1774 Repositories
Python text-summarization-dataset Libraries

Official code for our CVPR '22 paper "Dataset Distillation by Matching Training Trajectories"
Dataset Distillation by Matching Training Trajectories Project Page | Paper This repo contains code for training expert trajectories and distilling sy
 256 Jan 5, 2023
256 Jan 5, 2023

Official MegEngine implementation of CREStereo(CVPR 2022 Oral).
[CVPR 2022] Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation This repository contains MegEngine implementation of ou
 309 Dec 30, 2022
309 Dec 30, 2022
This program uses trial auth token of Azure Cognitive Services to do speech synthesis for you.
🗣️ aspeak A simple text-to-speech client using azure TTS API(trial). 😆 TL;DR: This program uses trial auth token of Azure Cognitive Services to do s
 359 Jan 5, 2023
359 Jan 5, 2023
Relative Human dataset, CVPR 2022
Relative Human (RH) contains multi-person in-the-wild RGB images with rich human annotations, including: Depth layers (DLs): relative depth relationsh
 112 Dec 2, 2022
112 Dec 2, 2022
OOD Dataset Curator and Benchmark for AI-aided Drug Discovery
🔥 DrugOOD 🔥 : OOD Dataset Curator and Benchmark for AI Aided Drug Discovery This is the official implementation of the DrugOOD project, this is the
 108 Dec 17, 2022
108 Dec 17, 2022

Pytorch implementation of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Make-A-Scene - PyTorch Pytorch implementation (inofficial) of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors (https://arxiv.org/
 259 Dec 28, 2022
259 Dec 28, 2022
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

KwaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%)
KuaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%) KuaiRec is a real-world dataset collected from the recommendation log
 70 Dec 28, 2022
70 Dec 28, 2022
🐤 Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
🐤 Nix-TTS An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation Rendi Chevi, Radityo Eko Prasojo, Alham Fikri Aji
 156 Jan 9, 2023
156 Jan 9, 2023
Parallel and High-Fidelity Text-to-Lip Generation; AAAI 2022 ; Official code
Parallel and High-Fidelity Text-to-Lip Generation This repository is the official PyTorch implementation of our AAAI-2022 paper, in which we propose P
 77 Dec 21, 2022
77 Dec 21, 2022

Entity Disambiguation as text extraction (ACL 2022)
ExtEnD: Extractive Entity Disambiguation This repository contains the code of ExtEnD: Extractive Entity Disambiguation, a novel approach to Entity Dis
 121 Jan 3, 2023
121 Jan 3, 2023

A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution (CVPR2022)
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution (CVPR2022) https://arxiv.org/abs/2203.09388 Jianqi Ma, Zheto
 104 Jan 5, 2023
104 Jan 5, 2023

Generate images from texts. In Russian
ruDALL-E Generate images from texts pip install rudalle==1.1.0rc0 🤗 HF Models: ruDALL-E Malevich (XL) ruDALL-E Emojich (XL) (readme here) ruDALL-E S
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

This repository consists of a complete guide on natural language processing (NLP) in Python where we'll learn various techniques for implementing NLP including parsing & text processing and understand how to use NLP for text feature engineering.
Python_Natural_Language_Processing This repository contains tutorials on important topics related to Natural Language Processing (NPL). No. Name 01 01
 170 Dec 13, 2022
170 Dec 13, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023
![[SIGGRAPH 2022 Journal Track] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars](https://github.com/hongfz16/AvatarCLIP/raw/main/assets/tallandskinny_femalesoldier_arguing.gif)
[SIGGRAPH 2022 Journal Track] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars Fangzhou Hong1* Mingyuan Zhang1* Liang Pan1 Zhongang Cai1,2,3 Lei Yang2
 749 Jan 4, 2023
749 Jan 4, 2023

Official PyTorch implementation of the paper "TEMOS: Generating diverse human motions from textual descriptions"
TEMOS: TExt to MOtionS Generating diverse human motions from textual descriptions Description Official PyTorch implementation of the paper "TEMOS: Gen
 187 Dec 27, 2022
187 Dec 27, 2022

