663 Repositories
Python decision-science Libraries
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 6k Jan 4, 2023
6k Jan 4, 2023

Viewflow is an Airflow-based framework that allows data scientists to create data models without writing Airflow code.
Viewflow Viewflow is a framework built on the top of Airflow that enables data scientists to create materialized views. It allows data scientists to f
 114 Oct 12, 2022
114 Oct 12, 2022

An introduction of Markov decision process (MDP) and two algorithms that solve MDPs (value iteration, policy iteration) along with their Python implementations.
Markov Decision Process A Markov decision process (MDP), by definition, is a sequential decision problem for a fully observable, stochastic environmen
 31 Dec 30, 2022
31 Dec 30, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
A probabilistic programming language in TensorFlow. Deep generative models, variational inference.
Edward is a Python library for probabilistic modeling, inference, and criticism. It is a testbed for fast experimentation and research with probabilis
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
Probabilistic reasoning and statistical analysis in TensorFlow
TensorFlow Probability TensorFlow Probability is a library for probabilistic reasoning and statistical analysis in TensorFlow. As part of the TensorFl
 3.8k Jan 5, 2023
3.8k Jan 5, 2023
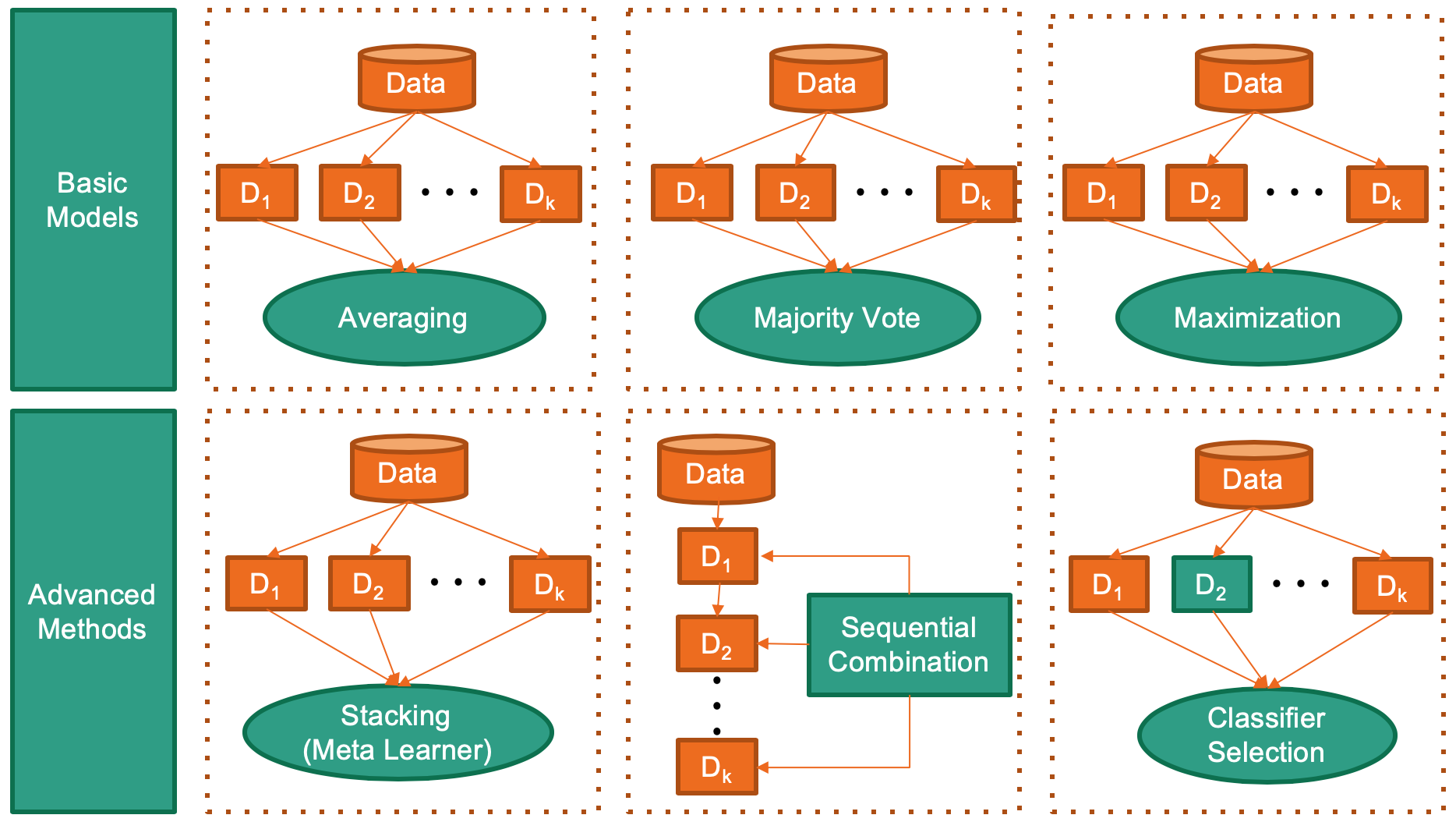
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
 4.2k Dec 28, 2022
4.2k Dec 28, 2022
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
 6.2k Jan 1, 2023
6.2k Jan 1, 2023

