2565 Repositories
Python genetic-data Libraries

FairLens is an open source Python library for automatically discovering bias and measuring fairness in data
FairLens FairLens is an open source Python library for automatically discovering bias and measuring fairness in data. The package can be used to quick
 69 Dec 15, 2022
69 Dec 15, 2022
This is a curated list of medical data for machine learning
Medical Data for Machine Learning This is a curated list of medical data for machine learning. This list is provided for informational purposes only,
 5.4k Dec 26, 2022
5.4k Dec 26, 2022
Segment axon and myelin from microscopy data using deep learning
Segment axon and myelin from microscopy data using deep learning. Written in Python. Using the TensorFlow framework. Based on a convolutional neural network architecture. Pixels are classified as either axon, myelin or background.
 103 Nov 29, 2022
103 Nov 29, 2022
Equipped customers with insights about their EVs Hourly energy consumption and helped predict future charging behavior using LSTM model
Equipped customers with insights about their EVs Hourly energy consumption and helped predict future charging behavior using LSTM model. Designed sample dashboard with insights and recommendation for customers.
 2 Apr 7, 2022
2 Apr 7, 2022
A Celery application to collect data, download media and extract information from social media APIs
Project IBEX A Celery application to collect data, download media and extract information from social media APIs. Requirements You must have a Redis D
 4 Dec 15, 2022
4 Dec 15, 2022
Data processing with Pandas.
Processing-data-with-python This is a simple example showing how to use Pandas to create a dataframe and the processing data with python. The jupyter
 1 Jan 23, 2022
1 Jan 23, 2022
Nobel Data Analysis
Nobel_Data_Analysis This project is for analyzing a set of data about people who have won the Nobel Prize in different fields and different countries
 1 Jan 24, 2022
1 Jan 24, 2022
Investigating EV charging data
Investigating EV charging data Introduction: Got an opportunity to work with a home monitoring technology company over the last 6 months whose goal wa
2 Apr 7, 2022
Analyze the Gravitational wave data stored at LIGO/VIRGO observatories
Gravitational-Wave-Analysis This project showcases how to analyze the Gravitational wave data stored at LIGO/VIRGO observatories, using Python program
 1 Jan 23, 2022
1 Jan 23, 2022
This python script allows you to manipulate the audience data from Sl.ido surveys
Slido-Automated-VoteBot This python script allows you to manipulate the audience data from Sl.ido surveys Since Slido blocks interference from automat
 1 Jan 24, 2022
1 Jan 24, 2022
Cormen-Lib - An academic tool for data structures and algorithms courses
The Cormen-lib module is an insular data structures and algorithms library based on the Thomas H. Cormen's Introduction to Algorithms Third Edition. This library was made specifically for administering and grading assignments related to data structure and algorithms in computer science.
 12 Aug 18, 2022
12 Aug 18, 2022

Collapse by Conditioning: Training Class-conditional GANs with Limited Data
Collapse by Conditioning: Training Class-conditional GANs with Limited Data Moha
 33 Dec 6, 2022
33 Dec 6, 2022
GoogleFormSpammer - A simple CLI script to spam Google Forms used by Crypto Wallet scammers to collect stolen data
GoogleFormSpammer - A simple CLI script to spam Google Forms used by Crypto Wallet scammers to collect stolen data
 14 Dec 17, 2022
14 Dec 17, 2022
Implement the Perspective open source code in preparation for data visualization
Task Overview | Installation Instructions | Link to Module 2 Introduction Experience Technology at JP Morgan Chase Try out what real work is like in t
 1 Jan 23, 2022
1 Jan 23, 2022
PostQF is a user-friendly Postfix queue data filter which operates on data produced by postqueue -j.
PostQF Copyright © 2022 Ralph Seichter PostQF is a user-friendly Postfix queue data filter which operates on data produced by postqueue -j. See the ma
 11 Nov 24, 2022
11 Nov 24, 2022
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences. Copula and functional Principle Component Analysis (fPCA) are statistical models that allow these properties to be simulated (Joe 2014). As such, copula generated data have shown potential to improve the generalization of machine learning (ML) emulators (Meyer et al. 2021) or anonymize real-data datasets (Patki et al. 2016).
 32 Dec 20, 2022
32 Dec 20, 2022
An easy-to-use feature store
A feature store is a data storage system for data science and machine-learning. It can store raw data and also transformed features, which can be fed straight into an ML model or training script.
 48 Dec 9, 2022
48 Dec 9, 2022
This repository contains FEDOT - an open-source framework for automated modeling and machine learning (AutoML)
package tests docs license stats support This repository contains FEDOT - an open-source framework for automated modeling and machine learning (AutoML
 482 Dec 26, 2022
482 Dec 26, 2022
Learn Basic to advanced level Data visualisation techniques from this Repository
Data visualisation Hey, You can learn Basic to advanced level Data visualisation techniques from this Repository. Data visualization is the graphic re
 16 Jan 3, 2023
16 Jan 3, 2023

