633 Repositories
Python deca-usb2-audio-interface Libraries
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
 323 Jan 1, 2023
323 Jan 1, 2023
Natural language computational chemistry command line interface.
nlcc Install pip install nlcc Must have Open-AI Codex key: export OPENAI_API_KEY=your key here then nlcc key bindings ctrl-w copy to clipboard (Note
 37 Dec 14, 2022
37 Dec 14, 2022
flora-dev-cli (fd-cli) is command line interface software to interact with flora blockchain.
Install git clone https://github.com/Flora-Network/fd-cli.git cd fd-cli python3 -m venv venv source venv/bin/activate pip install -e . --extra-index-u
 14 Sep 11, 2022
14 Sep 11, 2022

Microsoft Azure CLI - Azure Command-Line Interface
A great cloud needs great tools; we're excited to introduce Azure CLI, our next generation multi-platform command line experience for Azure.
 3.4k Dec 30, 2022
3.4k Dec 30, 2022

Web interface for browsing arXiv papers
Currently, arxivbox considers only major computer vision and machine learning conferences
 12 Sep 11, 2022
12 Sep 11, 2022
All Tools In One is a Script Developed with Python3. It gathers a total of 14 Discord tools (including a RAT, a Raid Tool, a Token Grabber, a Crash Video Maker, etc). It has a pleasant and intuitive interface to facilitate the use of all with help and explanations for each of them.
[Discord] - All Tools In One [Discord] - All Tools In One is a Script Gathering for Windows systems written in Python. Disclaimer This project was cre
 484 Jan 1, 2023
484 Jan 1, 2023
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022

personal finance tracker, written in python 3 and using the wxPython GUI toolkit.
personal finance tracker, written in python 3 and using the wxPython GUI toolkit.
 23 Oct 30, 2022
23 Oct 30, 2022
A tool to fuck a video/audio quality using FFmpeg
Media quality fucker A tool to fuck a video/audio quality using FFmpeg How to use Download the source Download Python Extract FFmpeg Put what you want
 8 Jan 25, 2022
8 Jan 25, 2022

