693 Repositories
Python fashion-mnist-dataset Libraries

Official code for our CVPR '22 paper "Dataset Distillation by Matching Training Trajectories"
Dataset Distillation by Matching Training Trajectories Project Page | Paper This repo contains code for training expert trajectories and distilling sy
 256 Jan 5, 2023
256 Jan 5, 2023

Official MegEngine implementation of CREStereo(CVPR 2022 Oral).
[CVPR 2022] Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation This repository contains MegEngine implementation of ou
 309 Dec 30, 2022
309 Dec 30, 2022
Relative Human dataset, CVPR 2022
Relative Human (RH) contains multi-person in-the-wild RGB images with rich human annotations, including: Depth layers (DLs): relative depth relationsh
 112 Dec 2, 2022
112 Dec 2, 2022
OOD Dataset Curator and Benchmark for AI-aided Drug Discovery
🔥 DrugOOD 🔥 : OOD Dataset Curator and Benchmark for AI Aided Drug Discovery This is the official implementation of the DrugOOD project, this is the
 108 Dec 17, 2022
108 Dec 17, 2022
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

KwaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%)
KuaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%) KuaiRec is a real-world dataset collected from the recommendation log
 70 Dec 28, 2022
70 Dec 28, 2022
How to train a CNN to 99% accuracy on MNIST in less than a second on a laptop
Training a NN to 99% accuracy on MNIST in 0.76 seconds A quick study on how fast you can reach 99% accuracy on MNIST with a single laptop. Our answer
 42 Dec 10, 2022
42 Dec 10, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023

BankNote-Net: Open dataset and encoder model for assistive currency recognition
BankNote-Net: Open Dataset for Assistive Currency Recognition Millions of people around the world have low or no vision. Assistive software applicatio
 13 Oct 28, 2022
13 Oct 28, 2022
Finally, some decent sample sentences
tts-dataset-prompts This repository aims to be a decent set of sentences for people looking to clone their own voices (e.g. using Tacotron 2). Each se
 19 Dec 13, 2022
19 Dec 13, 2022
For visualizing the dair-v2x-i dataset
3D Detection & Tracking Viewer The project is based on hailanyi/3D-Detection-Tracking-Viewer and is modified, you can find the original version of the
 34 Dec 29, 2022
34 Dec 29, 2022
H&M Fashion Image similarity search with Weaviate and DocArray
H&M Fashion Image similarity search with Weaviate and DocArray This example shows how to do image similarity search using DocArray and Weaviate as Doc
 18 Aug 11, 2022
18 Aug 11, 2022

FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset (CVPR2022)
FaceVerse FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset Lizhen Wang, Zhiyuan Chen, Tao Yu, Chenguang
 219 Dec 28, 2022
219 Dec 28, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022
Notebooks, slides and dataset of the CorrelAid Machine Learning Winter School
CorrelAid Machine Learning Spring School Welcome to the CorrelAid ML Spring School! In this repository you can find the slides and other files for the
 12 Nov 23, 2022
12 Nov 23, 2022

Precision Medicine Knowledge Graph (PrimeKG)
PrimeKG Website | bioRxiv Paper | Harvard Dataverse Precision Medicine Knowledge Graph (PrimeKG) presents a holistic view of diseases. PrimeKG integra
 103 Dec 10, 2022
103 Dec 10, 2022

The official GitHub repository for the Argoverse 2 dataset.
Argoverse 2 API Official GitHub repository for the Argoverse 2 family of datasets. If you have any questions or run into any problems with either the
 156 Dec 23, 2022
156 Dec 23, 2022
![ISNAS-DIP: Image Specific Neural Architecture Search for Deep Image Prior [CVPR 2022]](https://github.com/ozgurkara99/ISNAS-DIP/raw/main/docs/method.jpg)
ISNAS-DIP: Image Specific Neural Architecture Search for Deep Image Prior [CVPR 2022]
ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image Prior (CVPR 2022) Metin Ersin Arican*, Ozgur Kara*, Gustav Bredell, Ender Konukogl
 24 Dec 18, 2022
24 Dec 18, 2022
The SVO-Probes Dataset for Verb Understanding
The SVO-Probes Dataset for Verb Understanding This repository contains the SVO-Probes benchmark designed to probe for Subject, Verb, and Object unders
 20 Nov 30, 2022
20 Nov 30, 2022

