907 Repositories
Python nlp-datasets Libraries
Leaf: Multiple-Choice Question Generation
Leaf: Multiple-Choice Question Generation Easy to use and understand multiple-choice question generation algorithm using T5 Transformers. The applicat
 62 Dec 20, 2022
62 Dec 20, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022

Predict the spans of toxic posts that were responsible for the toxic label of the posts
toxic-spans-detection An attempt at the SemEval 2021 Task 5: Toxic Spans Detection. The Toxic Spans Detection task of SemEval2021 required participant
 3 Jul 24, 2022
3 Jul 24, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023

This Repository is an up-to-date version of Harvard nlp's Legacy code and a Refactoring of the jupyter notebook version as a shell script version.
This Repository is an up-to-date version of Harvard nlp's Legacy code and a Refactoring of the jupyter notebook version as a shell script version.
 17 Sep 25, 2022
17 Sep 25, 2022
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

Twitter bot that uses NLP models to summarize news articles referenced in a user's twitter timeline
Twitter-News-Summarizer Twitter bot that uses NLP models to summarize news articles referenced in a user's twitter timeline 1.) Extracts all tweets fr
 1 Jan 27, 2022
1 Jan 27, 2022

This is a NLP based project to extract effective date of the contract from their text files.
Date-Extraction-from-Contracts This is a NLP based project to extract effective date of the contract from their text files. Problem statement This is
 1 Jan 26, 2022
1 Jan 26, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022
Toward Model Interpretability in Medical NLP
Toward Model Interpretability in Medical NLP LING380: Topics in Computational Linguistics Final Project James Cross ([email protected]) and Daniel Kim
 1 Mar 4, 2022
1 Mar 4, 2022
Wikipedia-Utils: Preprocessing Wikipedia Texts for NLP
Wikipedia-Utils: Preprocessing Wikipedia Texts for NLP This repository maintains some utility scripts for retrieving and preprocessing Wikipedia text
 44 Oct 19, 2022
44 Oct 19, 2022
BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions
BERTopic BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable
 3.6k Jan 7, 2023
3.6k Jan 7, 2023

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023
Stanford CoreNLP provides a set of natural language analysis tools written in Java
Stanford CoreNLP Stanford CoreNLP provides a set of natural language analysis tools written in Java. It can take raw human language text input and giv
 8.8k Jan 7, 2023
8.8k Jan 7, 2023
Japanese NLP Library
Japanese NLP Library Back to Home Contents 1 Requirements 1.1 Links 1.2 Install 1.3 History 2 Libraries and Modules 2.1 Tokenize jTokenize.py 2.2 Cabo
 144 Dec 27, 2022
144 Dec 27, 2022

Open solution to the Toxic Comment Classification Challenge
Starter code: Kaggle Toxic Comment Classification Challenge More competitions 🎇 Check collection of public projects 🎁 , where you can find multiple
 153 Jun 22, 2022
153 Jun 22, 2022
Deep Learning Topics with Computer Vision & NLP
Deep learning Udacity Course Deep Learning Topics with Computer Vision & NLP for the AWS Machine Learning Engineer Nanodegree Program Tasks are mostly
 1 Jan 20, 2022
1 Jan 20, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022
Blackstone is a spaCy model and library for processing long-form, unstructured legal text
Blackstone Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project f
 579 Jan 8, 2023
579 Jan 8, 2023

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Original Implementation of Prompt Tuning from Lester, et al, 2021
Prompt Tuning This is the code to reproduce the experiments from the EMNLP 2021 paper "The Power of Scale for Parameter-Efficient Prompt Tuning" (Lest
 282 Dec 28, 2022
282 Dec 28, 2022
Awesome AI Learning with +100 AI Cheat-Sheets, Free online Books, Top Courses, Best Videos and Lectures, Papers, Tutorials, +99 Researchers, Premium Websites, +121 Datasets, Conferences, Frameworks, Tools
All about AI with Cheat-Sheets(+100 Cheat-sheets), Free Online Books, Courses, Videos and Lectures, Papers, Tutorials, Researchers, Websites, Datasets
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
84 Dec 20, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022

