3149 Repositories
Python fast-data-pipeline Libraries

Example scripts for the detection of lanes using the ultra fast lane detection model in Tensorflow Lite.
TFlite Ultra Fast Lane Detection Inference Example scripts for the detection of lanes using the ultra fast lane detection model in Tensorflow Lite. So
 12 Aug 27, 2022
12 Aug 27, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
⚡ A really fast and powerful Discord Token Checker
discord-token-checker ⚡ A really fast and powerful Discord Token Checker How To Use? Do pip install -r requirements.txt in your command prompt Make to
 25 Feb 26, 2022
25 Feb 26, 2022

FLAML is a lightweight Python library that finds accurate machine learning models automatically, efficiently and economically
FLAML - Fast and Lightweight AutoML
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
Implementation of fast algorithms for Maximum Spanning Tree (MST) parsing that includes fast ArcMax+Reweighting+Tarjan algorithm for single-root dependency parsing.
Fast MST Algorithm Implementation of fast algorithms for (Maximum Spanning Tree) MST parsing that includes fast ArcMax+Reweighting+Tarjan algorithm fo
 11 Oct 14, 2022
11 Oct 14, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

skimpy is a light weight tool that provides summary statistics about variables in data frames within the console.
skimpy Welcome Welcome to skimpy! skimpy is a light weight tool that provides summary statistics about variables in data frames within the console. Th
 267 Dec 29, 2022
267 Dec 29, 2022

The Devils Eye is an OSINT tool that searches the Darkweb for onion links and descriptions that match with the users query without requiring the use for Tor.
The Devil's Eye searches the darkweb for information relating to the user's query and returns the results including .onion links and their description
 135 Dec 31, 2022
135 Dec 31, 2022

Python based tool to extract forensic info from EventTranscript.db (Windows Diagnostic Data)
EventTranscriptParser EventTranscriptParser is python based tool to extract forensically useful details from EventTranscript.db (Windows Diagnostic Da
 24 Nov 18, 2022
24 Nov 18, 2022
A Python interface between Earth Engine and xarray for processing weather and climate data
wxee What is wxee? wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data ca
 160 Dec 31, 2022
160 Dec 31, 2022

A data parser for the internal syncing data format used by Fog of World.
A data parser for the internal syncing data format used by Fog of World. The parser is not designed to be a well-coded library with good performance, it is more like a demo for showing the data structure.
 40 Dec 12, 2022
40 Dec 12, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
code for paper "Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning" by Zhongzheng Ren*, Raymond A. Yeh*, Alexander G. Schwing.
Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning Overview This code is for paper: Not All Unlabeled Data are Equa
 22 Nov 23, 2022
22 Nov 23, 2022

Goblyn is a Python tool focused to enumeration and capture of website files metadata.
Goblyn Metadata Enumeration What's Goblyn? Goblyn is a tool focused to enumeration and capture of website files metadata. How it works? Goblyn will se
 46 Nov 22, 2022
46 Nov 22, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022