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022

In this tutorial, you will perform inference across 10 well-known pre-trained object detectors and fine-tune on a custom dataset. Design and train your own object detector.
Object Detection Object detection is a computer vision task for locating instances of predefined objects in images or videos. In this tutorial, you wi
 62 Dec 25, 2022
62 Dec 25, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
87 Dec 21, 2022

This project contains the ClonedPerson dataset and code described in our paper "Cloning Outfits from Real-World Images to 3D Characters for Generalizable Person Re-Identification".
ClonedPerson This is the official repository for the ClonedPerson project, which contains the ClonedPerson dataset and code described in our paper "Cl
 55 Dec 27, 2022
55 Dec 27, 2022
Everything you want about DP-Based Federated Learning, including Papers and Code. (Mechanism: Laplace or Gaussian, Dataset: femnist, shakespeare, mnist, cifar-10 and fashion-mnist. )
Differential Privacy (DP) Based Federated Learning (FL) Everything about DP-based FL you need is here. (所有你需要的DP-based FL的信息都在这里) Code Tip: the code o
 83 Dec 24, 2022
83 Dec 24, 2022
![[LREC] MMChat: Multi-Modal Chat Dataset on Social Media](https://github.com/silverriver/MMChat/raw/main/bin/sample.jpg)
[LREC] MMChat: Multi-Modal Chat Dataset on Social Media
MMChat This repo contains the code and data for the LREC2022 paper MMChat: Multi-Modal Chat Dataset on Social Media. Dataset MMChat is a large-scale d
 47 Jan 3, 2023
47 Jan 3, 2023
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
Creating a custom CNN hypertunned architeture for the Fashion MNIST dataset with Python, Keras and Tensorflow.
custom-cnn-fashion-mnist Creating a custom CNN hypertunned architeture for the Fashion MNIST dataset with Python, Keras and Tensorflow. The following
 1 Mar 5, 2022
1 Mar 5, 2022

In this project, RandomOverSampler and SMOTE algorithms were used to perform oversampling, ClusterCentroids algorithm was used to undersampling, SMOTEENN algorithm was applied as a combinatorial approach of over- and undersampling of credit card credit dataset from LendingClub. Machine learning models - BalancedRandomForestClassifier and EasyEnsembleClassifier were used to predict credit risk.
Overview of Credit Card Analysis In this project, RandomOverSampler and SMOTE algorithms were used to perform oversampling, ClusterCentroids algorithm
 1 Mar 12, 2022
1 Mar 12, 2022

Experimental Python implementation of OpenVINO Inference Engine (very slow, limited functionality). All codes are written in Python. Easy to read and modify.
PyOpenVINO - An Experimental Python Implementation of OpenVINO Inference Engine (minimum-set) Description The PyOpenVINO is a spin-off product from my
 7 Oct 31, 2022
7 Oct 31, 2022
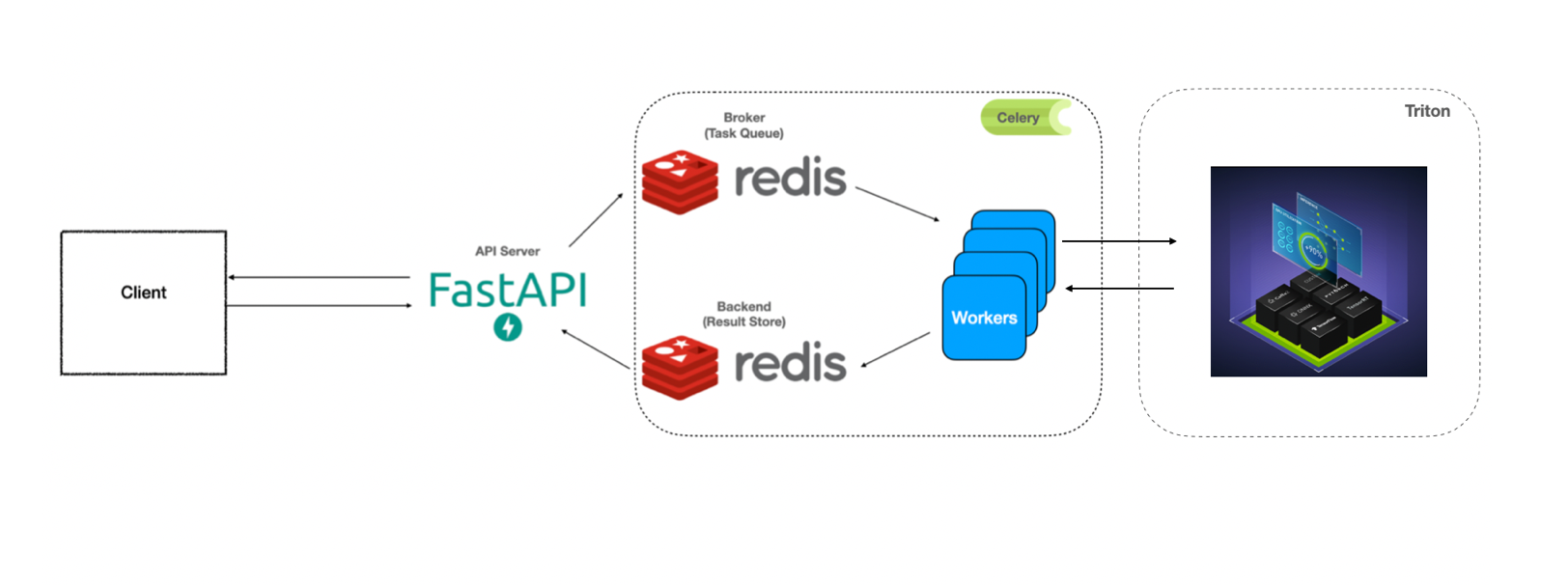
Simple example of FastAPI + Celery + Triton for benchmarking
You can see the previous work from: https://github.com/Curt-Park/producer-consumer-fastapi-celery https://github.com/Curt-Park/triton-inference-server
 37 Dec 29, 2022
37 Dec 29, 2022

