466 Repositories
Python pdf-scraper-with-ocr Libraries

Amazon Scraper: A command-line tool for scraping Amazon product data
Amazon Product Scraper: 2021 Description A command-line tool for scraping Amazon product data to CSV or JSON format(s). Requirements Python 3 pip3 Ins
 49 Nov 15, 2021
49 Nov 15, 2021
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021
A Web Scraper built with beautiful soup, that fetches udemy course information. Get udemy course information and convert it to json, csv or xml file
Udemy Scraper A Web Scraper built with beautiful soup, that fetches udemy course information. Installation Virtual Environment Firstly, it is recommen
 15 May 17, 2022
15 May 17, 2022

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023
Extract Thailand COVID-19 Cluster data from daily briefing pdf.
Thailand COVID-19 Cluster Data Extraction About Extract Clusters from Thailand Daily COVID-19 briefing PDF Download latest data Here. Data will be upd
 5 Sep 27, 2021
5 Sep 27, 2021
Automated data scraper for Thailand COVID-19 data
The Researcher COVID data Automated data scraper for Thailand COVID-19 data Accessing the Data 1st Dose Provincial Vaccination Data 2nd Dose Provincia
 31 Apr 17, 2022
31 Apr 17, 2022

Performing the following operations using python on PDF.
Python PDF Handling Tutorial Python is a highly versatile language with a huge set of libraries. It is a high level language with simple syntax. Pytho
 131 Dec 16, 2022
131 Dec 16, 2022

A Python tool to generate a static HTML file that represents the internal structure of a PDF file
PDFSyntax A Python tool to generate a static HTML file that represents the internal structure of a PDF file At some point the low-level functions deve
 394 Dec 30, 2022
394 Dec 30, 2022
Command line program to download documents from web portals.
command line document download made easy Highlights list available documents in json format or download them filter documents using string matching re
 16 Dec 26, 2022
16 Dec 26, 2022
pystitcher stitches your PDF files together, generating nice customizable bookmarks for you using a declarative markdown file as input
pystitcher pystitcher stitches your PDF files together, generating nice customizable bookmarks for you using a declarative input in the form of a mark
 387 Dec 10, 2022
387 Dec 10, 2022
A python library for extracting text from PDFs without losing the formatting of the PDF content.
Multilingual PDF to Text Install Package from Pypi Install it using pip. pip install multilingual-pdf2text The library uses Tesseract which can be ins
 49 Nov 7, 2022
49 Nov 7, 2022
Download images from forum threads
Forum Image Scraper Downloads images from forum threads Only works with forums which doesn't require a login to view and have an incremental paginatio
 9 Nov 16, 2022
9 Nov 16, 2022

mlscraper: Scrape data from HTML pages automatically with Machine Learning
🤖 Scrape data from HTML websites automatically with Machine Learning
 798 Dec 29, 2022
798 Dec 29, 2022
Python library to download bulk of images from Bing.com
Python library to download bulk of images form Bing.com. This package uses async url, which makes it very fast while downloading.
 105 Dec 14, 2022
105 Dec 14, 2022

A dataset for online Arabic calligraphy
Calliar Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic callig
 114 Dec 28, 2022
114 Dec 28, 2022
Some Boring Research About Products Recognition 、Duplicate Img Detection、Img Stitch、OCR
Products Recognition 介绍 商品识别,围绕在复杂的商场零售场景中,识别出货架图像中的商品信息。主要组成部分: 重复图像检测。【更新进度 4/10】 图像拼接。【更新进度 0/10】 目标检测。【更新进度 0/10】 商品识别。【更新进度 1/10】 OCR。【更新进度 1/10】
 18 Jan 27, 2022
18 Jan 27, 2022
Python 3 tool for finding unclaimed groups on Roblox. Supports multi-threading, multi-processing and HTTP proxies.
roblox-group-scanner Python 3 tool for finding unclaimed groups on Roblox. Supports multi-threading, multi-processing and HTTP proxies. Usage usage: s
 43 May 11, 2022
43 May 11, 2022
Anonymously scrapes onlinesim.ru for new usable phone numbers.
phone-scraper Anonymously scrapes onlinesim.ru for new usable phone numbers. Usage Clone the repository $ git clone https://github.com/thomasgruebl/ph
 16 Oct 8, 2022
16 Oct 8, 2022