BankNote-Net: Open dataset and encoder model for assistive currency recognition
BankNote-Net: Open Dataset for Assistive Currency Recognition Millions of people around the world have low or no vision. Assistive software applicatio
 13 Oct 28, 2022
13 Oct 28, 2022
Simple, Fast, Powerful and Easily extensible python package for extracting patterns from text, with over than 60 predefined Regular Expressions.
patterns-finder Simple, Fast, Powerful and Easily extensible python package for extracting patterns from text, with over than 60 predefined Regular Ex
 22 Dec 19, 2022
22 Dec 19, 2022

Comprehensive-E2E-TTS - PyTorch Implementation
A Non-Autoregressive End-to-End Text-to-Speech (text-to-wav), supporting a family of SOTA unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate E2E-TTS
 114 Nov 13, 2022
114 Nov 13, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022
Finally, some decent sample sentences
tts-dataset-prompts This repository aims to be a decent set of sentences for people looking to clone their own voices (e.g. using Tacotron 2). Each se
 19 Dec 13, 2022
19 Dec 13, 2022

Towards Implicit Text-Guided 3D Shape Generation (CVPR2022)
Towards Implicit Text-Guided 3D Shape Generation Towards Implicit Text-Guided 3D Shape Generation (CVPR2022) Code for the paper [Towards Implicit Text
 55 Dec 16, 2022
55 Dec 16, 2022
For visualizing the dair-v2x-i dataset
3D Detection & Tracking Viewer The project is based on hailanyi/3D-Detection-Tracking-Viewer and is modified, you can find the original version of the
 34 Dec 29, 2022
34 Dec 29, 2022

Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
CoCa - Pytorch Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch. They were able to elegantly fit in contras
 565 Dec 30, 2022
565 Dec 30, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

Pytorch re-implementation of Paper: SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition (CVPR 2022)
SwinTextSpotter This is the pytorch implementation of Paper: SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text R
 183 Jan 3, 2023
183 Jan 3, 2023

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset (CVPR2022)
FaceVerse FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset Lizhen Wang, Zhiyuan Chen, Tao Yu, Chenguang
 219 Dec 28, 2022
219 Dec 28, 2022
My Implementation for the paper EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks using Tensorflow
Easy Data Augmentation Implementation This repository contains my Implementation for the paper EDA: Easy Data Augmentation Techniques for Boosting Per
 9 Oct 31, 2022
9 Oct 31, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022

SentimentArcs: a large ensemble of dozens of sentiment analysis models to analyze emotion in text over time
SentimentArcs - Emotion in Text An end-to-end pipeline based on Jupyter notebooks to detect, extract, process and anlayze emotion over time in text. E
 14 Dec 19, 2022
14 Dec 19, 2022
Notebooks, slides and dataset of the CorrelAid Machine Learning Winter School
CorrelAid Machine Learning Spring School Welcome to the CorrelAid ML Spring School! In this repository you can find the slides and other files for the
 12 Nov 23, 2022
12 Nov 23, 2022

Precision Medicine Knowledge Graph (PrimeKG)
PrimeKG Website | bioRxiv Paper | Harvard Dataverse Precision Medicine Knowledge Graph (PrimeKG) presents a holistic view of diseases. PrimeKG integra
 103 Dec 10, 2022
103 Dec 10, 2022

The official GitHub repository for the Argoverse 2 dataset.
Argoverse 2 API Official GitHub repository for the Argoverse 2 family of datasets. If you have any questions or run into any problems with either the
 156 Dec 23, 2022
156 Dec 23, 2022
![ISNAS-DIP: Image Specific Neural Architecture Search for Deep Image Prior [CVPR 2022]](https://github.com/ozgurkara99/ISNAS-DIP/raw/main/docs/method.jpg)
ISNAS-DIP: Image Specific Neural Architecture Search for Deep Image Prior [CVPR 2022]
ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image Prior (CVPR 2022) Metin Ersin Arican*, Ozgur Kara*, Gustav Bredell, Ender Konukogl
 24 Dec 18, 2022
24 Dec 18, 2022
The SVO-Probes Dataset for Verb Understanding
The SVO-Probes Dataset for Verb Understanding This repository contains the SVO-Probes benchmark designed to probe for Subject, Verb, and Object unders
 20 Nov 30, 2022
20 Nov 30, 2022