Browser - A GTK browser trying to follow the GNOME Human Interface Guidelines.
A simple GTK browser trying to follow the GNOME Human Interface Guidelines.
 12 Nov 26, 2022
12 Nov 26, 2022
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023
Dockernized ZeroTierOne controller with zero-ui web interface.
docker-zerotier-controller Dockernized ZeroTierOne controller with zero-ui web interface. 中文讨论 Customize ZeroTierOne's controller planets Modify patch
 209 Jan 4, 2023
209 Jan 4, 2023
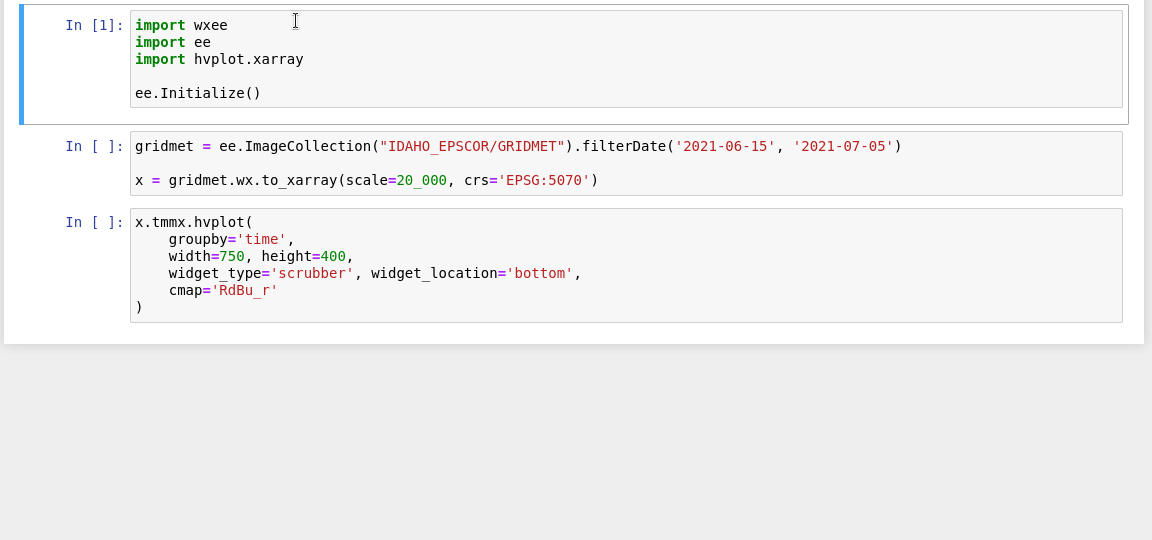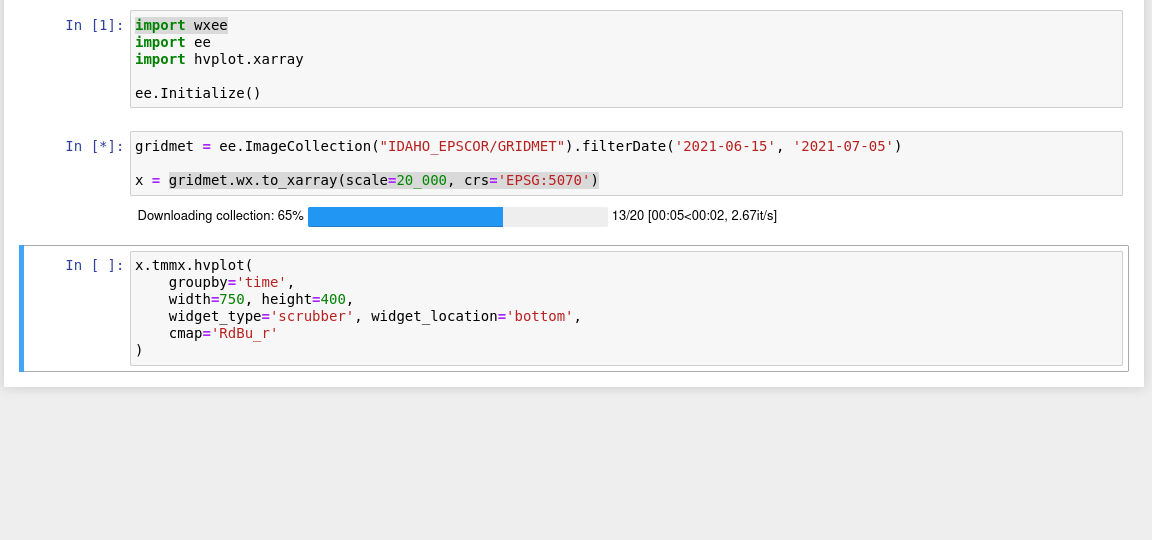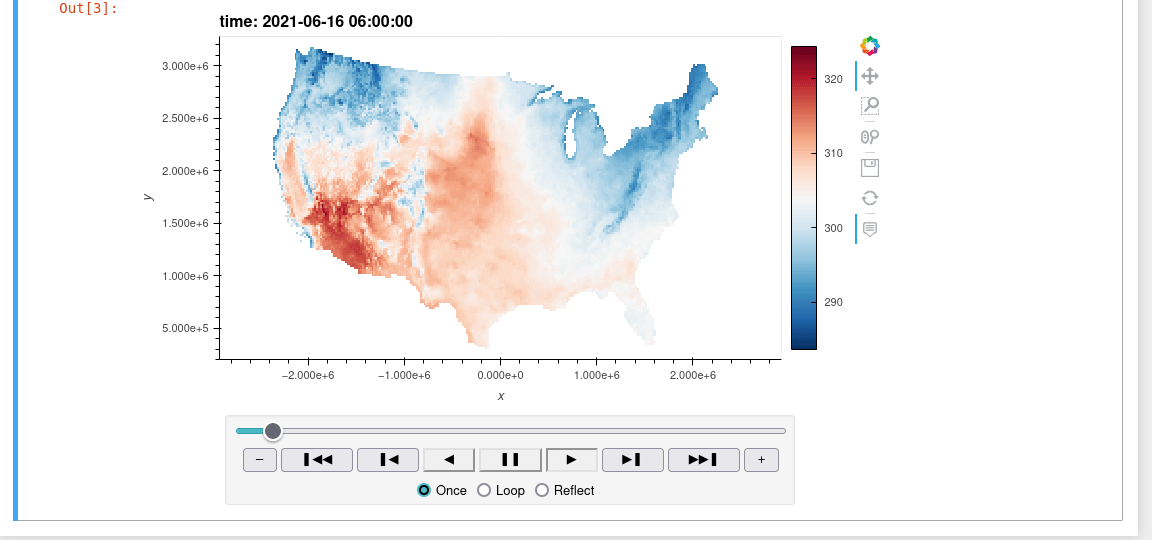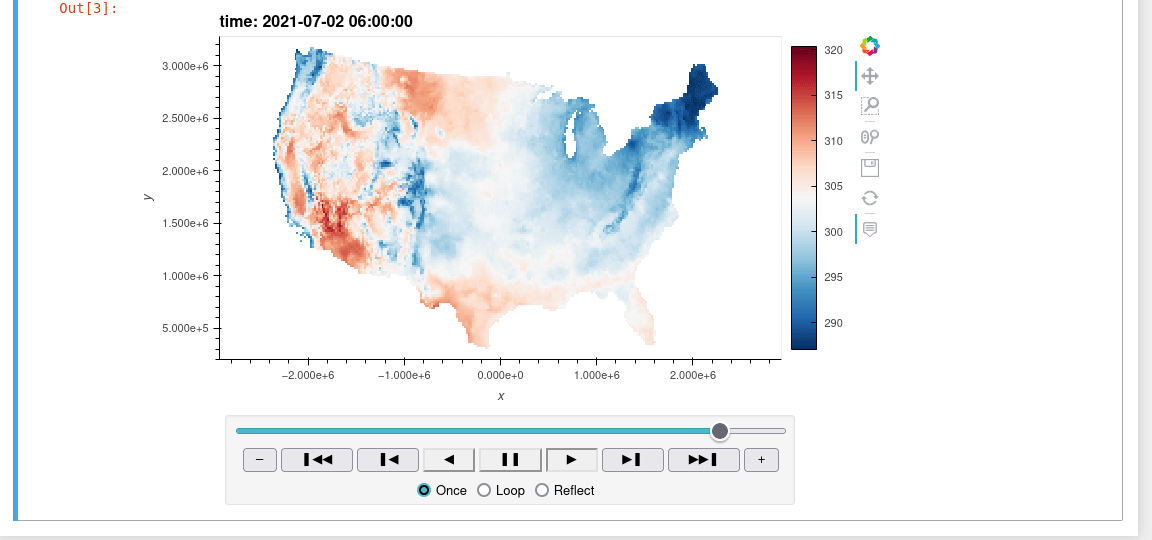
A Python interface between Earth Engine and xarray for processing weather and climate data
wxee What is wxee? wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data ca
 160 Dec 31, 2022
160 Dec 31, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
praudio provides audio preprocessing framework for Deep Learning audio applications
praudio provides objects and a script for performing complex preprocessing operations on entire audio datasets with one command.
 105 Dec 26, 2022
105 Dec 26, 2022
The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution.
WSRGlow The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution. Audio sa
 96 Jan 3, 2023
96 Jan 3, 2023
pywinauto is a set of python modules to automate the Microsoft Windows GUI
pywinauto is a set of python modules to automate the Microsoft Windows GUI. At its simplest it allows you to send mouse and keyboard actions to windows dialogs and controls, but it has support for more complex actions like getting text data.
 3.8k Jan 6, 2023
3.8k Jan 6, 2023
PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
samplernn-pytorch A PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. It's based on the reference implem
 261 Dec 14, 2022
261 Dec 14, 2022

