2010 Repositories
Python long-text-token-classification Libraries
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022
Show Rubygems description and annotate your code right from Sublime Text.
Gem Description for Sublime Text Show Rubygems description and annotate your code. Just mouse over your Gemfile's gem definitions to show the popup. s
 2 Dec 19, 2022
2 Dec 19, 2022
🥀 Find the start of the token !
Discord Token Finder Find half of your target's token with just their ID. Install 🔧 pip install -r requeriments.txt Gui Usage 💻 Go to Discord Setti
 2 Dec 22, 2021
2 Dec 22, 2021
Make an audio file (really) long-winded
longwind Make an audio file (really) long-winded Daily repetitions are an illusion anyway.
 2 Sep 12, 2022
2 Sep 12, 2022
Text-Adventure-Game [Open Source] A group project by the Python TASK Force
Text-Adventure-Game [Open Source] A group project by the Python TASK Force
 2 Sep 17, 2021
2 Sep 17, 2021
Semester long, web application project for CSCI 4370/6370 (Database Management)
Database_Project Prototype ideas for website: Computer Science library (Sells books, products, etc.) Code editor Graph visualizer / creator (can save
 4 Feb 17, 2022
4 Feb 17, 2022

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 829 Jan 7, 2023
829 Jan 7, 2023

Synthetic Scene Text from 3D Engines
Introduction UnrealText is a project that synthesizes scene text images using 3D graphics engine. This repository accompanies our paper: UnrealText: S
 215 Dec 29, 2022
215 Dec 29, 2022
The code written during my Bachelor Thesis "Classification of Human Whole-Body Motion using Hidden Markov Models".
This code was written during the course of my Bachelor thesis Classification of Human Whole-Body Motion using Hidden Markov Models. Some things might
 14 Dec 6, 2022
14 Dec 6, 2022
Simple Python Library to display text with color in Python Terminal
pyTextColor v1.0 Introduction pyTextColor is a simple Python Library to display colorful outputs in Terminal, etc. Note: Your Terminal or any software
 1 Jan 23, 2022
1 Jan 23, 2022
A Sublime Text plugin to select a default syntax dialect
Default Syntax Chooser This Sublime Text 4 plugin provides the set_default_syntax_dialect command. This command manipulates a syntax file (e.g.: SQL.s
 3 Jan 14, 2022
3 Jan 14, 2022
Automatic detection and classification of Covid severity degree in LUS (lung ultrasound) scans
Final-Project Final project in the Technion, Biomedical faculty, by Mor Ventura, Dekel Brav & Omri Magen. Subproject 1: Automatic Detection of LUS Cha
 1 Dec 18, 2021
1 Dec 18, 2021

Healthsea is a spaCy pipeline for analyzing user reviews of supplementary products for their effects on health.
Welcome to Healthsea ✨ Create better access to health with spaCy. Healthsea is a pipeline for analyzing user reviews to supplement products by extract
 75 Dec 19, 2022
75 Dec 19, 2022
Almost State-of-the-art Text Generation library
Ps: we are adding transformer model soon Text Gen 🐐 Almost State-of-the-art Text Generation library Text gen is a python library that allow you build
 63 Jun 24, 2022
63 Jun 24, 2022
Code for: Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification Prerequisite PyTorch = 1.2.0 Python3 torch
 16 Dec 14, 2022
16 Dec 14, 2022
Rethinking Nearest Neighbors for Visual Classification
Rethinking Nearest Neighbors for Visual Classification arXiv Environment settings Check out scripts/env_setup.sh Setup data Download the following fin
 29 Oct 11, 2022
29 Oct 11, 2022
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
 3k Jan 2, 2023
3k Jan 2, 2023

A CLI client for sending text emails. (Currently only gmail supported)
emailCLI A CLI client for sending text emails. (Currently only gmail supported)
 3 Dec 17, 2021
3 Dec 17, 2021

LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021
LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021 We propose a cross encoder model (LTR_CrossEncoder) for information retrieval, re-retrie
 7 Jan 12, 2022
7 Jan 12, 2022