Context-Sensitive Misspelling Correction of Clinical Text via Conditional Independence, CHIL 2022
cim-misspelling Pytorch implementation of Context-Sensitive Spelling Correction of Clinical Text via Conditional Independence, CHIL 2022. This model (
 11 Dec 19, 2022
11 Dec 19, 2022

Process text, including tokenizing and representing sentences as vectors and Applying some concepts like RNN, LSTM and GRU to create a classifier can detect the language in which a sentence is written from among 17 languages.
Language Identifier What is this ? The goal of this project is to create a model that is able to predict a given sentence language through text proces
 9 Dec 15, 2022
9 Dec 15, 2022
Get started with Machine Learning with Python - An introduction with Python programming examples
Machine Learning With Python Get started with Machine Learning with Python An engaging introduction to Machine Learning with Python TL;DR Download all
 130 Jan 2, 2023
130 Jan 2, 2023

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Implements VQGAN+CLIP for image and video generation, and style transfers, based on text and image prompts. Emphasis on ease-of-use, documentation, and smooth video creation.
VQGAN-CLIP-GENERATOR Overview This is a package (with available notebook) for running VQGAN+CLIP locally, with a focus on ease of use, good documentat
 98 Dec 30, 2022
98 Dec 30, 2022

In this tutorial, you will perform inference across 10 well-known pre-trained object detectors and fine-tune on a custom dataset. Design and train your own object detector.
Object Detection Object detection is a computer vision task for locating instances of predefined objects in images or videos. In this tutorial, you wi
 62 Dec 25, 2022
62 Dec 25, 2022

Code of paper: "DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks"
DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks Abstract: Adversarial training has been proven to
 58 Nov 10, 2022
58 Nov 10, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
 66 Dec 14, 2022
66 Dec 14, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023
SciFive: a text-text transformer model for biomedical literature
SciFive SciFive provided a Text-Text framework for biomedical language and natural language in NLP. Under the T5's framework and desrbibed in the pape
 54 Dec 24, 2022
54 Dec 24, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
87 Dec 21, 2022

Code for CVPR'2022 paper ✨ "Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model"
PPE ✨ Repository for our CVPR'2022 paper: Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-
 34 Nov 28, 2022
34 Nov 28, 2022

This project contains the ClonedPerson dataset and code described in our paper "Cloning Outfits from Real-World Images to 3D Characters for Generalizable Person Re-Identification".
ClonedPerson This is the official repository for the ClonedPerson project, which contains the ClonedPerson dataset and code described in our paper "Cl
 55 Dec 27, 2022
55 Dec 27, 2022
Everything you want about DP-Based Federated Learning, including Papers and Code. (Mechanism: Laplace or Gaussian, Dataset: femnist, shakespeare, mnist, cifar-10 and fashion-mnist. )
Differential Privacy (DP) Based Federated Learning (FL) Everything about DP-based FL you need is here. (所有你需要的DP-based FL的信息都在这里) Code Tip: the code o
 83 Dec 24, 2022
83 Dec 24, 2022
![[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators](https://github.com/microsoft/AMOS/raw/main/AMOS.png)
[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
AMOS This repository contains the scripts for fine-tuning AMOS pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: Pretraining Text Encoders wi
22 Sep 15, 2022

Official code for "Bridging Video-text Retrieval with Multiple Choice Questions", CVPR 2022 (Oral).
Bridging Video-text Retrieval with Multiple Choice Questions, CVPR 2022 (Oral) Paper | Project Page | Pre-trained Model | CLIP-Initialized Pre-trained
 99 Jan 6, 2023
99 Jan 6, 2023
![[x]it! support for working with todo and check list files in Sublime Text](https://github.com/jotaen/xit-sublime/raw/main/resources/xit-demo.png)
[x]it! support for working with todo and check list files in Sublime Text
[x]it! for Sublime Text This Sublime Package provides syntax-highlighting, shortcuts, and auto-completions for [x]it! files. Features Syntax highlight
 18 Sep 19, 2022
18 Sep 19, 2022
Direct application of DALLE-2 to video synthesis, using factored space-time Unet and Transformers
DALLE2 Video (wip) ** only to be built after DALLE2 image is done and replicated, and the importance of the prior network is validated ** Direct appli
105 May 15, 2022