ZeroGen: Efficient Zero-shot Learning via Dataset Generation
ZEROGEN This repository contains the code for our paper “ZeroGen: Efficient Zero
 31 Dec 30, 2022
31 Dec 30, 2022
Dataset Condensation with Contrastive Signals
Dataset Condensation with Contrastive Signals This repository is the official implementation of Dataset Condensation with Contrastive Signals (DCC). T
 3 May 19, 2022
3 May 19, 2022

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022

Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track)
Kcse-Data-Analysis Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track) Findings The performance of
 1 Feb 23, 2022
1 Feb 23, 2022
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022
Citation Intent Classification in scientific papers using the Scicite dataset an Pytorch
Citation Intent Classification Table of Contents About the Project Built With Installation Usage Acknowledgments About The Project Citation Intent Cla
 4 Mar 4, 2022
4 Mar 4, 2022
Computational inteligence project on faces in the wild dataset
Table of Contents The general idea How these scripts work? Loading data Needed modules and global variables Parsing the arrays in dataset Extracting a
 4 Oct 21, 2022
4 Oct 21, 2022
Repo for my Tensorflow/Keras CV experiments. Mostly revolving around the Danbooru20xx dataset
SW-CV-ModelZoo Repo for my Tensorflow/Keras CV experiments. Mostly revolving around the Danbooru20xx dataset Framework: TF/Keras 2.7 Training SQLite D
 20 Dec 27, 2022
20 Dec 27, 2022

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022

Code for ML, domain generation, graph generation of ABC dataset
This is the repository for codes for ML, domain generation, graph generation of Asymmetric Buckling Columns (ABC) dataset in the paper "Learning Mechanically Driven Emergent Behavior with Message Passing Neural Networks".
 0 Jan 28, 2022
0 Jan 28, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022
CodeContests is a competitive programming dataset for machine-learning
CodeContests CodeContests is a competitive programming dataset for machine-learning. This dataset was used when training AlphaCode. It consists of pro
1.6k Jan 8, 2023
JaQuAD: Japanese Question Answering Dataset
JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension (2022, Skelter Labs)
 84 Dec 27, 2022
84 Dec 27, 2022