A machine learning web application for binary classification using streamlit
Machine Learning web App This is a machine learning web application for binary classification using streamlit options this application contains 3 clas
 1 Dec 20, 2021
1 Dec 20, 2021
A very terrible python-based programming language that uses folders instead of text files
PYFolders by Lewis L. Foster PYFolders is a very terrible python-based programming language that uses folders instead of regular text files. In this r
 5 Jan 8, 2022
5 Jan 8, 2022
A simple, fast, and awesome discord nuke bot! The only thing you need to add is your bot token.
SimpleNukeBot A simple, fast, and awesome discord nuke bot! The only thing you need to add is your bot token. Instructions: All you need to do is crea
 1 Apr 18, 2022
1 Apr 18, 2022

Working demo of the Multi-class and Anomaly classification model using the CLIP feature space
👁️ Hindsight AI: Crime Classification With Clip About For Educational Purposes Only This is a recursive neural net trained to classify specific crime
 2 Jun 5, 2022
2 Jun 5, 2022

A python programusing Tkinter graphics library to randomize questions and answers contained in text files
RaffleOfQuestions Um programa simples em python, utilizando a biblioteca gráfica Tkinter para randomizar perguntas e respostas contidas em arquivos de
 1 Dec 16, 2021
1 Dec 16, 2021

Full Spectrum Bioinformatics - a free online text designed to introduce key topics in Bioinformatics using the Python
Full Spectrum Bioinformatics is a free online text designed to introduce key topics in Bioinformatics using the Python programming language. The text is written in interactive Jupyter Notebooks, which allow you to try out and modify example code and analyses.
 33 Dec 28, 2022
33 Dec 28, 2022

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022
A tool to customize your discord tokens
Fastest Discord Token Manager - Features: Change Token Username Change Token Password Change Token Avatar Change Token Bio This tool is created by Ace
 15 Dec 27, 2022
15 Dec 27, 2022

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
 217 Dec 5, 2022
217 Dec 5, 2022
ByT5: Towards a token-free future with pre-trained byte-to-byte models
ByT5: Towards a token-free future with pre-trained byte-to-byte models ByT5 is a tokenizer-free extension of the mT5 model. Instead of using a subword
 409 Jan 6, 2023
409 Jan 6, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
Repo for Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
ESACL: Enhanced Seq2Seq Autoencoder via Contrastive Learning for AbstractiveText Summarization This repo is for our paper "Enhanced Seq2Seq Autoencode
 14 Nov 1, 2022
14 Nov 1, 2022
Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks
wav2vec_finetune Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks Initial test: gender recognition on this dat
 8 Aug 11, 2022
8 Aug 11, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Large-scale pretraining for dialogue
A State-of-the-Art Large-scale Pretrained Response Generation Model (DialoGPT) This repository contains the source code and trained model for a large-
1.8k Jan 7, 2023
Code for ACL 2020 paper "Rigid Formats Controlled Text Generation"
SongNet SongNet: SongCi + Song (Lyrics) + Sonnet + etc. @inproceedings{li-etal-2020-rigid, title = "Rigid Formats Controlled Text Generation",
 212 Dec 17, 2022
212 Dec 17, 2022
Longformer: The Long-Document Transformer
Longformer Longformer and LongformerEncoderDecoder (LED) are pretrained transformer models for long documents. ***** New December 1st, 2020: Longforme
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022

Source code of paper "BP-Transformer: Modelling Long-Range Context via Binary Partitioning"
BP-Transformer This repo contains the code for our paper BP-Transformer: Modeling Long-Range Context via Binary Partition Zihao Ye, Qipeng Guo, Quan G
 119 Nov 14, 2022
119 Nov 14, 2022
Examples of using sparse attention, as in "Generating Long Sequences with Sparse Transformers"
Status: Archive (code is provided as-is, no updates expected) Update August 2020: For an example repository that achieves state-of-the-art modeling pe
 1.3k Dec 28, 2022
1.3k Dec 28, 2022
A curated list of long-tailed recognition resources.
Awesome Long-tailed Recognition A curated list of long-tailed recognition and related resources. Please feel free to pull requests or open an issue to
 542 Jan 1, 2023
542 Jan 1, 2023