A Human-in-the-Loop workflow for creating HD images from text
A Human-in-the-Loop? workflow for creating HD images from text DALL·E Flow is an interactive workflow for generating high-definition images from text
 2.5k Jan 2, 2023
2.5k Jan 2, 2023

CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
CLIP-GEN [简体中文][English] 本项目在萤火二号集群上用 PyTorch 实现了论文 《CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP》。 CLIP-GEN 是一个 Language-F
 75 Dec 29, 2022
75 Dec 29, 2022
Weakly Supervised Text-to-SQL Parsing through Question Decomposition
Weakly Supervised Text-to-SQL Parsing through Question Decomposition The official repository for the paper "Weakly Supervised Text-to-SQL Parsing thro
 14 Dec 19, 2022
14 Dec 19, 2022
![[LREC] MMChat: Multi-Modal Chat Dataset on Social Media](https://github.com/silverriver/MMChat/raw/main/bin/sample.jpg)
[LREC] MMChat: Multi-Modal Chat Dataset on Social Media
MMChat This repo contains the code and data for the LREC2022 paper MMChat: Multi-Modal Chat Dataset on Social Media. Dataset MMChat is a large-scale d
 47 Jan 3, 2023
47 Jan 3, 2023
Read Japanese manga inside browser with selectable text.
mokuro Read Japanese manga with selectable text inside a browser. See demo: https://kha-white.github.io/manga-demo mokuro_demo.mp4 Demo contains excer
170 Dec 27, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Helping data scientists better understand their datasets and models in text classification. With love from ServiceNow.
Azimuth, an open-source dataset and error analysis tool for text classification, with love from ServiceNow. Overview Azimuth is an open source applica
 145 Dec 23, 2022
145 Dec 23, 2022

The repo for the paper "I3CL: Intra- and Inter-Instance Collaborative Learning for Arbitrary-shaped Scene Text Detection".
I3CL: Intra- and Inter-Instance Collaborative Learning for Arbitrary-shaped Scene Text Detection Updates | Introduction | Results | Usage | Citation |
 33 Jan 5, 2023
33 Jan 5, 2023
![[arXiv22] Disentangled Representation Learning for Text-Video Retrieval](https://github.com/foolwood/DRL/raw/main/demo/pipeline.png)
[arXiv22] Disentangled Representation Learning for Text-Video Retrieval
Disentangled Representation Learning for Text-Video Retrieval This is a PyTorch implementation of the paper Disentangled Representation Learning for T
 49 Dec 18, 2022
49 Dec 18, 2022
"Video Moment Retrieval from Text Queries via Single Frame Annotation" in SIGIR 2022.
ViGA: Video moment retrieval via Glance Annotation This is the official repository of the paper "Video Moment Retrieval from Text Queries via Single F
 38 Dec 31, 2022
38 Dec 31, 2022

This repository contains the data and code for the paper "Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors" (SPNLP@ACL2022)
GP-VAE This repository provides datasets and code for preprocessing, training and testing models for the paper: Diverse Text Generation via Variationa
 18 Dec 29, 2022
18 Dec 29, 2022
Text classification is one of the popular tasks in NLP that allows a program to classify free-text documents based on pre-defined classes.
Deep-Learning-for-Text-Document-Classification Text classification is one of the popular tasks in NLP that allows a program to classify free-text docu
 2 Mar 17, 2022
2 Mar 17, 2022

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022

Author: Wenhao Yu ([email protected]). ACL 2022. Commonsense Reasoning on Knowledge Graph for Text Generation
Diversifying Commonsense Reasoning Generation on Knowledge Graph Introduction -- This is the pytorch implementation of our ACL 2022 paper "Diversifyin
 61 Dec 30, 2022
61 Dec 30, 2022
Creating a custom CNN hypertunned architeture for the Fashion MNIST dataset with Python, Keras and Tensorflow.
custom-cnn-fashion-mnist Creating a custom CNN hypertunned architeture for the Fashion MNIST dataset with Python, Keras and Tensorflow. The following
 1 Mar 5, 2022
1 Mar 5, 2022

