022
86 Nov 28, 2022
A Model for Natural Language Attack on Text Classification and Inference
TextFooler A Model for Natural Language Attack on Text Classification and Inference This is the source code for the paper: Jin, Di, et al. "Is BERT Re
 418 Dec 16, 2022
418 Dec 16, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022
The repository for the paper "When Do You Need Billions of Words of Pretraining Data?"
pretraining-learning-curves This is the repository for the paper When Do You Need Billions of Words of Pretraining Data? Edge Probing We use jiant1 fo
 19 Nov 25, 2022
19 Nov 25, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
8.4k Dec 28, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022
Code associated with the Don't Stop Pretraining ACL 2020 paper
dont-stop-pretraining Code associated with the Don't Stop Pretraining ACL 2020 paper Citation @inproceedings{dontstoppretraining2020, author = {Suchi
 449 Jan 4, 2023
449 Jan 4, 2023
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022
EMNLP 2021 paper "Pre-train or Annotate? Domain Adaptation with a Constrained Budget".
Pre-train or Annotate? Domain Adaptation with a Constrained Budget This repo contains code and data associated with EMNLP 2021 paper "Pre-train or Ann
 8 Dec 17, 2021
8 Dec 17, 2021

Source code for the ACL-IJCNLP 2021 paper entitled "T-DNA: Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adaptation" by Shizhe Diao et al.
T-DNA Source code for the ACL-IJCNLP 2021 paper entitled Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adapta
 17 Dec 22, 2022
17 Dec 22, 2022
Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF shows significant improvements over baseline fine-tuning without data filtration.
Information Gain Filtration Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF sho
 4 Jul 28, 2022
4 Jul 28, 2022
The code is the training example of AAAI2022 Security AI Challenger Program Phase 8: Data Centric Robot Learning on ML models.
Example code of [Tianchi AAAI2022 Security AI Challenger Program Phase 8]
 22 Oct 14, 2022
22 Oct 14, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

clustimage is a python package for unsupervised clustering of images.
clustimage The aim of clustimage is to detect natural groups or clusters of images. Image recognition is a computer vision task for identifying and ve
 52 Jan 2, 2023
52 Jan 2, 2023

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
 45 Dec 3, 2021
45 Dec 3, 2021
Data preprocessing rosetta parser for python
datapreprocessing_rosetta_parser I've never done any NLP or text data processing before, so I wanted to use this hackathon as a learning opportunity,
 2 Nov 28, 2021
2 Nov 28, 2021
Async boto3 with Autogenerated Data Classes
awspydk Async boto3 with Autogenerated JIT Data Classes Motivation This library is forked from an internal project that works with a lot of backend AW
 1 Dec 5, 2021
1 Dec 5, 2021
A command line tool that creates a super timeline from SentinelOne's Deep Visibility data
S1SuperTimeline A command line tool that creates a super timeline from SentinelOne's Deep Visibility data What does it do? The script accepts a S1QL q
 2 Feb 8, 2022
2 Feb 8, 2022
Visualize your pandas data with one-line code
PandasEcharts 简介 基于pandas和pyecharts的可视化工具 安装 pip 安装 $ pip install pandasecharts 源码安装 $ git clone https://github.com/gamersover/pandasecharts $ cd pand
 2 Apr 13, 2022
2 Apr 13, 2022

A Pythonic framework for threat modeling
pytm: A Pythonic framework for threat modeling Introduction Traditional threat modeling too often comes late to the party, or sometimes not at all. In
 644 Dec 20, 2022
644 Dec 20, 2022

ClearML - Auto-Magical Suite of tools to streamline your ML workflow. Experiment Manager, MLOps and Data-Management
ClearML - Auto-Magical Suite of tools to streamline your ML workflow Experiment Manager, MLOps and Data-Management ClearML Formerly known as Allegro T
 3.9k Jan 1, 2023
3.9k Jan 1, 2023

Implementation of Neonatal Seizure Detection using EEG signals for deploying on edge devices including Raspberry Pi.
NeonatalSeizureDetection Description Link: https://arxiv.org/abs/2111.15569 Citation: @misc{nagarajan2021scalable, title={Scalable Machine Learn
 11 Nov 8, 2022
11 Nov 8, 2022
Official Repository for "Robust On-Policy Data Collection for Data Efficient Policy Evaluation" (NeurIPS 2021 Workshop on OfflineRL).
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation Source code of Robust On-Policy Data Collection for Data-Efficient Policy Evalua
 2 Oct 9, 2022
2 Oct 9, 2022
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
 72 Jan 1, 2023
72 Jan 1, 2023
Data Consistency for Magnetic Resonance Imaging
Data Consistency for Magnetic Resonance Imaging Data Consistency (DC) is crucial for generalization in multi-modal MRI data and robustness in detectin
 19 Dec 12, 2022
19 Dec 12, 2022

