716 Repositories
Python summarization-dataset Libraries
The FinQA dataset from paper: FinQA: A Dataset of Numerical Reasoning over Financial Data
Data and code for EMNLP 2021 paper "FinQA: A Dataset of Numerical Reasoning over Financial Data"
 114 Dec 29, 2022
114 Dec 29, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

Python scripts for performing stereo depth estimation using the HITNET Tensorflow model.
HITNET-Stereo-Depth-estimation Python scripts for performing stereo depth estimation using the HITNET Tensorflow model from Google Research. Stereo de
 76 Jan 2, 2023
76 Jan 2, 2023

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
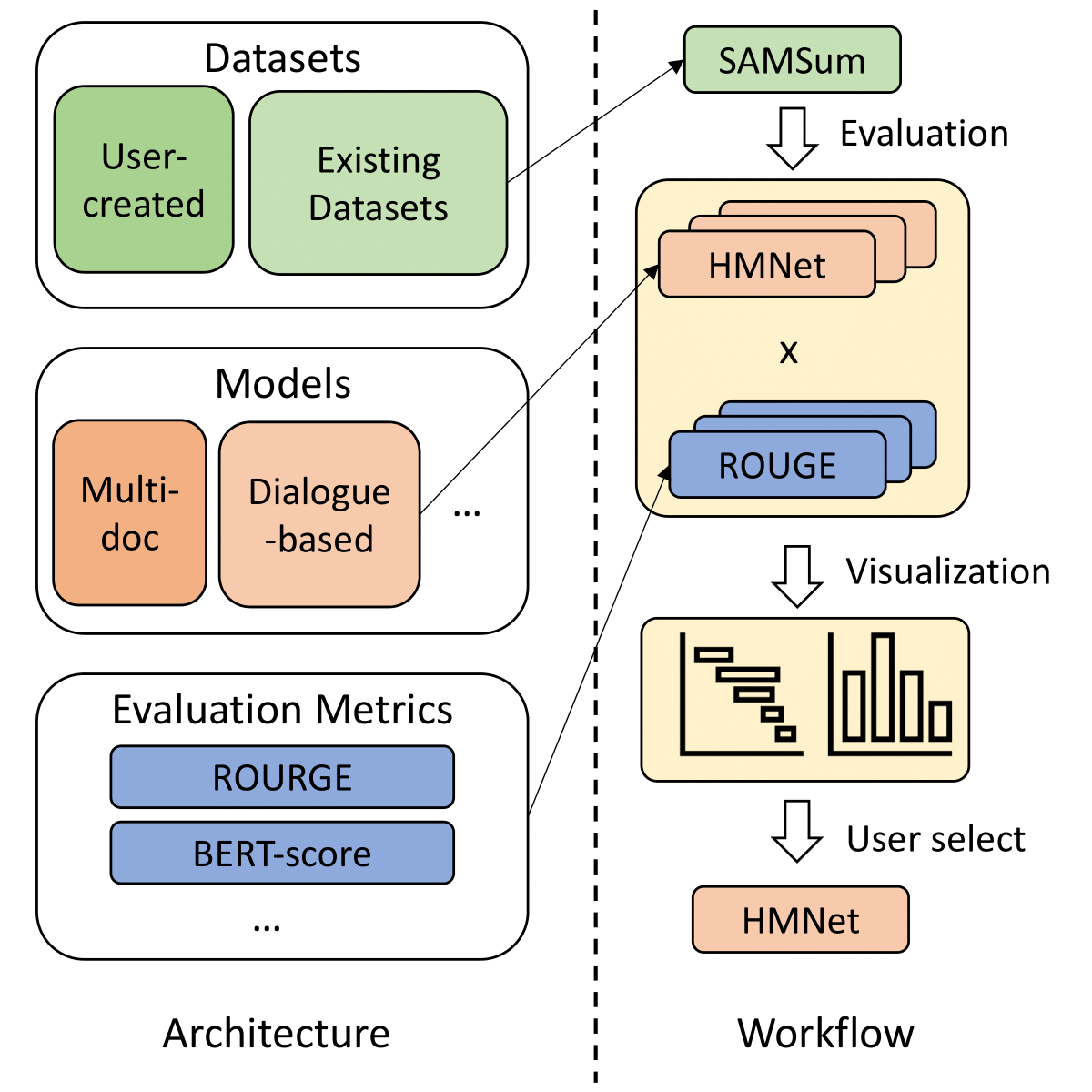
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection (ICCV 2021)
Preparation Please see dataset/README.md to get more details about our datasets-VIL100 Please see INSTALL.md to install environment and evaluation too
 82 Dec 15, 2022
82 Dec 15, 2022