A transformer which can randomly augment VOC format dataset (both image and bbox) online.
VocAug It is difficult to find a script which can augment VOC-format dataset, especially the bbox. Or find a script needs complex requirements so it i
 1 Mar 5, 2022
1 Mar 5, 2022
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
 0 Feb 8, 2022
0 Feb 8, 2022
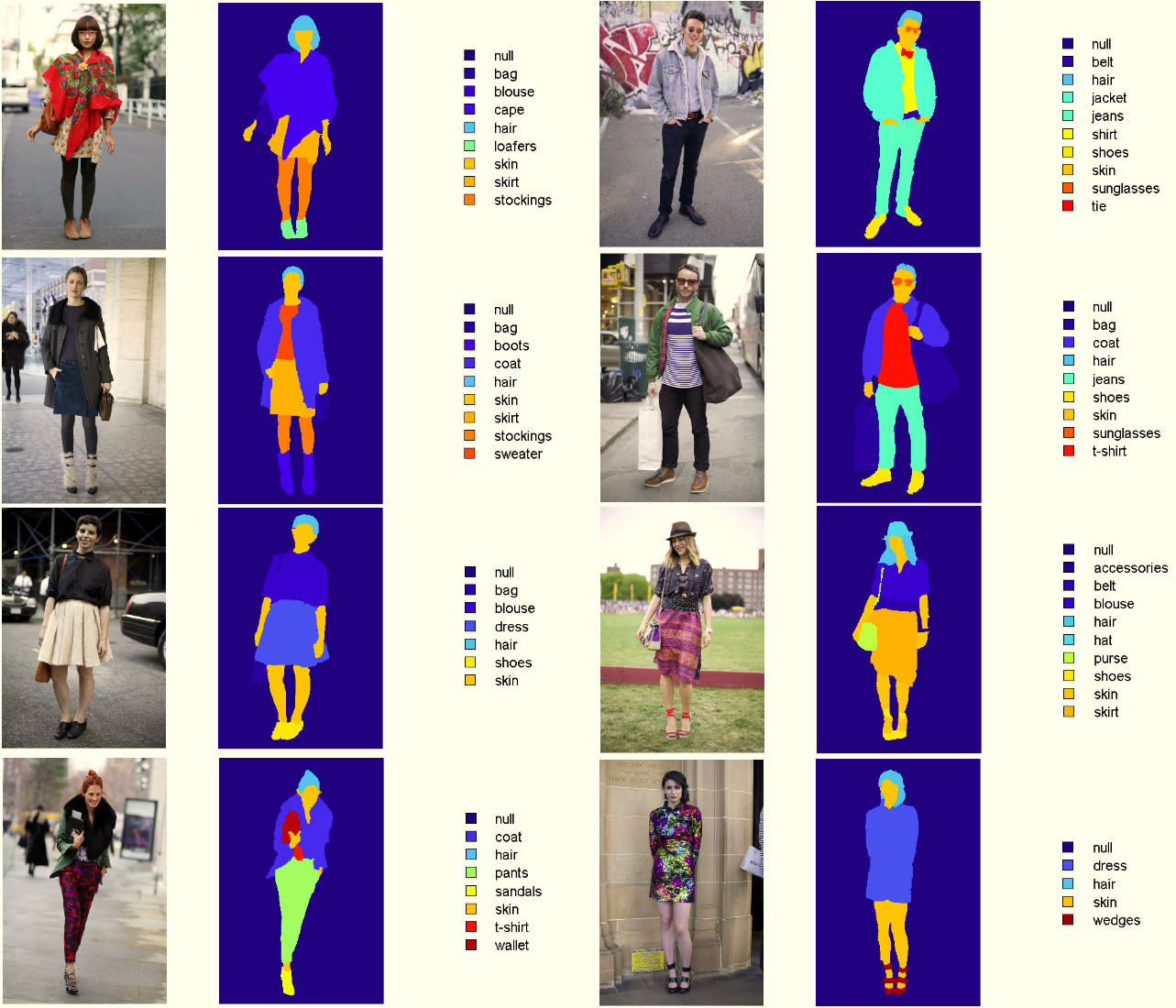
CCP dataset from Clothing Co-Parsing by Joint Image Segmentation and Labeling
Clothing Co-Parsing (CCP) Dataset Clothing Co-Parsing (CCP) dataset is a new clothing database including elaborately annotated clothing items. 2, 098
 434 Dec 24, 2022
434 Dec 24, 2022

