926 Repositories
Python memory-efficient-attention Libraries

PyTorchMemTracer - Depict GPU memory footprint during DNN training of PyTorch
A Memory Tracer For PyTorch OOM is a nightmare for PyTorch users. However, most
 9 Nov 14, 2022
9 Nov 14, 2022
Static Features Classifier - A static features classifier for Point-Could clusters using an Attention-RNN model
Static Features Classifier This is a static features classifier for Point-Could
 1 Jan 25, 2022
1 Jan 25, 2022
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline. The pipeline accepts english text as input and returns the French translation.
 1 Jan 24, 2022
1 Jan 24, 2022

This project generates news headlines using a Long Short-Term Memory (LSTM) neural network.
News Headlines Generator bunnysaini/Generate-Headlines Goal This project aims to generate news headlines using a Long Short-Term Memory (LSTM) neural
 1 Jan 24, 2022
1 Jan 24, 2022
A "multiclipboards" script for an efficient way to improve the original clipboards which are only able to save one string at a time
A "multiclipboards" script for an efficient way to improve the original clipboards which are only able to save one string at a time. Works on both Windows and Linux.
 1 Jan 24, 2022
1 Jan 24, 2022
Efficient Multi Collection Style Transfer Using GAN
Proposed a new model that can make style transfer from single style image, and allow to transfer into multiple different styles in a single model.
 2 Jan 15, 2022
2 Jan 15, 2022

Pytorch implementation of ICASSP 2022 paper Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 6 Sep 21, 2022
6 Sep 21, 2022

Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 3 Oct 31, 2022
3 Oct 31, 2022
HistoSeg : Quick attention with multi-loss function for multi-structure segmentation in digital histology images
HistoSeg : Quick attention with multi-loss function for multi-structure segmentation in digital histology images Histological Image Segmentation This
 11 Dec 16, 2022
11 Dec 16, 2022
Peek-a-Boo: What (More) is Disguised in a Randomly Weighted Neural Network, and How to Find It Efficiently
Peek-a-Boo: What (More) is Disguised in a Randomly Weighted Neural Network, and How to Find It Efficiently This repository is the official implementat
 4 Dec 20, 2022
4 Dec 20, 2022
A functional and efficient python implementation of the 3D version of Maxwell's equations
py-maxwell-fdfd Solving Maxwell's equations via A python implementation of the 3D curl-curl E-field equations. This code contains additional work to e
 12 Dec 11, 2022
12 Dec 11, 2022
Utilities to make function-based views cleaner, more efficient, and better tasting.
django-fbv Utilities to make Django function-based views cleaner, more efficient, and better tasting. 💥 📖 Complete documentation: https://django-fbv
 49 Dec 30, 2022
49 Dec 30, 2022
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022
GalaXC: Graph Neural Networks with Labelwise Attention for Extreme Classification
GalaXC GalaXC: Graph Neural Networks with Labelwise Attention for Extreme Classification @InProceedings{Saini21, author = {Saini, D. and Jain,
 28 Dec 5, 2022
28 Dec 5, 2022

Efficient Online Bayesian Inference for Neural Bandits
Efficient Online Bayesian Inference for Neural Bandits By Gerardo Durán-Martín, Aleyna Kara, and Kevin Murphy AISTATS 2022.
 49 Dec 27, 2022
49 Dec 27, 2022

Visual Python and C++ nanosecond profiler, logger, tests enabler
Look into Palanteer and get an omniscient view of your program Palanteer is a set of lean and efficient tools to improve the quality of software, for
 1.9k Dec 26, 2022
1.9k Dec 26, 2022
Seq2seq attn - Use the Seq2Seq method to implement machine translation and introduce Attention mechanism to improve the results
Seq2seq_attn Use the Seq2Seq method to implement machine translation and use the
 1 Jun 28, 2022
1 Jun 28, 2022
Unofficial PyTorch Implementation of "Augmenting Convolutional networks with attention-based aggregation"
Pytorch Implementation of Augmenting Convolutional networks with attention-based aggregation This is the unofficial PyTorch Implementation of "Augment
 20 Sep 9, 2022
20 Sep 9, 2022
Escaping the Gradient Vanishing: Periodic Alternatives of Softmax in Attention Mechanism
Period-alternatives-of-Softmax Experimental Demo for our paper 'Escaping the Gradient Vanishing: Periodic Alternatives of Softmax in Attention Mechani
 0 Sep 6, 2021
0 Sep 6, 2021
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
 27 Nov 7, 2022
27 Nov 7, 2022

