466 Repositories
Python pdf-scraper-with-ocr Libraries
Produce pdf in python backend from simple bootstrap vue frontend and download to browser
vollmacht produce pdf in python backend from simple bootstrap vue frontend and download to browser Frontend in one file with bootstrap-vue (allthough
 1 Nov 8, 2020
1 Nov 8, 2020
Amazon scraper using scrapy, a python framework for crawling websites.
#Amazon-web-scraper This is a python program, which use scrapy python framework to crawl all pages of the product and scrap products data. This progra
 1 Dec 26, 2021
1 Dec 26, 2021
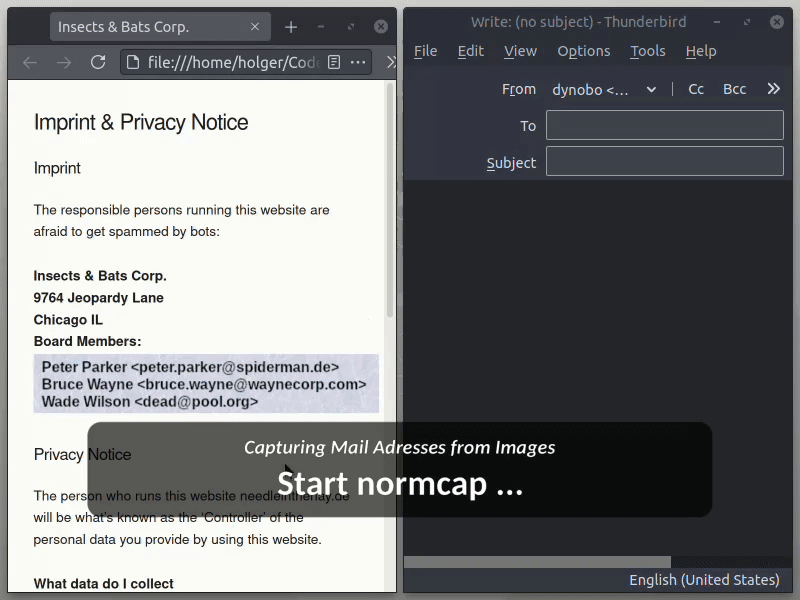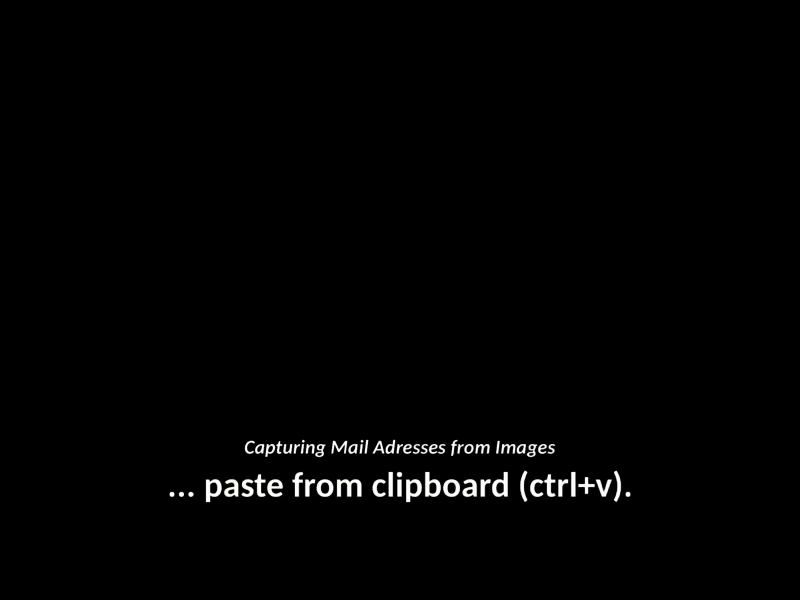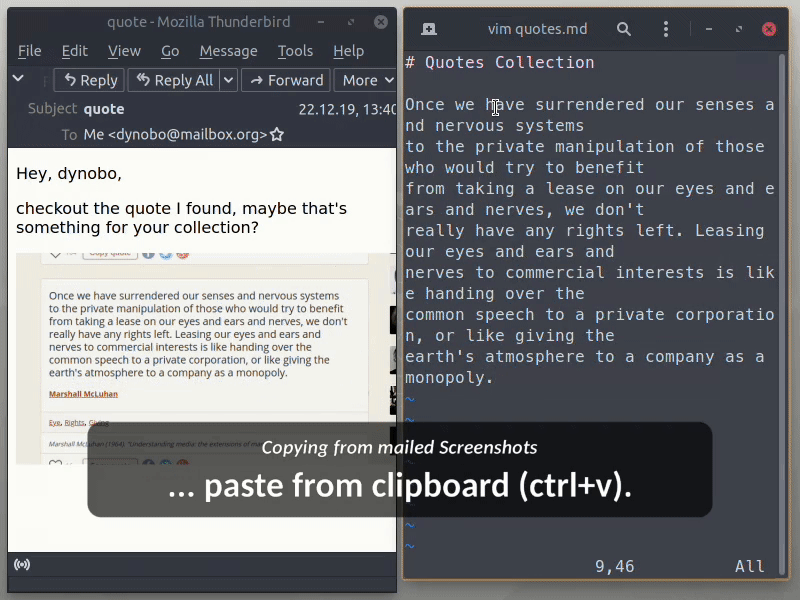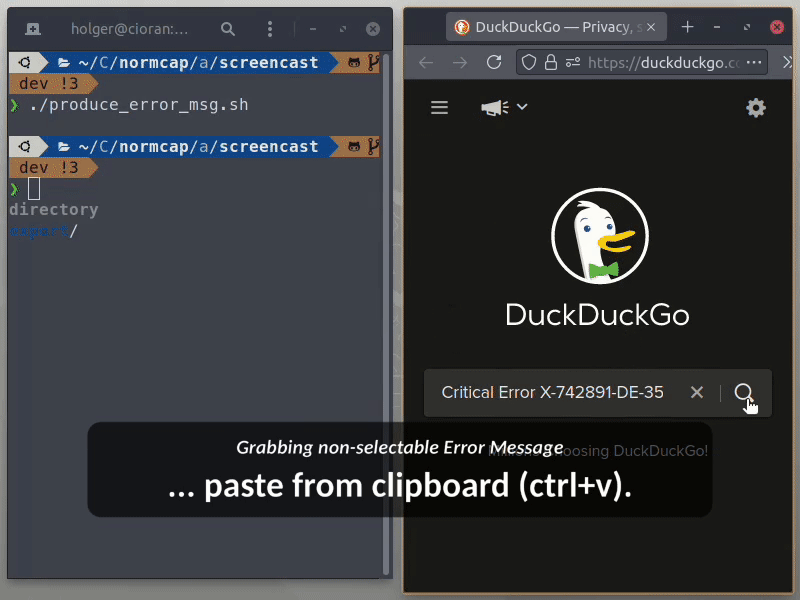
OCR powered screen-capture tool to capture information instead of images
NormCap OCR powered screen-capture tool to capture information instead of images. Links: Repo | PyPi | Releases | Changelog | FAQs Content: Quickstart
 575 Dec 31, 2022
575 Dec 31, 2022
Zen-Knit is a formal (PDF), informal (HTML) report generator for data analyst and data scientist who wants to use python.
About Zen-Knit: Zen-Knit is a formal (PDF), informal (HTML) report generator for data analyst and data scientist who wants to use python. Inspired fro
 27 Jul 13, 2022
27 Jul 13, 2022
Scrapes proxies and saves them to a text file
Proxy Scraper Scrapes proxies from https://proxyscrape.com and saves them to a file. Also has a customizable theme system Made by nell and Lamp
 2 Dec 22, 2021
2 Dec 22, 2021
Minecraft Item Scraper
Minecraft Item Scraper To run, first ensure you have the BeautifulSoup module: pip install bs4 Then run, python minecraft_items.py folder-to-save-ima
 1 Dec 29, 2021
1 Dec 29, 2021
Software that extracts spreadsheets from various .pdf files to .csv
Extração de planilhas de diversos arquivos .pdf para .csv O código inteiro foi desenvolvido em Python. Foi utilizado o pacote "tabula" e a biblioteca
 2 Jan 9, 2022
2 Jan 9, 2022