In this project, we compared Spanish BERT and Multilingual BERT in the Sentiment Analysis task.
Applying BERT Fine Tuning to Sentiment Classification on Amazon Reviews Abstract Sentiment analysis has made great progress in recent years, due to th
 5 Jan 3, 2022
5 Jan 3, 2022

Twitter-NLP-Analysis - Twitter Natural Language Processing Analysis
Twitter-NLP-Analysis Business Problem I got last @turk_politika 3000 tweets with
 7 Mar 12, 2022
7 Mar 12, 2022
Repositório do trabalho de introdução a NLP
Trabalho da disciplina de BI NLP Repositório do trabalho da disciplina Introdução a Processamento de Linguagem Natural da pós BI-Master da PUC-RIO. Eq
 1 Jan 18, 2022
1 Jan 18, 2022
In this Notebook I've build some machine-learning and deep-learning to classify corona virus tweets, in both multi class classification and binary classification.
Hello, This Notebook Contains Example of Corona Virus Tweets Multi Class Classification. - Classes is: Extremely Positive, Positive, Extremely Negativ
 3 Dec 6, 2022
3 Dec 6, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
Few-Shot-Intent-Detection includes popular challenging intent detection datasets with/without OOS queries and state-of-the-art baselines and results.
Few-Shot-Intent-Detection Few-Shot-Intent-Detection is a repository designed for few-shot intent detection with/without Out-of-Scope (OOS) intents. It
 73 Dec 26, 2022
73 Dec 26, 2022

Python Auto-ML Package for Tabular Datasets
Tabular-AutoML AutoML Package for tabular datasets Tabular dataset tuning is now hassle free! Run one liner command and get best tuning and processed
 18 Nov 20, 2022
18 Nov 20, 2022
A natural language processing model for sequential sentence classification in medical abstracts.
NLP PubMed Medical Research Paper Abstract (Randomized Controlled Trial) A natural language processing model for sequential sentence classification in
 1 Jan 17, 2022
1 Jan 17, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 847 Dec 19, 2022
847 Dec 19, 2022

