648 Repositories
Python mulran-dataset Libraries

MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity Introduction The 3D LiDAR place recognition aim
 16 Dec 8, 2022
16 Dec 8, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022
Code repository for our paper regarding the L3D dataset.
The Large Labelled Logo Dataset (L3D): A Multipurpose and Hand-Labelled Continuously Growing Dataset Website: https://lhf-labs.github.io/tm-dataset Da
 9 Dec 14, 2022
9 Dec 14, 2022

This repository consists of Blender python scripts and corresponding assets to generate variants of the CANDLE dataset
candle-simulator This repository consists of Blender python scripts and corresponding assets to generate variants of the IITH-CANDLE dataset. The rend
 1 Dec 15, 2021
1 Dec 15, 2021
A FAIR dataset of TCV experimental results for validating edge/divertor turbulence models.
TCV-X21 validation for divertor turbulence simulations Quick links Intro Welcome to TCV-X21. We're glad you've found us! This repository is designed t
 0 Dec 18, 2021
0 Dec 18, 2021
SpaCy3Urdu: run command to setup assets(dataset from UD)
Project setup run command to setup assets(dataset from UD) spacy project assets It uses project.yml file and download the data from UD GitHub reposito
 1 Dec 14, 2021
1 Dec 14, 2021
pyreports is a python library that allows you to create complex report from various sources
pyreports pyreports is a python library that allows you to create complex reports from various sources such as databases, text files, ldap, etc. and p
 78 Dec 13, 2022
78 Dec 13, 2022
Random dataframe and database table generator
Random database/dataframe generator Authored and maintained by Dr. Tirthajyoti Sarkar, Fremont, USA Introduction Often, beginners in SQL or data scien
 249 Jan 8, 2023
249 Jan 8, 2023

Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX.
Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX. The repository combines a class agnostic object localizer to first detect the objects in the image, and next a ResNet50 model trained on ImageNet is used to label each box.
 24 Nov 14, 2022
24 Nov 14, 2022
Users can free try their models on SIDD dataset based on this code
SIDD benchmark 1 Train python train.py If you want to train your network, just modify the yaml in the options folder. 2 Validation python validation.p
 2 May 20, 2022
2 May 20, 2022
Extract data from a wide range of Internet sources into a pandas DataFrame.
pandas-datareader Up to date remote data access for pandas, works for multiple versions of pandas. Installation Install using pip pip install pandas-d
 2.5k Jan 9, 2023
2.5k Jan 9, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
 264 Jan 3, 2023
264 Jan 3, 2023

This repo implements a 3D segmentation task for an airport baggage dataset.
3D CT Scan Segmentation With Occupancy Network This repo implements a 3D superresolution segmentation task for an airport baggage dataset. Our final p
 2 Mar 28, 2022
2 Mar 28, 2022
Machine learning Bot detection technique, based on United States election dataset
Machine learning Bot detection technique, based on United States election dataset (2020). Current github repo provides implementation described in pap
 4 Nov 20, 2022
4 Nov 20, 2022
Wikidated : An Evolving Knowledge Graph Dataset of Wikidata’s Revision History
Wikidated Wikidated 1.0 is a dataset of Wikidata’s full revision history, which encodes changes between Wikidata revisions as sets of deletions and ad
 11 Aug 16, 2022
11 Aug 16, 2022
CLDF dataset derived from Robbeets et al.'s "Triangulation Supports Agricultural Spread" from 2021
CLDF dataset derived from Robbeets et al.'s "Triangulation Supports Agricultural Spread" from 2021 How to cite If you use these data please cite the o
 2 Dec 20, 2021
2 Dec 20, 2021

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022

Official Code for VideoLT: Large-scale Long-tailed Video Recognition (ICCV 2021)
Pytorch Code for VideoLT [Website][Paper] Updates [10/29/2021] Features uploaded to Google Drive, for access please send us an e-mail: zhangxing18 at
 26 Sep 18, 2022
26 Sep 18, 2022
Python library for computer vision labeling tasks. The core functionality is to translate bounding box annotations between different formats-for example, from coco to yolo.
PyLabel pip install pylabel PyLabel is a Python package to help you prepare image datasets for computer vision models including PyTorch and YOLOv5. I
 176 Jan 1, 2023
176 Jan 1, 2023
The world's largest toxicity dataset.
The Toxicity Dataset by Surge AI Saving the internet is fun. Combing through thousands of online comments to build a toxicity dataset isn't. That's wh
 134 Dec 19, 2022
134 Dec 19, 2022