Simple torch.nn.module implementation of Alias-Free-GAN style filter and resample
Alias-Free-Torch Simple torch module implementation of Alias-Free GAN. This repository including Alias-Free GAN style lowpass sinc filter @filter.py A
 64 Dec 22, 2022
64 Dec 22, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
 15 Dec 22, 2022
15 Dec 22, 2022
FPGA based USB 2.0 high speed audio interface featuring multiple optical ADAT inputs and outputs
ADAT USB Audio Interface FPGA based USB 2.0 High Speed audio interface featuring multiple optical ADAT inputs and outputs Status / current limitations
 78 Dec 31, 2022
78 Dec 31, 2022

Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
 17.1k Jan 8, 2023
17.1k Jan 8, 2023
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021

Double Pendulum visualised with fetching system information in Python.
Show off your terminal, in style. A nice relaxing double pendulum simulation using ASCII, able to simulate multiple pendulums at once, and provide tra
 62 Dec 14, 2022
62 Dec 14, 2022
Double Pendulum implementation in Python, now with added pendulums and trails :D
Double Pendulum Using Curses in Python. A nice relaxing double pendulum simulation using ASCII, able to simulate multiple pendulums at once, and provi
62 Dec 14, 2022
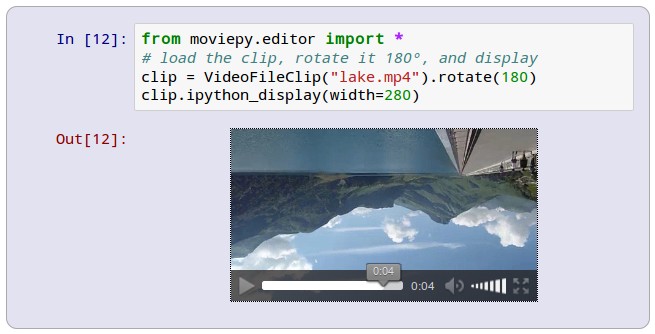
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023

A Python interface between Earth Engine and xarray
eexarray A Python interface between Earth Engine and xarray Description eexarray was built to make processing gridded, mesoscale time series data quic
159 Dec 23, 2022
A Telegram Bot to Play Audio in Voice Chats With Youtube and Deezer support. Supports Live streaming from youtube Supports Mega Radio Fm Streamings
Bot To Stream Musics on PyTGcalls with Channel Support. A Telegram Bot to Play Audio in Voice Chats With Supports Live streaming from youtube and Mega
 37 Dec 15, 2022
37 Dec 15, 2022

Code for the Interspeech 2021 paper "AST: Audio Spectrogram Transformer".
AST: Audio Spectrogram Transformer Introduction Citing Getting Started ESC-50 Recipe Speechcommands Recipe AudioSet Recipe Pretrained Models Contact I
 603 Jan 7, 2023
603 Jan 7, 2023

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022
Telegram Radio - A User-bot who continuously play random audio files (from the famous telegram music channel @mveargasm) in the intended voice chat.
MvEargasmDJ: This is my submission for the Telegram Radio Project of Baivaru. Which required a userbot to continiously play random audio files from th
 24 Nov 12, 2022
24 Nov 12, 2022

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling @ INTERSPEECH 2021 Accepted
NU-Wave — Official PyTorch Implementation NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling Junhyeok Lee, Seungu Han @ MINDsLab Inc
 242 Dec 23, 2022
242 Dec 23, 2022

Classify bird species based on their songs using SIamese Networks and 1D dilated convolutions.
The goal is to classify different birds species based on their songs/calls. Spectrograms have been extracted from the audio samples and used as features for classification.
9 Dec 27, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023
Flexible interface for high-performance research using SOTA Transformers leveraging Pytorch Lightning, Transformers, and Hydra.
Flexible interface for high performance research using SOTA Transformers leveraging Pytorch Lightning, Transformers, and Hydra. What is Lightning Tran
 581 Dec 21, 2022
581 Dec 21, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022

Here is my Senior Design Project that I implemented to graduate from Computer Engineering.
Here is my Senior Design Project that I implemented to graduate from Computer Engineering. It is a chatbot made in RASA and helps the user to plan their vacation in the Turkish language. In order to plan the user's vacation, it provides reservations by asking various questions for hotel, flight, or event.
 25 May 31, 2022
25 May 31, 2022
command line interface to manage VALORANT skins
A PROPER RELEASE IS COMING SOON, IF YOU KNOW HOW TO USE PYTHON YOU CAN USE IT NOW! valorant skin manager command line interface simple command line in
 131 Dec 25, 2022
131 Dec 25, 2022

This repository contains a PyTorch implementation of "AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis".
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis | Project Page | Paper | PyTorch implementation for the paper "AD-NeRF: Audio
 551 Dec 29, 2022
551 Dec 29, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
 59 Dec 6, 2022
59 Dec 6, 2022

Uma interfáce de usuário relativamente simples em pyqt5 + escolha de dispositivos
Interface para Scrcpy Uma interfáce de usuário relativamente simples em pyqt5 para sistemas UNIX Requerimentos: Python3 PyQt5 adb scrcpy Você pode ins
 10 Dec 16, 2022
10 Dec 16, 2022
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023