A fast tool to scan prototype pollution vulnerability
proto A fast tool to scan prototype pollution vulnerability Syntax python3 proto.py -l alive.txt Requirements Selenium Google Chrome Webdriver Note :
 4 Aug 31, 2021
4 Aug 31, 2021
Code and data for the EMNLP 2021 paper "Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts". Coming soon!
ToxiChat Code and data for the EMNLP 2021 paper "Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts". Install depen
 11 Jan 1, 2023
11 Jan 1, 2023
Framework for creating efficient data processing pipelines
Aqueduct Framework for creating efficient data processing pipelines. Contact Feel free to ask questions in telegram t.me/avito-ml Key Features Increas
 137 Dec 29, 2022
137 Dec 29, 2022
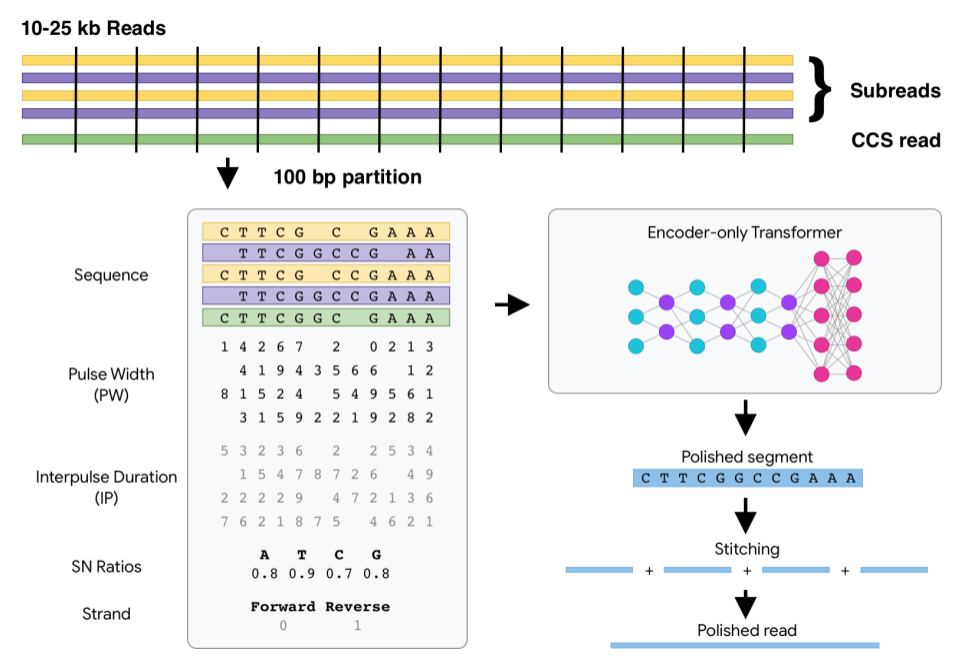
DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS) data.
DeepConsensus DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS)
 149 Dec 19, 2022
149 Dec 19, 2022
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
WarpDrive is a flexible, lightweight, and easy-to-use open-source reinforcement learning (RL) framework that implements end-to-end multi-agent RL on a single GPU (Graphics Processing Unit).
 334 Jan 6, 2023
334 Jan 6, 2023
Applicator Kit for Modo allow you to apply Apple ARKit Face Tracking data from your iPhone or iPad to your characters in Modo.
Applicator Kit for Modo Applicator Kit for Modo allow you to apply Apple ARKit Face Tracking data from your iPhone or iPad with a TrueDepth camera to
 3 Aug 24, 2021
3 Aug 24, 2021

A Red Team tool for exfiltrating sensitive data from Jira tickets.
Jir-thief This Module will connect to Jira's API using an access token, export to a word .doc, and download the Jira issues that the target has access
 82 Dec 12, 2022
82 Dec 12, 2022

Sink is a CLI tool that allows users to synchronize their local folders to their Google Drives. It is similar to the Git CLI and allows fast and reliable syncs with the drive.
Sink is a CLI synchronisation tool that enables a user to synchronise local system files and folders with their Google Drives. It follows a git C
 16 May 29, 2022
16 May 29, 2022

Example scripts for the detection of lanes using the ultra fast lane detection model in ONNX.
Example scripts for the detection of lanes using the ultra fast lane detection model in ONNX.
35 Sep 7, 2022

Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
 167 Dec 27, 2022
167 Dec 27, 2022

A fast python implementation of Ray Tracing in One Weekend using python and Taichi
ray-tracing-one-weekend-taichi A fast python implementation of Ray Tracing in One Weekend using python and Taichi. Taichi is a simple "Domain specific
 157 Dec 26, 2022
157 Dec 26, 2022
Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Official Python wrapper for the Quantel Finance API
Quantel is a powerful financial data and insights API. It provides easy access to world-class financial information. Quantel goes beyond just financial statements, giving users valuable information like insider transactions, major shareholder transactions, share ownership, peers, and so much more.
 47 Oct 16, 2022
47 Oct 16, 2022

Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown.
Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown
 915 Dec 26, 2022
915 Dec 26, 2022

prettymaps - A minimal Python library to draw customized maps from OpenStreetMap data.
A small set of Python functions to draw pretty maps from OpenStreetMap data. Based on osmnx, matplotlib and shapely libraries.
 9k Jan 8, 2023
9k Jan 8, 2023
Auto-updating data to assist in investment to NEPSE
Symbol Ratios Summary Sector LTP Undervalued Bonus % MEGA Strong Commercial Banks 368 5 10 JBBL Strong Development Banks 568 5 10 SIFC Strong Finance
 16 Nov 1, 2022
16 Nov 1, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
Public API client for GETTR, a "non-bias [sic] social network," designed for data archival and analysis.
GoGettr GoGettr is an API client for GETTR, a "non-bias [sic] social network." (We will not reward their domain with a hyperlink.) GoGettr is built an
 72 Dec 14, 2022
72 Dec 14, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022
Code for the KDD 2021 paper 'Filtration Curves for Graph Representation'
Filtration Curves for Graph Representation This repository provides the code from the KDD'21 paper Filtration Curves for Graph Representation. Depende
 16 Oct 16, 2022
16 Oct 16, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Generative Models as a Data Source for Multiview Representation Learning
GenRep Project Page | Paper Generative Models as a Data Source for Multiview Representation Learning Ali Jahanian, Xavier Puig, Yonglong Tian, Phillip
 81 Dec 3, 2022
81 Dec 3, 2022

Import, visualize, and analyze SpiderFoot OSINT data in Neo4j, a graph database
SpiderFoot Neo4j Tools Import, visualize, and analyze SpiderFoot OSINT data in Neo4j, a graph database Step 1: Installation NOTE: This installs the sf
 42 Dec 26, 2022
42 Dec 26, 2022
Low code JSON to extract data in one line
JSON Inline Low code JSON to extract data in one line ENG RU Installation pip install json-inline Usage Rules Modificator Description ?key:value Searc
 12 Mar 9, 2022
12 Mar 9, 2022

the swiss army knife in the hash field. fast, reliable and easy to use
hexxus Hexxus is a fast hash cracking tool which checks more than 30 thousand passwords in under 4 seconds and can crack the following types bcrypt sh
 17 Apr 5, 2022
17 Apr 5, 2022
A Pythonic Data Catalog powered by Ray that brings exabyte-level scalability and fast, ACID-compliant, change-data-capture to your big data workloads.
DeltaCAT DeltaCAT is a Pythonic Data Catalog powered by Ray. Its data storage model allows you to define and manage fast, scalable, ACID-compliant dat
 45 Oct 15, 2022
45 Oct 15, 2022

CPOST is a CLI tool to assist with the proper sizing of Clara Deploy pipelines
CPOST (Clara Pipeline Operator Sizing Tool) Tool to measure resource usage of Clara Platform pipeline operators Cpost is a tool that will help you run
 5 Sep 27, 2021
5 Sep 27, 2021
FPS, fast pluggable server, is a framework designed to compose and run a web-server based on plugins.
FPS, fast pluggable server, is a framework designed to compose and run a web-server based on plugins. It is based on top of fastAPI, uvicorn, typer, and pluggy.
 1 Nov 16, 2021
1 Nov 16, 2021

Data Preparation, Processing, and Visualization for MoVi Data
MoVi-Toolbox Data Preparation, Processing, and Visualization for MoVi Data, https://www.biomotionlab.ca/movi/ MoVi is a large multipurpose dataset of
 51 Nov 27, 2022
51 Nov 27, 2022

Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud This repository contains a reference implementation of our Part-Aware Data Augment
 62 Jan 3, 2023
62 Jan 3, 2023