Official implementation of particle-based models (GNS and DPI-Net) on the Physion dataset.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines [paper] Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, Hsiao-Y
 18 Dec 19, 2022
18 Dec 19, 2022
EMNLP 2021 Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections Ruiqi Zhong, Kristy Lee*, Zheng Zhang*, Dan Klein EMN
 42 Nov 3, 2022
42 Nov 3, 2022

LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision Project | Arxiv | Abstract It is very challenging for various visual tasks such as image
 377 Jan 7, 2023
377 Jan 7, 2023

NUANCED is a user-centric conversational recommendation dataset that contains 5.1k annotated dialogues and 26k high-quality user turns.
NUANCED: Natural Utterance Annotation for Nuanced Conversation with Estimated Distributions Overview NUANCED is a user-centric conversational recommen
 18 Dec 28, 2021
18 Dec 28, 2021
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

PyTorch DepthNet Training on Still Box dataset
DepthNet training on Still Box Project page This code can replicate the results of our paper that was published in UAVg-17. If you use this repo in yo
 115 Nov 21, 2022
115 Nov 21, 2022
PyTorch experiments with the Zalando fashion-mnist dataset
zalando-pytorch PyTorch experiments with the Zalando fashion-mnist dataset Project Organization ├── LICENSE ├── Makefile - Makefile with co
 31 Sep 25, 2021
31 Sep 25, 2021

YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset
YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research int
 73 Dec 16, 2022
73 Dec 16, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

Progressive Coordinate Transforms for Monocular 3D Object Detection
Progressive Coordinate Transforms for Monocular 3D Object Detection This repository is the official implementation of PCT. Introduction In this paper,
58 Nov 6, 2022

Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer Summary Explorer is a tool to visually inspect the summaries from several state-of-the-art neural summarization models across multipl
 42 Aug 14, 2022
42 Aug 14, 2022
A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild"
VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video
 45 Nov 29, 2022
45 Nov 29, 2022
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
42 Aug 14, 2022

Seeing Dynamic Scene in the Dark: High-Quality Video Dataset with Mechatronic Alignment (ICCV2021)
Seeing Dynamic Scene in the Dark: High-Quality Video Dataset with Mechatronic Alignment This is a pytorch project for the paper Seeing Dynamic Scene i
 21 Nov 28, 2022
21 Nov 28, 2022

Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch implementation of semantic segmentation models on MIT ADE20K scene parsing da
 4.5k Jan 8, 2023
4.5k Jan 8, 2023

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

This repository is to support contributions for tools for the Project CodeNet dataset hosted in DAX
The goal of Project CodeNet is to provide the AI-for-Code research community with a large scale, diverse, and high quality curated dataset to drive innovation in AI techniques.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

Tracing Versus Freehand for Evaluating Computer-Generated Drawings (SIGGRAPH 2021)
Tracing Versus Freehand for Evaluating Computer-Generated Drawings (SIGGRAPH 2021) Zeyu Wang, Sherry Qiu, Nicole Feng, Holly Rushmeier, Leonard McMill
 23 Dec 9, 2022
23 Dec 9, 2022

COVID-Net Open Source Initiative
The COVID-Net models provided here are intended to be used as reference models that can be built upon and enhanced as new data becomes available
 1.1k Dec 26, 2022
1.1k Dec 26, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022

Code for generating a single image pretraining dataset
Single Image Pretraining of Visual Representations As shown in the paper A critical analysis of self-supervision, or what we can learn from a single i
 12 Dec 19, 2022
12 Dec 19, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022
This repository contains the code for using the H3DS dataset introduced in H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
H3DS Dataset This repository contains the code for using the H3DS dataset introduced in H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction Access
 72 Dec 10, 2022
72 Dec 10, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022
Source code and Dataset creation for the paper "Neural Symbolic Regression That Scales"
NeuralSymbolicRegressionThatScales Pytorch implementation and pretrained models for the paper "Neural Symbolic Regression That Scales", presented at I
 35 Nov 25, 2022
35 Nov 25, 2022
Re-TACRED: Addressing Shortcomings of the TACRED Dataset
Re-TACRED Re-TACRED: Addressing Shortcomings of the TACRED Dataset
 40 Dec 10, 2022
40 Dec 10, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023

A PyTorch toolkit for 2D Human Pose Estimation.
PyTorch-Pose PyTorch-Pose is a PyTorch implementation of the general pipeline for 2D single human pose estimation. The aim is to provide the interface
 1.1k Dec 30, 2022
1.1k Dec 30, 2022