Senginta is All in one Search Engine Scrapper for used by API or Python Module. It's Free!
Senginta is All in one Search Engine Scrapper. With traditional scrapping, Senginta can be powerful to get result from any Search Engine, and convert to Json. Now support only for Google Product Search Engine (GShop, GVideo and many too) and Baidu Search Engine.
 33 Nov 21, 2022
33 Nov 21, 2022

A Python Instagram Scraper for Downloading Profile's Posts, stories, ProfilePic and See the Details of Particular Instagram Profile.
✔ ✔ InstAstra ⚡ ⚡ ⁜ Description ~ A Python Instagram Scraper for Downloading Profile's Posts, stories, ProfilePic and See the Details of Particular In
 12 Jun 23, 2022
12 Jun 23, 2022
A cross platform OCR Library based on PaddleOCR & OnnxRuntime
A cross platform OCR Library based on PaddleOCR & OnnxRuntime
 767 Jan 9, 2023
767 Jan 9, 2023
Python scraper to check for earlier appointments in Clalit Health Services
clalit-appt-checker Python scraper to check for earlier appointments in Clalit Health Services Some background If you ever needed to schedule a doctor
 16 Sep 17, 2022
16 Sep 17, 2022

PyMuPDF is a Python binding with support for MuPDF
PyMuPDF is a Python binding with support for MuPDF (current version 1.18.*), a lightweight PDF, XPS, and E-book viewer, renderer, and toolkit, which is maintained and developed by Artifex Software, Inc.
 1.9k Jan 3, 2023
1.9k Jan 3, 2023
IACR Events Scraper
IACR Events Scraper This scrapes https://iacr.org/events/ and exports it as a calendar file. I host a version of this for myself under https://arrrr.c
 6 May 28, 2022
6 May 28, 2022

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022
A command-line program to download media, like and unlike posts, and more from creators on OnlyFans.
onlyfans-scraper A command-line program to download media, like and unlike posts, and more from creators on OnlyFans. Installation You can install thi
 185 Jul 23, 2022
185 Jul 23, 2022
Python PDF Parser (Not actively maintained). Check out pdfminer.six.
PDFMiner PDFMiner is a text extraction tool for PDF documents. Warning: As of 2020, PDFMiner is not actively maintained. The code still works, but thi
 4.9k Jan 4, 2023
4.9k Jan 4, 2023
PyPDF2 is a pure-python PDF library capable of splitting, merging together, cropping, and transforming the pages of PDF files.
PyPDF2 is a pure-python PDF library capable of splitting, merging together, cropping, and transforming the pages of PDF files. It can also add custom data, viewing options, and passwords to PDF files. It can retrieve text and metadata from PDFs as well as merge entire files together.
 5k Jan 4, 2023
5k Jan 4, 2023
Automatically scrape all of your artifacts in Genshin Impact.
Genshin Artifact Scraper Automatically scrape all of your artifacts in Genshin Impact. Features: Simple recalibration (2 steps). GUI to select OCR reg
 21 Dec 17, 2022
21 Dec 17, 2022
Simple HTML and PDF document generator for Python - with built-in support for popular data analysis and plotting libraries.
Esparto is a simple HTML and PDF document generator for Python. Its primary use is for generating shareable single page reports with content from popular analytics and data science libraries.
 76 Dec 12, 2022
76 Dec 12, 2022

All in one Search Engine Scrapper for used by API or Python Module. It's Free!
All in one Search Engine Scrapper for used by API or Python Module. How to use: Video Documentation Senginta is All in one Search Engine Scrapper. Wit
33 Nov 21, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023
An Unofficial TikTok API Wrapper In Python
This is an unofficial api wrapper for TikTok.com in python. With this api you are able to call most trending and fetch specific user information as well as much more.
 2.9k Jan 8, 2023
2.9k Jan 8, 2023