Scraping and visualising India's real-time COVID-19 data from the MOHFW dataset.
COVID19-WEB-SCRAPER Open Source Tech Lab - Project [SEMESTER IV] OSTL Assignments OSTL Assignments - 1 OSTL Assignments - 2 Project COVID19 India Data
 8 Apr 28, 2022
8 Apr 28, 2022
A notebook to analyze Amazon Recommendation Review Dataset.
Amazon Recommendation Review Dataset Analyzer A notebook to analyze Amazon Recommendation Review Dataset. Features Calculates distinct user count, dis
 3 Aug 22, 2022
3 Aug 22, 2022
1900-2016 Olympic Data Analysis in Python by plotting different graphs
🔥 Olympics Data Analysis 🔥 In Data Science field, there is a big topic before creating a model for future prediction is Data Analysis. We can find o
 1 Feb 6, 2022
1 Feb 6, 2022
Mnist API server w/ FastAPI
Mnist API server w/ FastAPI
8 Feb 8, 2022

Generating retro pixel game characters with Generative Adversarial Networks. Dataset "TinyHero" included.
pixel_character_generator Generating retro pixel game characters with Generative Adversarial Networks. Dataset "TinyHero" included. Dataset TinyHero D
 88 Nov 17, 2022
88 Nov 17, 2022

Semantic Segmentation Suite in TensorFlow
Semantic Segmentation Suite in TensorFlow. Implement, train, and test new Semantic Segmentation models easily!
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
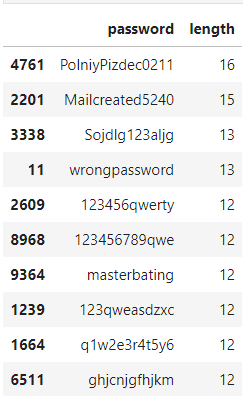
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
 7 Sep 4, 2022
7 Sep 4, 2022

Breast Cancer Classification Model is applied on a different dataset
Breast Cancer Classification Model is applied on a different dataset
 1 Feb 4, 2022
1 Feb 4, 2022
Credit Card Fraud Detection, used the credit card fraud dataset from Kaggle
Credit Card Fraud Detection, used the credit card fraud dataset from Kaggle
 1 Feb 4, 2022
1 Feb 4, 2022

Sematic-Segmantation - Semantic Segmentation on MIT ADE20K dataset in PyTorch
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch impleme
 4 Mar 22, 2022
4 Mar 22, 2022
Training a deep learning model on the noisy CIFAR dataset
Training-a-deep-learning-model-on-the-noisy-CIFAR-dataset This repository contai
 1 Jun 14, 2022
1 Jun 14, 2022

The code uses SegFormer for Semantic Segmentation on Drone Dataset.
SegFormer_Segmentation The code uses SegFormer for Semantic Segmentation on Drone Dataset. The details for the SegFormer can be obtained from the foll
 1 May 8, 2022
1 May 8, 2022

