84 Repositories
Python summarization-corpora Libraries
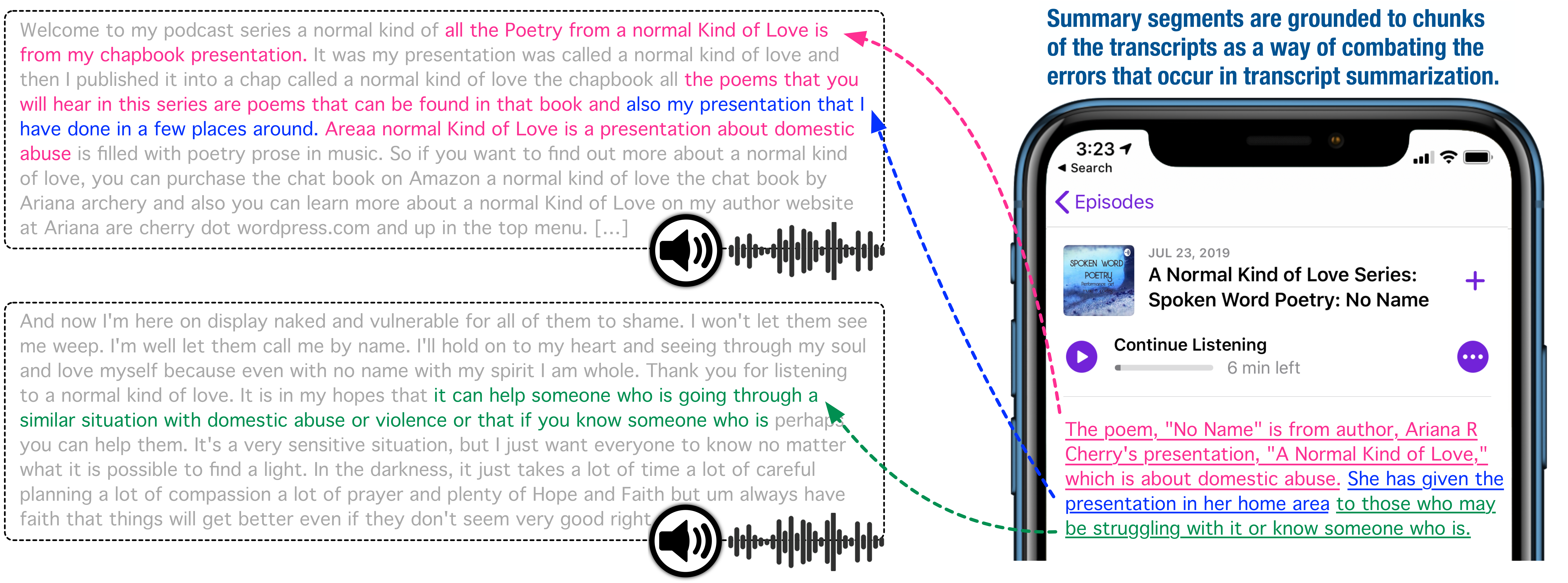
(ACL 2022) The source code for the paper "Towards Abstractive Grounded Summarization of Podcast Transcripts"
Towards Abstractive Grounded Summarization of Podcast Transcripts We provide the source code for the paper "Towards Abstractive Grounded Summarization
 10 Jul 1, 2022
10 Jul 1, 2022

Text-Summarization-using-NLP - Text Summarization using NLP to fetch BBC News Article and summarize its text and also it includes custom article Summarization
Text-Summarization-using-NLP Text Summarization using NLP to fetch BBC News Arti
 21 Aug 6, 2022
21 Aug 6, 2022
Scripts to convert the Ted-MDB corpora into the formats for DISRPT shared task and the converted corpora
Scripts to convert the Ted-MDB corpora into the formats for DISRPT shared task and the converted corpora.
 1 Feb 8, 2022
1 Feb 8, 2022

The NewSHead dataset is a multi-doc headline dataset used in NHNet for training a headline summarization model.
This repository contains the raw dataset used in NHNet [1] for the task of News Story Headline Generation. The code of data processing and training is available under Tensorflow Models - NHNet.
 31 Jul 15, 2022
31 Jul 15, 2022
NaijaSenti is an open-source sentiment and emotion corpora for four major Nigerian languages
NaijaSenti is an open-source sentiment and emotion corpora for four major Nigerian languages. This project was supported by lacuna-fund initiatives. Jump straight to one of the sections below, or just scroll down to find out more.
 14 Dec 20, 2022
14 Dec 20, 2022
Klexikon: A German Dataset for Joint Summarization and Simplification
Klexikon: A German Dataset for Joint Summarization and Simplification Dennis Aumiller and Michael Gertz Heidelberg University Under submission at LREC
 8 Jan 3, 2023
8 Jan 3, 2023