The Habitat-Matterport 3D Research Dataset - the largest-ever dataset of 3D indoor spaces.
Habitat-Matterport 3D Dataset (HM3D) The Habitat-Matterport 3D Research Dataset is the largest-ever dataset of 3D indoor spaces. It consists of 1,000
 62 Dec 27, 2022
62 Dec 27, 2022
JUSTICE: A Benchmark Dataset for Supreme Court’s Judgment Prediction
JUSTICE: A Benchmark Dataset for Supreme Court’s Judgment Prediction CSCI 544 Final Project done by: Mohammed Alsayed, Shaayan Syed, Mohammad Alali, S
 3 Dec 28, 2022
3 Dec 28, 2022
Codes for the compilation and visualization examples to the HIF vegetation dataset
High-impedance vegetation fault dataset This repository contains the codes that compile the "Vegetation Conduction Ignition Test Report" data, which a
 1 Dec 12, 2021
1 Dec 12, 2021

Multiview 3D object detection on MultiviewC dataset through moft3d.
Voxelized 3D Feature Aggregation for Multiview Detection [arXiv] Multiview 3D object detection on MultiviewC dataset through VFA. Introduction We prop
 20 Dec 21, 2022
20 Dec 21, 2022
This is the official github repository of the Met dataset
The Met dataset This is the official github repository of the Met dataset. The official webpage of the dataset can be found here. What is it? This cod
 35 Dec 17, 2022
35 Dec 17, 2022
NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles
NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles NewsMTSC is a dataset for target-dependent sentiment classification (TSC)
 79 Dec 30, 2022
79 Dec 30, 2022
Data pipelines for both TensorFlow and PyTorch!
rapidnlp-datasets Data pipelines for both TensorFlow and PyTorch ! If you want to load public datasets, try: tensorflow/datasets huggingface/datasets
 1 Dec 8, 2021
1 Dec 8, 2021
A Simple Example for Imitation Learning with Dataset Aggregation (DAGGER) on Torcs Env
Imitation Learning with Dataset Aggregation (DAGGER) on Torcs Env This repository implements a simple algorithm for imitation learning: DAGGER. In thi
 66 Nov 23, 2022
66 Nov 23, 2022
Hierarchical Attentive Recurrent Tracking
Hierarchical Attentive Recurrent Tracking This is an official Tensorflow implementation of single object tracking in videos by using hierarchical atte
 147 Aug 7, 2021
147 Aug 7, 2021
Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning"
CAPGNN Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning" Paper URL: https://ar
 1 Mar 12, 2022
1 Mar 12, 2022
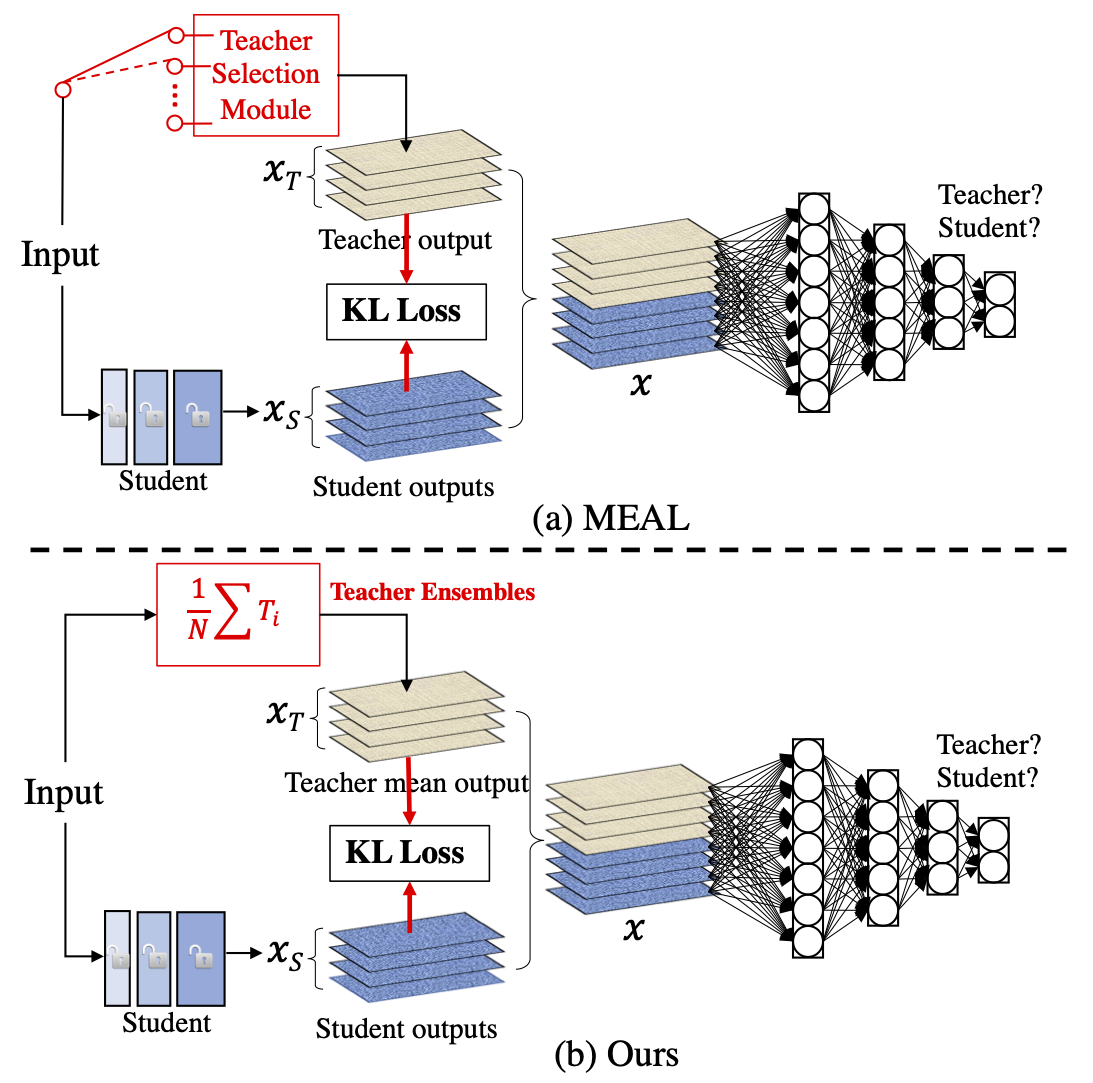
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022
DaReCzech is a dataset for text relevance ranking in Czech
Dataset DaReCzech is a dataset for text relevance ranking in Czech. The dataset consists of more than 1.6M annotated query-documents pairs,
 8 Jul 26, 2022
8 Jul 26, 2022
public repo for ESTER dataset and modeling (EMNLP'21)
Project / Paper Introduction This is the project repo for our EMNLP'21 paper: https://arxiv.org/abs/2104.08350 Here, we provide brief descriptions of
 19 Oct 27, 2022
19 Oct 27, 2022
The official homepage of the (outdated) COCO-Stuff 10K dataset.
COCO-Stuff 10K dataset v1.1 (outdated) Holger Caesar, Jasper Uijlings, Vittorio Ferrari Overview Welcome to official homepage of the COCO-Stuff [1] da
 263 Dec 11, 2022
263 Dec 11, 2022