In this project, RandomOverSampler and SMOTE algorithms were used to perform oversampling, ClusterCentroids algorithm was used to undersampling, SMOTEENN algorithm was applied as a combinatorial approach of over- and undersampling of credit card credit dataset from LendingClub. Machine learning models - BalancedRandomForestClassifier and EasyEnsembleClassifier were used to predict credit risk.
Overview of Credit Card Analysis In this project, RandomOverSampler and SMOTE algorithms were used to perform oversampling, ClusterCentroids algorithm
 1 Mar 12, 2022
1 Mar 12, 2022

This is a Text Data Analysis Project Involving (YouTube Case Study).
Text_Data_Analysis This is a Text Data Analysis Project Involving (YouTube Case Study). Problem Statement = Sentiment Analysis. Package1: There are m
 1 Mar 5, 2022
1 Mar 5, 2022
Code for ACL 2022 main conference paper "STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation".
STEMM: Self-learning with Speech-Text Manifold Mixup for Speech Translation This is a PyTorch implementation for the ACL 2022 main conference paper ST
 29 Oct 16, 2022
29 Oct 16, 2022
This project aims to conduct a text information retrieval and text mining on medical research publication regarding Covid19 - treatments and vaccinations.
Project: Text Analysis - This project aims to conduct a text information retrieval and text mining on medical research publication regarding Covid19 -
 1 Mar 14, 2022
1 Mar 14, 2022
code for the ICLR'22 paper: On Robust Prefix-Tuning for Text Classification
On Robust Prefix-Tuning for Text Classification Prefix-tuning has drawed much attention as it is a parameter-efficient and modular alternative to adap
 12 Nov 30, 2022
12 Nov 30, 2022
Group project for MFIN7036. Our goal is to predict firm profitability with text-based competition measures.
NLP_0-project Group project for MFIN7036. Our goal is to predict firm profitability with text-based competition measures1. We are a "democratic" and c
 3 Mar 16, 2022
3 Mar 16, 2022
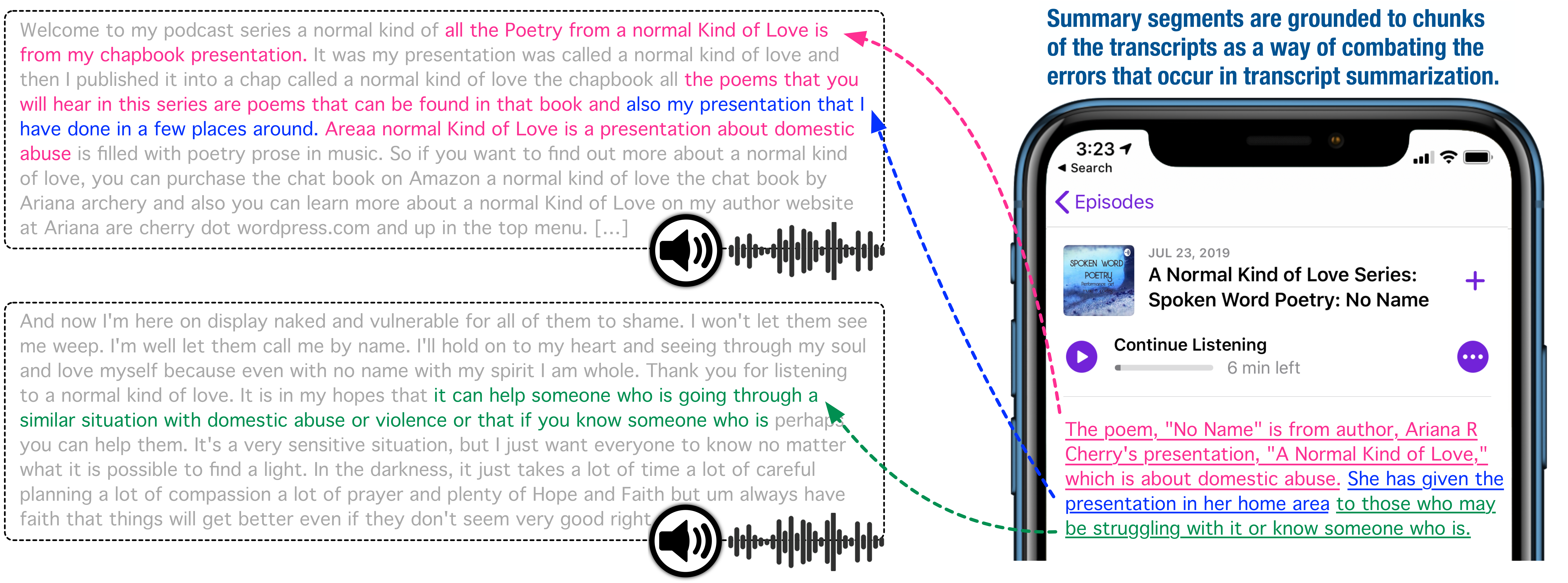
(ACL 2022) The source code for the paper "Towards Abstractive Grounded Summarization of Podcast Transcripts"
Towards Abstractive Grounded Summarization of Podcast Transcripts We provide the source code for the paper "Towards Abstractive Grounded Summarization
10 Jul 1, 2022
Input english text, then translate it between languages n times using the Deep Translator Python Library.
mass-translator About Input english text, then translate it between languages n times using the Deep Translator Python Library. How to Use Install dep
 2 Mar 4, 2022
2 Mar 4, 2022
a simple, efficient, and intuitive text editor
Oxygen beta a simple, efficient, and intuitive text editor Overview oxygen is a simple, efficient, and intuitive text editor designed as more featured
 1 Feb 23, 2022
1 Feb 23, 2022

