2785 Repositories
Python data-science-projects Libraries
Code and data of the Fine-Grained R2R Dataset proposed in paper Sub-Instruction Aware Vision-and-Language Navigation
Fine-Grained R2R Code and data of the Fine-Grained R2R Dataset proposed in the EMNLP2020 paper Sub-Instruction Aware Vision-and-Language Navigation. C
 34 Nov 15, 2022
34 Nov 15, 2022
🏅 The Most Comprehensive List of Kaggle Solutions and Ideas 🏅
🏅 Collection of Kaggle Solutions and Ideas 🏅
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
A list of multi-task learning papers and projects.
A list of multi-task learning papers and projects.
 84 Apr 27, 2021
84 Apr 27, 2021
A list of multi-task learning papers and projects.
This page contains a list of papers on multi-task learning for computer vision. Please create a pull request if you wish to add anything. If you are interested, consider reading our recent survey paper.
297 Dec 17, 2022

Coreference resolution for English, German and Polish, optimised for limited training data and easily extensible for further languages
Coreferee Author: Richard Paul Hudson, msg systems ag 1. Introduction 1.1 The basic idea 1.2 Getting started 1.2.1 English 1.2.2 German 1.2.3 Polish 1
 169 Dec 21, 2022
169 Dec 21, 2022
stock data on eink with raspberry
small python skript to display tradegate data on a waveshare e-ink important you need locale "de_AT.UTF-8 UTF-8" installed. do so in raspi-config's Lo
 24 Feb 22, 2022
24 Feb 22, 2022

Y. Zhang, Q. Yao, W. Dai, L. Chen. AutoSF: Searching Scoring Functions for Knowledge Graph Embedding. IEEE International Conference on Data Engineering (ICDE). 2020
AutoSF The code for our paper "AutoSF: Searching Scoring Functions for Knowledge Graph Embedding" and this paper has been accepted by ICDE2020. News:
 64 Dec 17, 2022
64 Dec 17, 2022
Focus on Algorithm Design, Not on Data Wrangling
The dataTap Python library is the primary interface for using dataTap's rich data management tools. Create datasets, stream annotations, and analyze model performance all with one library.
 37 Nov 25, 2022
37 Nov 25, 2022
The repo contains the code of the ACL2020 paper `Dice Loss for Data-imbalanced NLP Tasks`
Dice Loss for NLP Tasks This repository contains code for Dice Loss for Data-imbalanced NLP Tasks at ACL2020. Setup Install Package Dependencies The c
 223 Dec 17, 2022
223 Dec 17, 2022
skweak: A software toolkit for weak supervision applied to NLP tasks
Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
 850 Dec 28, 2022
850 Dec 28, 2022
Draw datasets from within Jupyter.
drawdata This small python app allows you to draw a dataset in a jupyter notebook. This should be very useful when teaching machine learning algorithm
 505 Nov 27, 2022
505 Nov 27, 2022

Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow.
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift
 214 Jan 2, 2023
214 Jan 2, 2023
![[Preprint] Escaping the Big Data Paradigm with Compact Transformers, 2021](https://github.com/SHI-Labs/Compact-Transformers/raw/main/images/model_sym.png)
[Preprint] Escaping the Big Data Paradigm with Compact Transformers, 2021
Compact Transformers Preprint Link: Escaping the Big Data Paradigm with Compact Transformers By Ali Hassani[1]*, Steven Walton[1]*, Nikhil Shah[1], Ab
 367 Dec 31, 2022
367 Dec 31, 2022
Simple, light-weight config handling through python data classes with to/from JSON serialization/deserialization.
Simple but maybe too simple config management through python data classes. We use it for machine learning.
 67 Nov 29, 2022
67 Nov 29, 2022
PyTorch implementation of neural style randomization for data augmentation
README Augment training images for deep neural networks by randomizing their visual style, as described in our paper: https://arxiv.org/abs/1809.05375
 84 Nov 23, 2022
84 Nov 23, 2022

Diffgram - Supervised Learning Data Platform
Data Annotation, Data Labeling, Annotation Tooling, Training Data for Machine Learning
 1.6k Jan 7, 2023
1.6k Jan 7, 2023
addon for blender to import mocap data from tools like easymocap, frankmocap and Vibe
b3d_mocap_import addon for blender to import mocap data from tools like easymocap, frankmocap and Vibe ==================VIBE================== To use
 97 Dec 7, 2022
97 Dec 7, 2022

The Django Leaflet Admin List package provides an admin list view featured by the map and bounding box filter for the geo-based data of the GeoDjango.
The Django Leaflet Admin List package provides an admin list view featured by the map and bounding box filter for the geo-based data of the GeoDjango. It requires a django-leaflet package.
 33 Nov 11, 2022
33 Nov 11, 2022