A simplified framework and utilities for PyTorch
Here is Poutyne. Poutyne is a simplified framework for PyTorch and handles much of the boilerplating code needed to train neural networks. Use Poutyne
 534 Dec 17, 2022
534 Dec 17, 2022
BlazingSQL is a lightweight, GPU accelerated, SQL engine for Python. Built on RAPIDS cuDF.
A lightweight, GPU accelerated, SQL engine built on the RAPIDS.ai ecosystem. Get Started on app.blazingsql.com Getting Started | Documentation | Examp
 1.8k Jan 2, 2023
1.8k Jan 2, 2023

Distributed scikit-learn meta-estimators in PySpark
sk-dist: Distributed scikit-learn meta-estimators in PySpark What is it? sk-dist is a Python package for machine learning built on top of scikit-learn
 282 Dec 9, 2022
282 Dec 9, 2022
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
 23.3k Dec 31, 2022
23.3k Dec 31, 2022

A Python library for detecting patterns and anomalies in massive datasets using the Matrix Profile
matrixprofile-ts matrixprofile-ts is a Python 2 and 3 library for evaluating time series data using the Matrix Profile algorithms developed by the Keo
 696 Dec 26, 2022
696 Dec 26, 2022
Python module for machine learning time series:
seglearn Seglearn is a python package for machine learning time series or sequences. It provides an integrated pipeline for segmentation, feature extr
 536 Dec 29, 2022
536 Dec 29, 2022
STUMPY is a powerful and scalable Python library for computing a Matrix Profile, which can be used for a variety of time series data mining tasks
STUMPY STUMPY is a powerful and scalable library that efficiently computes something called the matrix profile, which can be used for a variety of tim
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
 6k Jan 6, 2023
6k Jan 6, 2023

Automatic extraction of relevant features from time series:
tsfresh This repository contains the TSFRESH python package. The abbreviation stands for "Time Series Feature extraction based on scalable hypothesis
 7k Jan 6, 2023
7k Jan 6, 2023
Documentation and samples for ArcGIS API for Python
ArcGIS API for Python ArcGIS API for Python is a Python library for working with maps and geospatial data, powered by web GIS. It provides simple and
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
"Very simple but works well" Computer Vision based ID verification solution provided by LibraX.
ID Verification by LibraX.ai This is the first free Identity verification in the market. LibraX.ai is an identity verification platform for developers
 46 Dec 6, 2022
46 Dec 6, 2022

A collection of full-stack resources for programmers.
A collection of full-stack resources for programmers.
 22.3k Dec 30, 2022
22.3k Dec 30, 2022
TorchMetrics is a collection of 25+ PyTorch metrics implementations and an easy-to-use API to create custom metrics.
Machine learning metrics for distributed, scalable PyTorch applications.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
🦉Data Version Control | Git for Data & Models
Website • Docs • Blog • Twitter • Chat (Community & Support) • Tutorial • Mailing List Data Version Control or DVC is an open-source tool for data sci
 10.9k Jan 9, 2023
10.9k Jan 9, 2023