Official implementation of "Refiner: Refining Self-attention for Vision Transformers".
RefinerViT This repo is the official implementation of "Refiner: Refining Self-attention for Vision Transformers". The repo is build on top of timm an
 101 Dec 29, 2022
101 Dec 29, 2022

RETRO-pytorch - Implementation of RETRO, Deepmind's Retrieval based Attention net, in Pytorch
RETRO - Pytorch (wip) Implementation of RETRO, Deepmind's Retrieval based Attent
 556 Jan 4, 2023
556 Jan 4, 2023

"Moshpit SGD: Communication-Efficient Decentralized Training on Heterogeneous Unreliable Devices", official implementation
Moshpit SGD: Communication-Efficient Decentralized Training on Heterogeneous Unreliable Devices This repository contains the official PyTorch implemen
 21 Oct 18, 2022
21 Oct 18, 2022
Holographic Declarative Memory for Python ACT-R
HDM This is the repository for the Holographic Declarative Memory (HDM) module for Python ACT-R. This repository contains: documentation: a paper, con
 1 Jan 17, 2022
1 Jan 17, 2022

Implementation of Memory-Compressed Attention, from the paper "Generating Wikipedia By Summarizing Long Sequences"
Memory Compressed Attention Implementation of the Self-Attention layer of the proposed Memory-Compressed Attention, in Pytorch. This repository offers
47 Dec 23, 2022
Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2018)" and "CBAM: Convolutional Block Attention Module (ECCV2018)"
BAM and CBAM Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2018)" and "CBAM: Convolutional Block Attention Module (ECCV2018)" Updat
 1.7k Jan 1, 2023
1.7k Jan 1, 2023

An implementation of the efficient attention module.
Efficient Attention An implementation of the efficient attention module. Description Efficient attention is an attention mechanism that substantially
 194 Dec 15, 2022
194 Dec 15, 2022
This repository contains an implementation of the Permutohedral Attention Module in Pytorch
Permutohedral_attention_module This repository contains an implementation of the Permutohedral Attention Module
 26 Nov 27, 2022
26 Nov 27, 2022
The code for Expectation-Maximization Attention Networks for Semantic Segmentation (ICCV'2019 Oral)
EMANet News The bug in loading the pretrained model is now fixed. I have updated the .pth. To use it, download it again. EMANet-101 gets 80.99 on the
 663 Nov 30, 2022
663 Nov 30, 2022