In this project, we aim to achieve the task of predicting emojis from tweets. We aim to investigate the relationship between words and emojis.
Making Emojis More Predictable by Karan Abrol, Karanjot Singh and Pritish Wadhwa, Natural Language Processing (CSE546) under the guidance of Dr. Shad
 2 Jan 17, 2022
2 Jan 17, 2022
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes The codes for simu
 1 Jan 12, 2022
1 Jan 12, 2022
[ WSDM '22 ] On Sampling Collaborative Filtering Datasets
On Sampling Collaborative Filtering Datasets This repository contains the implementation of many popular sampling strategies, along with various expli
 17 Dec 8, 2022
17 Dec 8, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023
An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're feeling.
Disease detection API for MediSearch An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're fe
 1 Jan 15, 2022
1 Jan 15, 2022
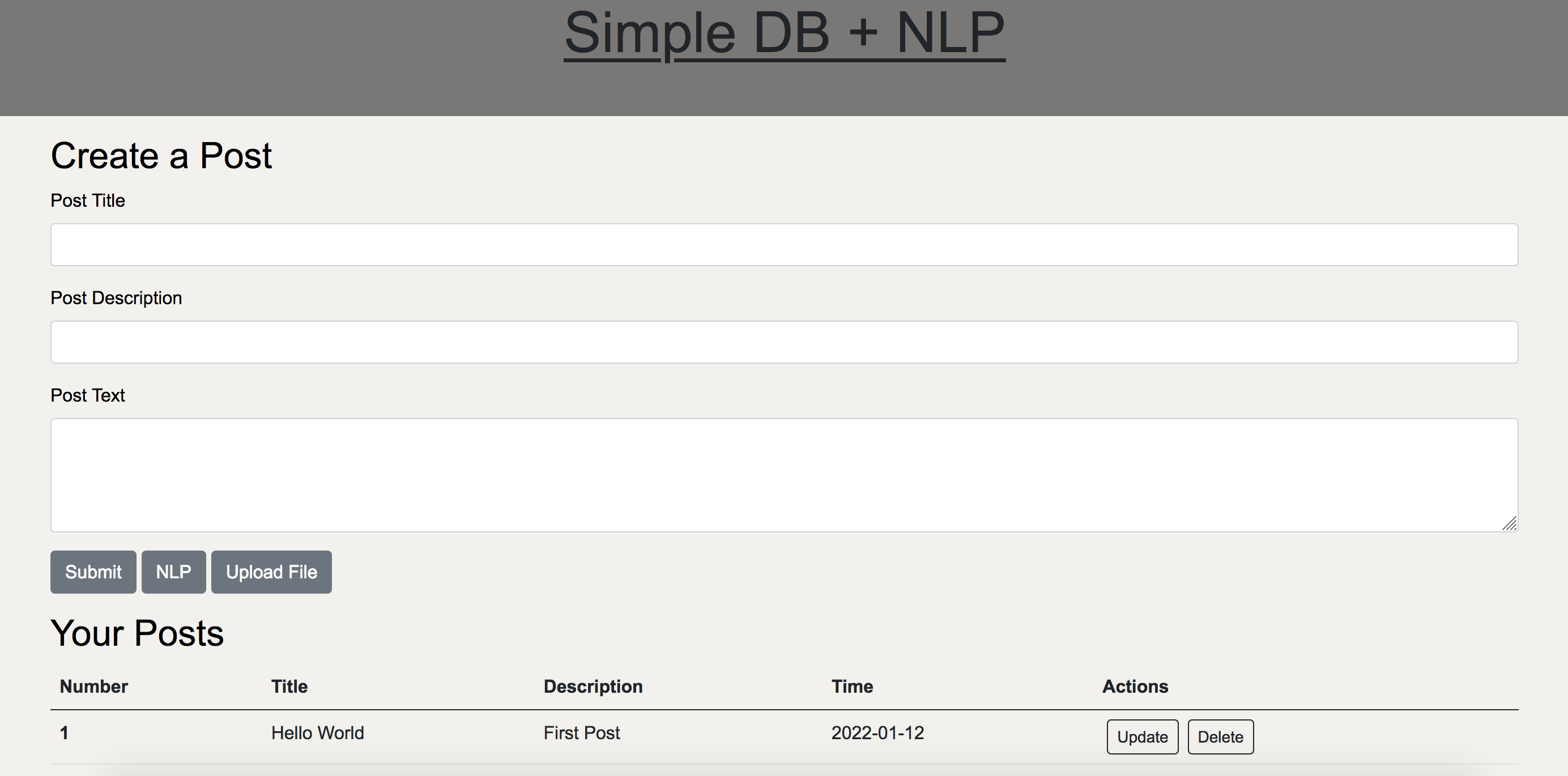
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
 1 Jan 15, 2022
1 Jan 15, 2022
NLP: SLU tagging
NLP: SLU tagging
 3 Jan 14, 2022
3 Jan 14, 2022

auto_code_complete is a auto word-completetion program which allows you to customize it on your need
auto_code_complete v1.3 purpose and usage auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the m
 2 Feb 22, 2022
2 Feb 22, 2022
Cl datasets - PyTorch image dataloaders and utility functions to load datasets for supervised continual learning
Continual learning datasets Introduction This repository contains PyTorch image
 5 Aug 28, 2022
5 Aug 28, 2022

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
👄 The most accurate natural language detection library for Python, suitable for long and short text alike
1. What does this library do? Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a prepr
 334 Dec 30, 2022
334 Dec 30, 2022

Sentiment-Analysis and EDA on the IMDB Movie Review Dataset
Sentiment-Analysis and EDA on the IMDB Movie Review Dataset The main part of the work focuses on the exploration and study of different approaches whi
 1 Jan 12, 2022
1 Jan 12, 2022
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023
Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis
Introduction This is an implementation of our paper Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis.
 24 Dec 6, 2022
24 Dec 6, 2022
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022