Pdraw - Generate Deterministic, Procedural Artwork from Arbitrary Text
pdraw.py: Generate Deterministic, Procedural Artwork from Arbitrary Text pdraw a
 2 Sep 12, 2022
2 Sep 12, 2022

PyTorch Implementation of DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS - PyTorch Implementation PyTorch implementation of DiffGAN-TTS: High
157 Jan 1, 2023
Django-Text-to-HTML-converter - The simple Text to HTML Converter using Django framework
Django-Text-to-HTML-converter This is the simple Text to HTML Converter using Dj
 6 Oct 9, 2022
6 Oct 9, 2022

ZeroGen: Efficient Zero-shot Learning via Dataset Generation
ZEROGEN This repository contains the code for our paper “ZeroGen: Efficient Zero
 31 Dec 30, 2022
31 Dec 30, 2022
SimCTG - A Contrastive Framework for Neural Text Generation
A Contrastive Framework for Neural Text Generation Authors: Yixuan Su, Tian Lan,
345 Jan 3, 2023
PaintPrint - This module can colorize any text in your terminal
PaintPrint This module can colorize any text in your terminal Author: tankalxat3
 2 Feb 17, 2022
2 Feb 17, 2022

Breaching - Breaching privacy in federated learning scenarios for vision and text
Breaching - A Framework for Attacks against Privacy in Federated Learning This P
 139 Jan 3, 2023
139 Jan 3, 2023
Python-Strongest-Encrypter - Transform your text into encrypted symbols using their dictionary
How does the encrypter works? Transform your text into encrypted symbols using t
 1 Jul 10, 2022
1 Jul 10, 2022

Text-Summarization-using-NLP - Text Summarization using NLP to fetch BBC News Article and summarize its text and also it includes custom article Summarization
Text-Summarization-using-NLP Text Summarization using NLP to fetch BBC News Arti
 21 Aug 6, 2022
21 Aug 6, 2022

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 36 Feb 13, 2022
36 Feb 13, 2022
Dataset Condensation with Contrastive Signals
Dataset Condensation with Contrastive Signals This repository is the official implementation of Dataset Condensation with Contrastive Signals (DCC). T
 3 May 19, 2022
3 May 19, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022
PyTorch implementation of NATSpeech: A Non-Autoregressive Text-to-Speech Framework
A Non-Autoregressive Text-to-Speech (NAR-TTS) framework, including official PyTorch implementation of PortaSpeech (NeurIPS 2021) and DiffSpeech (AAAI 2022)
 760 Jan 3, 2023
760 Jan 3, 2023

Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track)
Kcse-Data-Analysis Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track) Findings The performance of
 1 Feb 23, 2022
1 Feb 23, 2022
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022