Pytorch implementation of Compressive Transformers, from Deepmind
Compressive Transformer in Pytorch Pytorch implementation of Compressive Transformers, a variant of Transformer-XL with compressed memory for long-ran
118 Dec 1, 2022
Implementation of Axial attention - attending to multi-dimensional data efficiently
Axial Attention Implementation of Axial attention in Pytorch. A simple but powerful technique to attend to multi-dimensional data efficiently. It has
250 Dec 25, 2022
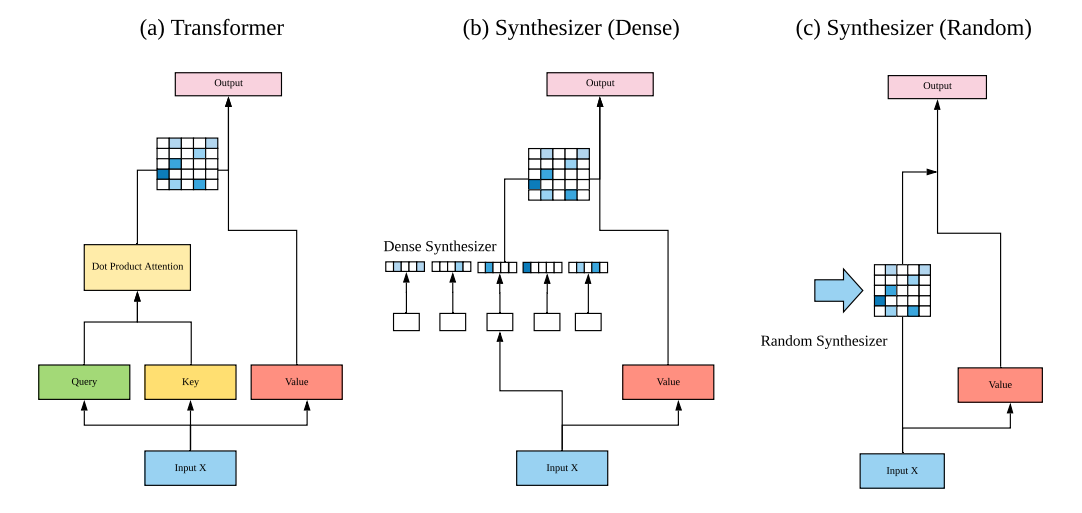
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch Reference Paper URL Author: Yi Tay, Dara Bahri, Donald Metzler
 66 Nov 30, 2022
66 Nov 30, 2022
The accompanying code for the paper "GMAT: Global Memory Augmentation for Transformers" (Ankit Gupta and Jonathan Berant).
GMAT: Global Memory Augmentation for Transformers This repository contains the accompanying code for the paper: "GMAT: Global Memory Augmentation for
 7 Oct 21, 2021
7 Oct 21, 2021

My take on a practical implementation of Linformer for Pytorch.
Linformer Pytorch Implementation A practical implementation of the Linformer paper. This is attention with only linear complexity in n, allowing for v
 349 Dec 25, 2022
349 Dec 25, 2022

Implementation of Kronecker Attention in Pytorch
Kronecker Attention Pytorch Implementation of Kronecker Attention in Pytorch. Results look less than stellar, but if someone found some context where
16 May 6, 2022

Implementation of Memformer, a Memory-augmented Transformer, in Pytorch
Memformer - Pytorch Implementation of Memformer, a Memory-augmented Transformer, in Pytorch. It includes memory slots, which are updated with attentio
60 Nov 6, 2022
![[NeurIPS 2020] Official Implementation:](https://github.com/giannisdaras/smyrf/raw/master/visuals/quality_degradation.png)
[NeurIPS 2020] Official Implementation: "SMYRF: Efficient Attention using Asymmetric Clustering".
SMYRF: Efficient attention using asymmetric clustering Get started: Abstract We propose a novel type of balanced clustering algorithm to approximate a
 46 Dec 22, 2022
46 Dec 22, 2022
![[ACM MM 2021] TSA-Net: Tube Self-Attention Network for Action Quality Assessment](https://github.com/Shunli-Wang/TSA-Net/raw/main/fig/TSA-Net.jpg)
[ACM MM 2021] TSA-Net: Tube Self-Attention Network for Action Quality Assessment
Tube Self-Attention Network (TSA-Net) This repository contains the PyTorch implementation for paper TSA-Net: Tube Self-Attention Network for Action Qu
 18 Dec 23, 2022
18 Dec 23, 2022
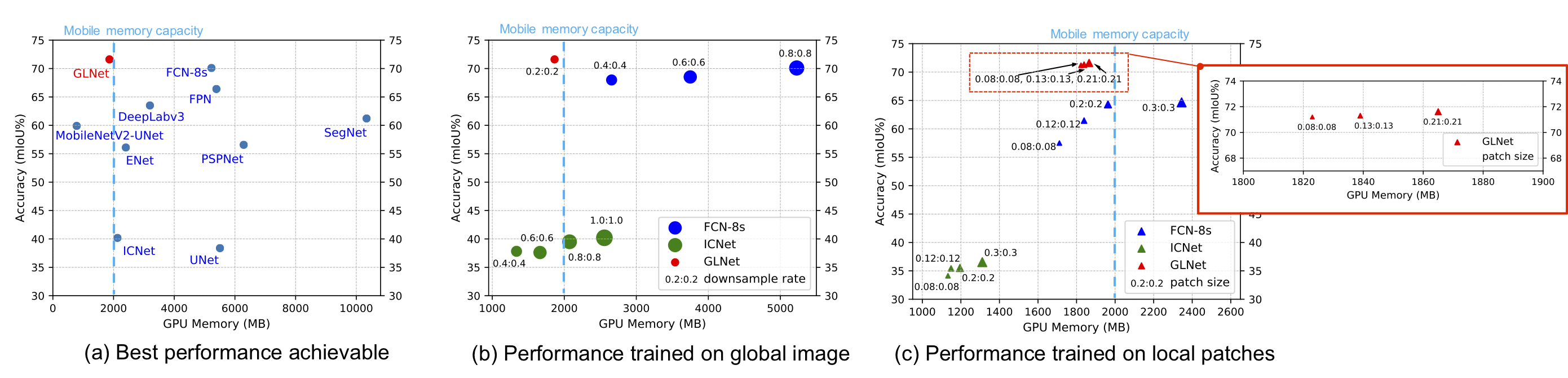
GLNet for Memory-Efficient Segmentation of Ultra-High Resolution Images
GLNet for Memory-Efficient Segmentation of Ultra-High Resolution Images Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-
298 Dec 12, 2022