Capture all information throughout your model's development in a reproducible way and tie results directly to the model code!
Rubicon Purpose Rubicon is a data science tool that captures and stores model training and execution information, like parameters and outcomes, in a r
 97 Jan 3, 2023
97 Jan 3, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
 10k Jan 1, 2023
10k Jan 1, 2023
An extension to pandas dataframes describe function.
pandas_summary An extension to pandas dataframes describe function. The module contains DataFrameSummary object that extend describe() with: propertie
 450 Dec 30, 2022
450 Dec 30, 2022
Supervised domain-agnostic prediction framework for probabilistic modelling
A supervised domain-agnostic framework that allows for probabilistic modelling, namely the prediction of probability distributions for individual data
112 Oct 23, 2022
A fork of OpenAI Baselines, implementations of reinforcement learning algorithms
Stable Baselines Stable Baselines is a set of improved implementations of reinforcement learning algorithms based on OpenAI Baselines. You can read a
 3.7k Jan 1, 2023
3.7k Jan 1, 2023
A scikit-learn-compatible Python implementation of ReBATE, a suite of Relief-based feature selection algorithms for Machine Learning.
Master status: Development status: Package information: scikit-rebate This package includes a scikit-learn-compatible Python implementation of ReBATE,
 374 Dec 15, 2022
374 Dec 15, 2022
A fast xgboost feature selection algorithm
BoostARoota A Fast XGBoost Feature Selection Algorithm (plus other sklearn tree-based classifiers) Why Create Another Algorithm? Automated processes l
 187 Dec 22, 2022
187 Dec 22, 2022
Automatic extraction of relevant features from time series:
tsfresh This repository contains the TSFRESH python package. The abbreviation stands for "Time Series Feature extraction based on scalable hypothesis
7k Jan 3, 2023
An open source python library for automated feature engineering
"One of the holy grails of machine learning is to automate more and more of the feature engineering process." ― Pedro Domingos, A Few Useful Things to
 6.4k Jan 5, 2023
6.4k Jan 5, 2023
Build, test, deploy, iterate - Dev and prod tool for data science pipelines
Prodmodel is a build system for data science pipelines. Users, testers, contributors are welcome! Motivation · Concepts · Installation · Usage · Contr
 53 Nov 29, 2022
53 Nov 29, 2022
BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflows even for datasets that do not fit into memory.
BatchFlow BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflo
 185 Dec 20, 2022
185 Dec 20, 2022
Easy pipelines for pandas DataFrames.
pdpipe ˨ Easy pipelines for pandas DataFrames (learn how!). Website: https://pdpipe.github.io/pdpipe/ Documentation: https://pdpipe.github.io/pdpipe/d
 694 Jan 5, 2023
694 Jan 5, 2023
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
A pure Python implementation of Apache Spark's RDD and DStream interfaces.
pysparkling Pysparkling provides a faster, more responsive way to develop programs for PySpark. It enables code intended for Spark applications to exe
 254 Dec 6, 2022
254 Dec 6, 2022
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023
treeinterpreter - Interpreting scikit-learn's decision tree and random forest predictions.
TreeInterpreter Package for interpreting scikit-learn's decision tree and random forest predictions. Allows decomposing each prediction into bias and
 720 Dec 22, 2022
720 Dec 22, 2022

A library for debugging/inspecting machine learning classifiers and explaining their predictions
ELI5 ELI5 is a Python package which helps to debug machine learning classifiers and explain their predictions. It provides support for the following m
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