Forest R-CNN: Large-Vocabulary Long-Tailed Object Detection and Instance Segmentation (ACM MM 2020)
Forest R-CNN: Large-Vocabulary Long-Tailed Object Detection and Instance Segmentation (ACM MM 2020) Official implementation of: Forest R-CNN: Large-Vo
 54 Jan 6, 2023
54 Jan 6, 2023
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning. CVPR 2018
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning Tensorflow code and models for the paper: Large Scale Fine-Grained Categ
 187 Oct 1, 2022
187 Oct 1, 2022
A Pytorch reproduction of Range Loss, which is proposed in paper 《Range Loss for Deep Face Recognition with Long-Tailed Training Data》
RangeLoss Pytorch This is a Pytorch reproduction of Range Loss, which is proposed in paper 《Range Loss for Deep Face Recognition with Long-Tailed Trai
 7 Nov 27, 2021
7 Nov 27, 2021
[WACV21] Code for our paper: Samuel, Atzmon and Chechik, "From Generalized zero-shot learning to long-tail with class descriptors"
DRAGON: From Generalized zero-shot learning to long-tail with class descriptors Paper Project Website Video Overview DRAGON learns to correct the bias
 25 Dec 6, 2022
25 Dec 6, 2022

DANet for Tabular data classification/ regression.
Deep Abstract Networks A pyTorch implementation for AAAI-2022 paper DANets: Deep Abstract Networks for Tabular Data Classification and Regression. Bri
 55 Sep 14, 2022
55 Sep 14, 2022
Code for Massive-scale Decoding for Text Generation using Lattices
Massive-scale Decoding for Text Generation using Lattices Jiacheng Xu, Greg Durrett TL;DR: a new search algorithm to construct lattices encoding many
 37 Dec 18, 2022
37 Dec 18, 2022
Weakly Supervised Posture Mining with Reverse Cross-entropy for Fine-grained Classification
Fine-grainedImageClassification Weakly Supervised Posture Mining with Reverse Cross-entropy for Fine-grained Classification We trained model here: lin
 14 Oct 21, 2022
14 Oct 21, 2022
Delta TTA(Text To Audio) SoftWare
Text-To-Audio-Windows Delta TTA(Text To Audio) SoftWare Info You Can Use It For Convert Your Text To Audio File You Just Write Your Text And Your End
 2 Dec 14, 2021
2 Dec 14, 2021

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

The projects lets you extract glossary words and their definitions from a given piece of text automatically using NLP techniques
Unsupervised technique to Glossary and Definition Extraction Code Files GPT2-DefinitionModel.ipynb - GPT-2 model for definition generation. Data_Gener
 28 May 25, 2021
28 May 25, 2021

Predict an emoji that is associated with a text
Sentiment Analysis Sentiment analysis in computational linguistics is a general term for techniques that quantify sentiment or mood in a text. Can you
 30 Sep 7, 2022
30 Sep 7, 2022
🔎 Like Chardet. 🚀 Package for encoding & language detection. Charset detection.
Charset Detection, for Everyone 👋 The Real First Universal Charset Detector A library that helps you read text from an unknown charset encoding. Moti
 332 Dec 31, 2022
332 Dec 31, 2022
Text completion with Hugging Face and TensorFlow.js running on Node.js
Katana ML Text Completion 🤗 Description Runs with with Hugging Face DistilBERT and TensorFlow.js on Node.js distilbert-model - converter from Hugging
 2 Nov 4, 2022
2 Nov 4, 2022
Put blind watermark into a text with python
text_blind_watermark Put blind watermark into a text. Can be used in Wechat dingding ... How to Use install pip install text_blind_watermark Alice Pu
 164 Dec 30, 2022
164 Dec 30, 2022