📼Command line tool based on youtube-dl to easily download selected channels from your subscriptions.
youtube-cdl Command line tool based on youtube-dl to easily download selected channels from your subscriptions. This tool is very handy if you want to
 64 Dec 25, 2022
64 Dec 25, 2022
Policy and data administration, distribution, and real-time updates on top of Open Policy Agent
⚡ OPAL ⚡ Open Policy Administration Layer OPAL is an administration layer for Open Policy Agent (OPA), detecting changes to both policy and policy dat
 8 Dec 7, 2022
8 Dec 7, 2022

Visualize classified time series data with interactive Sankey plots in Google Earth Engine
sankee Visualize changes in classified time series data with interactive Sankey plots in Google Earth Engine Contents Description Installation Using P
 76 Dec 15, 2022
76 Dec 15, 2022
Code related to "Have Your Text and Use It Too! End-to-End Neural Data-to-Text Generation with Semantic Fidelity" paper
DataTuner You have just found the DataTuner. This repository provides tools for fine-tuning language models for a task. See LICENSE.txt for license de
 81 Jan 1, 2023
81 Jan 1, 2023

Inspect the resources of your android projects and understand which ones are not being used and could potentially be removed.
Android Resources Checker What This program will inspect the resources of your app and help you understand which ones are not being used and could pot
 39 Feb 8, 2022
39 Feb 8, 2022

PyTorch3D is FAIR's library of reusable components for deep learning with 3D data
Introduction PyTorch3D provides efficient, reusable components for 3D Computer Vision research with PyTorch. Key features include: Data structure for
 6.8k Jan 1, 2023
6.8k Jan 1, 2023
A Pythonic introduction to methods for scaling your data science and machine learning work to larger datasets and larger models, using the tools and APIs you know and love from the PyData stack (such as numpy, pandas, and scikit-learn).
This tutorial's purpose is to introduce Pythonistas to methods for scaling their data science and machine learning work to larger datasets and larger models, using the tools and APIs they know and love from the PyData stack (such as numpy, pandas, and scikit-learn).
 102 Nov 10, 2022
102 Nov 10, 2022

DABO: Data Augmentation with Bilevel Optimization
DABO: Data Augmentation with Bilevel Optimization [Paper] The goal is to automatically learn an efficient data augmentation regime for image classific
 24 Aug 12, 2022
24 Aug 12, 2022

Wetterdienst - Open weather data for humans
We are a group of like-minded people trying to make access to weather data in Python feel like a warm summer breeze, similar to other projects like rdwd for the R language, which originally drew our interest in this project.
 226 Jan 4, 2023
226 Jan 4, 2023

Data Visualization Guide for Presentations, Reports, and Dashboards
This is a highly practical and example-based guide on visually representing data in reports and dashboards.
 395 Dec 29, 2022
395 Dec 29, 2022
PClean: A Domain-Specific Probabilistic Programming Language for Bayesian Data Cleaning
PClean: A Domain-Specific Probabilistic Programming Language for Bayesian Data Cleaning Warning: This is a rapidly evolving research prototype.
 190 Dec 27, 2022
190 Dec 27, 2022
A resource for learning about deep learning techniques from regression to LSTM and Reinforcement Learning using financial data and the fitness functions of algorithmic trading
A tour through tensorflow with financial data I present several models ranging in complexity from simple regression to LSTM and policy networks. The s
 195 Dec 7, 2022
195 Dec 7, 2022

Algorithmic trading using machine learning.
Algorithmic Trading This machine learning algorithm was built using Python 3 and scikit-learn with a Decision Tree Classifier. The program gathers sto
 101 Nov 10, 2022
101 Nov 10, 2022
Introducing neural networks to predict stock prices
IntroNeuralNetworks in Python: A Template Project IntroNeuralNetworks is a project that introduces neural networks and illustrates an example of how o
 637 Jan 4, 2023
637 Jan 4, 2023