An intuitive library to add plotting functionality to scikit-learn objects.
Welcome to Scikit-plot Single line functions for detailed visualizations The quickest and easiest way to go from analysis... ...to this. Scikit-plot i
 2.3k Dec 31, 2022
2.3k Dec 31, 2022
Python library that makes it easy for data scientists to create charts.
Chartify Chartify is a Python library that makes it easy for data scientists to create charts. Why use Chartify? Consistent input data format: Spend l
 3.2k Jan 1, 2023
3.2k Jan 1, 2023
Keras community contributions
keras-contrib : Keras community contributions Keras-contrib is deprecated. Use TensorFlow Addons. The future of Keras-contrib: We're migrating to tens
 1.6k Dec 21, 2022
1.6k Dec 21, 2022
Machine Learning Platform for Kubernetes
Reproduce, Automate, Scale your data science. Welcome to Polyaxon, a platform for building, training, and monitoring large scale deep learning applica
 3.2k Dec 23, 2022
3.2k Dec 23, 2022
A simplified framework and utilities for PyTorch
Here is Poutyne. Poutyne is a simplified framework for PyTorch and handles much of the boilerplating code needed to train neural networks. Use Poutyne
534 Dec 17, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 7, 2023
14.5k Jan 7, 2023
Home repository for the Regularized Greedy Forest (RGF) library. It includes original implementation from the paper and multithreaded one written in C++, along with various language-specific wrappers.
Regularized Greedy Forest Regularized Greedy Forest (RGF) is a tree ensemble machine learning method described in this paper. RGF can deliver better r
 363 Dec 14, 2022
363 Dec 14, 2022
Python-based implementations of algorithms for learning on imbalanced data.
ND DIAL: Imbalanced Algorithms Minimalist Python-based implementations of algorithms for imbalanced learning. Includes deep and representational learn
 220 Dec 13, 2022
220 Dec 13, 2022
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
6.2k Jan 1, 2023
MLBox is a powerful Automated Machine Learning python library.
MLBox is a powerful Automated Machine Learning python library. It provides the following features: Fast reading and distributed data preprocessing/cle
 1.4k Jan 6, 2023
1.4k Jan 6, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
8.9k Jan 9, 2023

Little Ball of Fur - A graph sampling extension library for NetworKit and NetworkX (CIKM 2020)
Little Ball of Fur is a graph sampling extension library for Python. Please look at the Documentation, relevant Paper, Promo video and External Resour
 619 Dec 14, 2022
619 Dec 14, 2022

Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
1.8k Jan 3, 2023
![[HELP REQUESTED] Generalized Additive Models in Python](https://github.com/dswah/pyGAM/raw/master/imgs/pygam_tensor.png)
[HELP REQUESTED] Generalized Additive Models in Python
pyGAM Generalized Additive Models in Python. Documentation Official pyGAM Documentation: Read the Docs Building interpretable models with Generalized
 747 Jan 5, 2023
747 Jan 5, 2023
Highly interpretable classifiers for scikit learn, producing easily understood decision rules instead of black box models
Highly interpretable, sklearn-compatible classifier based on decision rules This is a scikit-learn compatible wrapper for the Bayesian Rule List class
 482 Nov 19, 2022
482 Nov 19, 2022
50% faster, 50% less RAM Machine Learning. Numba rewritten Sklearn. SVD, NNMF, PCA, LinearReg, RidgeReg, Randomized, Truncated SVD/PCA, CSR Matrices all 50+% faster
[Due to the time taken @ uni, work + hell breaking loose in my life, since things have calmed down a bit, will continue commiting!!!] [By the way, I'm
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
4.2k Dec 29, 2022
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
 3k Jan 8, 2023
3k Jan 8, 2023
ReproZip is a tool that simplifies the process of creating reproducible experiments from command-line executions, a frequently-used common denominator in computational science.
ReproZip ReproZip is a tool aimed at simplifying the process of creating reproducible experiments from command-line executions, a frequently-used comm
 267 Jan 1, 2023
267 Jan 1, 2023

🍊 :bar_chart: :bulb: Orange: Interactive data analysis
Orange Data Mining Orange is a data mining and visualization toolbox for novice and expert alike. To explore data with Orange, one requires no program
 3.9k Jan 5, 2023
3.9k Jan 5, 2023
Data intensive science for everyone.
The latest information about Galaxy can be found on the Galaxy Community Hub. Community support is available at Galaxy Help. Galaxy Quickstart Galaxy
 1k Jan 8, 2023
1k Jan 8, 2023

A Python library that helps data scientists to infer causation rather than observing correlation.
A Python library that helps data scientists to infer causation rather than observing correlation.
 1.7k Jan 4, 2023
1.7k Jan 4, 2023
🦉Data Version Control | Git for Data & Models
Website • Docs • Blog • Twitter • Chat (Community & Support) • Tutorial • Mailing List Data Version Control or DVC is an open-source tool for data sci
10.9k Jan 5, 2023
MazeRL is an application oriented Deep Reinforcement Learning (RL) framework
MazeRL is an application oriented Deep Reinforcement Learning (RL) framework, addressing real-world decision problems. Our vision is to cover the complete development life cycle of RL applications ranging from simulation engineering up to agent development, training and deployment.
 222 Dec 24, 2022
222 Dec 24, 2022
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
5.4k Feb 20, 2021