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022
Code for the paper "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021)
MASTER-PyTorch PyTorch reimplementation of "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021). This projec
 255 Dec 29, 2022
255 Dec 29, 2022
PGPortfolio: Policy Gradient Portfolio, the source code of "A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem"(https://arxiv.org/pdf/1706.10059.pdf).
This is the original implementation of our paper, A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem (arXiv:1706.1
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
Bulk Downloader for Reddit
saveddit is a bulk media downloader for reddit pip3 install saveddit Setting up authorization Register an application with Reddit Write down your clie
 136 Jan 3, 2023
136 Jan 3, 2023

Layout Parser is a deep learning based tool for document image layout analysis tasks.
A Python Library for Document Layout Understanding
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
Polyglot Machine Learning example for scraping similar news articles.
Polyglot Machine Learning example for scraping similar news articles In this example, we will see how we can work with Machine Learning applications w
 15 Mar 28, 2022
15 Mar 28, 2022
Source Code for DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances (https://arxiv.org/pdf/2012.01775.pdf)
DialogBERT This is a PyTorch implementation of the DialogBERT model described in DialogBERT: Neural Response Generation via Hierarchical BERT with Dis
 67 Jan 6, 2023
67 Jan 6, 2023
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
README TabNet : Attentive Interpretable Tabular Learning This is a pyTorch implementation of Tabnet (Arik, S. O., & Pfister, T. (2019). TabNet: Attent
 2k Dec 27, 2022
2k Dec 27, 2022
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf # it's a scriptable c
 7.9k Jan 3, 2023
7.9k Jan 3, 2023

Convolutional Recurrent Neural Networks(CRNN) for Scene Text Recognition
CRNN_Tensorflow This is a TensorFlow implementation of a Deep Neural Network for scene text recognition. It is mainly based on the paper "An End-to-En
 1000 Dec 27, 2022
1000 Dec 27, 2022
An expandable and scalable OCR pipeline
Overview Nidaba is the central controller for the entire OGL OCR pipeline. It oversees and automates the process of converting raw images into citable
 81 Jan 4, 2023
81 Jan 4, 2023

A simple OCR API server, seriously easy to be deployed by Docker, on Heroku as well
ocrserver Simple OCR server, as a small working sample for gosseract. Try now here https://ocr-example.herokuapp.com/, and deploy your own now. Deploy
 541 Dec 28, 2022
541 Dec 28, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

Detect text blocks and OCR poorly scanned PDFs in bulk. Python module available via pip.
doc2text doc2text extracts higher quality text by fixing common scan errors Developing text corpora can be a massive pain in the butt. Much of the tex
 1.3k Jan 4, 2023
1.3k Jan 4, 2023

An OCR evaluation tool
dinglehopper dinglehopper is an OCR evaluation tool and reads ALTO, PAGE and text files. It compares a ground truth (GT) document page with a OCR resu
 40 Dec 20, 2022
40 Dec 20, 2022

Text recognition (optical character recognition) with deep learning methods.
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis | paper | training and evaluation data | failure cases and cle
3.2k Jan 4, 2023

TedEval: A Fair Evaluation Metric for Scene Text Detectors
TedEval: A Fair Evaluation Metric for Scene Text Detectors Official Python 3 implementation of TedEval | paper | slides Chae Young Lee, Youngmin Baek,
167 Nov 20, 2022
The CIS OCR PostCorrectionTool
The CIS OCR Post Correction Tool PoCoTo Source code for the Java-based PoCoTo client enabling fast interactive batch corrections of complete OCR error
 36 Dec 15, 2022
36 Dec 15, 2022
Toolbox for OCR post-correction
Ochre Ochre is a toolbox for OCR post-correction. Please note that this software is experimental and very much a work in progress! Overview of OCR pos
 117 Nov 10, 2022
117 Nov 10, 2022

Binarize document images
Binarization Binarization for document images Examples Introduction This tool performs document image binarization (i.e. transform colour/grayscale to
48 Jan 2, 2023
Pre-Recognize Library - library with algorithms for improving OCR quality.
PRLib - Pre-Recognition Library. The main aim of the library - prepare image for recogntion. Image processing can really help to improve recognition q
 80 Dec 30, 2022
80 Dec 30, 2022