The NewSHead dataset is a multi-doc headline dataset used in NHNet for training a headline summarization model.
This repository contains the raw dataset used in NHNet [1] for the task of News Story Headline Generation. The code of data processing and training is available under Tensorflow Models - NHNet.
 31 Jul 15, 2022
31 Jul 15, 2022
This repository collects together basic linguistic processing data for using dataset dumps from the Common Voice project
Common Voice Utils This repository collects together basic linguistic processing data for using dataset dumps from the Common Voice project. It aims t
 40 Dec 20, 2022
40 Dec 20, 2022
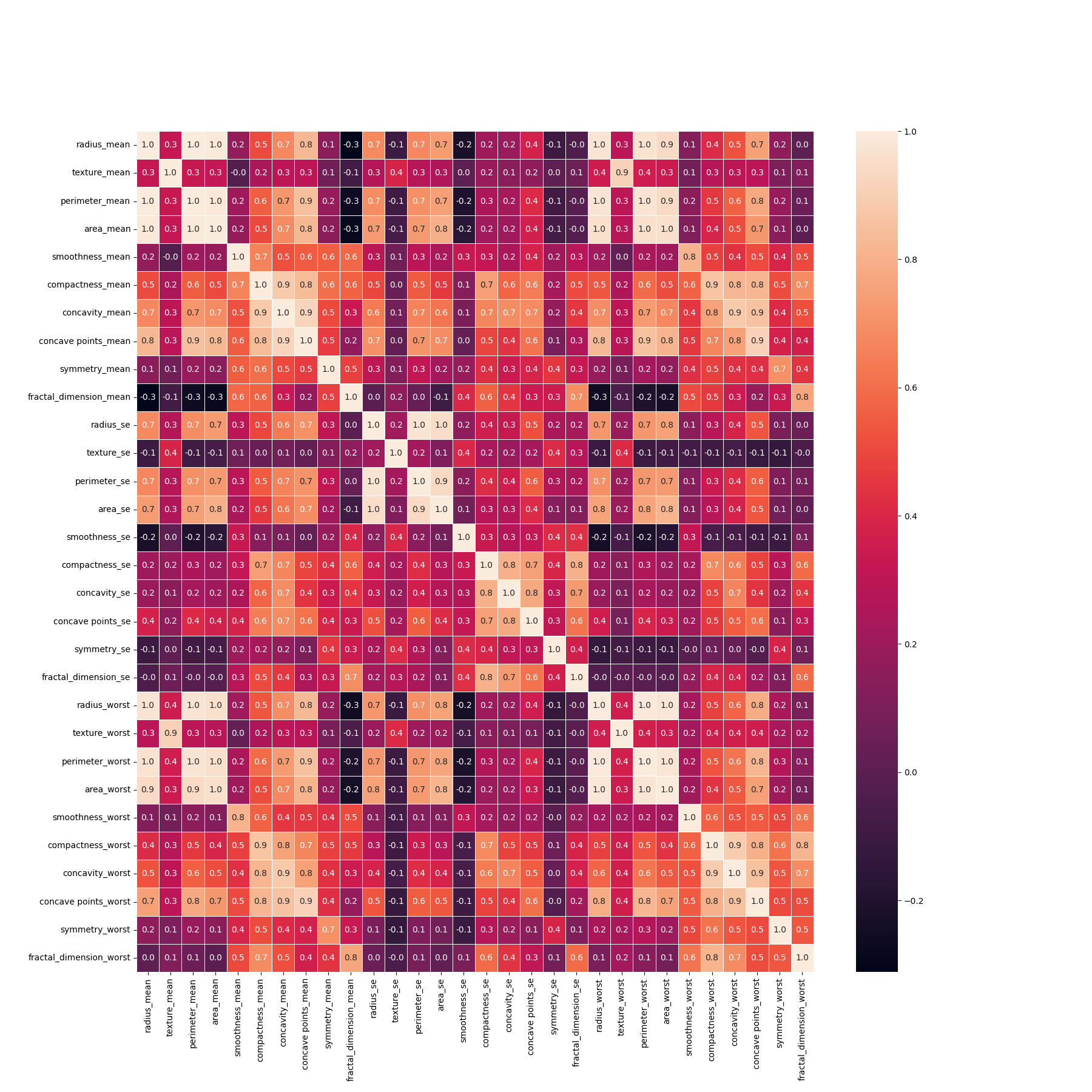
Breast-Cancer-Classification - Using SKLearn breast cancer dataset which contains 569 examples and 32 features classifying has been made with 6 different algorithms
Breast-Cancer-Classification - Using SKLearn breast cancer dataset which contains 569 examples and 32 features classifying has been made with 6 different algorithms
 1 Jan 31, 2022
1 Jan 31, 2022
Using Logistic Regression and classifiers of the dataset to produce an accurate recall, f-1 and precision score
Using Logistic Regression and classifiers of the dataset to produce an accurate recall, f-1 and precision score
 1 Jan 31, 2022
1 Jan 31, 2022
Based on the given clinical dataset, Predict whether the patient having Heart Disease or Not having Heart Disease
Heart_Disease_Classification Based on the given clinical dataset, Predict whether the patient having Heart Disease or Not having Heart Disease Dataset
 1 Jan 30, 2022
1 Jan 30, 2022
Template repository for managing machine learning research projects built with PyTorch-Lightning
Tutorial Repository with a minimal example for showing how to deploy training across various compute infrastructure.
 3 Feb 11, 2022
3 Feb 11, 2022
Notebooks, slides and dataset of the CorrelAid Machine Learning Winter School
CorrelAid Machine Learning Winter School Welcome to the CorrelAid ML Winter School! Task The problem we want to solve is to classify trees in Roosevel
12 Nov 23, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022