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
AMUSE - financial summarization
AMUSE AMUSE - financial summarization Unzip data.zip Train new model: python FinAnalyze.py --task train --start 0 --count how many files,-1 for all
 1 Jan 11, 2022
1 Jan 11, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
Official Implementation of "DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization."
DialogLM Code for AAAI 2022 paper: DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization. Pre-trained Models We release two ve
 92 Dec 19, 2022
92 Dec 19, 2022
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023

Understand Text Summarization and create your own summarizer in python
Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.
 1 Oct 18, 2022
1 Oct 18, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Text Summarization - WCN — Weighted Contextual N-gram method for evaluation of Text Summarization
Text Summarization WCN — Weighted Contextual N-gram method for evaluation of Text Summarization In this project, I fine tune T5 model on Extreme Summa
 1 Jan 3, 2022
1 Jan 3, 2022
Pointer-generator - Code for the ACL 2017 paper Get To The Point: Summarization with Pointer-Generator Networks
Note: this code is no longer actively maintained. However, feel free to use the Issues section to discuss the code with other users. Some users have u
 2.1k Jan 4, 2023
2.1k Jan 4, 2023
Age of Empires II recorded game parsing and summarization in Python 3.
mgz Age of Empires II recorded game parsing and summarization in Python 3. Supported Versions Age of Kings (.mgl) The Conquerors (.mgx) Userpatch 1.4
 148 Dec 11, 2022
148 Dec 11, 2022

This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs".
CrossSum This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summ
 29 Nov 19, 2022
29 Nov 19, 2022
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Table of contents Introduction Using BARTpho with fairseq Using BARTpho with transformers Notes BARTpho: Pre-trained Sequence-to-Sequence Models for V
 58 Dec 23, 2022
58 Dec 23, 2022
Official code repository for "Exploring Neural Models for Query-Focused Summarization"
Query-Focused Summarization Official code repository for "Exploring Neural Models for Query-Focused Summarization" This is a work in progress. Expect
 29 Dec 18, 2022
29 Dec 18, 2022
Repo for Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
ESACL: Enhanced Seq2Seq Autoencoder via Contrastive Learning for AbstractiveText Summarization This repo is for our paper "Enhanced Seq2Seq Autoencode
 14 Nov 1, 2022
14 Nov 1, 2022
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models
PEGASUS library Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised
 1.4k Dec 22, 2022
1.4k Dec 22, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022

Korean extractive summarization. 2021 AI 텍스트 요약 온라인 해커톤 화성갈끄니까팀 코드
korean extractive summarization 2021 AI 텍스트 요약 온라인 해커톤 화성갈끄니까팀 코드 Leaderboard Notice Text Summarization with Pretrained Encoders에 나오는 bertsumext모델(ext
 3 Aug 10, 2022
3 Aug 10, 2022
Simple GUI where you can enter an article and get a crisp summarized version.
Text-Summarization-using-TextRank-BART Simple GUI where you can enter an article and get a crisp summarized version. How to run: Clone the repo Instal
 4 Sep 28, 2022
4 Sep 28, 2022
A PyTorch Implementation of PGL-SUM from "Combining Global and Local Attention with Positional Encoding for Video Summarization", Proc. IEEE ISM 2021
PGL-SUM: Combining Global and Local Attention with Positional Encoding for Video Summarization PyTorch Implementation of PGL-SUM From "PGL-SUM: Combin
 35 Dec 22, 2022
35 Dec 22, 2022
WSDM‘2022: Knowledge Enhanced Sports Game Summarization
Knowledge Enhanced Sports Game Summarization Cooming Soon! :) Data will be released after approval process. Code will be published once the author of
 14 Jul 13, 2022
14 Jul 13, 2022
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021
code for EMNLP 2019 paper Text Summarization with Pretrained Encoders
PreSumm This code is for EMNLP 2019 paper Text Summarization with Pretrained Encoders Updates Jan 22 2020: Now you can Summarize Raw Text Input!. Swit
 1.2k Dec 28, 2022
1.2k Dec 28, 2022
Code for Discovering Topics in Long-tailed Corpora with Causal Intervention.
Code for Discovering Topics in Long-tailed Corpora with Causal Intervention ACL2021 Findings Usage 0. Prepare environment Requirements: python==3.6 te
 8 Dec 16, 2022
8 Dec 16, 2022
Multiple implementations for abstractive text summurization , using google colab
Text Summarization models if you are able to endorse me on Arxiv, i would be more than glad https://arxiv.org/auth/endorse?x=FRBB89 thanks This repo i
 463 Dec 26, 2022
463 Dec 26, 2022
This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
SummaC: Summary Consistency Detection This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Det
 24 Jan 3, 2023
24 Jan 3, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022
Improving Factual Consistency of Abstractive Text Summarization
Improving Factual Consistency of Abstractive Text Summarization We provide the code for the papers: "Entity-level Factual Consistency of Abstractive T
 61 Nov 27, 2022
61 Nov 27, 2022
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
This is REST-API for Indonesian Text Summarization using Non-Negative Matrix Factorization for the algorithm to summarize documents and FastAPI for the framework.
Indonesian Text Summarization Using FastAPI This is REST-API for Indonesian Text Summarization using Non-Negative Matrix Factorization for the algorit
 2 Nov 3, 2022
2 Nov 3, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023