Generate text images for training deep learning ocr model
New version release:https://github.com/oh-my-ocr/text_renderer Text Renderer Generate text images for training deep learning OCR model (e.g. CRNN). Su
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

A synthetic data generator for text recognition
TextRecognitionDataGenerator A synthetic data generator for text recognition What is it for? Generating text image samples to train an OCR software. N
 2.5k Jan 4, 2023
2.5k Jan 4, 2023
list all open dataset about ocr.
ocr-open-dataset list all open dataset about ocr. printed dataset year Born-Digital Images (Web and Email) 2011-2015 COCO-Text 2017 Text Extraction fr
 95 Nov 24, 2022
95 Nov 24, 2022
Tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML.
hocr-tools About About the code Installation System-wide with pip System-wide from source virtualenv Available Programs hocr-check -- check the hOCR f
 285 Dec 8, 2022
285 Dec 8, 2022
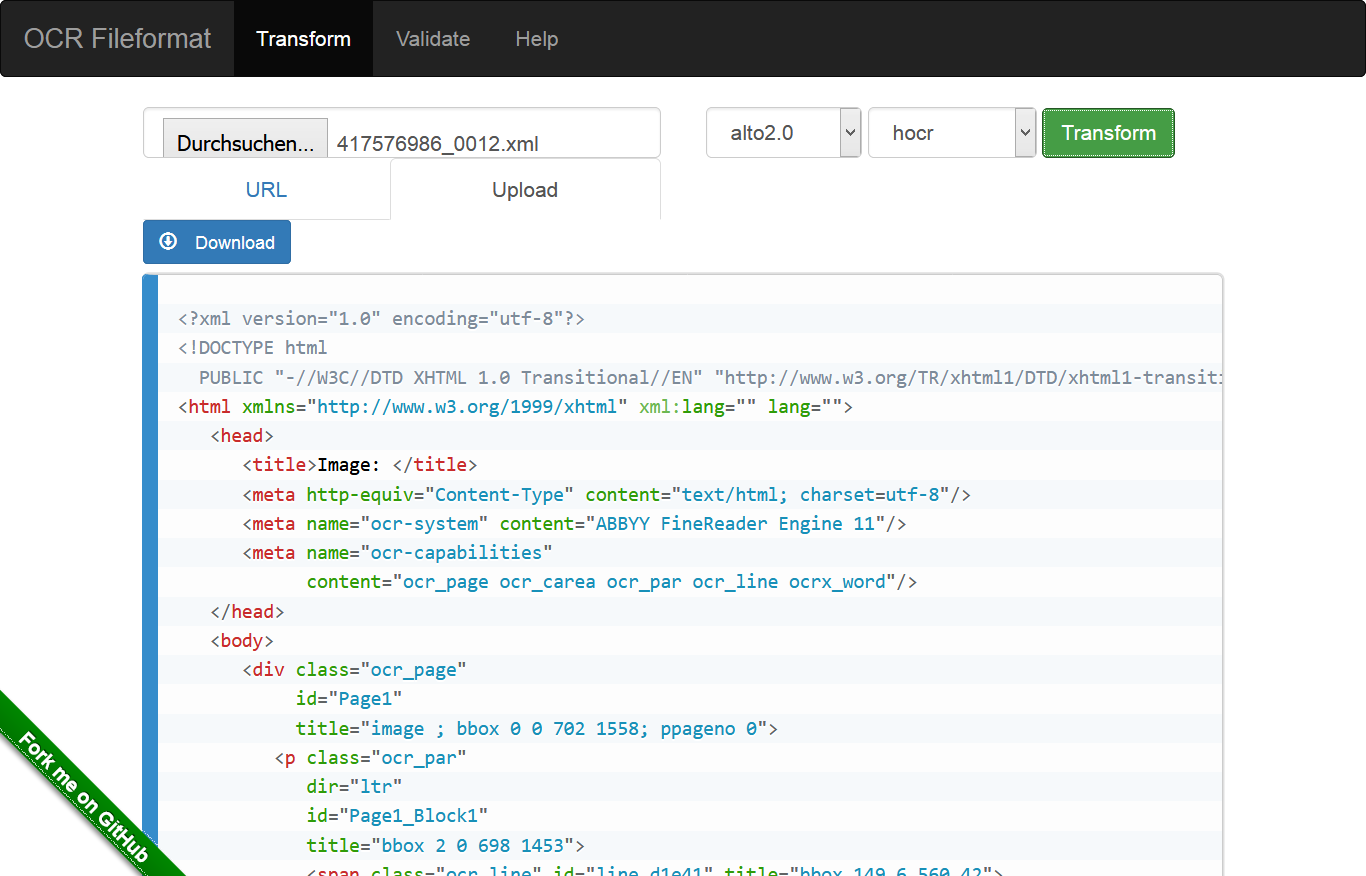
Validate and transform various OCR file formats (hOCR, ALTO, PAGE, FineReader)
ocr-fileformat Validate and transform between OCR file formats (hOCR, ALTO, PAGE, FineReader) Installation Docker System-wide Usage CLI GUI API Transf
 152 Dec 20, 2022
152 Dec 20, 2022
OCR, Scene-Text-Understanding, Text Recognition
Scene-Text-Understanding Survey [2015-PAMI] Text Detection and Recognition in Imagery: A Survey paper [2014-Front.Comput.Sci] Scene Text Detection and
 354 Dec 12, 2022
354 Dec 12, 2022
A curated list of promising OCR resources
Call for contributor(paper summary,dataset generation,algorithm implementation and any other useful resources) awesome-ocr A curated list of promising
 1.6k Jan 4, 2023
1.6k Jan 4, 2023
A collection of resources (including the papers and datasets) of OCR (Optical Character Recognition).
OCR Resources This repository contains a collection of resources (including the papers and datasets) of OCR (Optical Character Recognition). Contents
 363 Jan 3, 2023
363 Jan 3, 2023
Links to awesome OCR projects
Awesome OCR This list contains links to great software tools and libraries and literature related to Optical Character Recognition (OCR). Contribution
 2.2k Jan 2, 2023
2.2k Jan 2, 2023