TalkingHead-1KH is a talking-head dataset consisting of YouTube videos
TalkingHead-1KH Dataset TalkingHead-1KH is a talking-head dataset consisting of YouTube videos, originally created as a benchmark for face-vid2vid: On
 173 Dec 29, 2022
173 Dec 29, 2022
A face dataset generator with out-of-focus blur detection and dynamic interval adjustment.
A face dataset generator with out-of-focus blur detection and dynamic interval adjustment.
 2 Jan 29, 2022
2 Jan 29, 2022

An Empirical Investigation of Model-to-Model Distribution Shifts in Trained Convolutional Filters
CNN-Filter-DB An Empirical Investigation of Model-to-Model Distribution Shifts in Trained Convolutional Filters Paul Gavrikov, Janis Keuper Paper: htt
 18 Dec 30, 2022
18 Dec 30, 2022

FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction
FaceExtraction FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction Occlusions often occur in face images in the wild, tr
 16 Dec 14, 2022
16 Dec 14, 2022
Tracking Progress in Question Answering over Knowledge Graphs
Tracking Progress in Question Answering over Knowledge Graphs Table of contents Question Answering Systems with Descriptions The QA Systems Table cont
 47 Jan 2, 2023
47 Jan 2, 2023

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Detic ros - A simple ROS wrapper for Detic instance segmentation using pre-trained dataset
Detic ros - A simple ROS wrapper for Detic instance segmentation using pre-trained dataset
 12 Nov 19, 2022
12 Nov 19, 2022

PyTorch META-DATASET (Few-shot classification benchmark)
PyTorch META-DATASET (Few-shot classification benchmark) This repo contains a PyTorch implementation of meta-dataset and a unified implementation of s
 39 Oct 31, 2022
39 Oct 31, 2022

COPA-SSE contains crowdsourced explanations for the Balanced COPA dataset
COPA-SSE Repository for COPA-SSE: Semi-Structured Explanations for Commonsense Reasoning. COPA-SSE contains crowdsourced explanations for the Balanced
 5 Jul 31, 2022
5 Jul 31, 2022
PyTorch IPFS Dataset
PyTorch IPFS Dataset IPFSDataset(Dataset) See the jupyter notepad to see how it works and how it interacts with a standard pytorch DataLoader You need
 2 Apr 13, 2022
2 Apr 13, 2022
Application of K-means algorithm on a music dataset after a dimensionality reduction with PCA
PCA for dimensionality reduction combined with Kmeans Goal The Goal of this notebook is to apply a dimensionality reduction on a big dataset in order
 0 Sep 17, 2022
0 Sep 17, 2022

Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
 4 Jun 1, 2022
4 Jun 1, 2022

COCO Style Dataset Generator GUI
A simple GUI-based COCO-style JSON Polygon masks' annotation tool to facilitate quick and efficient crowd-sourced generation of annotation masks and bounding boxes. Optionally, one could choose to use a pretrained Mask RCNN model to come up with initial segmentations.
 142 Dec 9, 2022
142 Dec 9, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023
It is an open dataset for object detection in remote sensing images.
RSOD-Dataset It is an open dataset for object detection in remote sensing images. The dataset includes aircraft, oiltank, playground and overpass. The
 136 Dec 8, 2022
136 Dec 8, 2022
This jupyter notebook project was completed by me and my friend using the dataset from Kaggle
ARM This jupyter notebook project was completed by me and my friend using the dataset from Kaggle. The world Happiness 2017, which ranks 155 countries
 1 Jan 23, 2022
1 Jan 23, 2022