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
223 Dec 5, 2022

Joint Detection and Identification Feature Learning for Person Search
Person Search Project This repository hosts the code for our paper Joint Detection and Identification Feature Learning for Person Search. The code is
 712 Dec 17, 2022
712 Dec 17, 2022
Source code and dataset for ACL 2019 paper "ERNIE: Enhanced Language Representation with Informative Entities"
ERNIE Source code and dataset for "ERNIE: Enhanced Language Representation with Informative Entities" Reqirements: Pytorch=0.4.1 Python3 tqdm boto3 r
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022

CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
CSAW-M This repository contains code for CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer. Source code for tr
 7 Oct 11, 2022
7 Oct 11, 2022

PartImageNet is a large, high-quality dataset with part segmentation annotations
PartImageNet: A Large, High-Quality Dataset of Parts We will release our dataset and scripts soon after cleaning and approval. Introduction PartImageN
 77 Nov 30, 2022
77 Nov 30, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021
The Malware Open-source Threat Intelligence Family dataset contains 3,095 disarmed PE malware samples from 454 families
MOTIF Dataset The Malware Open-source Threat Intelligence Family (MOTIF) dataset contains 3,095 disarmed PE malware samples from 454 families, labeled
 112 Dec 13, 2022
112 Dec 13, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022
The official homepage of the COCO-Stuff dataset.
The COCO-Stuff dataset Holger Caesar, Jasper Uijlings, Vittorio Ferrari Welcome to official homepage of the COCO-Stuff [1] dataset. COCO-Stuff augment
715 Dec 31, 2022
Python script to download the celebA-HQ dataset from google drive
download-celebA-HQ Python script to download and create the celebA-HQ dataset. WARNING from the author. I believe this script is broken since a few mo
 133 Dec 21, 2022
133 Dec 21, 2022
[3DV 2021] A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
dispersion-score Official implementation of 3DV 2021 Paper A Dataset-dispersion Perspective on Reconstruction versus Recognition in Single-view 3D Rec
 7 May 28, 2022
7 May 28, 2022

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022
Dataset and codebase for NeurIPS 2021 paper: Exploring Forensic Dental Identification with Deep Learning
Repository under construction. Example dataset, checkpoints, and training/testing scripts will be avaible soon! 💡 Collated best practices from most p