A PyTorch implementation of "Pathfinder Discovery Networks for Neural Message Passing"
A PyTorch implementation of "Pathfinder Discovery Networks for Neural Message Passing" (WebConf 2021). Abstract In this work we propose Pathfind
49 Dec 1, 2022
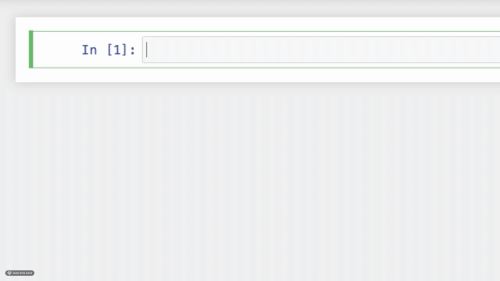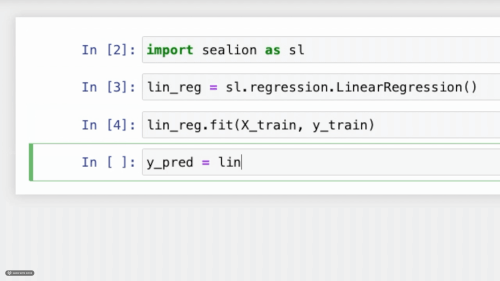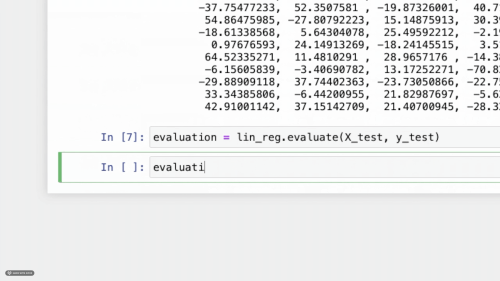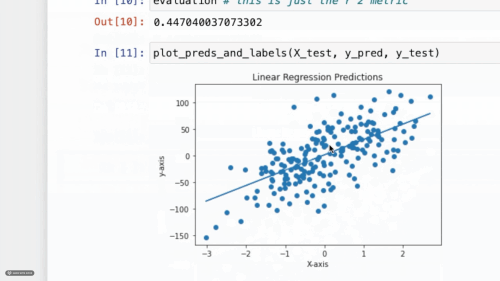
The first machine learning framework that encourages learning ML concepts instead of memorizing class functions.
SeaLion is designed to teach today's aspiring ml-engineers the popular machine learning concepts of today in a way that gives both intuition and ways of application. We do this through concise algorithms that do the job in the least jargon possible and examples to guide you through every step of the way.
 324 Dec 27, 2022
324 Dec 27, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
An open-source NLP research library, built on PyTorch.
An Apache 2.0 NLP research library, built on PyTorch, for developing state-of-the-art deep learning models on a wide variety of linguistic tasks. Quic
 9.7k Feb 18, 2021
9.7k Feb 18, 2021
💫 Industrial-strength Natural Language Processing (NLP) in Python
spaCy: Industrial-strength NLP spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest researc
 19.6k Feb 18, 2021
19.6k Feb 18, 2021
Drag’n’drop Pivot Tables and Charts for Jupyter/IPython Notebook, care of PivotTable.js
pivottablejs: the Python module Drag’n’drop Pivot Tables and Charts for Jupyter/IPython Notebook, care of PivotTable.js Installation pip install pivot
 419 Feb 11, 2021
419 Feb 11, 2021

An open-source plotting library for statistical data.
Lets-Plot Lets-Plot is an open-source plotting library for statistical data. It is implemented using the Kotlin programming language. The design of Le
 509 Feb 17, 2021
509 Feb 17, 2021
Visualize and compare datasets, target values and associations, with one line of code.
In-depth EDA (target analysis, comparison, feature analysis, correlation) in two lines of code! Sweetviz is an open-source Python library that generat
 1.2k Feb 18, 2021
1.2k Feb 18, 2021
Python library that makes it easy for data scientists to create charts.
Chartify Chartify is a Python library that makes it easy for data scientists to create charts. Why use Chartify? Consistent input data format: Spend l
2.8k Feb 18, 2021