Providing the solutions for high-frequency trading (HFT) strategies using data science approaches (Machine Learning) on Full Orderbook Tick Data.
Modeling High-Frequency Limit Order Book Dynamics Using Machine Learning Framework to capture the dynamics of high-frequency limit order books. Overvi
 1.3k Jan 7, 2023
1.3k Jan 7, 2023
Using python and scikit-learn to make stock predictions
MachineLearningStocks in python: a starter project and guide EDIT as of Feb 2021: MachineLearningStocks is no longer actively maintained MachineLearni
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
Python Data. Leaflet.js Maps.
folium Python Data, Leaflet.js Maps folium builds on the data wrangling strengths of the Python ecosystem and the mapping strengths of the Leaflet.js
 6k Jan 2, 2023
6k Jan 2, 2023
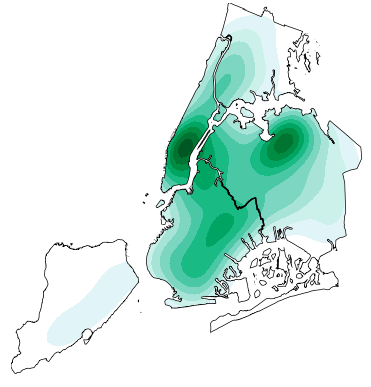
High-level geospatial data visualization library for Python.
geoplot: geospatial data visualization geoplot is a high-level Python geospatial plotting library. It's an extension to cartopy and matplotlib which m
 1k Jan 1, 2023
1k Jan 1, 2023
Satellite imagery for dummies.
felicette Satellite imagery for dummies. What can you do with this tool? TL;DR: Generate JPEG earth imagery from coordinates/location name with public
 1.8k Jan 3, 2023
1.8k Jan 3, 2023
Blender addons to make the bridge between Blender and geographic data
Blender GIS Blender minimal version : 2.8 Mac users warning : currently the addon does not work on Mac with Blender 2.80 to 2.82. Please do not report
 5.9k Jan 2, 2023
5.9k Jan 2, 2023
Implementation of Trajectory classes and functions built on top of GeoPandas
MovingPandas MovingPandas implements a Trajectory class and corresponding methods based on GeoPandas. Visit movingpandas.org for details! You can run
 897 Jan 1, 2023
897 Jan 1, 2023
A Python package for delineating nested surface depressions from digital elevation data.
Welcome to the lidar package lidar is Python package for delineating the nested hierarchy of surface depressions in digital elevation models (DEMs). I
 166 Jan 3, 2023
166 Jan 3, 2023
A toolbox for processing earth observation data with Python.
eo-box eobox is a Python package with a small collection of tools for working with Remote Sensing / Earth Observation data. Package Overview So far, t
 13 Jan 6, 2022
13 Jan 6, 2022
framework for large-scale SAR satellite data processing
pyroSAR A Python Framework for Large-Scale SAR Satellite Data Processing The pyroSAR package aims at providing a complete solution for the scalable or
 389 Dec 21, 2022
389 Dec 21, 2022

Automated download of LANDSAT data from USGS website
LANDSAT-Download It seems USGS has changed the structure of its data, and so far, I have not been able to find the direct links to the products? Help
 197 Dec 30, 2022
197 Dec 30, 2022
gpdvega is a bridge between GeoPandas and Altair that allows to seamlessly chart geospatial data
gpdvega gpdvega is a bridge between GeoPandas a geospatial extension of Pandas and the declarative statistical visualization library Altair, which all
 49 Jul 25, 2022
49 Jul 25, 2022