Pytorch implementation of "Get To The Point: Summarization with Pointer-Generator Networks"
About this repository This repo contains an Pytorch implementation for the ACL 2017 paper Get To The Point: Summarization with Pointer-Generator Netwo
 7 Oct 14, 2022
7 Oct 14, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022
Code and data for ACL2021 paper Cross-Lingual Abstractive Summarization with Limited Parallel Resources.
Multi-Task Framework for Cross-Lingual Abstractive Summarization (MCLAS) The code for ACL2021 paper Cross-Lingual Abstractive Summarization with Limit
 43 Nov 7, 2022
43 Nov 7, 2022
Does Pretraining for Summarization Reuqire Knowledge Transfer?
Pretraining summarization models using a corpus of nonsense
 12 Dec 19, 2022
12 Dec 19, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
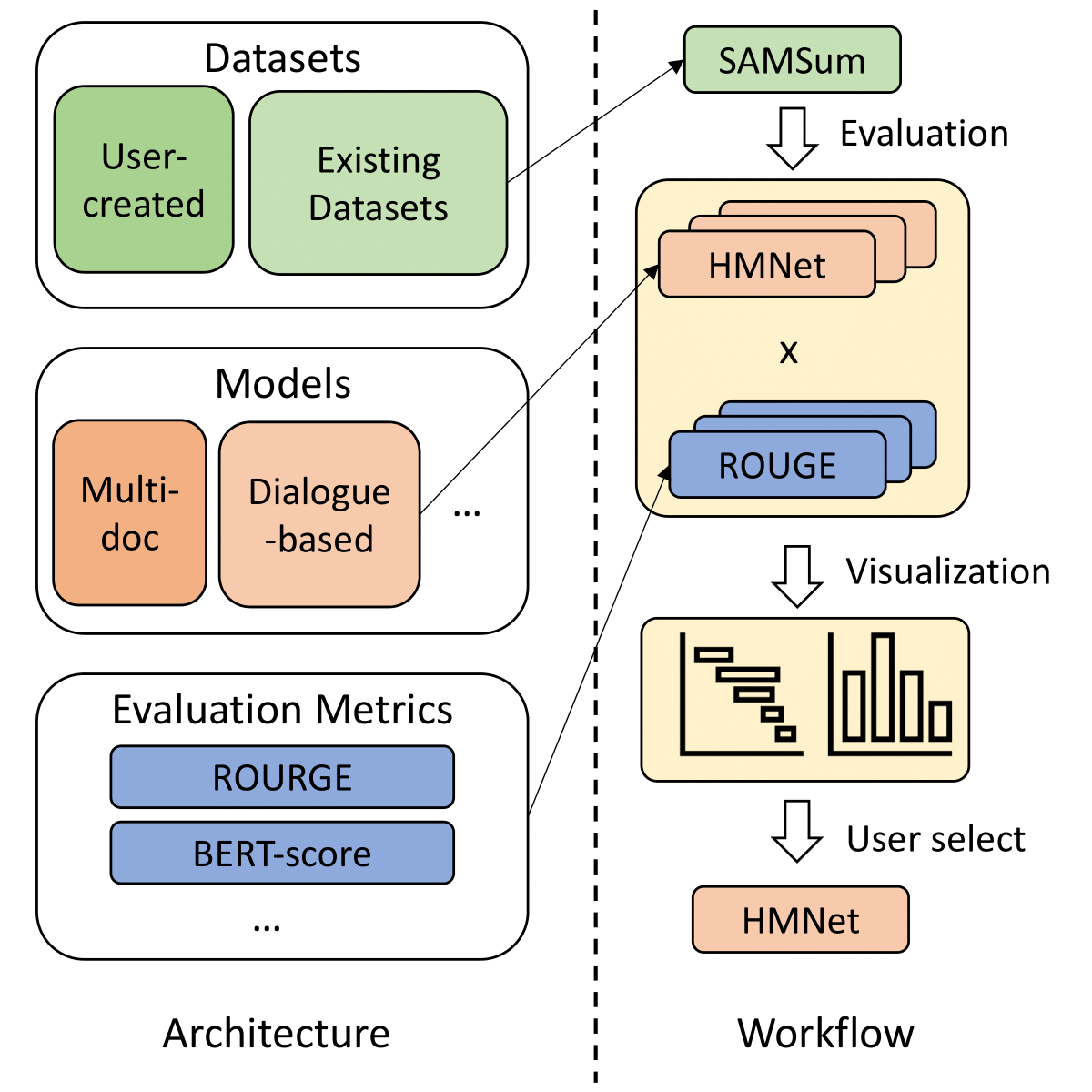
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer Summary Explorer is a tool to visually inspect the summaries from several state-of-the-art neural summarization models across multipl
 42 Aug 14, 2022
42 Aug 14, 2022
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
42 Aug 14, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
203 Dec 20, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
190 Jan 3, 2023
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023
code for modular summarization work published in ACL2021 by Krishna et al
This repository contains the code for running modular summarization pipelines as described in the publication Krishna K, Khosla K, Bigham J, Lipton ZC
 6 Jun 4, 2021
6 Jun 4, 2021
code for modular summarization work published in ACL2021 by Krishna et al
This repository contains the code for running modular summarization pipelines as described in the publication Krishna K, Khosla K, Bigham J, Lipton ZC
21 Nov 24, 2022
Codebase for the Summary Loop paper at ACL2020
Summary Loop This repository contains the code for ACL2020 paper: The Summary Loop: Learning to Write Abstractive Summaries Without Examples. Training
 44 Nov 4, 2022
44 Nov 4, 2022
EMNLP 2020 - Summarizing Text on Any Aspects
Summarizing Text on Any Aspects This repo contains preliminary code of the following paper: Summarizing Text on Any Aspects: A Knowledge-Informed Weak
 35 Nov 14, 2022
35 Nov 14, 2022
Code for our paper "SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization", ACL 2021
SimCLS Code for our paper: "SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization", ACL 2021 1. How to Install Requirements
 150 Dec 12, 2022
150 Dec 12, 2022