3D plotting and mesh analysis through a streamlined interface for the Visualization Toolkit (VTK)
PyVista Deployment Build Status Metrics Citation License Community 3D plotting and mesh analysis through a streamlined interface for the Visualization
 692 Feb 18, 2021
692 Feb 18, 2021
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
6.8k Feb 18, 2021

Analytical Web Apps for Python, R, Julia, and Jupyter. No JavaScript Required.
Dash Dash is the most downloaded, trusted Python framework for building ML & data science web apps. Built on top of Plotly.js, React and Flask, Dash t
 14k Feb 18, 2021
14k Feb 18, 2021
Statistical data visualization using matplotlib
seaborn: statistical data visualization Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing
 8.1k Feb 18, 2021
8.1k Feb 18, 2021
Run your jupyter notebooks as a REST API endpoint. This isn't a jupyter server but rather just a way to run your notebooks as a REST API Endpoint.
Jupter Notebook REST API Run your jupyter notebooks as a REST API endpoint. This isn't a jupyter server but rather just a way to run your notebooks as
 54 Nov 4, 2022
54 Nov 4, 2022
Download courses from khanacademy.org
khan-dl A python script to download courses from Khan Academy using youtube-dl and beautifulsoup4.
 806 Jan 3, 2023
806 Jan 3, 2023
CJK computer science terms comparison / 中日韓電腦科學術語對照 / 日中韓のコンピュータ科学の用語対照 / 한·중·일 전산학 용어 대조
CJK computer science terms comparison This repository contains the source code of the website. You can see the website from the following link: Englis
 88 Dec 23, 2022
88 Dec 23, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021
Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
2k Dec 27, 2022
An open-source NLP research library, built on PyTorch.
An Apache 2.0 NLP research library, built on PyTorch, for developing state-of-the-art deep learning models on a wide variety of linguistic tasks. Quic
11.4k Jan 1, 2023
💫 Industrial-strength Natural Language Processing (NLP) in Python
spaCy: Industrial-strength NLP spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest researc
19.5k Feb 13, 2021
Drag’n’drop Pivot Tables and Charts for Jupyter/IPython Notebook, care of PivotTable.js
pivottablejs: the Python module Drag’n’drop Pivot Tables and Charts for Jupyter/IPython Notebook, care of PivotTable.js Installation pip install pivot
512 Dec 26, 2022
An open-source plotting library for statistical data.
Lets-Plot Lets-Plot is an open-source plotting library for statistical data. It is implemented using the Kotlin programming language. The design of Le
820 Jan 6, 2023
Visualize and compare datasets, target values and associations, with one line of code.
In-depth EDA (target analysis, comparison, feature analysis, correlation) in two lines of code! Sweetviz is an open-source Python library that generat
2.3k Jan 5, 2023
Python library that makes it easy for data scientists to create charts.
Chartify Chartify is a Python library that makes it easy for data scientists to create charts. Why use Chartify? Consistent input data format: Spend l
3.2k Jan 4, 2023
3D plotting and mesh analysis through a streamlined interface for the Visualization Toolkit (VTK)
PyVista Deployment Build Status Metrics Citation License Community 3D plotting and mesh analysis through a streamlined interface for the Visualization
1.6k Jan 8, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023
Analytical Web Apps for Python, R, Julia, and Jupyter. No JavaScript Required.
Dash Dash is the most downloaded, trusted Python framework for building ML & data science web apps. Built on top of Plotly.js, React and Flask, Dash t
13.9k Feb 13, 2021
Statistical data visualization using matplotlib
seaborn: statistical data visualization Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing
8.1k Feb 13, 2021
fklearn: Functional Machine Learning
fklearn: Functional Machine Learning fklearn uses functional programming principles to make it easier to solve real problems with Machine Learning. Th
 1.4k Dec 7, 2022
1.4k Dec 7, 2022
Shōgun
The SHOGUN machine learning toolbox Unified and efficient Machine Learning since 1999. Latest release: Cite Shogun: Develop branch build status: Donat
 2.8k Feb 13, 2021
2.8k Feb 13, 2021
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
2.8k Feb 12, 2021

Deep learning library featuring a higher-level API for TensorFlow.
TFLearn: Deep learning library featuring a higher-level API for TensorFlow. TFlearn is a modular and transparent deep learning library built on top of
 9.5k Feb 12, 2021
9.5k Feb 12, 2021
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
5.7k Feb 12, 2021