Automatic Data-Regularized Actor-Critic (Auto-DrAC)
Auto-DrAC: Automatic Data-Regularized Actor-Critic This is a PyTorch implementation of the methods proposed in Automatic Data Augmentation for General
 89 Dec 13, 2022
89 Dec 13, 2022
PyContinual (An Easy and Extendible Framework for Continual Learning)
PyContinual (An Easy and Extendible Framework for Continual Learning) Easy to Use You can sumply change the baseline, backbone and task, and then read
 176 Jan 5, 2023
176 Jan 5, 2023
Code to produce syntactic representations that can be used to study syntax processing in the human brain
Can fMRI reveal the representation of syntactic structure in the brain? The code base for our paper on understanding syntactic representations in the
 4 Dec 18, 2022
4 Dec 18, 2022
This repository is for the preprint "A generative nonparametric Bayesian model for whole genomes"
BEAR Overview This repository contains code associated with the preprint A generative nonparametric Bayesian model for whole genomes (2021), which pro
 10 Sep 18, 2022
10 Sep 18, 2022

Removing Inter-Experimental Variability from Functional Data in Systems Neuroscience
Removing Inter-Experimental Variability from Functional Data in Systems Neuroscience This repository is the official implementation of [https://www.bi
 6 Oct 9, 2022
6 Oct 9, 2022
Auditing Black-Box Prediction Models for Data Minimization Compliance
Data-Minimization-Auditor An auditing tool for model-instability based data minimization that is introduced in "Auditing Black-Box Prediction Models f
 2 Mar 24, 2022
2 Mar 24, 2022
[NeurIPS 2021] "G-PATE: Scalable Differentially Private Data Generator via Private Aggregation of Teacher Discriminators"
G-PATE This is the official code base for our NeurIPS 2021 paper: "G-PATE: Scalable Differentially Private Data Generator via Private Aggregation of T
 14 Oct 12, 2022
14 Oct 12, 2022
TAUFE: Task-Agnostic Undesirable Feature DeactivationUsing Out-of-Distribution Data
A deep neural network (DNN) has achieved great success in many machine learning tasks by virtue of its high expressive power. However, its prediction can be easily biased to undesirable features, which are not essential for solving the target task and are even imperceptible to a human, thereby resulting in poor generalization
 8 Dec 7, 2022
8 Dec 7, 2022
Equivariant layers for RC-complement symmetry in DNA sequence data
Equi-RC Equivariant layers for RC-complement symmetry in DNA sequence data This is a repository that implements the layers as described in "Reverse-Co
 7 May 19, 2022
7 May 19, 2022
Hide sensitive information in images
Data-Preserved Script allowing to blur the most sensitive information on images. Prerequisites Before you begin, ensure you have met the following req
 2 Dec 1, 2021
2 Dec 1, 2021

Official PyTorch implementation of Data-free Knowledge Distillation for Object Detection, WACV 2021.
Introduction This repository is the official PyTorch implementation of Data-free Knowledge Distillation for Object Detection, WACV 2021. Data-free Kno
 50 Jan 5, 2023
50 Jan 5, 2023
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
124 Jan 2, 2023
Sign data using symmetric-key algorithm encryption.
Sign data using symmetric-key algorithm encryption. Validate signed data and identify possible validation errors. Uses sha-(1, 224, 256, 385 and 512)/hmac for signature encryption. Custom hash algorithms are allowed. Useful shortcut functions for signing (and validating) dictionaries and URLs.
 39 Jun 10, 2022
39 Jun 10, 2022
A Python 3 library making time series data mining tasks, utilizing matrix profile algorithms
MatrixProfile MatrixProfile is a Python 3 library, brought to you by the Matrix Profile Foundation, for mining time series data. The Matrix Profile is
 302 Dec 29, 2022
302 Dec 29, 2022
Various Algorithms for Short Text Mining
Short Text Mining in Python Introduction This package shorttext is a Python package that facilitates supervised and unsupervised learning for short te
 466 Dec 6, 2022
466 Dec 6, 2022
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022

Memory tests solver with using OpenCV
Human Benchmark project This project is OpenCV based programs which are puzzle solvers for 7 different games for https://humanbenchmark.com/. made as
 24 Dec 27, 2022
24 Dec 27, 2022
An helper library to scrape data from Instagram effortlessly, using the Influencer Hunters APIs.
Instagram Scraper An utility library to scrape data from Instagram hassle-free Go to the website » View Demo · Report Bug · Request Feature About The
 2 Jul 6, 2022
2 Jul 6, 2022
tradingview socket api for fetching real time prices.
tradingView-API tradingview socket api for fetching real time prices. How to run git clone https://github.com/mohamadkhalaj/tradingView-API.git cd tra
 35 Dec 31, 2022
35 Dec 31, 2022
This repository is used to provide data to zzhack,
This repository is used to provide data to zzhack, but you don't have to care about anything, just write your thinking down, and you can see your thinking is rendered in zzhack perfectly
 5 Apr 29, 2022
5 Apr 29, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
 1 Nov 30, 2021
1 Nov 30, 2021
Code of our paper "Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning"
CCOP Code of our paper Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning Requirement Install OpenSelfSup Install Detectron2
 5 Nov 30, 2021
5 Nov 30, 2021