A curated list of resources for text detection/recognition (optical character recognition ) with deep learning methods.
awesome-deep-text-detection-recognition A curated list of awesome deep learning based papers on text detection and recognition. Text Detection Papers
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
A general list of resources to image text localization and recognition 场景文本位置感知与识别的论文资源与实现合集 シーンテキストの位置認識と識別のための論文リソースの要約
Scene Text Localization & Recognition Resources Read this institute-wise: English, 简体中文. Read this year-wise: English, 简体中文. Tags: [STL] (Scene Text L
 901 Dec 11, 2022
901 Dec 11, 2022

OCR system for Arabic language that converts images of typed text to machine-encoded text.
Arabic OCR OCR system for Arabic language that converts images of typed text to machine-encoded text. The system currently supports only letters (29 l
 144 Jan 5, 2023
144 Jan 5, 2023
Solution for Problem 1 by team codesquad for AIDL 2020. Uses ML Kit for OCR and OpenCV for image processing
CodeSquad PS1 Solution for Problem Statement 1 for AIDL 2020 conducted by @unifynd technologies. Problem Given images of bills/invoices, the task was
 111 Nov 27, 2022
111 Nov 27, 2022
Go package for OCR (Optical Character Recognition), by using Tesseract C++ library
gosseract OCR Golang OCR package, by using Tesseract C++ library. OCR Server Do you just want OCR server, or see the working example of this package?
1.9k Dec 28, 2022
OCR engine for all the languages
Description kraken is a turn-key OCR system optimized for historical and non-Latin script material. kraken's main features are: Fully trainable layout
 431 Jan 4, 2023
431 Jan 4, 2023
Some bits of javascript to transcribe scanned pages using PageXML
nashi (nasḫī) Some bits of javascript to transcribe scanned pages using PageXML. Both ltr and rtl languages are supported. Try it! But wait, there's m
 15 Nov 9, 2022
15 Nov 9, 2022
Provides OCR (Optical Character Recognition) services through web applications
OCR4all As suggested by the name one of the main goals of OCR4all is to allow basically any given user to independently perform OCR on a wide variety
 174 Dec 31, 2022
174 Dec 31, 2022
A machine learning software for extracting information from scholarly documents
GROBID GROBID documentation Visit the GROBID documentation for more detailed information. Summary GROBID (or Grobid, but not GroBid nor GroBiD) means
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
Visual Attention based OCR
Attention-OCR Authours: Qi Guo and Yuntian Deng Visual Attention based OCR. The model first runs a sliding CNN on the image (images are resized to hei
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
A Tensorflow model for text recognition (CNN + seq2seq with visual attention) available as a Python package and compatible with Google Cloud ML Engine.
Attention-based OCR Visual attention-based OCR model for image recognition with additional tools for creating TFRecords datasets and exporting the tra
 933 Dec 29, 2022
933 Dec 29, 2022
Ocular is a state-of-the-art historical OCR system.
Ocular Ocular is a state-of-the-art historical OCR system. Its primary features are: Unsupervised learning of unknown fonts: requires only document im
 228 Dec 30, 2022
228 Dec 30, 2022