Simple pdf editor while preserving structure and format.
SIMPdf Simple pdf editor while preserving structure and format.
 242 Jan 4, 2023
242 Jan 4, 2023
Open clone of OpenAI's unreleased WebText dataset scraper.
Open clone of OpenAI's unreleased WebText dataset scraper. This version uses pushshift.io files instead of the API for speed.
 471 Dec 30, 2022
471 Dec 30, 2022
minipdf is a package for creating simple, single-page PDF documents.
minipdf minipdf is a package for creating simple, single-page PDF documents. Installation You can install the development version from GitHub with: #
 41 Dec 19, 2022
41 Dec 19, 2022
Crawl BookCorpus
These are scripts to reproduce BookCorpus by yourself.
 590 Jan 3, 2023
590 Jan 3, 2023
A simple Discord Mass Dm with Scraper
Python-Mass-DM A simple Discord Mass Dm with Scraper If Member Scraper in Taliban.py doesn't work. You can DM me cuz that scraper is for tokens that g
 4 Sep 2, 2022
4 Sep 2, 2022

Useful PDF-related productivity tool.
Luftmensch 1.4.7 (Español) | 1.4.3 (English) Version 1.4.7 (Español) released in October 2021. Version 1.4.3 (English) released in September 2021. 🏮
 8 Dec 29, 2022
8 Dec 29, 2022

Scans pdfs for links written in plaintext and checks if they are active or returns an error code.
Scans pdfs for links written in plaintext and checks if they are active or returns an error code. It then generates a report of its findings. Extract references (pdf, url, doi, arxiv) and metadata from a PDF.
 22 Nov 21, 2022
22 Nov 21, 2022

Google Developer Profile Badge Scraper
Google Developer Profile Badge Scraper It is a Google Developer Profile Web Scraper which scrapes for specific badges in a user's Google Developer Pro
 2 Feb 22, 2022
2 Feb 22, 2022

Convert given source code into .pdf with syntax highlighting and more features
Code2pdf 📠 Convert given source code into .pdf with syntax highlighting and more features Build Status Version Downloads Python Demo Installation Bui
 343 Jan 5, 2023
343 Jan 5, 2023
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
 3k Jan 2, 2023
3k Jan 2, 2023
Danbooru scraper with python
Danbooru Version: 0.0.1 License under: MIT License Dependencies Python: = 3.9.7 beautifulsoup4 cloudscraper Example of use Danbooru from danbooru imp
 2 Oct 27, 2022
2 Oct 27, 2022

Automate the case review on legal case documents and find the most critical cases using network analysis
Automation on Legal Court Cases Review This project is to automate the case review on legal case documents and find the most critical cases using netw
 7 Dec 28, 2022
7 Dec 28, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Little tool in python to watch anime from the terminal (the better way to watch anime)
anipy-cli Little tool in python to watch anime from the terminal (the better way to watch anime) Has a resume playback function when picking from Hist
 97 Dec 29, 2022
97 Dec 29, 2022
Scrapes Every Email Address of Every Society in Every University
society-email-scrape Site Live at https://kcsoc.github.io/society-email-scrape/ How to automatically generate new data Go to unis.yml Add your uni Cre
 18 Dec 14, 2022
18 Dec 14, 2022
Demo processor to illustrate OCR-D Python API
ocrd_vandalize/ Demo processor to illustrate the OCR-D/core Python API Description :TODO: write docs :) Installation From PyPI pip3 install ocrd_vanda
 5 May 5, 2022
5 May 5, 2022
A simple Discord scraper for discord bots
A simple Discord scraper for discord bots. That includes sending an guild members ids to an file, Mass inviter for joining servers your bot is in and Fetching all the servers of the bot (w/MemberCount) to the console.
 1 Jan 6, 2022
1 Jan 6, 2022
An Amazon Product Scraper built using scapy module of python
Amazon Product Scraper This is an Amazon Product Scraper built using scapy module of python Features it scrape various things Product Title Product Im
 1 Dec 13, 2021
1 Dec 13, 2021