Create charts with Python in a very similar way to creating charts using Chart.js
Create charts with Python in a very similar way to creating charts using Chart.js. The charts created are fully configurable, interactive and modular and are displayed directly in the output of the the cells of your jupyter notebook environment.
 68 Dec 8, 2022
68 Dec 8, 2022

visualize_ML is a python package made to visualize some of the steps involved while dealing with a Machine Learning problem
visualize_ML visualize_ML is a python package made to visualize some of the steps involved while dealing with a Machine Learning problem. It is build
 164 Dec 12, 2022
164 Dec 12, 2022
Equibles Stocks API for Python
Equibles Stocks API for Python Requirements. Python 2.7 and 3.4+ Installation & Usage pip install If the python package is hosted on Github, you can i
 3 Apr 15, 2022
3 Apr 15, 2022
A server and client for passing data between computercraft computers/turtles across dimensions or even servers.
ccserver A server and client for passing data between computercraft computers/turtles across dimensions or even servers. pastebin get zUnE5N0v client
 1 Jan 22, 2022
1 Jan 22, 2022
Feature engineering and machine learning: together at last
Feature engineering and machine learning: together at last! Lambdo is a workflow engine which significantly simplifies data analysis by unifying featu
 14 Sep 15, 2022
14 Sep 15, 2022
INFO-H515 - Big Data Scalable Analytics
INFO-H515 - Big Data Scalable Analytics Jacopo De Stefani, Giovanni Buroni, Théo Verhelst and Gianluca Bontempi - Machine Learning Group Exercise clas
 58 Dec 11, 2022
58 Dec 11, 2022
BioPy is a collection (in-progress) of biologically-inspired algorithms written in Python
BioPy is a collection (in-progress) of biologically-inspired algorithms written in Python. Some of the algorithms included are mor
 40 Aug 26, 2022
40 Aug 26, 2022
This module is used to create Convolutional AutoEncoders for Variational Data Assimilation
VarDACAE This module is used to create Convolutional AutoEncoders for Variational Data Assimilation. A user can define, create and train an AE for Dat
 23 Dec 16, 2022
23 Dec 16, 2022
Tutorials, examples, collections, and everything else that falls into the categories: pattern classification, machine learning, and data mining
**Tutorials, examples, collections, and everything else that falls into the categories: pattern classification, machine learning, and data mining.** S
 4k Dec 30, 2022
4k Dec 30, 2022
Perform sentiment analysis on textual data that people generally post on websites like social networks and movie review sites.
Sentiment Analyzer The goal of this project is to perform sentiment analysis on textual data that people generally post on websites like social networ
 53 Mar 1, 2022
53 Mar 1, 2022

Dive into Machine Learning
Dive into Machine Learning Hi there! You might find this guide helpful if: You know Python or you're learning it 🐍 You're new to Machine Learning You
 11.1k Jan 3, 2023
11.1k Jan 3, 2023
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow with breakpoints + real-time visualization of the data flowing through the computational graph
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow (Google's Deep Learning framework) with breakpoints + real-time visualization of the data flowing through the computational graph.
 1.4k Dec 15, 2022
1.4k Dec 15, 2022
Python for Data Analysis, 2nd Edition
Python for Data Analysis, 2nd Edition Materials and IPython notebooks for "Python for Data Analysis" by Wes McKinney, published by O'Reilly Media Buy
 18.6k Jan 8, 2023
18.6k Jan 8, 2023
INF42 - Topological Data Analysis
TDA INF421(Conception et analyse d'algorithmes) Projet : Topological Data Analysis SphereMin Etant donné un nuage des points, ce programme contient de
 2 Jan 7, 2022
2 Jan 7, 2022