simpleT5 is built on top of PyTorch-lightning⚡️ and Transformers🤗 that lets you quickly train your T5 models.
Quickly train T5 models in just 3 lines of code + ONNX support simpleT5 is built on top of PyTorch-lightning ⚡️ and Transformers 🤗 that lets you quic
 220 Dec 30, 2022
220 Dec 30, 2022
This is the repo for the paper `SumGNN: Multi-typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization'. (published in Bioinformatics'21)
SumGNN: Multi-typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization This is the code for our paper ``SumGNN: Multi-typed Drug
 58 Dec 21, 2022
58 Dec 21, 2022

This project provides an unsupervised framework for mining and tagging quality phrases on text corpora with pretrained language models (KDD'21).
UCPhrase: Unsupervised Context-aware Quality Phrase Tagging To appear on KDD'21...[pdf] This project provides an unsupervised framework for mining and
 146 Dec 22, 2022
146 Dec 22, 2022
Code for NAACL 2021 full paper "Efficient Attentions for Long Document Summarization"
LongDocSum Code for NAACL 2021 paper "Efficient Attentions for Long Document Summarization" This repository contains data and models needed to reprodu
 56 Jan 2, 2023
56 Jan 2, 2023

Codes for our IJCAI21 paper: Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization
DDAMS This is the pytorch code for our IJCAI 2021 paper Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization [Arxiv Pr
55 Dec 27, 2022

BOOKSUM: A Collection of Datasets for Long-form Narrative Summarization
BOOKSUM: A Collection of Datasets for Long-form Narrative Summarization Authors: Wojciech Kryściński, Nazneen Rajani, Divyansh Agarwal, Caiming Xiong,
125 Dec 31, 2022