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022
Telegram bot that can do a lot of things related to PDF files.
Telegram PDF Bot A Telegram bot that can: Compress, crop, decrypt, encrypt, merge, preview, rename, rotate, scale and split PDF files Compare text dif
 130 Dec 26, 2022
130 Dec 26, 2022
This is a webscraper for a specific website
This is a webscraper for a specific website. It is tuned to extract the headlines of that website. With some little adjustments the webscraper is able to extract any part of the website.
 1 Dec 13, 2021
1 Dec 13, 2021
Jobinja.ir jobs scraper.
Jobinja.ir Dataset Introduction This project is a simple web scraper that scraps pages of jobinja.ir concurrently and writes and update (if file gets
 3 Apr 15, 2022
3 Apr 15, 2022
Um scraper feito em python que gera arquivos de excel baseados nas tier lists do site LoLalytics.
LoLalytics-scraper Um scraper feito em python que gera arquivos de excel baseados nas tier lists do site LoLalytics. Começando por um único script com
 1 Feb 19, 2022
1 Feb 19, 2022
Excalibur: A web interface to extract tabular data from PDFs
Excalibur: A web interface to extract tabular data from PDFs Excalibur is a web interface to extract tabular data from PDFs, written in Python 3! It i
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Educational application aimed at automating user-defined workflows for the mobile game, "Granblue Fantasy", using a variety of CV technologies in the backend such as OpenCV, PyAutoGUI and EasyOCR and a frontend coded in Typescript.
Granblue Automation using Template Matching (It is like Full Auto, but with Full Customization!) Discord here: https://discord.gg/5Yv4kqjAbm Android v
 71 Dec 30, 2022
71 Dec 30, 2022

Python bindings for MuPDF's rendering library.
PyMuPDF 1.19.3 Release date: December 15, 2021 On PyPI since August 2016: Author Jorj X. McKie, based on original code by Ruikai Liu. Introduction PyM
 0 Nov 3, 2022
0 Nov 3, 2022
This tool crawls a list of websites and download all PDF and office documents
This tool crawls a list of websites and download all PDF and office documents. Then it analyses the PDF documents and tries to detect accessibility issues.
 7 Sep 30, 2022
7 Sep 30, 2022
Creating Scrapy scrapers via the Django admin interface
django-dynamic-scraper Django Dynamic Scraper (DDS) is an app for Django which builds on top of the scraping framework Scrapy and lets you create and
 1.1k Dec 17, 2022
1.1k Dec 17, 2022

A web scraper for nomadlist.com, made to avoid website restrictions.
Gypsylist gypsylist.py is a web scraper for nomadlist.com, made to avoid website restrictions. nomadlist.com is a website with a lot of information fo
 5 Nov 24, 2022
5 Nov 24, 2022
Grab the changelog from releases on Github
release-notes-scraper This simple script can be used to grab the release notes for projects from github that do not keep a CHANGELOG, but publish thei
 4 Apr 1, 2022
4 Apr 1, 2022

Convert PDF/Image to TXT using EasyOcr - the best OCR engine available!
PDFImage2TXT - DOWNLOAD INSTALLER HERE What can you do with it? Convert scanned PDFs to TXT. Convert scanned Documents to TXT. No coding required!! In
 2 Feb 22, 2022
2 Feb 22, 2022

A database scraper created with mechanical soup and sqlite
WebscrapingDatabases a database scraper created with mechanical soup and sqlite author: Mariya Sha Watch on YouTube: This repository was created to su
 30 Aug 8, 2022
30 Aug 8, 2022
Get paper names from dblp.org
scraper-dblp Get paper names from dblp.org and store them in a .txt file Useful for a related literature :) Install libraries pip3 install -r requirem
 1 Dec 7, 2021
1 Dec 7, 2021

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021

pubmex.py - a script to get a fancy paper title based on given DOI or PMID
pubmex.py is a script to get a fancy paper title based on given DOI or PMID (can be also combined with macOS Finder)
 13 Nov 20, 2022
13 Nov 20, 2022
Examine.com supplement research scraper!
ExamineScraper Examine.com supplement research scraper! Why I want to be able to search pages for a specific term. For example, I want to be able to s
 15 Dec 6, 2022
15 Dec 6, 2022

A tool for certificate PDF generation.
certificate-pdf-generator 获奖证书PDF批量生成工具 | a Tool for certificate PDF generation. ⚠️ 下载前请注意 本项目使用了LFS来存储PDF等大文件。在克隆或下载本仓库前,请先使用apt等包管理器安装git-lfs包。如果已经克
 4 Nov 28, 2022
4 Nov 28, 2022
Web and PDF Scraper Refactoring
Web and PDF Scraper Refactoring This repository contains the example code of the Web and PDF scraper code roast. Here are the links to the videos: Par
 18 Dec 31, 2022
18 Dec 31, 2022
A python script that fetches the grades of a student from a WAEC result in pdf format.
About waec-result-analyzer A python script that fetches the grades of a student from a WAEC result in pdf format. Built for federal government college
 2 Dec 4, 2021
2 Dec 4, 2021
FOTS Pytorch Implementation
News!!! Recognition branch now is added into model. The whole project has beed optimized and refactored. ICDAR Dataset SynthText 800K Dataset detectio
 599 Dec 19, 2022
599 Dec 19, 2022
Indonesian ID Card OCR using tesseract OCR
KTP OCR Indonesian ID Card OCR using tesseract OCR KTP OCR is python-flask with tesseract web application to convert Indonesian ID Card to text / JSON
 5 Dec 6, 2021
5 Dec 6, 2021