Demonstrate the breadth and depth of your data science skills by earning all of the Databricks Data Scientist credentials
Data Scientist Learning Plan Demonstrate the breadth and depth of your data science skills by earning all of the Databricks Data Scientist credentials
 27 Nov 1, 2022
27 Nov 1, 2022

sequitur is a library that lets you create and train an autoencoder for sequential data in just two lines of code
sequitur sequitur is a library that lets you create and train an autoencoder for sequential data in just two lines of code. It implements three differ
 305 Dec 21, 2022
305 Dec 21, 2022

Google AI Open Images - Object Detection Track: Open Solution
Google AI Open Images - Object Detection Track: Open Solution This is an open solution to the Google AI Open Images - Object Detection Track 😃 More c
 46 Jun 22, 2022
46 Jun 22, 2022

TGS Salt Identification Challenge
TGS Salt Identification Challenge This is an open solution to the TGS Salt Identification Challenge. Note Unfortunately, we can no longer provide supp
 123 Nov 4, 2022
123 Nov 4, 2022

Airbus Ship Detection Challenge
Airbus Ship Detection Challenge This is an open solution to the Airbus Ship Detection Challenge. Our goals We are building entirely open solution to t
55 Nov 29, 2022
This is an analysis and prediction project for house prices in King County, USA based on certain features of the house
This is a project for analysis and estimation of House Prices in King County USA The .csv file contains the data of the house and the .ipynb file con
 1 Jan 21, 2022
1 Jan 21, 2022
Python Sreamlit Duplicate Records Finder Remover
Python-Sreamlit-Duplicate-Records-Finder-Remover Streamlit is an open-source Python library that makes it easy to create and share beautiful, custom w
 1 Jan 21, 2022
1 Jan 21, 2022
Program that predicts the NBA mvp based on data from previous years.
NBA MVP Predictor A machine learning model using RandomForest Regression that predicts NBA MVP's using player data. Explore the docs » View Demo · Rep
 1 Jan 21, 2022
1 Jan 21, 2022
Simple Translator in Python
Simple Translator in Python Project Description: In this project, we'll be making a very simple translator in Python using some libraries. Requirement
 3 Jan 23, 2022
3 Jan 23, 2022

Open solution to the Toxic Comment Classification Challenge
Starter code: Kaggle Toxic Comment Classification Challenge More competitions 🎇 Check collection of public projects 🎁 , where you can find multiple
153 Jun 22, 2022
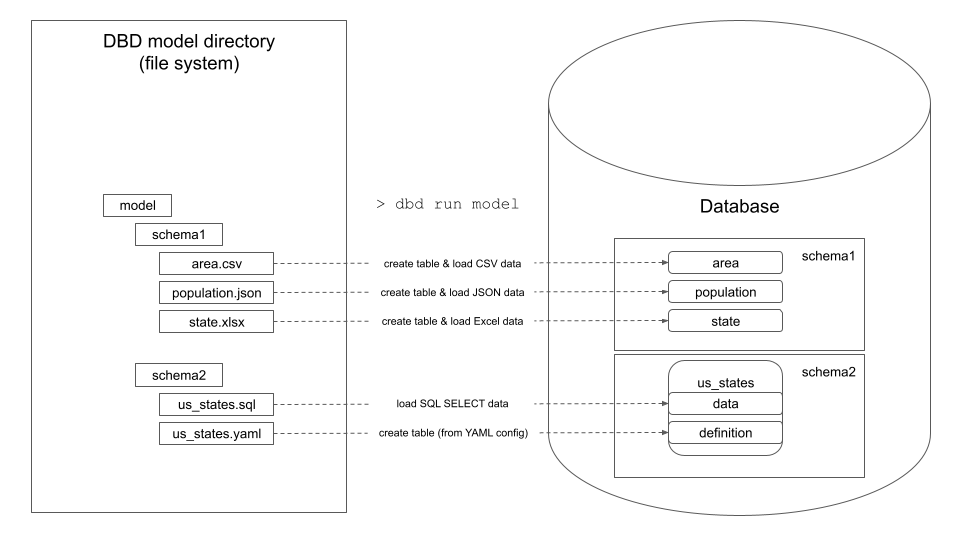
dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL databases.
dbd: database prototyping tool dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL d
 47 Dec 7, 2022
47 Dec 7, 2022
Data-driven Computer Science UoB
COMS20011_2021 Data-driven Computer Science UoB Staff Laurence Aitchison [[email protected]] (unit director) Majid Mirmehdi [m.mirmehdi
 6 May 16, 2022
6 May 16, 2022
Colab notebook and additional materials for Python-driven analysis of redlining data in Philadelphia
RedliningExploration The Google Colaboratory file contained in this repository contains work inspired by a project on educational inequality in the Ph
 1 Jan 20, 2022
1 Jan 20, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022

