907 Repositories
Python nlp-datasets Libraries
NLP, Machine learning
Netflix-recommendation-system NLP, Machine learning About Recommendation algorithms are at the core of the Netflix product. It provides their members
 6 Jan 12, 2022
6 Jan 12, 2022
novel deep learning research works with PaddlePaddle
Research 发布基于飞桨的前沿研究工作,包括CV、NLP、KG、STDM等领域的顶会论文和比赛冠军模型。 目录 计算机视觉(Computer Vision) 自然语言处理(Natrual Language Processing) 知识图谱(Knowledge Graph) 时空数据挖掘(Spa
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
Benchmark datasets, data loaders, and evaluators for graph machine learning
Overview The Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover
 1.5k Jan 5, 2023
1.5k Jan 5, 2023
Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers.
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
 2 Oct 14, 2021
2 Oct 14, 2021
A cross-lingual COVID-19 fake news dataset
CrossFake An English-Chinese COVID-19 fake&real news dataset from the ICDMW 2021 paper below: Cross-lingual COVID-19 Fake News Detection. Jiangshu Du,
 11 Dec 1, 2022
11 Dec 1, 2022
Smart discord chatbot integrated with Dialogflow
academic-NLP-chatbot Smart discord chatbot integrated with Dialogflow to interact with students naturally and manage different classes in a school. De
 5 Oct 24, 2022
5 Oct 24, 2022

NLP topic mdel LDA - Gathered from New York Times website
NLP topic mdel LDA - Gathered from New York Times website
 1 Oct 14, 2021
1 Oct 14, 2021
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets that can be described as multidimensional arrays o
 411 Dec 27, 2022
411 Dec 27, 2022
Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database.
MIMIC-III Benchmarks Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database. Currently, the benchmark data
 6 Jan 2, 2023
6 Jan 2, 2023
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Tribuo - A Java machine learning library
Tribuo - A Java prediction library (v4.1) Tribuo is a machine learning library in Java that provides multi-class classification, regression, clusterin
 1.1k Dec 28, 2022
1.1k Dec 28, 2022
Train 🤗-transformers model with Poutyne.
poutyne-transformers Train 🤗 -transformers models with Poutyne. Installation pip install poutyne-transformers Example import torch from transformers
 2 Dec 18, 2022
2 Dec 18, 2022

Google's Meena transformer chatbot implementation
Here's my attempt at recreating Meena, a state of the art chatbot developed by Google Research and described in the paper Towards a Human-like Open-Domain Chatbot.
 94 Dec 25, 2022
94 Dec 25, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
A set of examples around hub for creating and processing datasets
Examples for Hub - Dataset Format for AI A repository showcasing examples of using Hub Uploading Dataset Places365 Colab Tutorials Notebook Link Getti
 11 Dec 14, 2022
11 Dec 14, 2022
A Python library for choreographing your machine learning research.
A Python library for choreographing your machine learning research.
 270 Jan 6, 2023
270 Jan 6, 2023
Signature remover is a NLP based solution which removes email signatures from the rest of the text.
Signature Remover Signature remover is a NLP based solution which removes email signatures from the rest of the text. It helps to enchance data conten
 8 Jan 6, 2023
8 Jan 6, 2023
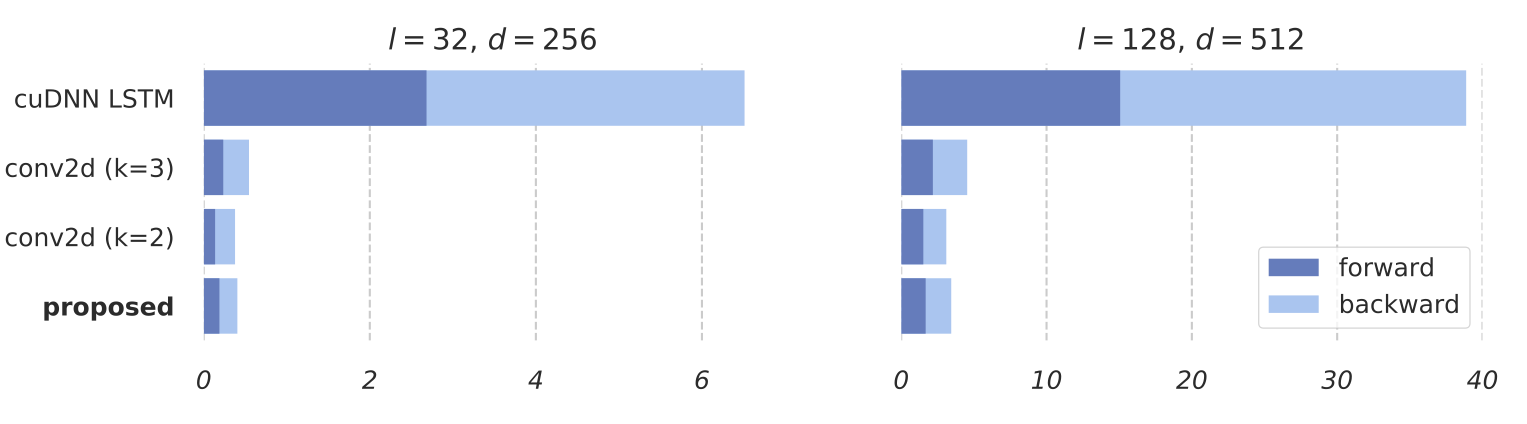
Training RNNs as Fast as CNNs
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
TorchXRayVision: A library of chest X-ray datasets and models.
torchxrayvision A library for chest X-ray datasets and models. Including pre-trained models. ( 🎬 promo video about the project) Motivation: While the
 575 Jan 8, 2023
575 Jan 8, 2023
Beyond Paragraphs: NLP for Long Sequences
Beyond Paragraphs: NLP for Long Sequences
338 Dec 2, 2022
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023
Paradigm Shift in NLP - "Paradigm Shift in Natural Language Processing".
Paradigm Shift in NLP Welcome to the webpage for "Paradigm Shift in Natural Language Processing". Some resources of the paper are constantly maintaine
 41 Dec 30, 2022
41 Dec 30, 2022