LightNet++: Boosted Light-weighted Networks for Real-time Semantic Segmentation
LightNet++ !!!New Repo.!!! ⇒ EfficientNet.PyTorch: Concise, Modular, Human-friendly PyTorch implementation of EfficientNet with Pre-trained Weights !!
 237 Jan 5, 2023
237 Jan 5, 2023
The official implementation of ELSA: Enhanced Local Self-Attention for Vision Transformer
ELSA: Enhanced Local Self-Attention for Vision Transformer By Jingkai Zhou, Pich
 87 Dec 19, 2022
87 Dec 19, 2022
Eff video representation - Efficient video representation through neural fields
Neural Residual Flow Fields for Efficient Video Representations 1. Download MPI
 41 Jan 6, 2023
41 Jan 6, 2023
Semi-Supervised Semantic Segmentation with Pixel-Level Contrastive Learning from a Class-wise Memory Bank
This repository provides the official code for replicating experiments from the paper: Semi-Supervised Semantic Segmentation with Pixel-Level Contrast
 58 Dec 15, 2022
58 Dec 15, 2022

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022

Repository of Vision Transformer with Deformable Attention
Vision Transformer with Deformable Attention This repository contains the code for the paper Vision Transformer with Deformable Attention [arXiv]. Int
 410 Jan 3, 2023
410 Jan 3, 2023

K Closest Points and Maximum Clique Pruning for Efficient and Effective 3D Laser Scan Matching (To appear in RA-L 2022)
KCP The official implementation of KCP: k Closest Points and Maximum Clique Pruning for Efficient and Effective 3D Laser Scan Matching, accepted for p
 109 Dec 14, 2022
109 Dec 14, 2022
This repository provides the official implementation of 'Learning to ignore: rethinking attention in CNNs' accepted in BMVC 2021.
inverse_attention This repository provides the official implementation of 'Learning to ignore: rethinking attention in CNNs' accepted in BMVC 2021. Le
 5 Jul 8, 2022
5 Jul 8, 2022
Source code of paper: "HRegNet: A Hierarchical Network for Efficient and Accurate Outdoor LiDAR Point Cloud Registration".
HRegNet: A Hierarchical Network for Efficient and Accurate Outdoor LiDAR Point Cloud Registration Environments The code mainly requires the following
 3 Oct 6, 2022
3 Oct 6, 2022
Financial portfolio optimisation in python, including classical efficient frontier, Black-Litterman, Hierarchical Risk Parity
PyPortfolioOpt has recently been published in the Journal of Open Source Software 🎉 PyPortfolioOpt is a library that implements portfolio optimizatio
 3.2k Jan 2, 2023
3.2k Jan 2, 2023
Fast, efficient Blowfish cipher implementation in pure Python (3.4+).
blowfish This module implements the Blowfish cipher using only Python (3.4+). Blowfish is a block cipher that can be used for symmetric-key encryption
 41 Dec 31, 2022
41 Dec 31, 2022
Unofficial PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution
PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution [arXiv 2021].
 122 Dec 12, 2022
122 Dec 12, 2022
The official TensorFlow implementation of the paper Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition
Action Transformer A Self-Attention Model for Short-Time Human Action Recognition This repository contains the official TensorFlow implementation of t
 20 Jan 3, 2023
20 Jan 3, 2023
Alignment Attention Fusion framework for Few-Shot Object Detection
AAF framework Framework generalities This repository contains the code of the AAF framework proposed in this paper. The main idea behind this work is
 20 Dec 16, 2022
20 Dec 16, 2022