Official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.
 281 Dec 30, 2022
281 Dec 30, 2022
Official repository with code and data accompanying the NAACL 2021 paper "Hurdles to Progress in Long-form Question Answering" (https://arxiv.org/abs/2103.06332).
Hurdles to Progress in Long-form Question Answering This repository contains the official scripts and datasets accompanying our NAACL 2021 paper, "Hur
 41 Nov 8, 2022
41 Nov 8, 2022
Parametric Contrastive Learning (ICCV2021)
Parametric-Contrastive-Learning This repository contains the implementation code for ICCV2021 paper: Parametric Contrastive Learning (https://arxiv.or
 156 Dec 21, 2022
156 Dec 21, 2022
Nasdaq Cloud Data Service (NCDS) provides a modern and efficient method of delivery for realtime exchange data and other financial information. This repository provides an SDK for developing applications to access the NCDS.
Nasdaq Cloud Data Service (NCDS) Nasdaq Cloud Data Service (NCDS) provides a modern and efficient method of delivery for realtime exchange data and ot
 8 Dec 1, 2022
8 Dec 1, 2022
Using python-binance to provide websocket data to freqtrade
The goal of this project is to provide an alternative way to get realtime data from Binance and use it in freqtrade despite the exchange used. It also uses talipp for computing
 58 Jan 1, 2023
58 Jan 1, 2023
Fast as FUCK nvim completion. SQLite, concurrent scheduler, hundreds of hours of optimization.
Fast as FUCK nvim completion. SQLite, concurrent scheduler, hundreds of hours of optimization.
 2.8k Jan 5, 2023
2.8k Jan 5, 2023
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

Script de monitoramento de telemetria para missões espaciais, cansat e foguetemodelismo.
Aeroespace_GroundStation Script de monitoramento de telemetria para missões espaciais, cansat e foguetemodelismo. Imagem 1 - Dashboard realizando moni
 5 Nov 27, 2022
5 Nov 27, 2022
Home Assistant integration for spanish electrical data providers (e.g., datadis)
homeassistant-edata Esta integración para Home Assistant te permite seguir de un vistazo tus consumos y máximas potencias alcanzadas. Para ello, se ap
 163 Jan 5, 2023
163 Jan 5, 2023
This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, reading data from PubSub.
Sample streaming Dataflow pipeline written in Python This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, readin
 9 Mar 18, 2022
9 Mar 18, 2022
SlotRefine: A Fast Non-Autoregressive Model forJoint Intent Detection and Slot Filling
SlotRefine: A Fast Non-Autoregressive Model for Joint Intent Detection and Slot Filling Reference Main paper to be cited (Di Wu et al., 2020) @article
 34 Nov 3, 2022
34 Nov 3, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
 65 Sep 13, 2022
65 Sep 13, 2022

Python ELT Studio, an application for building ELT (and ETL) data flows.
The Python Extract, Load, Transform Studio is an application for performing ELT (and ETL) tasks. Under the hood the application consists of a two parts.
 55 Nov 18, 2022
55 Nov 18, 2022

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022
Test django schema and data migrations, including migrations' order and best practices.
django-test-migrations Features Allows to test django schema and data migrations Allows to test both forward and rollback migrations Allows to test th
 382 Dec 27, 2022
382 Dec 27, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
235 Dec 22, 2022

A light-weight image labelling tool for Python designed for creating segmentation data sets.
An image labelling tool for creating segmentation data sets, for Django and Flask.
 117 Nov 21, 2022
117 Nov 21, 2022
A library for fast import of Windows NT Registry(REGF) into Elasticsearch.
A library for fast import of Windows NT Registry(REGF) into Elasticsearch.
 3 Apr 1, 2022
3 Apr 1, 2022
Download history data from binance and save to dataframe or csv file
Binance history data downloader Download history data from binance and save to dataframe or csv file
 10 Dec 2, 2022
10 Dec 2, 2022