A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets
HOW TO USE THIS PROJECT A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets Based on DeepLabCut toolbox, we run wit
 1 Jan 10, 2022
1 Jan 10, 2022
![[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021](https://github.com/hasanirtiza/Pedestron/raw/master/gifs/1.gif)
[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021
Pedestron Pedestron is a MMdetection based repository, that focuses on the advancement of research on pedestrian detection. We provide a list of detec
 594 Jan 5, 2023
594 Jan 5, 2023
Exploration of BERT-based models on twitter sentiment classifications
twitter-sentiment-analysis Explore the relationship between twitter sentiment of Tesla and its stock price/return. Explore the effect of different BER
 2 Oct 2, 2022
2 Oct 2, 2022

A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
 65 Dec 19, 2022
65 Dec 19, 2022
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023
Code and data accompanying Natural Language Processing with PyTorch
Natural Language Processing with PyTorch Build Intelligent Language Applications Using Deep Learning By Delip Rao and Brian McMahan Welcome. This is a
 1.8k Jan 1, 2023
1.8k Jan 1, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
Auto_code_complete is a auto word-completetion program which allows you to customize it on your needs
auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the model for this program is one of the deep-learning NLP(Natural Language Process) model structure called 'GRU(gated recurrent unit)'.
2 Feb 22, 2022
A general and strong 3D object detection codebase that supports more methods, datasets and tools (debugging, recording and analysis).
ALLINONE-Det ALLINONE-Det is a general and strong 3D object detection codebase built on OpenPCDet, which supports more methods, datasets and tools (de
 5 Nov 3, 2022
5 Nov 3, 2022

Beyond Accuracy: Behavioral Testing of NLP models with CheckList
CheckList This repository contains code for testing NLP Models as described in the following paper: Beyond Accuracy: Behavioral Testing of NLP models
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch
Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch. Topics: Face detection with Detectron 2, Time Series anomaly detection with LSTM Autoencoders, Object Detection with YOLO v5, Build your first Neural Network, Time Series forecasting for Coronavirus daily cases, Sentiment Analysis with BERT.
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
Mycroft Core, the Mycroft Artificial Intelligence platform.
Mycroft Mycroft is a hackable open source voice assistant. Table of Contents Getting Started Running Mycroft Using Mycroft Home Device and Account Man
 6.1k Jan 9, 2023
6.1k Jan 9, 2023
A list of NLP(Natural Language Processing) tutorials
NLP Tutorial A list of NLP(Natural Language Processing) tutorials built on PyTorch. Table of Contents A step-by-step tutorial on how to implement and
 1.3k Dec 25, 2022
1.3k Dec 25, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022

Keras implementation of "One pixel attack for fooling deep neural networks" using differential evolution on Cifar10 and ImageNet
One Pixel Attack How simple is it to cause a deep neural network to misclassify an image if an attacker is only allowed to modify the color of one pix
 1.2k Dec 26, 2022
1.2k Dec 26, 2022

Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
 5.3k Dec 30, 2022
5.3k Dec 30, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023

Repository for Project Insight: NLP as a Service
Project Insight NLP as a Service Contents Introduction Features Installation Setup and Documentation Project Details Demonstration Directory Details H
 286 Dec 6, 2022
286 Dec 6, 2022
Simple translation demo showcasing our headliner package.
Headliner Demo This is a demo showcasing our Headliner package. In particular, we trained a simple seq2seq model on an English-German dataset. We didn
 16 Nov 24, 2022
16 Nov 24, 2022

Rhyme with AI
Local development Create a conda virtual environment and activate it: conda env create --file environment.yml conda activate rhyme-with-ai Install the
 28 Nov 21, 2022
28 Nov 21, 2022