To prepare an image processing model to classify the type of disaster based on the image dataset
Disaster Classificiation using CNNs bunnysaini/Disaster-Classificiation Goal To prepare an image processing model to classify the type of disaster bas
 1 Jan 24, 2022
1 Jan 24, 2022
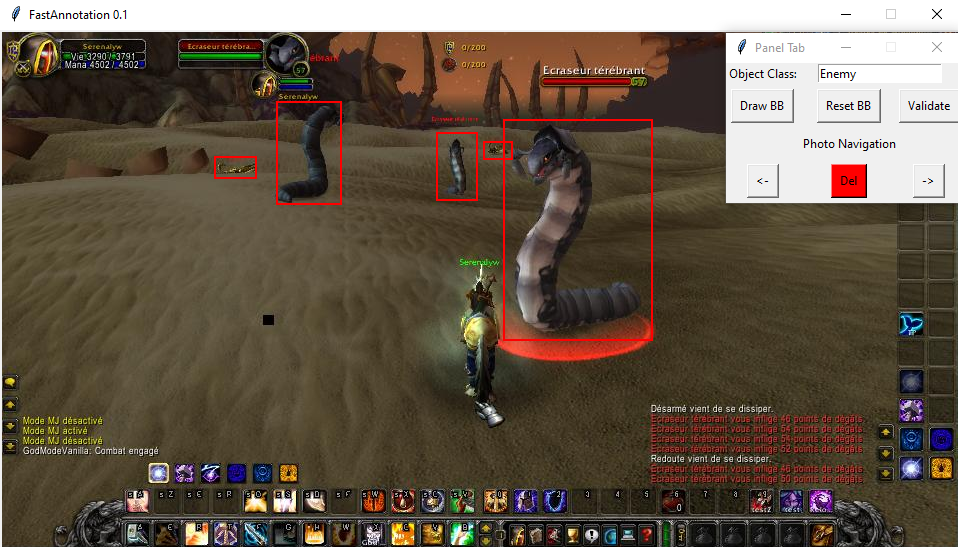
This is a simple framework to make object detection dataset very quickly
FastAnnotation Table of contents General info Requirements Setup General info This is a simple framework to make object detection dataset very quickly
 1 Jan 24, 2022
1 Jan 24, 2022
Klexikon: A German Dataset for Joint Summarization and Simplification
Klexikon: A German Dataset for Joint Summarization and Simplification Dennis Aumiller and Michael Gertz Heidelberg University Under submission at LREC
 8 Jan 3, 2023
8 Jan 3, 2023
Titanic Traveller Survivability Prediction
The aim of the mini project is predict whether or not a passenger survived based on attributes such as their age, sex, passenger class, where they embarked and more.
 0 Jan 20, 2022
0 Jan 20, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022

KGDet: Keypoint-Guided Fashion Detection (AAAI 2021)
KGDet: Keypoint-Guided Fashion Detection (AAAI 2021) This is an official implementation of the AAAI-2021 paper "KGDet: Keypoint-Guided Fashion Detecti
 35 Dec 29, 2022
35 Dec 29, 2022

PyTorch implementation of image classification models for CIFAR-10/CIFAR-100/MNIST/FashionMNIST/Kuzushiji-MNIST/ImageNet
PyTorch Image Classification Following papers are implemented using PyTorch. ResNet (1512.03385) ResNet-preact (1603.05027) WRN (1605.07146) DenseNet
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Finetune the base 64 px GLIDE-text2im model from OpenAI on your own image-text dataset
Finetune the base 64 px GLIDE-text2im model from OpenAI on your own image-text dataset
 82 Oct 13, 2022
82 Oct 13, 2022

A repo to show how to use custom dataset to train s2anet, and change backbone to resnext101
A repo to show how to use custom dataset to train s2anet, and change backbone to resnext101
 3 Dec 28, 2022
3 Dec 28, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
Custom IMDB Dataset is extracted between 2020-2021 and custom distilBERT model is trained for movie success probability prediction
IMDB Success Predictor Project involves Web Scraping custom IMDB data between 2020 and 2021 of 10000 movies and shows sorted by number of votes ,fine
 1 Jan 18, 2022
1 Jan 18, 2022
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction
The dataset contains 3 million attribute-value annotations across 1257 unique categories on 2.2 million cleaned Amazon product profiles. It is a large, multi-sourced, diverse dataset for product attribute extraction study.
17 Jan 18, 2022
"Exploring Vision Transformers for Fine-grained Classification" at CVPRW FGVC8
FGVC8 Exploring Vision Transformers for Fine-grained Classification paper presented at the CVPR 2021, The Eight Workshop on Fine-Grained Visual Catego
 19 Dec 6, 2022
19 Dec 6, 2022

The mini-MusicNet dataset
mini-MusicNet A music-domain dataset for multi-label classification Music transcription is sequence-to-sequence prediction problem: given an audio per
 4 Nov 9, 2022
4 Nov 9, 2022
This repo is about implementing different approaches of pose estimation and also is a sub-task of the smart hospital bed project :smile:
Pose-Estimation This repo is a sub-task of the smart hospital bed project which is about implementing the task of pose estimation 😄 Many thanks to th
 11 Oct 17, 2022
11 Oct 17, 2022