Slack bot for monitoring your Metaflow flows!
Metaflowbot - Slack Bot for your Metaflow flows! Metaflowbot makes it fun and easy to monitor your Metaflow runs, past and present. Imagine starting a
 21 Dec 7, 2022
21 Dec 7, 2022
Creates a C array from a hex-string or a stream of binary data.
hex2array-c Creates a C array from a hex-string. Usage Usage: python3 hex2array_c.py HEX_STRING [-h|--help] Use '-' to read the hex string from STDIN.
 3 Nov 24, 2022
3 Nov 24, 2022
Piccolo - A fast, user friendly ORM and query builder which supports asyncio.
A fast, user friendly ORM and query builder which supports asyncio.
 919 Jan 4, 2023
919 Jan 4, 2023
Implementation of "Selection via Proxy: Efficient Data Selection for Deep Learning" from ICLR 2020.
Selection via Proxy: Efficient Data Selection for Deep Learning This repository contains a refactored implementation of "Selection via Proxy: Efficien
 70 Nov 16, 2022
70 Nov 16, 2022
Data from "HateCheck: Functional Tests for Hate Speech Detection Models" (Röttger et al., ACL 2021)
In this repo, you can find the data from our ACL 2021 paper "HateCheck: Functional Tests for Hate Speech Detection Models". "test_suite_cases.csv" con
 43 Nov 11, 2022
43 Nov 11, 2022

A robust pointcloud registration pipeline based on correlation.
PHASER: A Robust and Correspondence-Free Global Pointcloud Registration Ubuntu 18.04+ROS Melodic: Overview Pointcloud registration using correspondenc
 101 Dec 1, 2022
101 Dec 1, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

Amazon Scraper: A command-line tool for scraping Amazon product data
Amazon Product Scraper: 2021 Description A command-line tool for scraping Amazon product data to CSV or JSON format(s). Requirements Python 3 pip3 Ins
 49 Nov 15, 2021
49 Nov 15, 2021

A Data Annotation Tool for Semantic Segmentation, Object Detection and Lane Line Detection.(In Development Stage)
Data-Annotation-Tool How to Run this Tool? To run this software, follow the steps: git clone https://github.com/Autonomous-Car-Project/Data-Annotation
 13 Aug 18, 2022
13 Aug 18, 2022
Scraping Thailand COVID-19 data from the DDC's tableau dashboard
Scraping COVID-19 data from DDC Dashboard Scraping Thailand COVID-19 data from the DDC's tableau dashboard. Data is updated at 07:30 and 08:00 daily.
 5 Jan 4, 2022
5 Jan 4, 2022
DenseClus is a Python module for clustering mixed type data using UMAP and HDBSCAN
DenseClus is a Python module for clustering mixed type data using UMAP and HDBSCAN. Allowing for both categorical and numerical data, DenseClus makes it possible to incorporate all features in clustering.
 53 Dec 8, 2022
53 Dec 8, 2022
ml4h is a toolkit for machine learning on clinical data of all kinds including genetics, labs, imaging, clinical notes, and more
ml4h is a toolkit for machine learning on clinical data of all kinds including genetics, labs, imaging, clinical notes, and more
 65 Dec 20, 2022
65 Dec 20, 2022
This repository is home to the Optimus data transformation plugins for various data processing needs.
Transformers Optimus's transformation plugins are implementations of Task and Hook interfaces that allows execution of arbitrary jobs in optimus. To i
 37 Dec 14, 2022
37 Dec 14, 2022

Minimal Ethereum fee data viewer for the terminal, contained in a single python script.
Minimal Ethereum fee data viewer for the terminal, contained in a single python script. Connects to your node and displays some metrics in real-time.
 48 Dec 5, 2022
48 Dec 5, 2022

This solution helps you deploy Data Lake Infrastructure on AWS using CDK Pipelines.
CDK Pipelines for Data Lake Infrastructure Deployment This solution helps you deploy data lake infrastructure on AWS using CDK Pipelines. This is base
 66 Nov 23, 2022
66 Nov 23, 2022

Google Project: Search and auto-complete sentences within given input text files, manipulating data with complex data-structures.
Auto-Complete Google Project In this project there is an implementation for one feature of Google's search engines - AutoComplete. Autocomplete, or wo
 10 Jun 20, 2022
10 Jun 20, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
 37 Dec 4, 2022
37 Dec 4, 2022

FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
FPGA & FreeNet Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification by Zhuo Zheng, Yanfei Zhong, Ailong M
 92 Jan 3, 2023
92 Jan 3, 2023

Data and Code for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning"
Introduction Code and data for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning". We cons
 81 Dec 27, 2022
81 Dec 27, 2022
OpenGAN: Open-Set Recognition via Open Data Generation
OpenGAN: Open-Set Recognition via Open Data Generation ICCV 2021 (oral) Real-world machine learning systems need to analyze novel testing data that di
 90 Jan 6, 2023
90 Jan 6, 2023
Finetuning Pipeline
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022
Code release for our paper, "SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo"
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo Thomas Kollar, Michael Laskey, Kevin Stone, Brijen Thananjeyan
 68 Dec 14, 2022
68 Dec 14, 2022
MODALS: Modality-agnostic Automated Data Augmentation in the Latent Space
Update (20 Jan 2020): MODALS on text data is avialable MODALS MODALS: Modality-agnostic Automated Data Augmentation in the Latent Space Table of Conte
 38 Dec 15, 2022
38 Dec 15, 2022
Extract Thailand COVID-19 Cluster data from daily briefing pdf.
Thailand COVID-19 Cluster Data Extraction About Extract Clusters from Thailand Daily COVID-19 briefing PDF Download latest data Here. Data will be upd
5 Sep 27, 2021
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022

Evidently helps analyze machine learning models during validation or production monitoring
Evidently helps analyze machine learning models during validation or production monitoring. The tool generates interactive visual reports and JSON profiles from pandas DataFrame or csv files. Currently 6 reports are available.
 3.1k Jan 7, 2023
3.1k Jan 7, 2023
Collect super-resolution related papers, data, repositories
Collect super-resolution related papers, data, repositories
 1.7k Jan 3, 2023
1.7k Jan 3, 2023
Use this script to track the gains of cryptocurrencies using historical data and display it on a super-imposed chart in order to find the highest performing cryptocurrencies historically
crypto-performance-tracker Use this script to track the gains of cryptocurrencies using historical data and display it on a super-imposed chart in ord
 25 Aug 31, 2022
25 Aug 31, 2022
Automated data scraper for Thailand COVID-19 data
The Researcher COVID data Automated data scraper for Thailand COVID-19 data Accessing the Data 1st Dose Provincial Vaccination Data 2nd Dose Provincia
 31 Apr 17, 2022
31 Apr 17, 2022
GlokyPortScannar is a really fast tool to scan TCP ports implemented in Python.
GlokyPortScannar is a really fast tool to scan TCP ports implemented in Python. Installation: This program requires Python 3.9. Linux
 5 Jun 25, 2022
5 Jun 25, 2022

Random Erasing Data Augmentation. Experiments on CIFAR10, CIFAR100 and Fashion-MNIST
Random Erasing Data Augmentation =============================================================== black white random This code has the source code for
 654 Dec 26, 2022
654 Dec 26, 2022
This repository contains the source code and data for reproducing results of Deep Continuous Clustering paper
Deep Continuous Clustering Introduction This is a Pytorch implementation of the DCC algorithms presented in the following paper (paper): Sohil Atul Sh
 197 Nov 29, 2022
197 Nov 29, 2022
A curated list of amazingly awesome Cybersecurity datasets
A curated list of amazingly awesome Cybersecurity datasets
 758 Dec 28, 2022
758 Dec 28, 2022
Easily turn single threaded command line applications into a fast, multi-threaded application with CIDR and glob support.
Easily turn single threaded command line applications into a fast, multi-threaded application with CIDR and glob support.
 1k Jan 7, 2023
1k Jan 7, 2023

A python application for manipulating pandas data frames from the comfort of your web browser
A python application for manipulating pandas data frames from the comfort of your web browser. Data flows are represented as a Directed Acyclic Graph, and nodes can be ran individually as the user sees fit.
161 Jan 4, 2023