 4 Jun 26, 2022
4 Jun 26, 2022
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Cluttered MNIST Dataset
Cluttered MNIST Dataset A setup script will download MNIST and produce mnist/*.t7 files: luajit download_mnist.lua Example usage: local mnist_clutter
 50 Jul 12, 2022
50 Jul 12, 2022
A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset
xwrf A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset. The primary objective of
 43 Nov 29, 2022
43 Nov 29, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Project to deploy a machine learning model based on Titanic dataset from Kaggle
kaggle_titanic_deploy Project to deploy a machine learning model based on Titanic dataset from Kaggle In this project we used the Titanic dataset from
 8 May 23, 2022
8 May 23, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Dataset and Source code of paper 'Enhancing Keyphrase Extraction from Academic Articles with their Reference Information'.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information Overview Dataset and code for paper "Enhancing Keyphrase Extrac
 15 Nov 24, 2022
15 Nov 24, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
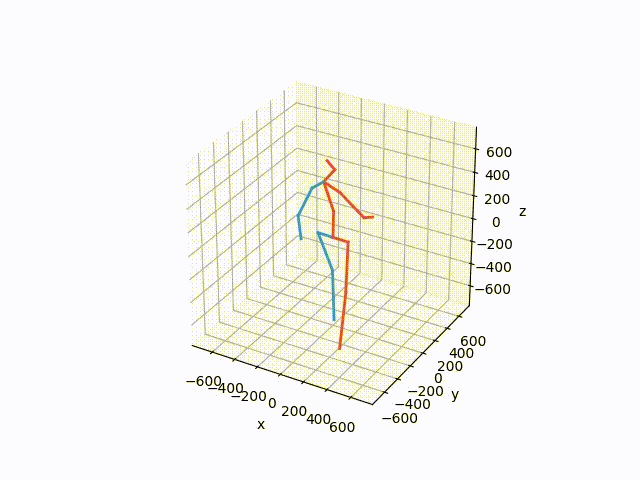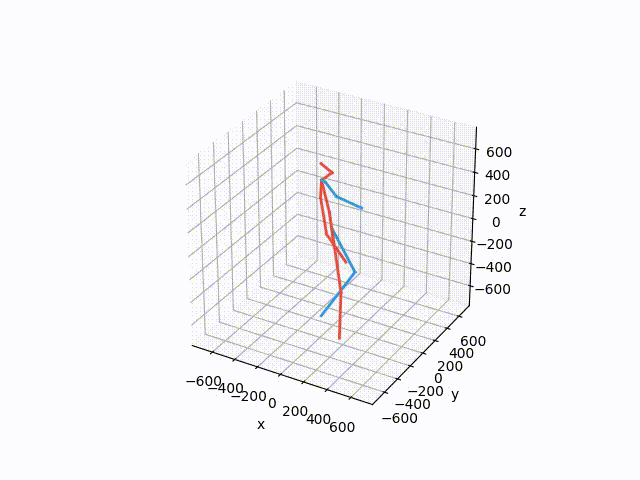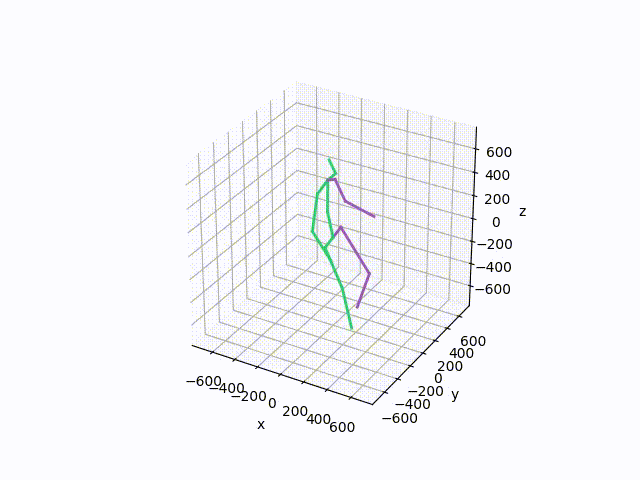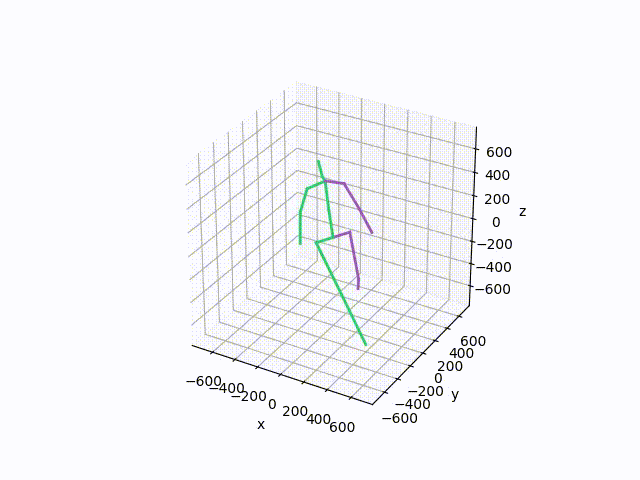
Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset.
Visualization-of-Human3.6M-Dataset Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset. human-motion-prediction
 5 Nov 18, 2022
5 Nov 18, 2022
A benchmark dataset for mesh multi-label-classification based on cube engravings introduced in MeshCNN
Double Cube Engravings This script creates a dataset for multi-label mesh clasification, with an intentionally difficult setup for point cloud classif
 1 Nov 30, 2021
1 Nov 30, 2021
A fast, dataset-agnostic, deep visual search engine for digital art history
imgs.ai imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings. It utilizes modern
 5 Dec 14, 2022
5 Dec 14, 2022
Predicting diabetes over a five year period using logistic regression and the Pima First-Nation dataset
Diabetes This script uses the Pima First Nations dataset to create a model to predict whether or not an individual will develop Diabetes Mellitus Type
 1 Mar 28, 2022
1 Mar 28, 2022
Train an imgs.ai model on your own dataset
imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings.
5 Dec 21, 2021