A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You can find two approaches for achieving this in this repo.
multitask-learning-transformers A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You
 48 Jan 2, 2023
48 Jan 2, 2023
Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ)
DeepNLP-models-Pytorch Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ: NLP with Deep Learning) This is not for Pytorch be
 2.9k Dec 24, 2022
2.9k Dec 24, 2022
An IPython Notebook tutorial on deep learning for natural language processing, including structure prediction.
Table of Contents: Introduction to Torch's Tensor Library Computation Graphs and Automatic Differentiation Deep Learning Building Blocks: Affine maps,
 1.8k Jan 4, 2023
1.8k Jan 4, 2023

C++ Implementation of PyTorch Tutorials for Everyone
C++ Implementation of PyTorch Tutorials for Everyone OS (Compiler)\LibTorch 1.9.0 macOS (clang 10.0, 11.0, 12.0) Linux (gcc 8, 9, 10, 11) Windows (msv
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023
Create Fast and easy image datasets using reddit
Reddit-Image-Scraper Reddit Reddit is an American Social news aggregation, web content rating, and discussion website. Reddit has been devided by topi
 4 Apr 27, 2022
4 Apr 27, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022
Universal Adversarial Triggers for Attacking and Analyzing NLP (EMNLP 2019)
Universal Adversarial Triggers for Attacking and Analyzing NLP This is the official code for the EMNLP 2019 paper, Universal Adversarial Triggers for
 248 Dec 17, 2022
248 Dec 17, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
730 Jan 9, 2023

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 4, 2023
7.1k Jan 4, 2023
Recurrent Variational Autoencoder that generates sequential data implemented with pytorch
Pytorch Recurrent Variational Autoencoder Model: This is the implementation of Samuel Bowman's Generating Sentences from a Continuous Space with Kim's
 347 Nov 14, 2022
347 Nov 14, 2022
A Domain Specific Language (DSL) for building language patterns. These can be later compiled into spaCy patterns, pure regex, or any other format
RITA DSL This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy co
 60 Sep 26, 2022
60 Sep 26, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
A2T: Towards Improving Adversarial Training of NLP Models (EMNLP 2021 Findings)
A2T: Towards Improving Adversarial Training of NLP Models This is the source code for the EMNLP 2021 (Findings) paper "Towards Improving Adversarial T
17 Oct 15, 2022

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 50 Dec 21, 2022
50 Dec 21, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022
Code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
This repository contains the code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
 28 Nov 10, 2022
28 Nov 10, 2022
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless. This is the official Roboflow python package that interfaces with the Roboflow API.
 52 Dec 23, 2022
52 Dec 23, 2022
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
23 Nov 30, 2022
An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results
EasyDatas An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results Installation pip install git+https
 4 Dec 14, 2021
4 Dec 14, 2021
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
 81 Dec 9, 2022
81 Dec 9, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
297 Dec 29, 2022

OpenCVのGrabCut()を利用したセマンティックセグメンテーション向けアノテーションツール(Annotation tool using GrabCut() of OpenCV. It can be used to create datasets for semantic segmentation.)
[Japanese/English] GrabCut-Annotation-Tool GrabCut-Annotation-Tool.mp4 OpenCVのGrabCut()を利用したアノテーションツールです。 セマンティックセグメンテーション向けのデータセット作成にご使用いただけます。 ※Grab
 30 Nov 18, 2022
30 Nov 18, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022
Ask for weather information like a human
weather-nlp About Ask for weather information like a human. Goals Understand typical questions like: Hourly temperatures in Potsdam on 2020-09-15. Rai
 5 Oct 29, 2022
5 Oct 29, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
The official repository for our paper "The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers". We significantly improve the systematic generalization of transformer models on a variety of datasets using simple tricks and careful considerations.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
 230 Nov 22, 2022
230 Nov 22, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022
GraphGT: Machine Learning Datasets for Graph Generation and Transformation
GraphGT: Machine Learning Datasets for Graph Generation and Transformation Dataset Website | Paper Installation Using pip To install the core environm
 50 Aug 18, 2022
50 Aug 18, 2022
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022
Base pretrained models and datasets in pytorch (MNIST, SVHN, CIFAR10, CIFAR100, STL10, AlexNet, VGG16, VGG19, ResNet, Inception, SqueezeNet)
This is a playground for pytorch beginners, which contains predefined models on popular dataset. Currently we support mnist, svhn cifar10, cifar100 st
 2.4k Dec 28, 2022
2.4k Dec 28, 2022
Minimal But Practical Image Classifier Pipline Using Pytorch, Finetune on ResNet18, Got 99% Accuracy on Own Small Datasets.
PyTorch Image Classifier Updates As for many users request, I released a new version of standared pytorch immage classification example at here: http:
 106 Nov 6, 2022
106 Nov 6, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
7.1k Jan 5, 2023
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

A complete NLP guideline for enthusiasts
NLP-NINJA A complete guide for Natural Language Processing in Python Table of Contents S.No. Topic Level Meaning 1 Tokenization 🤍 Beginner 2 Stemming
 22 Dec 27, 2022
22 Dec 27, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
65 Sep 13, 2022