Logistic Bandit experiments. Official code for the paper "Jointly Efficient and Optimal Algorithms for Logistic Bandits".
Code for the paper Jointly Efficient and Optimal Algorithms for Logistic Bandits, by Louis Faury, Marc Abeille, Clément Calauzènes and Kwang-Sun Jun.
 1 Jan 22, 2022
1 Jan 22, 2022
Easy and Efficient Object Detector
EOD Easy and Efficient Object Detector EOD (Easy and Efficient Object Detection) is a general object detection model production framework. It aim on p
 381 Jan 1, 2023
381 Jan 1, 2023
A wrapper around ffmpeg to make it work in a concurrent and memory-buffered fashion.
Media Fixer Have you ever had a film or TV show that your TV wasn't able to play its audio? Well this program is for you. Media Fixer is a program whi
 3 May 4, 2022
3 May 4, 2022

Implementation of a Transformer using ReLA (Rectified Linear Attention)
ReLA (Rectified Linear Attention) Transformer Implementation of a Transformer using ReLA (Rectified Linear Attention). It will also contain an attempt
49 Oct 14, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions Project Page | Paper If you find our work useful for your research, please con
 96 Jan 4, 2023
96 Jan 4, 2023

Official PyTorch implementation of "The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation" (ICCV 21).
CenterGroup This the official implementation of our ICCV 2021 paper The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person P
 43 Dec 25, 2022
43 Dec 25, 2022

Code for "Multi-Time Attention Networks for Irregularly Sampled Time Series", ICLR 2021.
Multi-Time Attention Networks (mTANs) This repository contains the PyTorch implementation for the paper Multi-Time Attention Networks for Irregularly
 68 Dec 17, 2022
68 Dec 17, 2022

This is a super simple visualization toolbox (script) for transformer attention visualization ✌
Trans_attention_vis This is a super simple visualization toolbox (script) for transformer attention visualization ✌ 1. How to prepare your attention m
 3 Jul 9, 2022
3 Jul 9, 2022
Make YouTube videos tasks in Todoist faster and time efficient!
Youtubist Basically fork of yt-dlp python module to my needs. You can paste playlist or channel link on the YouTube. It will automatically format to s
 1 Dec 4, 2022
1 Dec 4, 2022
RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality?
RaftMLP RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality? By Yuki Tatsunami and Masato Taki (Rikkyo University) [arxiv]
 20 Aug 31, 2022
20 Aug 31, 2022

Sign Language Recognition service utilizing a deep learning model with Long Short-Term Memory to perform sign language recognition.
Sign Language Recognition Service This is a Sign Language Recognition service utilizing a deep learning model with Long Short-Term Memory to perform s
 1 Jan 8, 2022
1 Jan 8, 2022
Import Python modules from dicts and JSON formatted documents.
Paker Paker is module for importing Python packages/modules from dictionaries and JSON formatted documents. It was inspired by httpimporter. Important
 1 Sep 7, 2022
1 Sep 7, 2022
Module for remote in-memory Python package/module loading through HTTP/S
httpimport Python's missing feature! The feature has been suggested in Python Mailing List Remote, in-memory Python package/module importing through H
 220 Dec 17, 2022
220 Dec 17, 2022