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This repository contains the source code of our work on designing efficient CNNs for computer vision
Efficient networks for Computer Vision This repo contains source code of our work on designing efficient networks for different computer vision tasks:
 386 Nov 26, 2022
386 Nov 26, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
LSUN Dataset Documentation and Demo Code
LSUN Please check LSUN webpage for more information about the dataset. Data Release All the images in one category are stored in one lmdb database fil
 426 Jan 2, 2023
426 Jan 2, 2023
A new test set for ImageNet
ImageNetV2 The ImageNetV2 dataset contains new test data for the ImageNet benchmark. This repository provides associated code for assembling and worki
 186 Dec 18, 2022
186 Dec 18, 2022
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
 10.1k Dec 30, 2022
10.1k Dec 30, 2022

We are building an open database of COVID-19 cases with chest X-ray or CT images.
🛑 Note: please do not claim diagnostic performance of a model without a clinical study! This is not a kaggle competition dataset. Please read this pa
 2.9k Dec 30, 2022
2.9k Dec 30, 2022
Python code for loading the Aschaffenburg Pose Dataset.
Aschaffenburg Pose Dataset (APD) This repository contains Python code for loading and filtering the Aschaffenburg Pose Dataset. The dataset itself and
 1 Nov 26, 2021
1 Nov 26, 2021

Unofficial PyTorch implementation of "RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving" (ECCV 2020)
RTM3D-PyTorch The PyTorch Implementation of the paper: RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving (ECCV 2020
 271 Nov 29, 2022
271 Nov 29, 2022

Benchmarks for the Optimal Power Flow Problem
Power Grid Lib - Optimal Power Flow This benchmark library is curated and maintained by the IEEE PES Task Force on Benchmarks for Validation of Emergi
 207 Dec 8, 2022
207 Dec 8, 2022
The devkit of the nuScenes dataset.
nuScenes devkit Welcome to the devkit of the nuScenes and nuImages datasets. Overview Changelog Devkit setup nuImages nuImages setup Getting started w
 1.6k Jan 5, 2023
1.6k Jan 5, 2023