Resources for the "Evaluating the Factual Consistency of Abstractive Text Summarization" paper
Evaluating the Factual Consistency of Abstractive Text Summarization Authors: Wojciech Kryściński, Bryan McCann, Caiming Xiong, and Richard Socher Int
165 Dec 21, 2022
Code and data for ACL2021 paper Cross-Lingual Abstractive Summarization with Limited Parallel Resources.
Multi-Task Framework for Cross-Lingual Abstractive Summarization (MCLAS) The code for ACL2021 paper Cross-Lingual Abstractive Summarization with Limit
43 Nov 7, 2022

FactSumm: Factual Consistency Scorer for Abstractive Summarization
FactSumm: Factual Consistency Scorer for Abstractive Summarization FactSumm is a toolkit that scores Factualy Consistency for Abstract Summarization W
 83 Jan 9, 2023
83 Jan 9, 2023
Source codes for "Structure-Aware Abstractive Conversation Summarization via Discourse and Action Graphs"
Structure-Aware-BART This repo contains codes for the following paper: Jiaao Chen, Diyi Yang:Structure-Aware Abstractive Conversation Summarization vi
 56 Dec 8, 2022
56 Dec 8, 2022

SummVis is an interactive visualization tool for text summarization.
SummVis is an interactive visualization tool for analyzing abstractive summarization model outputs and datasets.
 246 Dec 8, 2022
246 Dec 8, 2022
Automated Phrase Mining from Massive Text Corpora in Python.
Automated Phrase Mining from Massive Text Corpora in Python.
 28 Apr 15, 2021
28 Apr 15, 2021

The guide to tackle with the Text Summarization
The guide to tackle with the Text Summarization
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
Package for controllable summarization
summarizers summarizers is package for controllable summarization based CTRLsum. currently, we only supports English. It doesn't work in other languag
 72 Dec 7, 2022
72 Dec 7, 2022

Summarization, translation, sentiment-analysis, text-generation and more at blazing speed using a T5 version implemented in ONNX.
Summarization, translation, Q&A, text generation and more at blazing speed using a T5 version implemented in ONNX. This package is still in alpha stag
 137 Feb 1, 2021
137 Feb 1, 2021
An Analysis Toolkit for Natural Language Generation (Translation, Captioning, Summarization, etc.)
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation
 310 Feb 1, 2021
310 Feb 1, 2021

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
 2.5k Feb 17, 2021
2.5k Feb 17, 2021
:mag: End-to-End Framework for building natural language search interfaces to data by utilizing Transformers and the State-of-the-Art of NLP. Supporting DPR, Elasticsearch, HuggingFace’s Modelhub and much more!
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
1.4k Feb 18, 2021
Summarization, translation, sentiment-analysis, text-generation and more at blazing speed using a T5 version implemented in ONNX.
Summarization, translation, Q&A, text generation and more at blazing speed using a T5 version implemented in ONNX. This package is still in alpha stag
211 Dec 28, 2022
An Analysis Toolkit for Natural Language Generation (Translation, Captioning, Summarization, etc.)
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation
409 Oct 28, 2022

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
1.9k Jan 6, 2023
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 8, 2023

Chinese NewsTitle Generation Project by GPT2.带有超级详细注释的中文GPT2新闻标题生成项目。
GPT2-NewsTitle 带有超详细注释的GPT2新闻标题生成项目 UpDate 01.02.2021 从网上收集数据,将清华新闻数据、搜狗新闻数据等新闻数据集,以及开源的一些摘要数据进行整理清洗,构建一个较完善的中文摘要数据集。 数据集清洗时,仅进行了简单地规则清洗。
 785 Dec 29, 2022
785 Dec 29, 2022
On Generating Extended Summaries of Long Documents
ExtendedSumm This repository contains the implementation details and datasets used in On Generating Extended Summaries of Long Documents paper at the
 76 Sep 5, 2022
76 Sep 5, 2022

Summarization module based on KoBART
KoBART-summarization Install KoBART pip install git+https://github.com/SKT-AI/KoBART#egg=kobart Requirements pytorch==1.7.0 transformers==4.0.0 pytor
 148 Dec 28, 2022
148 Dec 28, 2022
CrossNER: Evaluating Cross-Domain Named Entity Recognition (AAAI-2021)
CrossNER is a fully-labeled collected of named entity recognition (NER) data spanning over five diverse domains (Politics, Natural Science, Music, Literature, and Artificial Intelligence) with specialized entity categories for different domains.
 89 Nov 10, 2022
89 Nov 10, 2022
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 3, 2023
A sentence aligner for comparable corpora
About Yalign is a tool for extracting parallel sentences from comparable corpora. Statistical Machine Translation relies on parallel corpora (eg.. eur
 128 Aug 24, 2022
128 Aug 24, 2022