WebVirtCloud is virtualization web interface for admins and users
WebVirtCloud is a virtualization web interface for admins and users. It can delegate Virtual Machine's to users. A noVNC viewer presents a full graphical console to the guest domain. KVM is currently the only hypervisor supported.
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
A pretty quick and simple interface to paramiko SFTP
A pretty quick and simple interface to paramiko SFTP. Provides multi-threaded routines with progress notifications for reliable, asynchronous transfers. This is a Python3 optimized fork of pysftp with additional features & improvements.
 14 Dec 21, 2022
14 Dec 21, 2022
A Youtube audio player for your terminal
AudioLine A lightweight Youtube audio player for your terminal Explore the docs » View Demo · Report Bug · Request Feature · Send a Pull Request About
 26 Jan 4, 2023
26 Jan 4, 2023
Audio augmentations library for PyTorch for audio in the time-domain
Audio augmentations library for PyTorch for audio in the time-domain, with support for stochastic data augmentations as used often in self-supervised / contrastive learning.
 166 Jan 8, 2023
166 Jan 8, 2023
poro is a LCU interface to change some lol's options.
poro is a LCU interface to change some lol's options. with this program you can: change your profile icon change your profiel background image ch
 2 Jan 5, 2022
2 Jan 5, 2022

Unofficial TensorFlow implementation of Protein Interface Prediction using Graph Convolutional Networks.
[TensorFlow] Protein Interface Prediction using Graph Convolutional Networks Unofficial TensorFlow implementation of Protein Interface Prediction usin
 9 Oct 25, 2022
9 Oct 25, 2022

Textual is a TUI (Text User Interface) framework for Python using Rich as a renderer.
Textual is a TUI (Text User Interface) framework for Python using Rich as a renderer. The end goal is to be able to rapidly create rich termin
17k Jan 2, 2023
 1000 Jun 3, 2021
1000 Jun 3, 2021

Rich.tui is a TUI (Text User Interface) framework for Python using Rich as a renderer.
rich.tui Rich.tui is a TUI (Text User Interface) framework for Python using Rich as a renderer. The end goal is to be able to rapidly create rich term
17.1k Jan 4, 2023
Python interface for the DIGIT tactile sensor
DIGIT-INTERFACE Python interface for the DIGIT tactile sensor. For updates and discussions please join the #DIGIT channel at the www.touch-sensing.org
35 Dec 22, 2022

A telegram bot that can send you high-quality audio 🎧🎧🎧
Music downloader bot Still under development Please Report issues to improve this repo.I will try to fix bugs in next update Music downloader bot is a
 36 Dec 6, 2022
36 Dec 6, 2022
An audio guide for destroying oracles in Destiny's Vault of Glass raid
prophet An audio guide for destroying oracles in Destiny's Vault of Glass raid. This project allows you to make any encounter with oracles without hav
 24 Sep 15, 2022
24 Sep 15, 2022

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling
NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling For Official repo of NU-Wave: A Diffusion Probabilistic Model for Neural Audio Up
38 Oct 11, 2022

Source code for "MusCaps: Generating Captions for Music Audio" (IJCNN 2021)
MusCaps: Generating Captions for Music Audio Ilaria Manco1 2, Emmanouil Benetos1, Elio Quinton2, Gyorgy Fazekas1 1 Queen Mary University of London, 2
 57 Dec 7, 2022
57 Dec 7, 2022