A 1.3B text-to-image generation model trained on 14 million image-text pairs
minDALL-E on Conceptual Captions minDALL-E, named after minGPT, is a 1.3B text-to-image generation model trained on 14 million image-text pairs for no
 604 Dec 14, 2022
604 Dec 14, 2022
A simple program for training and testing vit
Vit This is a simple program for training and testing vit. Key requirements: torch, torchvision and timm. Dataset I put 5 categories of the cub classi
 2 Oct 11, 2022
2 Oct 11, 2022
Joint learning of images and text via maximization of mutual information
mutual_info_img_txt Joint learning of images and text via maximization of mutual information. This repository incorporates the algorithms presented in
 10 Dec 22, 2022
10 Dec 22, 2022
Using Bert as the backbone model for lime, designed for NLP task explanation (sentence pair text classification task)
Lime Comparing deep contextualized model for sentences highlighting task. In addition, take the classic explanation model "LIME" with bert-base model
 2 Jan 18, 2022
2 Jan 18, 2022
![[AAAI 2022] Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification](https://github.com/qkrdmsghk/TextSSL/raw/master/TextSSL.png)
[AAAI 2022] Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification
Sparse Structure Learning via Graph Neural Networks for inductive document classification Make graph dataset create co-occurrence graph for datasets.
 16 Dec 22, 2022
16 Dec 22, 2022
![[ICME 2021 Oral] CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning](https://github.com/jylins/CORE-Text/raw/main/resources/core_text.png)
[ICME 2021 Oral] CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning
CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning This repository is the official PyTorch implementation of CORE-Text, a
 18 Aug 11, 2022
18 Aug 11, 2022
Adversarial Examples for Extreme Multilabel Text Classification
Adversarial Examples for Extreme Multilabel Text Classification The code is adapted from the source codes of BERT-ATTACK [1], APLC_XLNet [2], and Atte
 1 May 14, 2022
1 May 14, 2022
Type annotations builder for boto3 compatible with VSCode, PyCharm, Emacs, Sublime Text, pyright and mypy.
mypy_boto3_builder Type annotations builder for boto3-stubs project. Compatible with VSCode, PyCharm, Emacs, Sublime Text, mypy, pyright and other too
 2 Dec 5, 2022
2 Dec 5, 2022
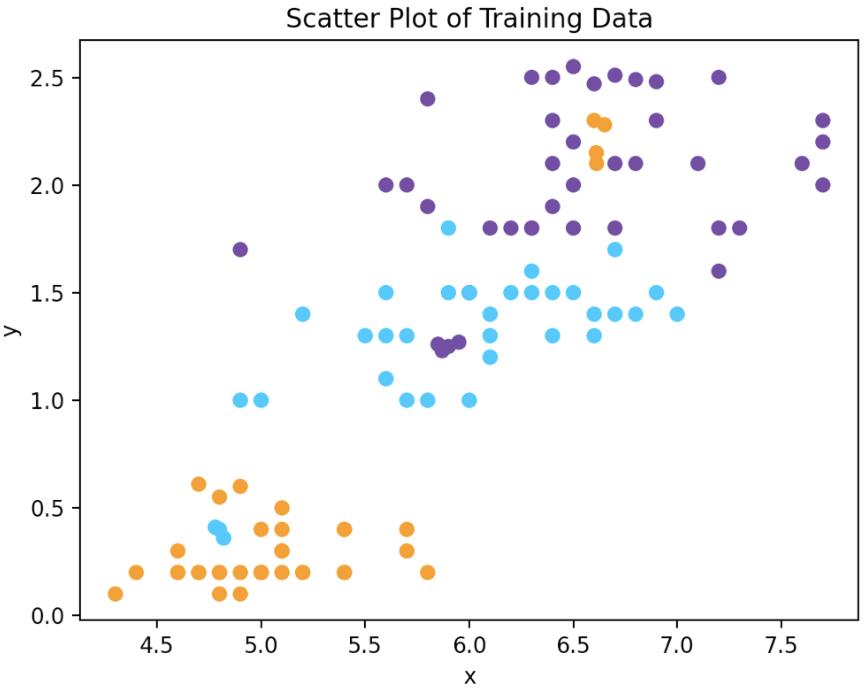
Weighted K Nearest Neighbors (kNN) algorithm implemented on python from scratch.
kNN_From_Scratch I implemented the k nearest neighbors (kNN) classification algorithm on python. This algorithm is used to predict the classes of new
 1 Dec 14, 2021
1 Dec 14, 2021