Synthetic LiDAR sequential point cloud dataset with point-wise annotations
SynLiDAR dataset: Learning From Synthetic LiDAR Sequential Point Cloud This is official repository of the SynLiDAR dataset. For technical details, ple
 78 Dec 27, 2022
78 Dec 27, 2022
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks (SDPoint) This repository contains the cod
 17 Jul 4, 2022
17 Jul 4, 2022
Tooling for the Common Objects In 3D dataset.
CO3D: Common Objects In 3D This repository contains a set of tools for working with the Common Objects in 3D (CO3D) dataset. Download the dataset The
724 Jan 6, 2023
Moment-DETR code and QVHighlights dataset
Moment-DETR QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries Jie Lei, Tamara L. Berg, Mohit Bansal For dataset de
 133 Dec 22, 2022
133 Dec 22, 2022
Reference implementation of code generation projects from Facebook AI Research. General toolkit to apply machine learning to code, from dataset creation to model training and evaluation. Comes with pretrained models.
This repository is a toolkit to do machine learning for programming languages. It implements tokenization, dataset preprocessing, model training and m
408 Jan 1, 2023

A simple python tool for explore your object detection dataset
A simple tool for explore your object detection dataset. The goal of this library is to provide simple and intuitive visualizations from your dataset and automatically find the best parameters for generating a specific grid of anchors that can fit you data characteristics
 142 Dec 25, 2022
142 Dec 25, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

Implementation of QuickDraw - an online game developed by Google, combined with AirGesture - a simple gesture recognition application
QuickDraw - AirGesture Introduction Here is my python source code for QuickDraw - an online game developed by google, combined with AirGesture - a sim
 89 Dec 18, 2022
89 Dec 18, 2022
LiDAR R-CNN: An Efficient and Universal 3D Object Detector
LiDAR R-CNN: An Efficient and Universal 3D Object Detector Introduction This is the official code of LiDAR R-CNN: An Efficient and Universal 3D Object
 295 Jan 5, 2023
295 Jan 5, 2023

A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
 75 Dec 26, 2022
75 Dec 26, 2022

Semantic Segmentation of images using PixelLib with help of Pascalvoc dataset trained with Deeplabv3+ framework.
CARscan- Approach 1 - Segmentation of images by detecting contours. It failed because in images with elements along with cars were also getting detect
 5 Jul 29, 2021
5 Jul 29, 2021

Using Tensorflow Object Detection API to detect Waymo open dataset
Waymo-2D-Object-Detection Using Tensorflow Object Detection API to detect Waymo open dataset Result CenterNet Training Loss SSD ResNet Training Loss C
 76 Dec 12, 2022
76 Dec 12, 2022
Code and dataset for ACL2018 paper "Exploiting Document Knowledge for Aspect-level Sentiment Classification"
Aspect-level Sentiment Classification Code and dataset for ACL2018 [paper] ‘‘Exploiting Document Knowledge for Aspect-level Sentiment Classification’’
 146 Nov 29, 2022
146 Nov 29, 2022

The first dataset of composite images with rationality score indicating whether the object placement in a composite image is reasonable.
Object-Placement-Assessment-Dataset-OPA Object-Placement-Assessment (OPA) is to verify whether a composite image is plausible in terms of the object p
 53 Nov 15, 2022
53 Nov 15, 2022

The first dataset on shadow generation for the foreground object in real-world scenes.
Object-Shadow-Generation-Dataset-DESOBA Object Shadow Generation is to deal with the shadow inconsistency between the foreground object and the backgr
105 Dec 30, 2022

Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
 22 Nov 8, 2022
22 Nov 8, 2022

Check the basic quality of any dataset
Data Quality Checker in Python Check the basic quality of any dataset. Sneak Peek Read full tutorial at Medium. Explore the app Requirements python 3.
 8 Feb 23, 2022
8 Feb 23, 2022
Fixes 500+ mislabeled MURA images
In this repository, new csv files are provided that fixes 500+ mislabeled MURA x-rays for all categories. The mislabeled x-rays mainly had hardware in them. This project only fixes the false negatives for now.
 4 May 18, 2022
4 May 18, 2022

SDL: Synthetic Document Layout dataset
SDL is the project that synthesizes document images. It facilitates multiple-level labeling on document images and can generate in multiple languages.
 0 Oct 7, 2021
0 Oct 7, 2021
Large dataset storage format for Pytorch
H5Record Large dataset ( 100G, = 1T) storage format for Pytorch (wip) Support python 3 pip install h5record Why? Writing large dataset is still a
 43 Oct 22, 2022
43 Oct 22, 2022