Tkinter Designer - Create Beautiful Tkinter GUIs by Drag and Drop.
Tkinter Designer is created to speed up and beautify Python GUI Experience. It uses well know design software called Figma. Which makes creating Tkinter GUI in Python a piece of cake.
 5.2k Jan 9, 2023
5.2k Jan 9, 2023
Audio processor to map oracle notes in the VoG raid in Destiny 2 to call outs.
vog_oracles Audio processor to map oracle notes in the VoG raid in Destiny 2 to call outs. Huge thanks to mzucker on GitHub for the note detection cod
 19 Sep 29, 2022
19 Sep 29, 2022
VMD Audio/Text control with natural language
This repository is a proof of principle for performing Molecular Dynamics analysis, in this case with the program VMD, via natural language commands.
13 Jun 9, 2022
企业微信消息推送的python封装接口,让你轻松用python实现对企业微信的消息推送
👋 corpwechat-bot是一个python封装的企业机器人&应用消息推送库,通过企业微信提供的api实现。 利用本库,你可以轻松地实现从服务器端发送一条文本、图片、视频、markdown等等消息到你的微信手机端,而不依赖于其他的第三方应用,如ServerChan。 如果喜欢该项目,记得给个
 161 Jan 6, 2023
161 Jan 6, 2023
Accompanying code for our paper "Point Cloud Audio Processing"
Point Cloud Audio Processing Krishna Subramani1, Paris Smaragdis1 1UIUC Paper For the necessary libraries/prerequisites, please use conda/anaconda to
 17 Nov 17, 2022
17 Nov 17, 2022
Donors data of Tamil Nadu Chief Ministers Relief Fund scrapped from https://ereceipt.tn.gov.in/cmprf/Interface/CMPRF/MonthWiseReport
Tamil Nadu Chief Minister's Relief Fund Donors Scrapped data from https://ereceipt.tn.gov.in/cmprf/Interface/CMPRF/MonthWiseReport Scrapper scrapper.p
 5 May 18, 2021
5 May 18, 2021
Python interface for SmartRF Sniffer 2 Firmware
#TI SmartRF Packet Sniffer 2 Python Interface TI Makes available a nice packet sniffer firmware, which interfaces to Wireshark. You can see this proje
 3 May 18, 2021
3 May 18, 2021
Python codes for Lite Audio-Visual Speech Enhancement.
Lite Audio-Visual Speech Enhancement (Interspeech 2020) Introduction This is the PyTorch implementation of Lite Audio-Visual Speech Enhancement (LAVSE
 85 Dec 1, 2022
85 Dec 1, 2022
Telegram bot + userbot for streaming audio in group calls.
Calls Music — Telegram bot + userbot for streaming audio in group calls ✍🏻 Requirements FFmpeg Python 3.7+ 🚀 Deployment 🛠 Configuration Copy exampl
 30 May 17, 2021
30 May 17, 2021
Hide Your Secret Message in any Wave Audio File.
HiddenWave Embedding secret messages in wave audio file What is HiddenWave Hiddenwave is a python based program for simple audio steganography. You ca
 99 Dec 28, 2022
99 Dec 28, 2022

Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and convert them into audio. Here I have used Google-text-to-speech library popularly known as gTTS library to convert text file to .mp3 file. Hope you like my project!
Text to speech (using Python) Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and co
 19 Jun 30, 2022
19 Jun 30, 2022
Python3 Interface to numa Linux library
py-libnuma is python3 interface to numa Linux library so that you can set task affinity and memory affinity in python level for your process which can help you to improve your code's performence.
 13 Nov 10, 2022
13 Nov 10, 2022

Code for paper 'Audio-Driven Emotional Video Portraits'.
Audio-Driven Emotional Video Portraits [CVPR2021] Xinya Ji, Zhou Hang, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, Feng Xu [Project] [Paper] G
 197 Dec 31, 2022
197 Dec 31, 2022

The project help you to quickly build layouts in terminal,cross-platform
The project help you to quickly build layouts in terminal,cross-platform
 133 Nov 30, 2022
133 Nov 30, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition
 111 Jan 7, 2023
111 Jan 7, 2023

dualFace: Two-Stage Drawing Guidance for Freehand Portrait Sketching (CVMJ)
dualFace dualFace: Two-Stage Drawing Guidance for Freehand Portrait Sketching (CVMJ) We provide python implementations for our CVM 2021 paper "dualFac
 46 Nov 10, 2022
46 Nov 10, 2022
Word2Wave: a framework for generating short audio samples from a text prompt using WaveGAN and COALA.
Word2Wave is a simple method for text-controlled GAN audio generation. You can either follow the setup instructions below and use the source code and CLI provided in this repo or you can have a play around in the Colab notebook provided. Note that, in both cases, you will need to train a WaveGAN model first
91 Dec 23, 2022

Euporie is a text-based user interface for running and editing Jupyter notebooks
Euporie is a text-based user interface for running and editing Jupyter notebooks
 781 Jan 1, 2023
781 Jan 1, 2023

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
881 Jan 3, 2023
Data manipulation and transformation for audio signal processing, powered by PyTorch
torchaudio: an audio library for PyTorch The aim of torchaudio is to apply PyTorch to the audio domain. By supporting PyTorch, torchaudio follows the
 1.9k Jan 8, 2023
1.9k Jan 8, 2023