Manage your WordPress installation directly from SublimeText SideBar and Command Palette.
WordpressPluginManager Manage your WordPress installation directly from SublimeText SideBar and Command Palette. Installation Dependencies You will ne
 1 Dec 14, 2021
1 Dec 14, 2021

Converts a text file of songs to a playlist on your Spotify account.
Playlist Converter Convert a text file of songs to a playlist on your Spotify account. Create your playlists faster instead of manually searching for
 18 Dec 21, 2022
18 Dec 21, 2022
Extreme Dynamic Classifier Chains - XGBoost for Multi-label Classification
Extreme Dynamic Classifier Chains Classifier chains is a key technique in multi-label classification, sinceit allows to consider label dependencies ef
 6 Oct 8, 2022
6 Oct 8, 2022
The code of "Dependency Learning for Legal Judgment Prediction with a Unified Text-to-Text Transformer".
Code data_preprocess.py: preprocess data for Dependent-T5. parameters.py: define parameters of Dependent-T5. train_tools.py: traning and evaluation co
 1 Apr 21, 2022
1 Apr 21, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022
Code repository for our paper regarding the L3D dataset.
The Large Labelled Logo Dataset (L3D): A Multipurpose and Hand-Labelled Continuously Growing Dataset Website: https://lhf-labs.github.io/tm-dataset Da
 9 Dec 14, 2022
9 Dec 14, 2022

Binary classification for arrythmia detection with ECG datasets.
HEART DISEASE AI DATATHON 2021 [Eng] / [Kor] #English This is an AI diagnosis modeling contest that uses the heart disease echocardiography and electr
 3 Jul 14, 2022
3 Jul 14, 2022
Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts
t5-japanese Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts. The following is a list of models that
 1 Dec 13, 2021
1 Dec 13, 2021
Rule Based Classification Project For Python
Rule-Based-Classification-Project (ENG) Business Problem: A game company wants to create new level-based customer definitions (personas) by using some
 4 Oct 29, 2022
4 Oct 29, 2022
Rule Based Classification Project
Kural Tabanlı Sınıflandırma ile Potansiyel Müşteri Getirisi Hesaplama İş Problemi: Bir oyun şirketi müşterilerinin bazı özelliklerini kullanaraknseviy
 1 Jan 12, 2022
1 Jan 12, 2022

Python library to build pretty command line user prompts ✨Easy to use multi-select lists, confirmations, free text prompts ...
Questionary ✨ Questionary is a Python library for effortlessly building pretty command line interfaces ✨ Features Installation Usage Documentation Sup
 990 Jan 1, 2023
990 Jan 1, 2023
Extract price amount and currency symbol from a raw text string
price-parser is a small library for extracting price and currency from raw text strings.
 252 Dec 31, 2022
252 Dec 31, 2022
Convert long numbers into a human-readable format in Python
Convert long numbers into a human-readable format in Python
 73 Dec 28, 2022
73 Dec 28, 2022
SeqAttack: a framework for adversarial attacks on token classification models
A framework for adversarial attacks against token classification models
 23 Nov 25, 2022
23 Nov 25, 2022

Discord Token Stealer Malware Protection
TokenGuard TokenGuard, protect your account, prevent token steal. Totally free and open source Discord Server: https://discord.gg/EmwfaGuBE8 Source Co
 10 Nov 23, 2022
10 Nov 23, 2022

♟️ QR Code display for P4wnP1 (SSH, VNC, any text / URL)
♟️ Display QR Codes on P4wnP1 (p4wnsolo-qr) 🟢 QR Code display for P4wnP1 w/OLED (SSH, VNC, P4wnP1 WebGUI, any text / URL / exfiltrated data) Note: Th
 4 Dec 19, 2022
4 Dec 19, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022