Processing and interpolating spatial data with a twist of machine learning
Documentation | Documentation (dev version) | Contact | Part of the Fatiando a Terra project About Verde is a Python library for processing spatial da
 468 Dec 20, 2022
468 Dec 20, 2022
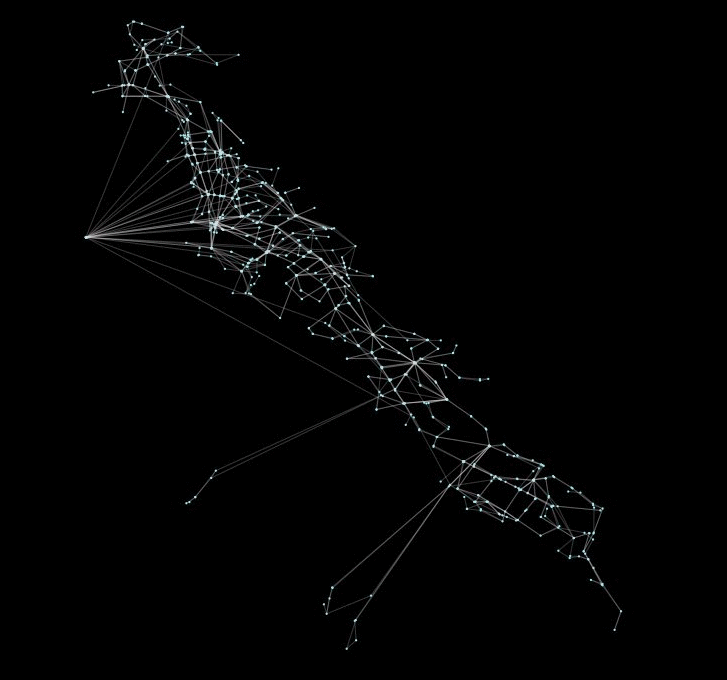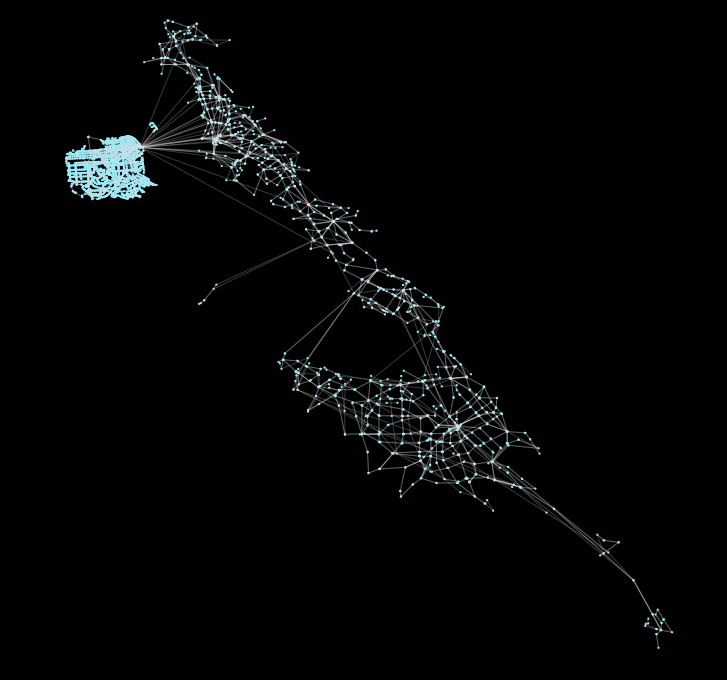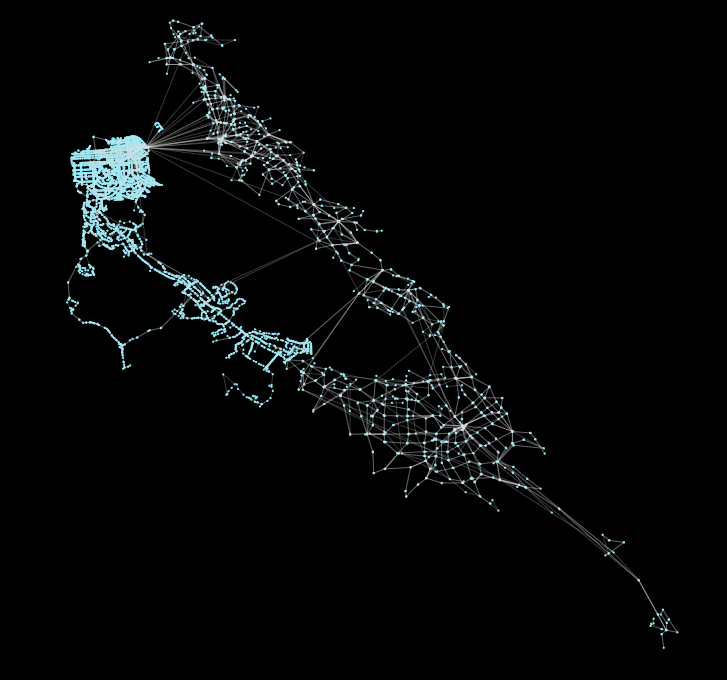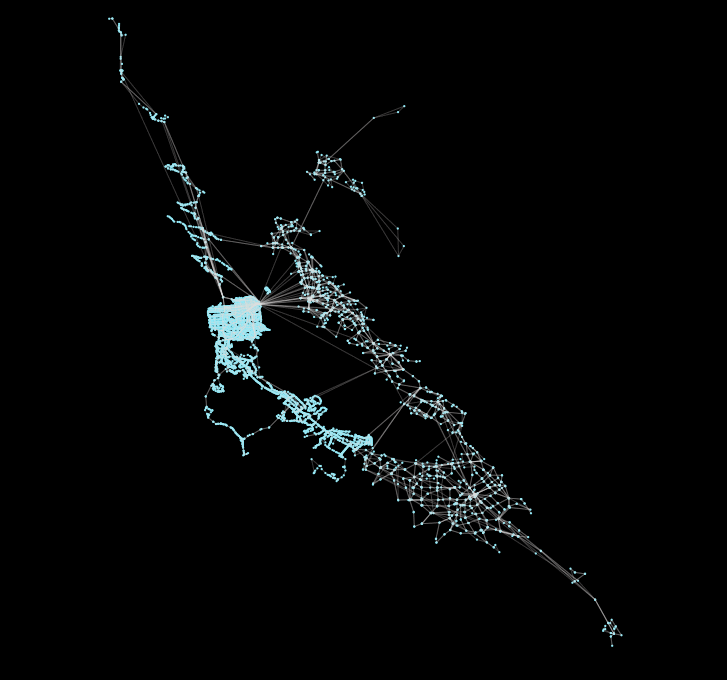
peartree: A library for converting transit data into a directed graph for sketch network analysis.
peartree 🍐 🌳 peartree is a library for converting GTFS feed schedules into a representative directed network graph. The tool uses Partridge to conve
 183 Dec 29, 2022
183 Dec 29, 2022
Tools for the extraction of OpenStreetMap street network data
OSMnet Tools for the extraction of OpenStreetMap (OSM) street network data. Intended to be used in tandem with Pandana and UrbanAccess libraries to ex
 47 Sep 21, 2022
47 Sep 21, 2022
Open GeoJSON data on geojson.io
geojsonio.py Open GeoJSON data on geojson.io from Python. geojsonio.py also contains a command line utility that is a Python port of geojsonio-cli. Us
 114 Dec 21, 2022
114 Dec 21, 2022
Tool to suck data from ArcGIS Server and spit it into PostgreSQL
chupaESRI About ChupaESRI is a Python module/command line tool to extract features from ArcGIS Server map services. Name? Think "chupacabra" or "Chupa
 34 Dec 4, 2022
34 Dec 4, 2022
OSMnx: Python for street networks. Retrieve, model, analyze, and visualize street networks and other spatial data from OpenStreetMap.
OSMnx OSMnx is a Python package that lets you download geospatial data from OpenStreetMap and model, project, visualize, and analyze real-world street
 4k Jan 8, 2023
4k Jan 8, 2023