make a better chinese character recognition OCR than tesseract
deep ocr See README_en.md for English installation documentation. 只在ubuntu下面测试通过,需要virtualenv安装,安装路径可自行调整: git clone https://github.com/JinpengLI/deep
 1.5k Dec 28, 2022
1.5k Dec 28, 2022

CTPN + DenseNet + CTC based end-to-end Chinese OCR implemented using tensorflow and keras
简介 基于Tensorflow和Keras实现端到端的不定长中文字符检测和识别 文本检测:CTPN 文本识别:DenseNet + CTC 环境部署 sh setup.sh 注:CPU环境执行前需注释掉for gpu部分,并解开for cpu部分的注释 Demo 将测试图片放入test_images
 2.6k Dec 29, 2022
2.6k Dec 29, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
3.2k Dec 31, 2022
Repository collecting all the submodules for the new PyTorch-based OCR System.
OCRopus3 is being replaced by OCRopus4, which is a rewrite using PyTorch 1.7; release should be soonish. Please check github.com/tmbdev/ocropus for up
 138 Dec 9, 2022
138 Dec 9, 2022
Tesseract Open Source OCR Engine (main repository)
Tesseract OCR About This package contains an OCR engine - libtesseract and a command line program - tesseract. Tesseract 4 adds a new neural net (LSTM
 48.4k Jan 9, 2023
48.4k Jan 9, 2023

Pure Javascript OCR for more than 100 Languages 📖🎉🖥
Version 2 is now available and under development in the master branch, read a story about v2: Why I refactor tesseract.js v2? Check the support/1.x br
 29.2k Jan 5, 2023
29.2k Jan 5, 2023

ISI's Optical Character Recognition (OCR) software for machine-print and handwriting data
VistaOCR ISI's Optical Character Recognition (OCR) software for machine-print and handwriting data Publications "How to Efficiently Increase Resolutio
 21 Dec 8, 2021
21 Dec 8, 2021
A small C++ implementation of LSTM networks, focused on OCR.
clstm CLSTM is an implementation of the LSTM recurrent neural network model in C++, using the Eigen library for numerical computations. Status and sco
 794 Dec 30, 2022
794 Dec 30, 2022
CNN+LSTM+CTC based OCR implemented using tensorflow.
CNN_LSTM_CTC_Tensorflow CNN+LSTM+CTC based OCR(Optical Character Recognition) implemented using tensorflow. Note: there is No restriction on the numbe
 356 Dec 8, 2022
356 Dec 8, 2022

第一届西安交通大学人工智能实践大赛(2018AI实践大赛--图片文字识别)第一名;仅采用densenet识别图中文字
OCR 第一届西安交通大学人工智能实践大赛(2018AI实践大赛--图片文字识别)冠军 模型结果 该比赛计算每一个条目的f1score,取所有条目的平均,具体计算方式在这里。这里的计算方式不对一句话里的相同文字重复计算,故f1score比提交的最终结果低: - train val f1score 0
 441 Dec 22, 2022
441 Dec 22, 2022
MXNet OCR implementation. Including text recognition and detection.
insightocr Text Recognition Accuracy on Chinese dataset by caffe-ocr Network LSTM 4x1 Pooling Gray Test Acc SimpleNet N Y Y 99.37% SE-ResNet34 N Y Y 9
 99 Nov 1, 2022
99 Nov 1, 2022
A tool for extracting text from scanned documents (via OCR), with user-defined post-processing.
The project is based on older versions of tesseract and other tools, and is now superseded by another project which allows for more granular control o
 32 Jul 24, 2022
32 Jul 24, 2022