The open source extract transaction infomation by using OCR.
Transaction OCR Mã nguồn trích xuất thông tin transaction từ file scaned pdf, ở đây tôi lựa chọn tài liệu sao kê công khai của Thuy Tien. Mã nguồn có
 18 Jun 2, 2022
18 Jun 2, 2022
An helper library to scrape data from Instagram effortlessly, using the Influencer Hunters APIs.
Instagram Scraper An utility library to scrape data from Instagram hassle-free Go to the website » View Demo · Report Bug · Request Feature About The
 2 Jul 6, 2022
2 Jul 6, 2022
Google Developer Profile Badge Scraper
Google Developer Profile Badge Scraper GDev Profile Badge Scraper is a Google Developer Profile Web Scraper which scrapes for specific badges in a use
 7 Jan 10, 2022
7 Jan 10, 2022
A leetcode scraper to compile all questions in leetcode free tier to text file. pdf also available.
A leetcode scraper to compile all questions in leetcode free tier to text file, pdf also available. if new questions get added, run again to get new questions.
 3 Dec 7, 2021
3 Dec 7, 2021
Trata PDF para torná-lo compatível com PDF/X e com impressoras em escala de cinza.
tratapdf Trata PDF para torná-lo compatível com PDF/X e com impressoras em escala de cinza. dependências icc-profiles ghostscript visualizador de PDF
 1 Nov 30, 2021
1 Nov 30, 2021
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
 1 Nov 30, 2021
1 Nov 30, 2021

Add members to unlimited telegram channels and groups
Program Features 📌 Coded with Python version 10. 📌 without the need for a proxy. 📌 without the need for a Telegram ID. 📌 Ability to add infinite p
 10 Nov 25, 2022
10 Nov 25, 2022
A Simple Web Scraper made to Extract Download Links from Todaytvseries2.com
TDTV2-Direct Version 1.00.1 • A Simple Web Scraper made to Extract Download Links from Todaytvseries2.com :) How to Works?? install all dependancies v
 1 Nov 28, 2021
1 Nov 28, 2021

Meaningful titles for tabs and PDF downloads! Also supports tab search.
arxiv-utils If you are a researcher that reads a lot on ArXiv, you'll benefit a lot from this web extension. Renames the title of PDF page to the pape
 174 Dec 20, 2022
174 Dec 20, 2022
Busca no nome e conteúdo de arquivos PDF no diretório e subdiretórios.
PDF Finder Este script auxilia na pesquisa em pastas com inúmeros arquivos PDF. A pesquisa é feita em todos os arquivos do doretório e subdiretórios.
 1 Nov 27, 2021
1 Nov 27, 2021

Camelot is a Python library that makes it easy for anyone to extract tables from PDF files
Camelot: PDF Table Extraction for Humans Camelot is a Python library that makes it easy for anyone to extract tables from PDF files! Note: You can als
 3.3k Jan 6, 2023
3.3k Jan 6, 2023
CLI tool to generate pdf invoices written in python
invoicepy CLI invoice tool, store and print invoices as pdf. save companies and customers for later use. installation pip install invoicepy config co
 9 Aug 1, 2022
9 Aug 1, 2022
A web Scraper for CSrankings.com that scrapes University and Faculty list for a particular country
A web Scraper for CSrankings.com that scrapes University and Faculty list for a particular country To run the file: Open terminal
 2 Jun 6, 2022
2 Jun 6, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023
DivNoising is an unsupervised denoising method to generate diverse denoised samples for any noisy input image. This repository contains the code to reproduce the results reported in the paper https://openreview.net/pdf?id=agHLCOBM5jP
DivNoising: Diversity Denoising with Fully Convolutional Variational Autoencoders Mangal Prakash1, Alexander Krull1,2, Florian Jug2 1Authors contribut
 33 Dec 30, 2022
33 Dec 30, 2022

OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages
OCR-Streamlit-App OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages OCR app gets an image a
 5 Apr 5, 2022
5 Apr 5, 2022
Semplice scraper realizzato in Python tramite la libreria BeautifulSoup
Semplice scraper realizzato in Python tramite la libreria BeautifulSoup
 2 Nov 22, 2021
2 Nov 22, 2021

A Python web scraper to scrape latest posts from official Coinbase's Blog.
Coinbase Blog Scraper A Python web scraper to scrape latest posts from official Coinbase's Blog. IDEA It scrapes up latest blog posts from https://blo
 3 Feb 18, 2022
3 Feb 18, 2022

Telegram Group Scrapper
this programe is make your work so much easy on telegrame. do you want to send messages on everyone to your group or others group. use this script it will do your work automatically with one click. and sit down and watch the screen. if you want to add members on your group then jest use this script it will do your work.
 3 Dec 3, 2022
3 Dec 3, 2022
Web scraper for Zillow
Zillow-Scraper Instructions All terminal commands are highlighted. Make sure you first have python 3 installed. You can check this by running "python
 1 Nov 23, 2021
1 Nov 23, 2021
A simple, configurable and expandable combined shop scraper to minimize the costs of ordering several items
combined-shop-scraper A simple, configurable and expandable combined shop scraper to minimize the costs of ordering several items. Features Define an
 2 Dec 13, 2021
2 Dec 13, 2021
Sheet Data Image/PDF-to-CSV Converter
Sheet Data Image/PDF-to-CSV Converter
 5 Nov 22, 2021
5 Nov 22, 2021
Discord webhook spammer with proxy support and proxy scraper
Discord webhook spammer with proxy support and proxy scraper
 3 Feb 27, 2022
3 Feb 27, 2022

Apply different text recognition services to images of handwritten documents.
Handprint The Handwritten Page Recognition Test is a command-line program that invokes HTR (handwritten text recognition) services on images of docume
 117 Jan 2, 2023
117 Jan 2, 2023

The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
 2 Nov 20, 2021
2 Nov 20, 2021
rst2pdf: Use a text editor. Make a PDF.
rst2pdf: Use a text editor. Make a PDF.
 487 Jan 6, 2023
487 Jan 6, 2023
TikTok downloader video without watermark from Telegram bot
⬇️ How to download video from Tik Tok via telegram bot? Send a link to the video from tik tok to our telegram bot and it will send you a video without
 1 Mar 4, 2022
1 Mar 4, 2022
A Python Oriented tool to Scrap WhatsApp Group Link using Google Dork it Scraps Whatsapp Group Links From Google Results And Gives Working Links.
WaGpScraper A Python Oriented tool to Scrap WhatsApp Group Link using Google Dork it Scraps Whatsapp Group Links From Google Results And Gives Working
 27 Dec 18, 2022
27 Dec 18, 2022
A simple Discord Mass-Ban that's still working with Member Scraper.
Mass-Ban [!] This was made for education / you can use for revenge. Please don't skid it. [!] If you want to use it, please use member scraper before
1 Nov 20, 2021
This is PDF Merger Application Developed using Just Python
This is PDF Merger Application Developed using Just Python
 2 Nov 18, 2021
2 Nov 18, 2021
An IpVanish Proxies Scraper
EzProxies Tired of searching for good proxies for hours? Just get an IpVanish account and get thousands of good proxies in few seconds! Showcase Watch
 11 Nov 13, 2022
11 Nov 13, 2022
Chilean Digital Vaccination Pass Parser (CDVPP) parses digital vaccination passes from PDF files
cdvpp Chilean Digital Vaccination Pass Parser (CDVPP) parses digital vaccination passes from PDF files Reads a Digital Vaccination Pass PDF file as in
 1 Nov 17, 2021
1 Nov 17, 2021
A simple Python script to convert multiple images (well technically also a single image) into a pdf.
PythonImage2PDF A simple Python script to convert multiple images into a single PDF-document. Created basically for only my own needs for converting m
 1 Jun 28, 2022
1 Jun 28, 2022
A simple Telegram bot can convert web docs, Telegraph links, etc. to Pdf !
A Telegram Bot to convert http Links to PDF
 10 Oct 28, 2022
10 Oct 28, 2022
The goal of this project is for anyone with an old printer to be able to double-sided printing.
Welcome to PDF-double-side! Hi! I'm 15. I have a old printer so I can't print double-sided outs. The goal of this project is for anyone with an old pr
 4 Dec 28, 2021
4 Dec 28, 2021
A simple reddit scraper to get memes (only images) from r/ProgrammerHumor.
memey A simple reddit scraper to get memes (only images) from r/ProgrammerHumor. Note Only works if you have firefox installed (yet). Instructions foo
 2 Nov 16, 2021
2 Nov 16, 2021
Simple python tool for the purpose of swapping latinic letters with cirilic ones and vice versa in txt, docx and pdf files in Serbian language
Alpha Swap English This is a simple python tool for the purpose of swapping latinic letters with cirylic ones and vice versa, in txt, docx and pdf fil
 3 May 31, 2022
3 May 31, 2022
Scrapes all articles and their headlines from theonion.com
The Onion Article Scraper Scrapes all articles and their headlines from the satirical news website https://www.theonion.com Also see Clickhole Article
 0 Nov 17, 2021
0 Nov 17, 2021