Apache Superset is a Data Visualization and Data Exploration Platform
Apache Superset is a Data Visualization and Data Exploration Platform
 49.9k Jan 2, 2023
49.9k Jan 2, 2023
Distribution Analyser is a Web App that allows you to interactively explore continuous distributions from SciPy and fit distribution(s) to your data.
Distribution Analyser Distribution Analyser is a Web App that allows you to interactively explore continuous distributions from SciPy and fit distribu
 46 Nov 8, 2022
46 Nov 8, 2022
Hands-on machine learning workshop
emb-ntua-workshop This workshop discusses introductory concepts of machine learning and data mining following a hands-on approach using popular tools
 12 Oct 30, 2022
12 Oct 30, 2022
原神抽卡记录数据集-Genshin Impact gacha data
提要 持续收集原神抽卡记录中 可以使用抽卡记录导出工具导出抽卡记录的json,将json文件发送至[email protected],我会在清除个人信息后将文件提交到此处。以下两种导出工具任选其一即可。 一种抽卡记录导出工具 from sunfkny 使用方法演示视频 另一种electron版的抽
 117 Dec 27, 2022
117 Dec 27, 2022
The source code for the Cutoff data augmentation approach proposed in this paper: "A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation".
Cutoff: A Simple Data Augmentation Approach for Natural Language This repository contains source code necessary to reproduce the results presented in
 49 Dec 22, 2022
49 Dec 22, 2022
Code, Data and Demo for Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting
InversePrompting Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting Code: The code is provided in the "chinese_ip"
 101 Dec 16, 2022
101 Dec 16, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022

An open-source library of algorithms to analyse time series in GPU and CPU.
An open-source library of algorithms to analyse time series in GPU and CPU.
 216 Dec 30, 2022
216 Dec 30, 2022

Regularizing Generative Adversarial Networks under Limited Data (CVPR 2021)
Regularizing Generative Adversarial Networks under Limited Data [Project Page][Paper] Implementation for our GAN regularization method. The proposed r
 148 Nov 18, 2022
148 Nov 18, 2022
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
 42 Dec 13, 2022
42 Dec 13, 2022