A version of nrsc5-gui that merges the interface developed by cmnybo with the architecture developed by zefie in order to start a new baseline that is not heavily dependent upon Python processing.
NRSC5-DUI is a graphical interface for nrsc5. It makes it easy to play your favorite FM HD radio stations using an RTL-SDR dongle. It will also displa
 61 Dec 22, 2022
61 Dec 22, 2022

Aggrokatz is an aggressor plugin extension for Cobalt Strike which enables pypykatz to interface with the beacons remotely and allows it to parse LSASS dump files and registry hive files to extract credentials and other secrets stored without downloading the file and without uploading any suspicious code to the beacon.
aggrokatz What is this aggrokatz is an Aggressor plugin extension for CobaltStrike which enables pypykatz to interface with the beacons remotely. The
 148 Dec 9, 2022
148 Dec 9, 2022
Universal Command Line Interface for Amazon Web Services
This package provides a unified command line interface to Amazon Web Services.
 13.3k Jan 7, 2023
13.3k Jan 7, 2023
Contrastive Language-Audio Pretraining
CLAP Contrastive Language-Audio Pretraining In due time this repo will be full of lovely things, I hope. Feel free to check out the Issues if you're i
 83 Dec 1, 2022
83 Dec 1, 2022

BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation
BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation This is a demo implementation of BYOL for Audio (BYOL-A), a self-sup
 160 Jan 4, 2023
160 Jan 4, 2023

Code for Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021)
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021) Hang Zhou, Yasheng Sun, Wayne Wu, Chen Cha
 628 Dec 28, 2022
628 Dec 28, 2022
Dress up your code with a beautiful graphical user interface !
Dresscode Dress up your code with a beautiful graphical user interface ! This project is part of the Pyrustic Ecosystem. Look powered by the cyberpunk
 20 Aug 24, 2022
20 Aug 24, 2022

Python interface to PROJ (cartographic projections and coordinate transformations library)
pyproj Python interface to PROJ (cartographic projections and coordinate transformations library). Documentation Stable: http://pyproj4.github.io/pypr
 832 Dec 31, 2022
832 Dec 31, 2022
This tool extracts Credit card numbers, NTLM(DCE-RPC, HTTP, SQL, LDAP, etc), Kerberos (AS-REQ Pre-Auth etype 23), HTTP Basic, SNMP, POP, SMTP, FTP, IMAP, etc from a pcap file or from a live interface.
This tool extracts Credit card numbers, NTLM(DCE-RPC, HTTP, SQL, LDAP, etc), Kerberos (AS-REQ Pre-Auth etype 23), HTTP Basic, SNMP, POP, SMTP, FTP, IMAP, etc from a pcap file or from a live interface.
 1.6k Jan 1, 2023
1.6k Jan 1, 2023
Anaconda is the OS installer used by Fedora, RHEL, CentOS and other Linux distributions.
Anaconda is the OS installer used by Fedora, RHEL, CentOS and other Linux distributions. Documentation Documentation for the Anaconda install
 454 Jan 8, 2023
454 Jan 8, 2023
RSS feed generator website with user friendly interface
RSS feed generator website with user friendly interface
 331 Jan 2, 2023
331 Jan 2, 2023
Command line interface for testing internet bandwidth using speedtest.net
speedtest-cli Command line interface for testing internet bandwidth using speedtest.net Versions speedtest-cli works with Python 2.4-3.7 Installation
 12.4k Jan 8, 2023
12.4k Jan 8, 2023
Pytorch port of Google Research's LEAF Audio paper
leaf-audio-pytorch Pytorch port of Google Research's LEAF Audio paper published at ICLR 2021. This port is not completely finished, but the Leaf() fro
 80 Oct 31, 2022
80 Oct 31, 2022
A collection of common regular expressions bundled with an easy to use interface.
CommonRegex Find all times, dates, links, phone numbers, emails, ip addresses, prices, hex colors, and credit card numbers in a string. We did the har
 1.5k Dec 31, 2022
1.5k Dec 31, 2022
Simple yet flexible natural sorting in Python.
natsort Simple yet flexible natural sorting in Python. Source Code: https://github.com/SethMMorton/natsort Downloads: https://pypi.org/project/natsort
 712 Dec 23, 2022
712 Dec 23, 2022