Streamlit tool to explore coco datasets
What is this This tool given a COCO annotations file and COCO predictions file will let you explore your dataset, visualize results and calculate impo
 75 Dec 16, 2022
75 Dec 16, 2022
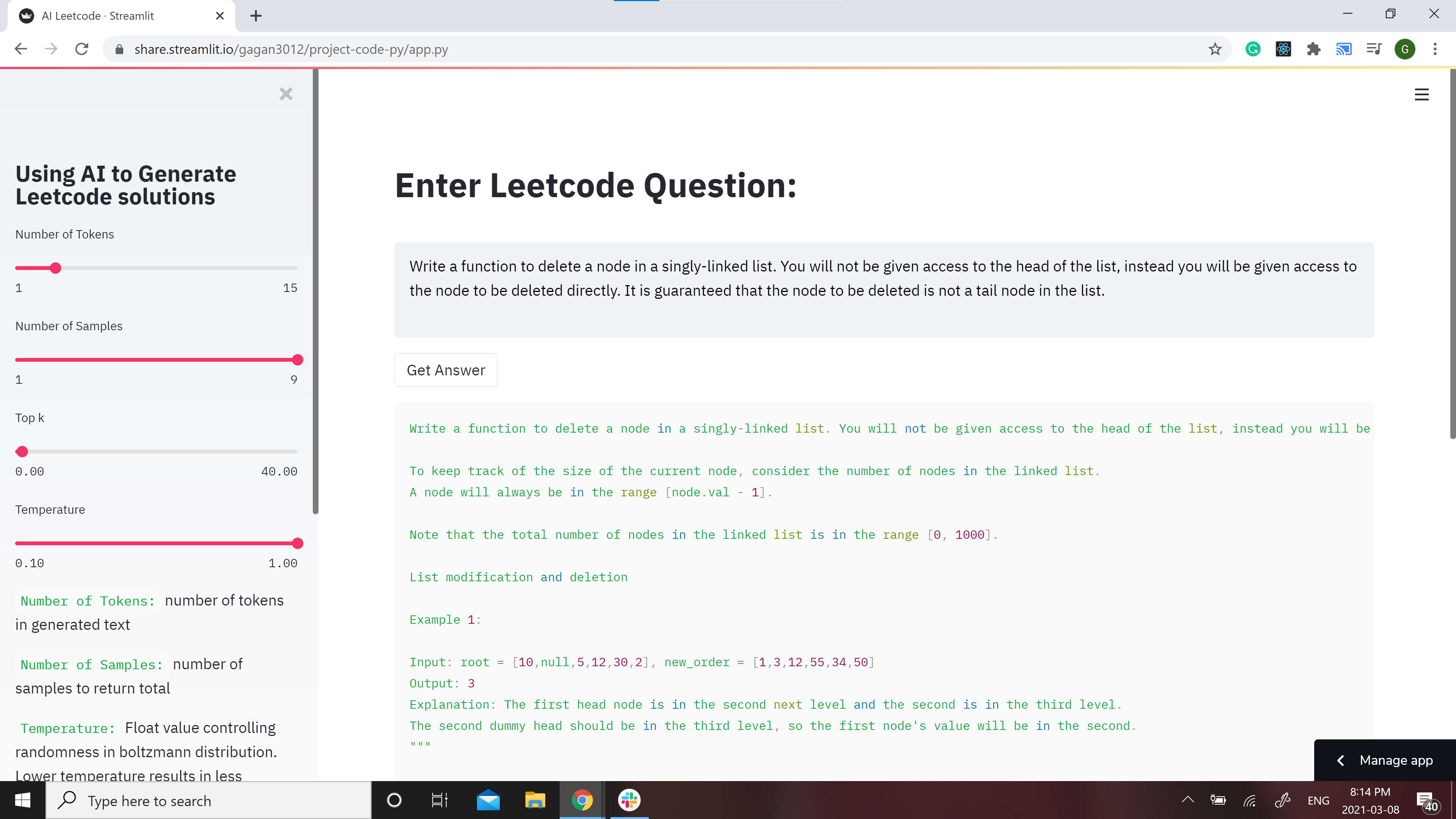
GPT-2 Model for Leetcode Questions in python
Leetcode using AI 🤖 GPT-2 Model for Leetcode Questions in python New demo here: https://huggingface.co/spaces/gagan3012/project-code-py Note: the Ans
 100 Dec 12, 2022
100 Dec 12, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022