Ingest openldap data into bloodhound
Bloodhound for Linux Ingest a dumped OpenLDAP ldif into neo4j to be visualized in Bloodhound. Usage: ./ldif_to_neo4j.py ./sample.ldif | cypher-shell -
 71 Nov 9, 2022
71 Nov 9, 2022
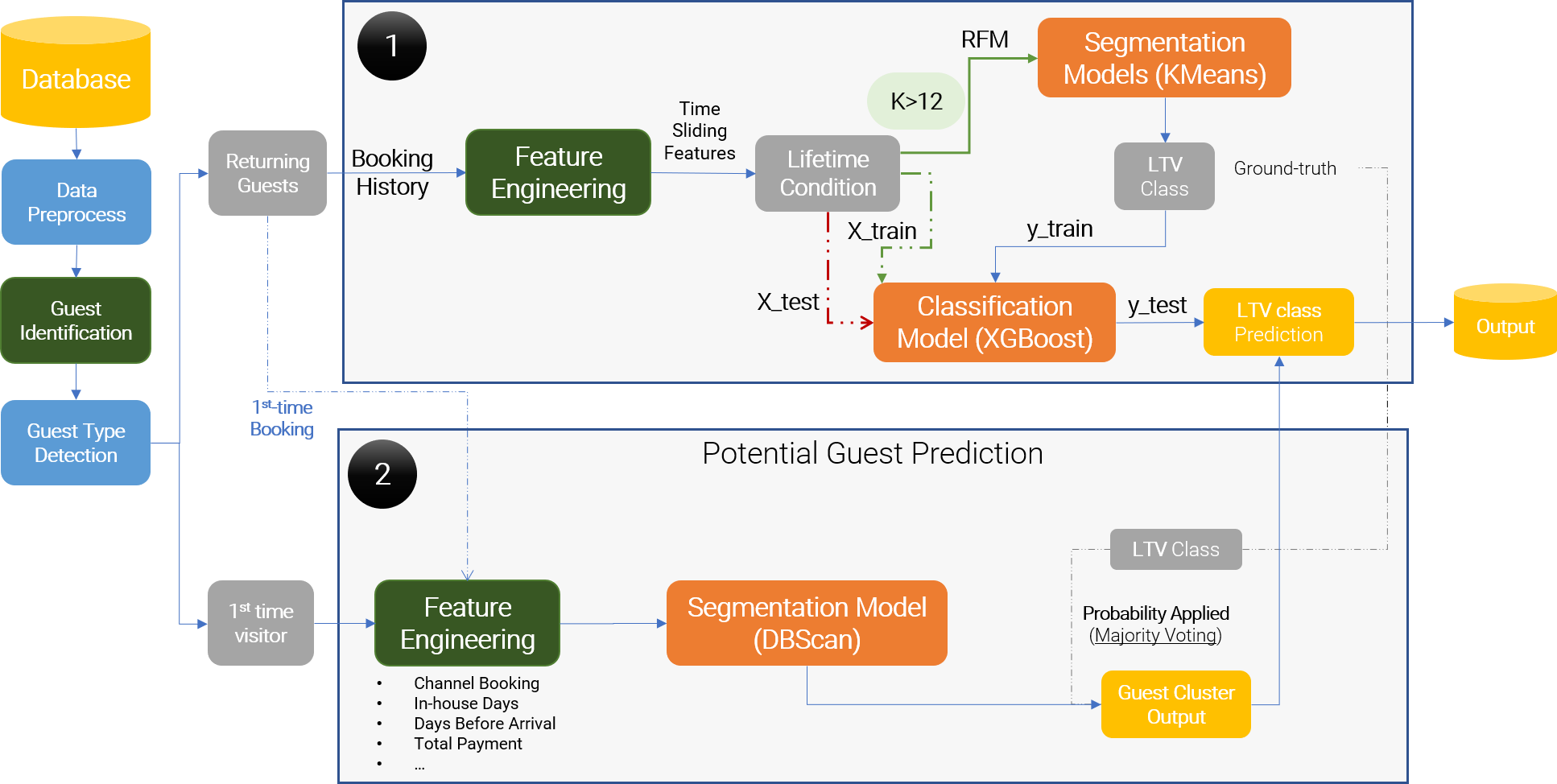
Using Hotel Data to predict High Value And Potential VIP Guests
Description Using hotel data and AI to predict high value guests and potential VIP guests. Hotel can leverage on prediction resutls to run more effect
 12 Feb 14, 2022
12 Feb 14, 2022
Flenser is a simple, minimal, automated exploratory data analysis tool.
Flenser Have you ever been handed a dataset you've never seen before? Flenser is a simple, minimal, automated exploratory data analysis tool. It runs
 79 Sep 20, 2022
79 Sep 20, 2022

Data Orchestration Platform
Table of contents What is DOP Design Concept A Typical DOP Orchestration Flow Prerequisites - Run in Docker For DOP Native Features For DBT Instructio
 61 Mar 4, 2022
61 Mar 4, 2022
Duckiter will Automatically dockerize your Django projects.
Duckiter Duckiter will Automatically dockerize your Django projects. Requirements : - python version : python version 3.6 or upper version - OS :
 23 Sep 16, 2021
23 Sep 16, 2021
The most widely used Python to C compiler
Welcome to Cython! Cython is a language that makes writing C extensions for Python as easy as Python itself. Cython is based on Pyrex, but supports mo
 7.6k Jan 3, 2023
7.6k Jan 3, 2023
IPython: Productive Interactive Computing
IPython: Productive Interactive Computing Overview Welcome to IPython. Our full documentation is available on ipython.readthedocs.io and contains info
 15.6k Dec 31, 2022
15.6k Dec 31, 2022
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 6k Jan 4, 2023
6k Jan 4, 2023

Viewflow is an Airflow-based framework that allows data scientists to create data models without writing Airflow code.
Viewflow Viewflow is a framework built on the top of Airflow that enables data scientists to create materialized views. It allows data scientists to f
 114 Oct 12, 2022
114 Oct 12, 2022