Official implementation of the AAAI 2022 paper "Learning Token-based Representation for Image Retrieval"
Token: Token-based Representation for Image Retrieval PyTorch training code for Token-based Representation for Image Retrieval. We propose a joint loc
 42 Dec 6, 2022
42 Dec 6, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
Python 3 module to print out long strings of text with intervals of time inbetween
Python-Fastprint Python 3 module to print out long strings of text with intervals of time inbetween Install: pip install fastprint Sync Usage: from fa
 2 Jun 27, 2022
2 Jun 27, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021

This script has been created in order to find what are the most common demanded technologies in Data Engineering field.
This is a Python script that given a whole corpus of job descriptions and a file with keywords it extracts the number of number of ocurrences of these keywords and write it to a file. This script it is easy to extend to accept more functionalities
 0 Jul 17, 2022
0 Jul 17, 2022
Synchronised text editor over TCP, for live editing with others.
SyncTEd Synchronised text editor over TCP, for live editing with others. Written in Python with PyGame. Run Install requirements: pip install -r requi
 1 May 13, 2022
1 May 13, 2022
A wrapper for The Movie Database API v3 and v4 that only uses the read access token (not api key).
fulltmdb A wrapper for The Movie Database API v3 and v4 that only uses the read access token (not api key). Installation Use the package manager pip t
 2 Sep 26, 2021
2 Sep 26, 2021
Creation & manipulation of PyPI tokens
PyPIToken: Manipulate PyPI API tokens PyPIToken is an open-source Python 3.6+ library for generating and manipulating PyPI tokens. PyPI tokens are ver
 8 Nov 1, 2022
8 Nov 1, 2022
Code for the AAAI-2022 paper: Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification (AAAI 2022) Prerequisite PyTorch = 1.2.0 P
16 Dec 14, 2022

Unimodal Face Classification with Multimodal Training
Unimodal Face Classification with Multimodal Training This is a PyTorch implementation of the following paper: Unimodal Face Classification with Multi
 3 Jul 6, 2022
3 Jul 6, 2022
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022

HairCLIP: Design Your Hair by Text and Reference Image
Overview This repository hosts the official PyTorch implementation of the paper: "HairCLIP: Design Your Hair by Text and Reference Image". Our single
 322 Jan 6, 2023
322 Jan 6, 2023

Official implementation of Self-supervised Image-to-text and Text-to-image Synthesis
Self-supervised Image-to-text and Text-to-image Synthesis This is the official implementation of Self-supervised Image-to-text and Text-to-image Synth
 6 Jul 31, 2022
6 Jul 31, 2022

A new video text spotting framework with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
67 Jan 3, 2023
ScisorWiz: Differential Isoform Visualizer for Long-Read RNA Sequencing Data
ScisorWiz: Vizualizer for Differential Isoform Expression README ScisorWiz is a linux-based R-package for visualizing differential isoform expression
 6 Oct 4, 2022
6 Oct 4, 2022
Fail tests that take too long to run
GitHub | PyPI | Issues pytest-fail-slow is a pytest plugin for making tests fail that take too long to run. It adds a --fail-slow DURATION command-lin
 4 Nov 27, 2022
4 Nov 27, 2022
Integrate clang-format with Sublime Text
Sublime Text Clang Format Plugin This is a minimal plugin integrating clang-format with Sublime Text, with emphasis on the word minimal. It is not rea
 1 Dec 17, 2021
1 Dec 17, 2021

1st Online Python Editor With Live Syntax Checking and Execution
PythonBuddy 🖊️ 🐍 Online Python 3 Programming with Live Pylint Syntax Checking! Usage Fetch from repo: git clone https://github.com/ethanchewy/Python
 255 Dec 23, 2022
255 Dec 23, 2022
Code for paper "Extract, Denoise and Enforce: Evaluating and Improving Concept Preservation for Text-to-Text Generation" EMNLP 2021
The repo provides the code for paper "Extract, Denoise and Enforce: Evaluating and Improving Concept Preservation for Text-to-Text Generation" EMNLP 2
 18 May 24, 2022
18 May 24, 2022