Interactive dimensionality reduction for large datasets
BlosSOM 🌼 BlosSOM is a graphical environment for running semi-supervised dimensionality reduction with EmbedSOM. You can use it to explore multidimen
 19 Dec 14, 2022
19 Dec 14, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Using BERT-based models for toxic span detection
SemEval 2021 Task 5: Toxic Spans Detection: Task: Link to SemEval-2021: Task 5 Toxic Span Detection is https://competitions.codalab.org/competitions/2
 1 Jan 4, 2022
1 Jan 4, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023

NLP-Project - Used an API to scrape 2000 reddit posts, then used NLP analysis and created a classification model to mixed succcess
Project 3: Web APIs & NLP Problem Statement How do r/Libertarian and r/Neoliberal differ on Biden post-inaguration? The goal of the project is to see
 2 Mar 29, 2022
2 Mar 29, 2022
NLP-SentimentAnalysis - Coursera Course ( Duration : 5 weeks ) offered by DeepLearning.AI
Coursera Natural Language Processing Specialization This repository contains material related to Coursera Natural Language Processing Specialization.
 1 Jun 5, 2022
1 Jun 5, 2022
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it. Study notes and a curated list of awesome resources of such topics.
 1.2k Jan 7, 2023
1.2k Jan 7, 2023

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

KoBERT - Korean BERT pre-trained cased (KoBERT)
KoBERT KoBERT Korean BERT pre-trained cased (KoBERT) Why'?' Training Environment Requirements How to install How to use Using with PyTorch Using with
 1k Jan 2, 2023
1k Jan 2, 2023
News-Articles-and-Essays - NLP (Topic Modeling and Clustering)
NLP T5 Project proposal Topic Modeling and Clustering of News-Articles-and-Essays Students: Nasser Alshehri Abdullah Bushnag Abdulrhman Alqurashi OVER
 2 Jan 18, 2022
2 Jan 18, 2022
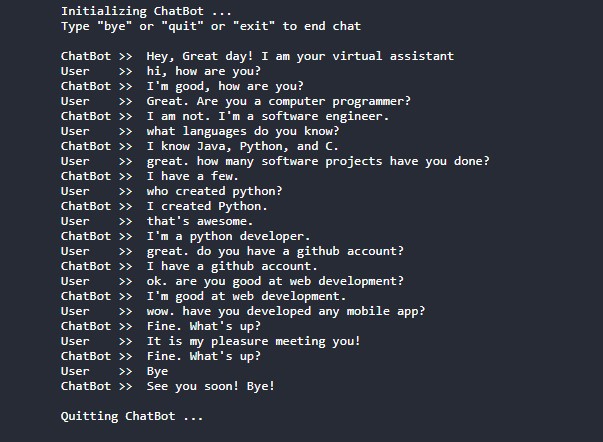
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022
A recommendation system for suggesting new books given similar books.
Book Recommendation System A recommendation system for suggesting new books given similar books. Datasets Dataset Kaggle Dataset Notebooks goodreads-E
 2 Jan 6, 2022
2 Jan 6, 2022

SPT_LSA_ViT - Implementation for Visual Transformer for Small-size Datasets
Vision Transformer for Small-Size Datasets Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song | Paper Inha University Abstract Recently, the Vision
 87 Jan 1, 2023
87 Jan 1, 2023
StyleGAN2-ADA-training-jupyter - Training custom datasets in styleGAN2-ADA by NVIDIA using Jupyter
styleGAN2-ADA-training-jupyter Training custom datasets in styleGAN2-ADA on Jupyter Official StyleGAN2-ADA by NIVIDIA Paper Training Generative Advers
 2 Feb 24, 2022
2 Feb 24, 2022

Search-Engine - 📖 AI based search engine
Search Engine AI based search engine that was trained on 25000 samples, feel free to train on up to 1.2M sample from kaggle dataset, link below StackS
 2 Nov 29, 2022
2 Nov 29, 2022

A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
 335 Jan 4, 2023
335 Jan 4, 2023

Natural Language Processing for Adverse Drug Reaction (ADR) Detection
Natural Language Processing for Adverse Drug Reaction (ADR) Detection This repo contains code from a project to identify ADRs in discharge summaries a
 21 Aug 5, 2022
21 Aug 5, 2022