In this project we use both Resnet and Self-attention layer for cat, dog and flower classification.
cdf_att_classification classes = {0: 'cat', 1: 'dog', 2: 'flower'} In this project we use both Resnet and Self-attention layer for cdf-Classification.
 3 Nov 23, 2022
3 Nov 23, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

GAT - Graph Attention Network (PyTorch) 💻 + graphs + 📣 = ❤️
GAT - Graph Attention Network (PyTorch) 💻 + graphs + 📣 = ❤️ This repo contains a PyTorch implementation of the original GAT paper ( 🔗 Veličković et
 1.9k Jan 9, 2023
1.9k Jan 9, 2023
Very efficient backup system based on the git packfile format, providing fast incremental saves and global deduplication
Very efficient backup system based on the git packfile format, providing fast incremental saves and global deduplication (among and within files, including virtual machine images). Current release is 0.31, and the development branch is master. Please post problems or patches to the mailing list for discussion (see the end of the README below).
 6.9k Dec 27, 2022
6.9k Dec 27, 2022

Vis2Mesh: Efficient Mesh Reconstruction from Unstructured Point Clouds of Large Scenes with Learned Virtual View Visibility ICCV2021
Vis2Mesh This is the offical repository of the paper: Vis2Mesh: Efficient Mesh Reconstruction from Unstructured Point Clouds of Large Scenes with Lear
 71 Dec 25, 2022
71 Dec 25, 2022
Fast convergence of detr with spatially modulated co-attention
Fast convergence of detr with spatially modulated co-attention Usage There are no extra compiled components in SMCA DETR and package dependencies are
 135 Dec 7, 2022
135 Dec 7, 2022

SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition PDF Abstract Explainable artificial intelligence has been gaining attention
 87 Dec 26, 2022
87 Dec 26, 2022
Custom studies about block sparse attention.
Block Sparse Attention 研究总结 本人近半年来对Block Sparse Attention(块稀疏注意力)的研究总结(持续更新中)。按时间顺序,主要分为如下三部分: PyTorch 自定义 CUDA 算子——以矩阵乘法为例 基于 Triton 的 Block Sparse A
 2 Jan 9, 2022
2 Jan 9, 2022

Attention-based Transformation from Latent Features to Point Clouds (AAAI 2022)
Attention-based Transformation from Latent Features to Point Clouds This repository contains a PyTorch implementation of the paper: Attention-based Tr
 12 Nov 11, 2022
12 Nov 11, 2022
EfficientMPC - Efficient Model Predictive Control Implementation
efficientMPC Efficient Model Predictive Control Implementation The original algo
 8 Dec 4, 2022
8 Dec 4, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023

Scalene: a high-performance, high-precision CPU, GPU, and memory profiler for Python
Scalene: a high-performance CPU, GPU and memory profiler for Python by Emery Berger, Sam Stern, and Juan Altmayer Pizzorno. Scalene community Slack Ab
 7k Dec 30, 2022
7k Dec 30, 2022