Airborne magnetic data of the Osborne Mine and Lightning Creek sill complex, Australia
Osborne Mine, Australia - Airborne total-field magnetic anomaly This is a section of a survey acquired in 1990 by the Queensland Government, Australia
 1 Jan 21, 2022
1 Jan 21, 2022
This a classic fintech problem that introduces real life difficulties such as data imbalance. Check out the notebook to find out more!
Credit Card Fraud Detection Introduction Online transactions have become a crucial part of any business over the years. Many of those transactions use
 0 Jan 20, 2022
0 Jan 20, 2022

FFCV: Fast Forward Computer Vision (and other ML workloads!)
Fast Forward Computer Vision: train models at a fraction of the cost with accele
 2.3k Jan 3, 2023
2.3k Jan 3, 2023
ServiceX Transformer that converts flat ROOT ntuples into columnwise data
ServiceX_Uproot_Transformer ServiceX Transformer that converts flat ROOT ntuples into columnwise data Usage You can invoke the transformer from the co
 0 Jan 20, 2022
0 Jan 20, 2022
This repo is dedicated to the data extraction and manipulation of the World Bank's database called STEP.
Overview Welcome to the Step-X repository. This repo is dedicated to the data extraction and manipulation of the World Bank's database called STEP. Be
 0 Jan 20, 2022
0 Jan 20, 2022
ECLARE: Extreme Classification with Label Graph Correlations
ECLARE ECLARE: Extreme Classification with Label Graph Correlations @InProceedings{Mittal21b, author = "Mittal, A. and Sachdeva, N. and Agrawal
 35 Nov 6, 2022
35 Nov 6, 2022
CO2Ampel - This RaspberryPi project uses weather data to estimate the share of renewable energy in the power grid
CO2Ampel This RaspberryPi project uses weather data to estimate the share of ren
 4 Jan 19, 2022
4 Jan 19, 2022

The scope of this project will be to build a data ware house on Google Cloud Platform that will help answer common business questions as well as powering dashboards
The scope of this project will be to build a data ware house on Google Cloud Platform that will help answer common business questions as well as powering dashboards.
 2 Jan 20, 2022
2 Jan 20, 2022
RedlineSpam - Python tool to spam Redline Infostealer panels with legit looking data
RedlineSpam Python tool to spam Redline Infostealer panels with legit looking da
 4 Jan 27, 2022
4 Jan 27, 2022

PrimaryBid - Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift
Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift This project is composed of two parts: Part1 and Part2
 1 Jan 19, 2022
1 Jan 19, 2022
Conditional Generative Adversarial Networks (CGAN) for Mobility Data Fusion
This code implements the paper, Kim et al. (2021). Imputing Qualitative Attributes for Trip Chains Extracted from Smart Card Data Using a Conditional Generative Adversarial Network. Transportation Research Part C. Under Review.
 2 Feb 3, 2022
2 Feb 3, 2022
Import, connect and transform data into Excel
xlwings_query Import, connect and transform data into Excel. Description The concept is to apply data transformations to a main query object. When the
 1 Jan 19, 2022
1 Jan 19, 2022
Code for Private Recommender Systems: How Can Users Build Their Own Fair Recommender Systems without Log Data? (SDM 2022)
Private Recommender Systems: How Can Users Build Their Own Fair Recommender Systems without Log Data? (SDM 2022) We consider how a user of a web servi
 20 Aug 21, 2022
20 Aug 21, 2022
A combination between python-flask, that fetch and send data from league client during champion select thanks to LCU
A combination between python-flask, that fetch data and send from league client during champion select thanks to LCU and compare picked champs to the gamesDataBase that we need to collect using my other python script and then send the games result to localhost:5000/members that will be read by electron-reactJS script to present the results as a GUI on browser (localhost:5000)
 1 Jan 19, 2022
1 Jan 19, 2022
RedisJSON - a JSON data type for Redis
RedisJSON is a Redis module that implements ECMA-404 The JSON Data Interchange Standard as a native data type. It allows storing, updating and fetching JSON values from Redis keys (documents).
 3.4k Dec 29, 2022
3.4k Dec 29, 2022