Free-Game-Scraper is a useful script that allows you to track down free games and DLCs on many platforms.
Game Scraper Free-Game-Scraper is a useful script that allows you to track down free games and DLCs on many platforms. Join the discord About The Proj
 2 Mar 28, 2022
2 Mar 28, 2022

Extract the table in the PDF,outputs the data similar to the json format
extract the table in the PDF,outputs the data similar to the json format
 3 Nov 25, 2021
3 Nov 25, 2021

Reads Data from given Excel File and exports Single PDFs and a complete PDF grouped by Gateway
E-Shelter Excel2QR Reads Data from given Excel File and exports Single PDFs and a complete PDF grouped by Gateway Features Reads Excel 2021 Export Sin
 1 Nov 13, 2021
1 Nov 13, 2021
Build custom OSINT tools and APIs (Ping, Traceroute, Scans, Archives, DNS, Scrape, Whois, Metadata & built-in database for more info) with this python package
Build custom OSINT tools and APIs with this python package - It includes different OSINT modules (Ping, Traceroute, Scans, Archives, DNS, Scrape, Whoi
 52 Jan 6, 2023
52 Jan 6, 2023

Automatic Proxy scraper and Proxy-rotating Nitro Generator.
Automatic Proxy scraper and Proxy-rotating Nitro Generator.
 2 Nov 8, 2021
2 Nov 8, 2021
OCR of Chicago 1909 Renumbering Plan
Requirements: Python 3 (probably at least 3.4) pipenv (pip3 install pipenv) tesseract (brew install tesseract, at least if you have a mac and homebrew
 2 Nov 21, 2021
2 Nov 21, 2021
eBay Scraper Homework 3 With Python
eBay Scraper Homework 3 Description of Code My ebay-dl.py file is programmed with python to download 6 key pieces of information - name, if there are
 1 Nov 10, 2021
1 Nov 10, 2021
A Certificate renaming tool made for IEEE CS SBC, SJCE.
PDF Batch Renamer Made for IEEE CS SBC, SJCE How to use? Before using the python script, ensure that pytesseract, pdf2image, opencv and other supporti
 2 Nov 14, 2021
2 Nov 14, 2021
Searching keywords in PDF file folders
keyword_searching Steps to use this Python scripts: (1)Paste this script into the file folder containing the PDF files you need to search from; (2)Thi
 1 Nov 8, 2021
1 Nov 8, 2021

This is a file deletion program that asks you for an extension of a file (.mp3, .pdf, .docx, etc.) to delete all of the files in a dir that have that extension.
FileBulk This is a file deletion program that asks you for an extension of a file (.mp3, .pdf, .docx, etc.) to delete all of the files in a dir that h
 1 Jun 26, 2022
1 Jun 26, 2022
pikepdf is a Python library for reading and writing PDF files.
A Python library for reading and writing PDF, powered by qpdf
 1.6k Jan 3, 2023
1.6k Jan 3, 2023
Built as part of an assignment for S5 OOSE Subject CSE
Installation Steps: Download and install Python from here based on your operating system. I have used Python v3.8.10 for this. Clone the repository gi
 2 Sep 9, 2022
2 Sep 9, 2022

This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
 75 Oct 21, 2022
75 Oct 21, 2022
Facebook Group Scraping Using Beautiful Soup & Selenium
Extract Facebook group posts that are related to a specific topic and write them to a .json file.
 14 Aug 12, 2022
14 Aug 12, 2022