This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transformations at CVPR'21. According to some product reasons, we are not planning to release the training/testing codes and models. However, we will release the dataset and the scripts to prepare the dataset.
TransFill-Reference-Inpainting This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transf
 80 Dec 8, 2022
80 Dec 8, 2022
![[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach](https://github.com/SHI-Labs/Rethinking-Text-Segmentation/raw/main/.figure/image_only.jpg)
[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach This is the repo to host the dataset TextSeg and code for TexRNe
 174 Dec 19, 2022
174 Dec 19, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023

A large dataset of 100k Google Satellite and matching Map images, resembling pix2pix's Google Maps dataset.
Larger Google Sat2Map dataset This dataset extends the aerial ⟷ Maps dataset used in pix2pix (Isola et al., CVPR17). The provide script download_sat2m
 34 Dec 28, 2022
34 Dec 28, 2022
BloodCheck enables Red and Blue Teams to manage multiple Neo4j databases and run Cypher queries against a BloodHound dataset.
BloodCheck BloodCheck enables Red and Blue Teams to manage multiple Neo4j databases and run Cypher queries against a BloodHound dataset. Installation
 16 Nov 5, 2021
16 Nov 5, 2021

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023

A dataset for online Arabic calligraphy
Calliar Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic callig
 114 Dec 28, 2022
114 Dec 28, 2022

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022

Code for SIMMC 2.0: A Task-oriented Dialog Dataset for Immersive Multimodal Conversations
The Second Situated Interactive MultiModal Conversations (SIMMC 2.0) Challenge 2021 Welcome to the Second Situated Interactive Multimodal Conversation
81 Nov 22, 2022

Open-sourcing the Slates Dataset for recommender systems research
FINN.no Recommender Systems Slate Dataset This repository accompany the paper "Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sa
 48 Nov 28, 2022
48 Nov 28, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

Official Code for ICML 2021 paper "Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline"
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline Ankit Goyal, Hei Law, Bowei Liu, Alejandro Newell, Jia Deng Internati
 115 Jan 4, 2023
115 Jan 4, 2023

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022
A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation(DANN), support Office-31 and Office-Home dataset
DANN A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation Prerequisites Linux or OSX NVIDIA GPU + CUDA (may CuDNN) and corre
 8 Apr 16, 2022
8 Apr 16, 2022
This is the dataset and code release of the OpenRooms Dataset.
This is the dataset and code release of the OpenRooms Dataset.
 95 Jan 8, 2023
95 Jan 8, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022
code for modular summarization work published in ACL2021 by Krishna et al
This repository contains the code for running modular summarization pipelines as described in the publication Krishna K, Khosla K, Bigham J, Lipton ZC
 6 Jun 4, 2021
6 Jun 4, 2021

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022
code for modular summarization work published in ACL2021 by Krishna et al
This repository contains the code for running modular summarization pipelines as described in the publication Krishna K, Khosla K, Bigham J, Lipton ZC
 21 Nov 24, 2022
21 Nov 24, 2022

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
DSTC10 Track 2 - Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations
DSTC10 Track 2 - Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations This repository contains the data, scripts and baseline co
 51 Dec 17, 2022
51 Dec 17, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022

IMGUR5K handwriting set. It is a handwritten in-the-wild dataset, which contains challenging real world handwritten samples from different writers.The dataset is shared as a set of image urls with annotations. This code downloads the images and verifies the hash to the image to avoid data contamination.
IMGUR5K Handwriting Dataset To run the code for downloading the urls and generate corresponding annotations : Usage: python download_imgur5k.py --data
213 Dec 26, 2022
A Dataset of Python Challenges for AI Research
Python Programming Puzzles (P3) This repo contains a dataset of python programming puzzles which can be used to teach and evaluate an AI's programming
 850 Dec 24, 2022
850 Dec 24, 2022

Aerial Imagery dataset for fire detection: classification and segmentation (Unmanned Aerial Vehicle (UAV))
Aerial Imagery dataset for fire detection: classification and segmentation using Unmanned Aerial Vehicle (UAV) Title FLAME (Fire Luminosity Airborne-b
 79 Jan 6, 2023
79 Jan 6, 2023

COVID-19 deaths statistics around the world
COVID-19-Deaths-Dataset COVID-19 deaths statistics around the world This is a daily updated dataset of COVID-19 deaths around the world. The dataset c
 4 Jul 10, 2022
4 Jul 10, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022