100 Days of Code Learning program to keep a habit of coding daily and learn things at your own pace with help from our remote community.
100 Days of Code Learning program to keep a habit of coding daily and learn things at your own pace with help from our remote community.
 41 Dec 30, 2022
41 Dec 30, 2022

Elkeid HUB - A rule/event processing engine maintained by the Elkeid Team that supports streaming/offline data processing
Elkeid HUB - A rule/event processing engine maintained by the Elkeid Team that supports streaming/offline data processing
 61 Dec 29, 2022
61 Dec 29, 2022

Beta Shapley: a Unified and Noise-reduced Data Valuation Framework for Machine Learning
Beta Shapley: a Unified and Noise-reduced Data Valuation Framework for Machine Learning This repository provides an implementation of the paper Beta S
 28 Nov 10, 2022
28 Nov 10, 2022
Used Logistic Regression, Random Forest, and XGBoost to predict the outcome of Search & Destroy games from the Call of Duty World League for the 2018 and 2019 seasons.
Call of Duty World League: Search & Destroy Outcome Predictions Growing up as an avid Call of Duty player, I was always curious about what factors led
 2 Jan 18, 2022
2 Jan 18, 2022
converts nominal survey data into a numerical value based on a dictionary lookup.
SWAP RATE Converts nominal survey data into a numerical values based on a dictionary lookup. It allows the user to switch nominal scale data from text
 1 Jan 18, 2022
1 Jan 18, 2022
This is a place where I'm playing around with pandas to analyze data in a csv/excel file.
pandas-csv-excel-analysis This is a place where I'm playing around with pandas to analyze data in a csv/excel file. 0-start A very simple cheat sheet
 3 Oct 5, 2022
3 Oct 5, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
Convert any binary data to a PNG image file and vice versa.
What is PngBin? The name PngBin comes from an image format file extension PNG (Portable Network Graphics) and the word Binary. An image produced by Pn
 87 Dec 22, 2022
87 Dec 22, 2022
PyGRANSO: A PyTorch-enabled port of GRANSO with auto-differentiation
PyGRANSO PyGRANSO: A PyTorch-enabled port of GRANSO with auto-differentiation Please check https://ncvx.org/PyGRANSO for detailed instructions (introd
 26 Nov 16, 2022
26 Nov 16, 2022
This project is for finding a solution to use Security Onion Elastic data with Jupyter Notebooks.
This project is for finding a solution to use Security Onion Elastic data with Jupyter Notebooks. The goal is to successfully use this notebook project below with Security Onion for beacon detection capabilities.
 4 Jun 8, 2022
4 Jun 8, 2022
Latent Network Models to Account for Noisy, Multiply-Reported Social Network Data
VIMuRe Latent Network Models to Account for Noisy, Multiply-Reported Social Network Data. If you use this code please cite this article (preprint). De
 6 Dec 15, 2022
6 Dec 15, 2022