This is the implementation of the paper "Gated Recurrent Convolution Neural Network for OCR"
Gated Recurrent Convolution Neural Network for OCR This project is an implementation of the GRCNN for OCR. For details, please refer to the paper: htt
 90 Dec 22, 2022
90 Dec 22, 2022
🖺 OCR using tensorflow with attention
tensorflow-ocr 🖺 OCR using tensorflow with attention, batteries included Installation git clone --recursive http://github.com/pannous/tensorflow-ocr
 646 Nov 11, 2022
646 Nov 11, 2022

Scan the MRZ code of a passport and extract the firstname, lastname, passport number, nationality, date of birth, expiration date and personal numer.
PassportScanner Works with 2 and 3 line identity documents. What is this With PassportScanner you can use your camera to scan the MRZ code of a passpo
 441 Dec 24, 2022
441 Dec 24, 2022
Tensorflow-based CNN+LSTM trained with CTC-loss for OCR
Overview This collection demonstrates how to construct and train a deep, bidirectional stacked LSTM using CNN features as input with CTC loss to perfo
 489 Dec 21, 2022
489 Dec 21, 2022
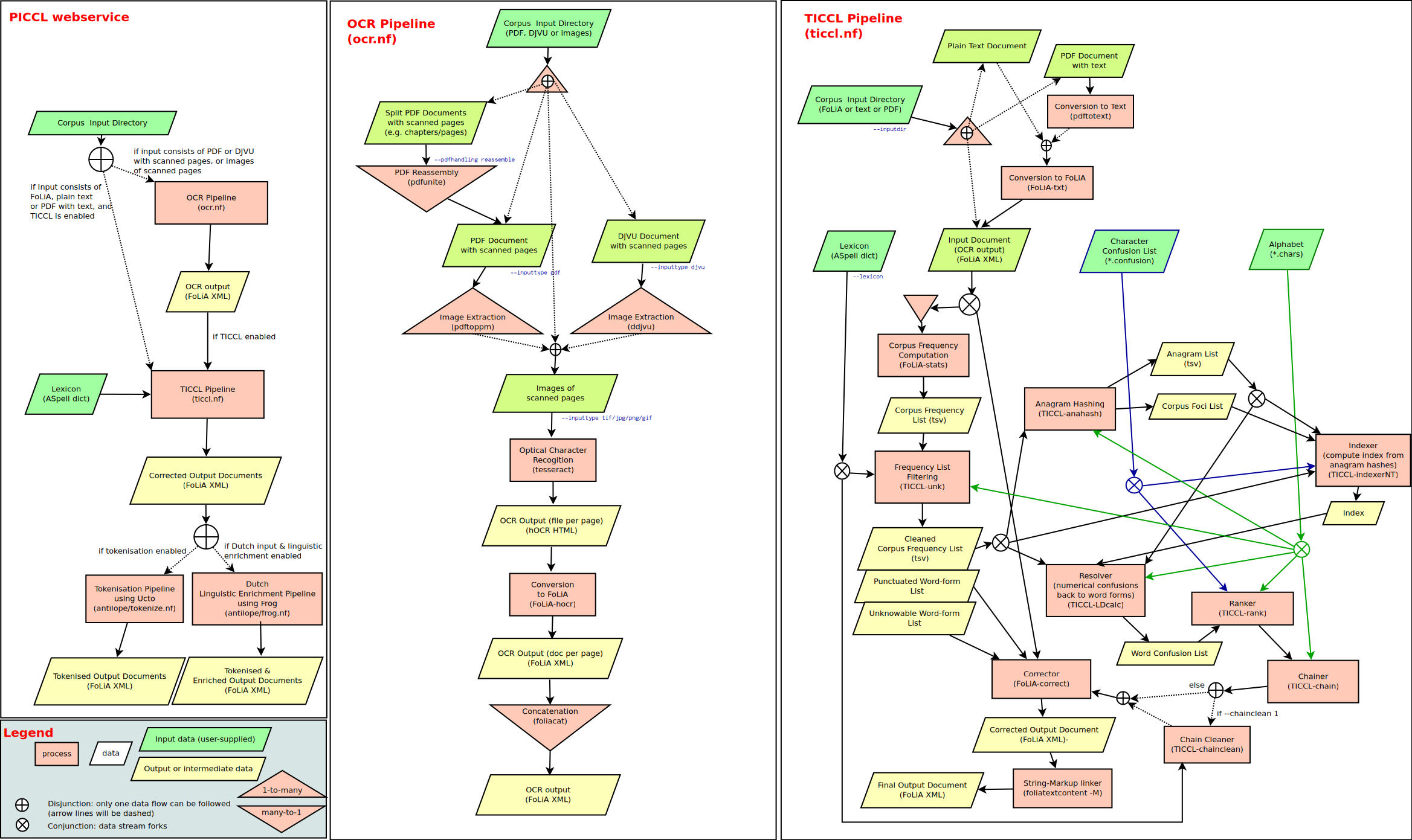
A set of workflows for corpus building through OCR, post-correction and normalisation
PICCL: Philosophical Integrator of Computational and Corpus Libraries PICCL offers a workflow for corpus building and builds on a variety of tools. Th
 41 Dec 27, 2022
41 Dec 27, 2022
Run tesseract with the tesserocr bindings with @OCR-D's interfaces
ocrd_tesserocr Crop, deskew, segment into regions / tables / lines / words, or recognize with tesserocr Introduction This package offers OCR-D complia
 38 Oct 14, 2022
38 Oct 14, 2022
python ocr using tesseract/ with EAST opencv detector
pytextractor python ocr using tesseract/ with EAST opencv text detector Uses the EAST opencv detector defined here with pytesseract to extract text(de
 38 Dec 5, 2022
38 Dec 5, 2022