Machine learning library for fast and efficient Gaussian mixture models
This repository contains code which implements the Stochastic Gaussian Mixture Model (S-GMM) for event-based datasets Dependencies CMake Premake4 Blaz
 1 Dec 19, 2022
1 Dec 19, 2022
DeepSpamReview: Detection of Fake Reviews on Online Review Platforms using Deep Learning Architectures. Summer Internship project at CoreView Systems.
Detection of Fake Reviews on Online Review Platforms using Deep Learning Architectures Dataset: https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polar
 37 Dec 17, 2022
37 Dec 17, 2022
PyTorch code for 'Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning'
Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning This repository is for EMSRDPN introduced in the foll
 2 Jan 4, 2022
2 Jan 4, 2022
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss This repository implements the SAFL in pytorch. Installation conda env create -f environm
 6 Aug 24, 2022
6 Aug 24, 2022
CV backbones including GhostNet, TinyNet and TNT, developed by Huawei Noah's Ark Lab.
CV Backbones including GhostNet, TinyNet, TNT (Transformer in Transformer) developed by Huawei Noah's Ark Lab. GhostNet Code TinyNet Code TNT Code Pyr
 3k Jan 8, 2023
3k Jan 8, 2023
Understanding and Overcoming the Challenges of Efficient Transformer Quantization
Transformer Quantization This repository contains the implementation and experiments for the paper presented in Yelysei Bondarenko1, Markus Nagel1, Ti
 83 Dec 30, 2022
83 Dec 30, 2022
PyTorch code for 'Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning'
Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning This repository is for EMSRDPN introduced in the foll
7 Feb 10, 2022
![[CVPR 2020] GAN Compression: Efficient Architectures for Interactive Conditional GANs](https://github.com/mit-han-lab/gan-compression/raw/master/imgs/teaser.png)
[CVPR 2020] GAN Compression: Efficient Architectures for Interactive Conditional GANs
GAN Compression project | paper | videos | slides [NEW!] GAN Compression is accepted by T-PAMI! We released our T-PAMI version in the arXiv v4! [NEW!]
 1k Jan 7, 2023
1k Jan 7, 2023

DAGAN - Dual Attention GANs for Semantic Image Synthesis
Contents Semantic Image Synthesis with DAGAN Installation Dataset Preparation Generating Images Using Pretrained Model Train and Test New Models Evalu
 104 Oct 8, 2022
104 Oct 8, 2022

CLADE - Efficient Semantic Image Synthesis via Class-Adaptive Normalization (TPAMI 2021)
Efficient Semantic Image Synthesis via Class-Adaptive Normalization (Accepted by TPAMI)
 49 Nov 17, 2022
49 Nov 17, 2022

AttentionGAN for Unpaired Image-to-Image Translation & Multi-Domain Image-to-Image Translation
AttentionGAN-v2 for Unpaired Image-to-Image Translation AttentionGAN-v2 Framework The proposed generator learns both foreground and background attenti
530 Dec 27, 2022

A unified framework to jointly model images, text, and human attention traces.
connect-caption-and-trace This repository contains the reference code for our paper Connecting What to Say With Where to Look by Modeling Human Attent
 73 Oct 24, 2022
73 Oct 24, 2022

Meshed-Memory Transformer for Image Captioning. CVPR 2020
M²: Meshed-Memory Transformer This repository contains the reference code for the paper Meshed-Memory Transformer for Image Captioning (CVPR 2020). Pl
 422 Dec 28, 2022
422 Dec 28, 2022
![Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]](https://github.com/JDAI-CV/image-captioning/raw/master/images/framework.jpg)
Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]
Introduction This repository is for X-Linear Attention Networks for Image Captioning (CVPR 2020). The original paper can be found here. Please cite wi
 240 Dec 17, 2022
240 Dec 17, 2022
PyTorch code for MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning PyTorch code for our ACL 2020 paper "MART: Memory-Augmented Recur
 151 Jan 6, 2023
151 Jan 6, 2023
Code for paper Adaptively Aligned Image Captioning via Adaptive Attention Time
Adaptively Aligned Image Captioning via Adaptive Attention Time This repository includes the implementation for Adaptively Aligned Image Captioning vi
 45 Aug 27, 2022
45 Aug 27, 2022

Tensorflow implementation of soft-attention mechanism for video caption generation.
SA-tensorflow Tensorflow implementation of soft-attention mechanism for video caption generation. An example of soft-attention mechanism. The attentio
 153 Nov 14, 2022
153 Nov 14, 2022

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022

Image captioning - Tensorflow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Introduction This neural system for image captioning is roughly based on the paper "Show, Attend and Tell: Neural Image Caption Generation with Visual
 749 Dec 28, 2022
749 Dec 28, 2022