Magic: The Gathering Arena draft tool that utilizes 17Lands data
MTGA_Draft_17Lands Magic: The Gathering Arena draft tool that utilizes 17Lands data. Steps for Windows Step 1: Download and unzip the MTGA_Draft_17Lan
 41 Dec 31, 2022
41 Dec 31, 2022
Exploring the Top ML and DL GitHub Repositories
This repository contains my work related to my project where I scraped data on the most popular machine learning and deep learning GitHub repositories in order to further visualize and analyze it.
 17 Aug 21, 2022
17 Aug 21, 2022
[ACM MM 2021] Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation) [arXiv] [paper] @inproceedings{hou2021multiview, title={Multiview
 27 Dec 13, 2022
27 Dec 13, 2022
Binance harvester - A Python 3 script to harvest data from the Binance socket stream and calculate popular TA indicators and produce lists of top trending coins
Binance harvester - A Python 3 script to harvest data from the Binance socket stream and calculate popular TA indicators and produce lists of top trending coins
 68 Oct 8, 2022
68 Oct 8, 2022
Dex-scrapper - Hobby project for scrapping dex data on VeChain
Folders /zumo_abis # abi extracted from zumo repo /zumo_pools # runtime e
 3 Jan 20, 2022
3 Jan 20, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022
Data collection, enhancement, and metrics calculation.
l3_data_collection Data collection, enhancement, and metrics calculation. Summary Repository containing code for QuantDAO's JDT data collection task.
 3 Dec 23, 2022
3 Dec 23, 2022

Data App Performance Tests
Data App Performance Tests My hypothesis is that The different architectures of
 6 Dec 14, 2022
6 Dec 14, 2022
Implementation of Axial attention - attending to multi-dimensional data efficiently
Axial Attention Implementation of Axial attention in Pytorch. A simple but powerful technique to attend to multi-dimensional data efficiently. It has
 250 Dec 25, 2022
250 Dec 25, 2022

learn python in 100 days, a simple step could be follow from beginner to master of every aspect of python programming and project also include side project which you can use as demo project for your personal portfolio
learn python in 100 days, a simple step could be follow from beginner to master of every aspect of python programming and project also include side project which you can use as demo project for your personal portfolio
 6 Nov 5, 2022
6 Nov 5, 2022
Completed task 1 and task 2 at LetsGrowMore as a data science intern.
LetsGrowMore-Internship Completed task 1 and task 2 at LetsGrowMore as a data science intern. Task 1- Task 2- Creating a Decision Tree classifier and
 1 Jan 16, 2022
1 Jan 16, 2022
100 Days of Code The Complete Python Pro Bootcamp for 2022
100-Day-With-Python 100 Days of Code - The Complete Python Pro Bootcamp for 2022. In this course, I spend with python language over 100 days, and I up
 8 Jun 22, 2022
8 Jun 22, 2022
Python data processing, analysis, visualization, and data operations
Python This is a Python data processing, analysis, visualization and data operations of the source code warehouse, book ISBN: 9787115527592 Descriptio
 1 Jan 16, 2022
1 Jan 16, 2022
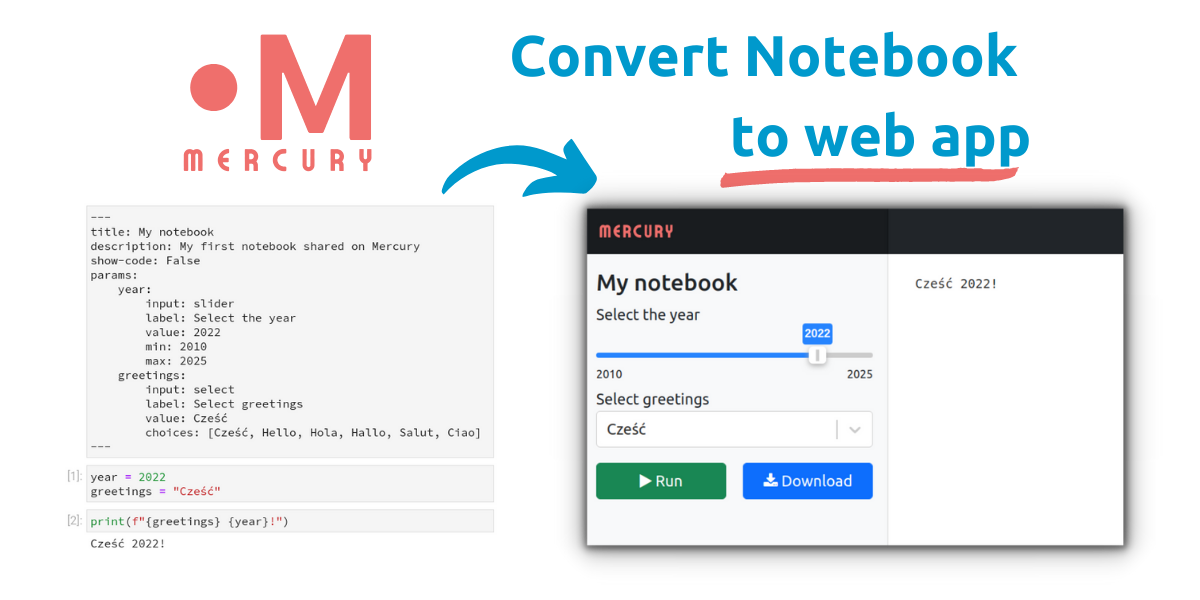
Mercury: easily convert Python notebook to web app and share with others
Mercury Share your Python notebooks with others Easily convert your Python notebooks into interactive web apps by adding parameters in YAML. Simply ad
 2.2k Dec 27, 2022
2.2k Dec 27, 2022
NW 2022 Hackathon Project by Angelique Clara Hanzel, Aryan Sonik, Damien Fung, Ramit Brata Biswas
Spiral-Data-Visualizer NW 2022 Hackathon Project by Angelique Clara Hanzell, Aryan Sonik, Damien Fung, Ramit Brata Biswas Description This project vis
 2 Jan 16, 2022
2 Jan 16, 2022