A pure pytorch implemented ocr project including text detection and recognition
ocr.pytorch A pure pytorch implemented ocr project. Text detection is based CTPN and text recognition is based CRNN. More detection and recognition me
 444 Dec 30, 2022
444 Dec 30, 2022

Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
English | 简体中文 Introduction PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and a
 27.5k Jan 8, 2023
27.5k Jan 8, 2023
![[python3.6] 运用tf实现自然场景文字检测,keras/pytorch实现ctpn+crnn+ctc实现不定长场景文字OCR识别](https://github.com/xiaofengShi/CHINESE-OCR/raw/master/asset/ctpn_model.png)
[python3.6] 运用tf实现自然场景文字检测,keras/pytorch实现ctpn+crnn+ctc实现不定长场景文字OCR识别
本文基于tensorflow、keras/pytorch实现对自然场景的文字检测及端到端的OCR中文文字识别 update20190706 为解决本项目中对数学公式预测的准确性,做了其他的改进和尝试,效果还不错,https://github.com/xiaofengShi/Image2Katex 希
 2.7k Dec 25, 2022
2.7k Dec 25, 2022
The first open-source library that detects the font of a text in a image.
Typefont Typefont is an experimental library that detects the font of a text in a image. Usage Import the main function and invoke it like in the foll
 1.6k Feb 24, 2022
1.6k Feb 24, 2022
Textboxes implementation with Tensorflow (python)
tb_tensorflow A python implementation of TextBoxes Dependencies TensorFlow r1.0 OpenCV2 Code from Chaoyue Wang 03/09/2017 Update: 1.Debugging optimize
 20 May 31, 2019
20 May 31, 2019
TextBoxes++: A Single-Shot Oriented Scene Text Detector
TextBoxes++: A Single-Shot Oriented Scene Text Detector Introduction This is an application for scene text detection (TextBoxes++) and recognition (CR
 930 Jan 4, 2023
930 Jan 4, 2023