An attempt at the implementation of GLOM, Geoffrey Hinton's paper for emergent part-whole hierarchies from data
GLOM TensorFlow This Python package attempts to implement GLOM in TensorFlow, which allows advances made by several different groups transformers, neu
 32 Feb 21, 2022
32 Feb 21, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
A probabilistic programming language in TensorFlow. Deep generative models, variational inference.
Edward is a Python library for probabilistic modeling, inference, and criticism. It is a testbed for fast experimentation and research with probabilis
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
Probabilistic reasoning and statistical analysis in TensorFlow
TensorFlow Probability TensorFlow Probability is a library for probabilistic reasoning and statistical analysis in TensorFlow. As part of the TensorFl
 3.8k Jan 5, 2023
3.8k Jan 5, 2023
Data Analysis Baseline Library
dabl The data analysis baseline library. "Mr Sanchez, are you a data scientist?" "I dabl, Mr president." Find more information on the website. State o
 122 Dec 27, 2022
122 Dec 27, 2022
Topological Data Analysis for Python🐍
Scikit-TDA is a home for Topological Data Analysis Python libraries intended for non-topologists. This project aims to provide a curated library of TD
 373 Dec 24, 2022
373 Dec 24, 2022
scikit-learn cross validators for iterative stratification of multilabel data
iterative-stratification iterative-stratification is a project that provides scikit-learn compatible cross validators with stratification for multilab
 745 Jan 5, 2023
745 Jan 5, 2023
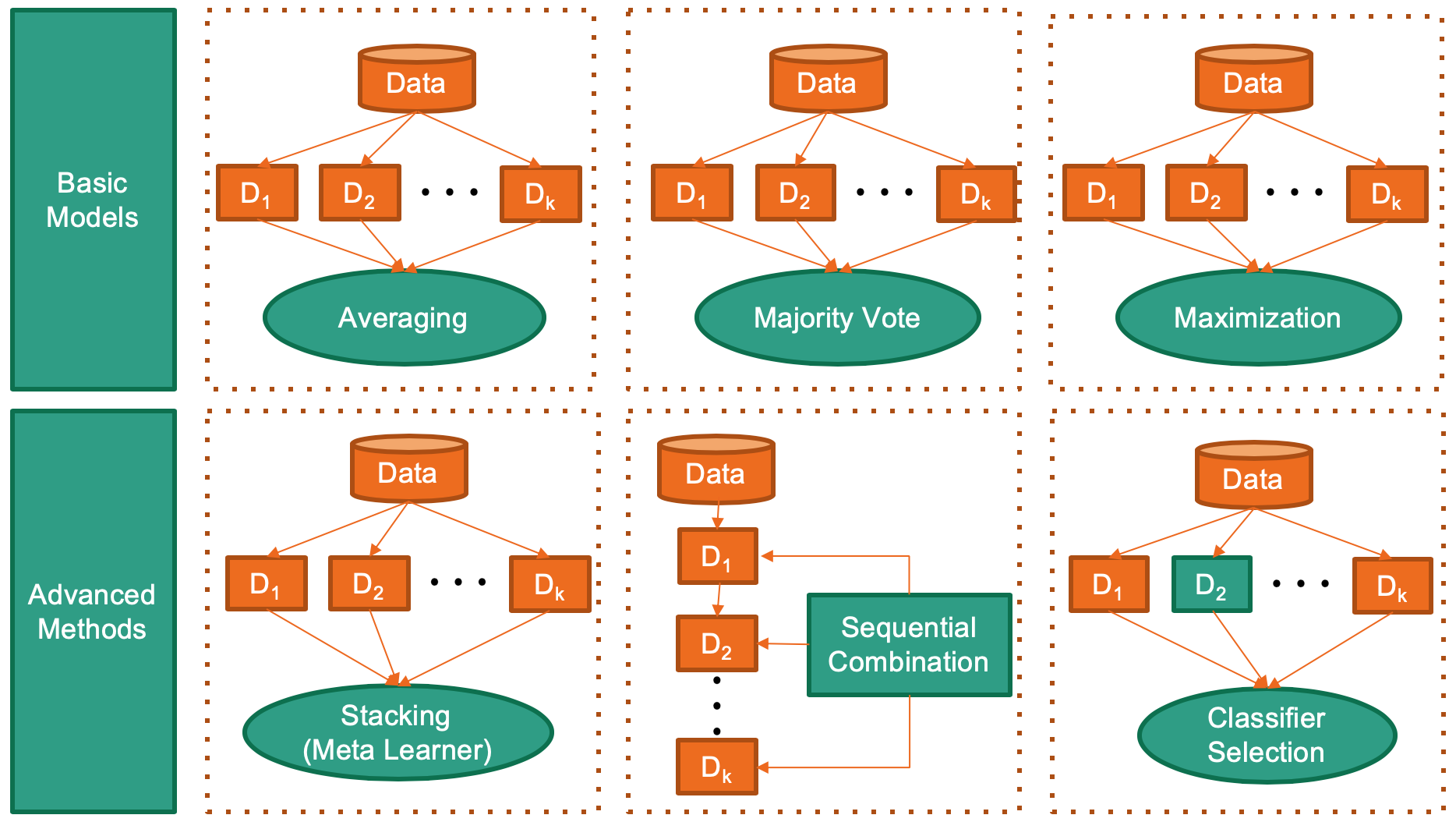
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
 4.2k Dec 28, 2022
4.2k Dec 28, 2022
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
 6.2k Jan 1, 2023
6.2k Jan 1, 2023