Dimension Reduced Turbulent Flow Data From Deep Vector Quantizers
Dimension Reduced Turbulent Flow Data From Deep Vector Quantizers This is an implementation of A Physics-Informed Vector Quantized Autoencoder for Dat
 3 Sep 12, 2022
3 Sep 12, 2022
This repository gives an example on how to preprocess the data of the HECKTOR challenge
HECKTOR 2021 challenge This repository gives an example on how to preprocess the data of the HECKTOR challenge. Any other preprocessing is welcomed an
 56 Dec 1, 2022
56 Dec 1, 2022
Code and data (Incidents Dataset) for ECCV 2020 Paper "Detecting natural disasters, damage, and incidents in the wild".
Incidents Dataset See the following pages for more details: Project page: IncidentsDataset.csail.mit.edu. ECCV 2020 Paper "Detecting natural disasters
 67 Dec 27, 2022
67 Dec 27, 2022
This repo generates the training data and the model for Morpheus-Deblend
Morpheus-Deblend This repo generates the training data and the model for Morpheus-Deblend. This is the active development repo for the project and as
 2 Apr 18, 2022
2 Apr 18, 2022
Deeplearning project at The Technological University of Denmark (DTU) about Neural ODEs for finding dynamics in ordinary differential equations and real world time series data
Authors Marcus Lenler Garsdal, [email protected] Valdemar Søgaard, [email protected] Simon Moe Sørensen, [email protected] Introduction This repo contains the
 6 Sep 5, 2022
6 Sep 5, 2022
Accurate identification of bacteriophages from metagenomic data using Transformer
PhaMer is a python library for identifying bacteriophages from metagenomic data. PhaMer is based on a Transorfer model and rely on protein-based vocab
 9 Nov 30, 2022
9 Nov 30, 2022

Fully Adaptive Bayesian Algorithm for Data Analysis (FABADA) is a new approach of noise reduction methods. In this repository is shown the package developed for this new method based on \citepaper.
Fully Adaptive Bayesian Algorithm for Data Analysis FABADA FABADA is a novel non-parametric noise reduction technique which arise from the point of vi
 18 Oct 20, 2022
18 Oct 20, 2022

Data-driven reduced order modeling for nonlinear dynamical systems
SSMLearn Data-driven Reduced Order Models for Nonlinear Dynamical Systems This package perform data-driven identification of reduced order model based
 27 Dec 13, 2022
27 Dec 13, 2022

A curated list of awesome open source libraries to deploy, monitor, version and scale your machine learning
Awesome production machine learning This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, versi
 12.9k Jan 4, 2023
12.9k Jan 4, 2023
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023

An awesome Data Science repository to learn and apply for real world problems.
AWESOME DATA SCIENCE An open source Data Science repository to learn and apply towards solving real world problems. This is a shortcut path to start s
 20.3k Jan 9, 2023
20.3k Jan 9, 2023