A large-scale face dataset for face parsing, recognition, generation and editing.
CelebAMask-HQ [Paper] [Demo] CelebAMask-HQ is a large-scale face image dataset that has 30,000 high-resolution face images selected from the CelebA da
 1.7k Dec 26, 2022
1.7k Dec 26, 2022
Python script for diving image data to train test and val
dataset-division-to-train-val-test-python python script for dividing image data to train test and val If you have an image dataset in the following st
 1 Nov 14, 2022
1 Nov 14, 2022
An open source algorithm and dataset for finding poop in pictures.
The shitspotter module is where I will be work on the "shitspotter" poop-detection algorithm and dataset. The primary goal of this work is to allow for the creation of a phone app that finds where your dog pooped, because you ran to grab the doggy-bags you forgot, and now you can't find the damn thing.
 29 Nov 29, 2022
29 Nov 29, 2022
A colab notebook for training Stylegan2-ada on colab, transfer learning onto your own dataset.
Stylegan2-Ada-Google-Colab-Starter-Notebook A no thrills colab notebook for training Stylegan2-ada on colab. transfer learning onto your own dataset h
 66 Dec 16, 2022
66 Dec 16, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023
Command-line tool for downloading and extending the RedCaps dataset.
RedCaps Downloader This repository provides the official command-line tool for downloading and extending the RedCaps dataset. Users can seamlessly dow
 33 Dec 14, 2022
33 Dec 14, 2022
Official Implementation of "Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras"
Multi Camera Pig Tracking Official Implementation of Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras CVPR2021 CV4Animals Workshop P
 44 Jan 6, 2023
44 Jan 6, 2023

Curating a dataset for bioimage transfer learning
CytoImageNet A large-scale pretraining dataset for bioimage transfer learning. Motivation In past few decades, the increase in speed of data collectio
 9 Jun 20, 2022
9 Jun 20, 2022
The source code and dataset for the RecGURU paper (WSDM 2022)
RecGURU About The Project Source code and baselines for the RecGURU paper "RecGURU: Adversarial Learning of Generalized User Representations for Cross
 17 Jan 7, 2023
17 Jan 7, 2023

A tutorial on training a DarkNet YOLOv4 model for the CrowdHuman dataset
YOLOv4 CrowdHuman Tutorial This is a tutorial demonstrating how to train a YOLOv4 people detector using Darknet and the CrowdHuman dataset. Table of c
 118 Nov 10, 2022
118 Nov 10, 2022
Lacmus is a cross-platform application that helps to find people who are lost in the forest using computer vision and neural networks.
lacmus The program for searching through photos from the air of lost people in the forest using Retina Net neural nwtwork. The project is being develo
 168 Dec 27, 2022
168 Dec 27, 2022
Txt2Xml tool will help you convert from txt COCO format to VOC xml format in Object Detection Problem.
TXT 2 XML All codes assume running from root directory. Please update the sys path at the beginning of the codes before running. Over View Txt2Xml too
 4 Nov 24, 2022
4 Nov 24, 2022
Source code and notebooks to reproduce experiments and benchmarks on Bias Faces in the Wild (BFW).
Face Recognition: Too Bias, or Not Too Bias? Robinson, Joseph P., Gennady Livitz, Yann Henon, Can Qin, Yun Fu, and Samson Timoner. "Face recognition:
 41 Dec 12, 2022
41 Dec 12, 2022

Predicting the usefulness of reviews given the review text and metadata surrounding the reviews.
Predicting Yelp Review Quality Table of Contents Introduction Motivation Goal and Central Questions The Data Data Storage and ETL EDA Data Pipeline Da
 3 Nov 27, 2022
3 Nov 27, 2022

This repository will help you get label for images in Stanford Cars Dataset.
STANFORD CARS DATASET stanford-cars "The Cars dataset contains 16,185 images of 196 classes of cars. The data is split into 8,144 training images and
3 Sep 20, 2022
Json2Xml tool will help you convert from json COCO format to VOC xml format in Object Detection Problem.
JSON 2 XML All codes assume running from root directory. Please update the sys path at the beginning of the codes before running. Over View Json2Xml t
6 Aug 22, 2022