A simplified framework and utilities for PyTorch
Here is Poutyne. Poutyne is a simplified framework for PyTorch and handles much of the boilerplating code needed to train neural networks. Use Poutyne
 534 Dec 17, 2022
534 Dec 17, 2022
Tez is a super-simple and lightweight Trainer for PyTorch. It also comes with many utils that you can use to tackle over 90% of deep learning projects in PyTorch.
Tez: a simple pytorch trainer NOTE: Currently, we are not accepting any pull requests! All PRs will be closed. If you want a feature or something does
 1.1k Jan 4, 2023
1.1k Jan 4, 2023
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
README TabNet : Attentive Interpretable Tabular Learning This is a pyTorch implementation of Tabnet (Arik, S. O., & Pfister, T. (2019). TabNet: Attent
 2k Dec 27, 2022
2k Dec 27, 2022
A collection of extensions and data-loaders for few-shot learning & meta-learning in PyTorch
Torchmeta A collection of extensions and data-loaders for few-shot learning & meta-learning in PyTorch. Torchmeta contains popular meta-learning bench
 1.7k Jan 6, 2023
1.7k Jan 6, 2023
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022

General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and optimized for advanced GPU data processing usecases.
Vulkan Kompute The general purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabl
 1k Dec 26, 2022
1k Dec 26, 2022
BlazingSQL is a lightweight, GPU accelerated, SQL engine for Python. Built on RAPIDS cuDF.
A lightweight, GPU accelerated, SQL engine built on the RAPIDS.ai ecosystem. Get Started on app.blazingsql.com Getting Started | Documentation | Examp
 1.8k Jan 2, 2023
1.8k Jan 2, 2023

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
 4.2k Jan 8, 2023
4.2k Jan 8, 2023

Distributed scikit-learn meta-estimators in PySpark
sk-dist: Distributed scikit-learn meta-estimators in PySpark What is it? sk-dist is a Python package for machine learning built on top of scikit-learn
 282 Dec 9, 2022
282 Dec 9, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective. 10x Larger Models 10x Faster Trainin
 8.4k Dec 30, 2022
8.4k Dec 30, 2022
BigDL: Distributed Deep Learning Framework for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can w
 4.1k Jan 9, 2023
4.1k Jan 9, 2023
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
 23.3k Dec 31, 2022
23.3k Dec 31, 2022
Automatically build ARIMA, SARIMAX, VAR, FB Prophet and XGBoost Models on Time Series data sets with a Single Line of Code. Now updated with Dask to handle millions of rows.
Auto_TS: Auto_TimeSeries Automatically build multiple Time Series models using a Single Line of Code. Now updated with Dask. Auto_timeseries is a comp
 519 Jan 3, 2023
519 Jan 3, 2023

A Python library for detecting patterns and anomalies in massive datasets using the Matrix Profile
matrixprofile-ts matrixprofile-ts is a Python 2 and 3 library for evaluating time series data using the Matrix Profile algorithms developed by the Keo
 696 Dec 26, 2022
696 Dec 26, 2022
Python module for machine learning time series:
seglearn Seglearn is a python package for machine learning time series or sequences. It provides an integrated pipeline for segmentation, feature extr
 536 Dec 29, 2022
536 Dec 29, 2022
STUMPY is a powerful and scalable Python library for computing a Matrix Profile, which can be used for a variety of time series data mining tasks
STUMPY STUMPY is a powerful and scalable library that efficiently computes something called the matrix profile, which can be used for a variety of tim
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
Real-time stream processing for python
Streamz Streamz helps you build pipelines to manage continuous streams of data. It is simple to use in simple cases, but also supports complex pipelin
 1.1k Dec 28, 2022
1.1k Dec 28, 2022
A machine learning toolkit dedicated to time-series data
tslearn The machine learning toolkit for time series analysis in Python Section Description Installation Installing the dependencies and tslearn Getti
 2.3k Dec 29, 2022
2.3k Dec 29, 2022
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
 6k Jan 6, 2023
6k Jan 6, 2023

Automatic extraction of relevant features from time series:
tsfresh This repository contains the TSFRESH python package. The abbreviation stands for "Time Series Feature extraction based on scalable hypothesis
 7k Jan 6, 2023
7k Jan 6, 2023
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment. With Qlib, you can easily try your ideas to create better Quant investment strategies.
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technol
10.1k Dec 31, 2022